0. 학습목표
- Confusin matrix를 만들고 해석할 수 있다.
- 정밀도, 재현율을 이해하고 사용할 수 있다.
- ROC curve, AUC점수를 이해하고 사용할 수 있다.
1. 주요개념
1. Confusion matrix(혼동 행렬)
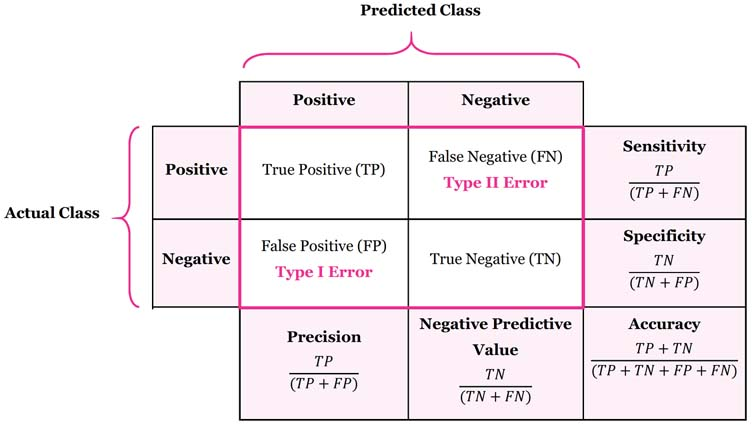
Confusion matrix랑 어떤 개인이나, 모델, 검사도구, 알고리즘의 진단분류판별예측 능력을 평가하기 위해서 고안된 표이다.
흔히 긍정(Postive) 또는 부정(Negative)의 형태로 이진적(Binary)인 논리로 알려져 있지만, 혼동행렬은 2 by 2행렬의 형태로만 나타나는 것은 아니다. 3개 이상의 등급(Class)을 갖는 다등급(Multi-class)분류의 결과도 혼동행렬로 나타내는 것이 가능하다. 예를들어 어떤 사람에게 동북 아시아인들의 얼굴 사진들을 보여주면서 한국인, 일본인, 중국인을 알아맞혀 보라고 한다면, 이때의 혼동행렬은 3 by 3 행렬의 형태로 나타나게 된다. 이 경우는 기존의 2 by 2 행렬에서 '부정'으로만 표시되던 셀을 세분화했다고 보면 된다.
기계학습에서 혼동행렬은 흔한 평가기준으로 사용된다. 특히 지도학습에 있어서 혼동행렬은 필수적이다. 이 혼동행렬을 이용하여 정확도, 정밀도, 재현율등의 평가지표를 계산할 수 있다.
2. 분류 모델의 성능평가지표
2-1. 정밀도(Precision)
예측 결과가 긍정적일 때 현실도 실제로 긍정일 확률이다. 정밀도가 높다는것은 긍정적인 예측이 제대로 적중한 경우가 많다는 의미가 되며, 정밀도 높은 예측 알고리즘은 안정성이 높다고 인정된다. 하지만 정밀도는 예측 결과가 부정적일 때 이를 얼마나 신뢰해야 할지에 대한 정보는 제공하지 않는다.
데이터의 관점에서 볼 때 정밀도가 높을수록 그 데이터는 분산(Variance)이 낮으며, 따라서 안정성이 높은 데이터로 평가될 수 있다.
2-2. 재현율(Recall)
민감도라고도 하며, 현실이 실제로 긍정일 때 예측 결과도 긍정적일 확률이다. 여기서는 현실이 긍정인 경우에만 관심을 갖고, 분모에는 참긍정과 거짓부정을 모아 넣는 반면 분자에는 참긍정만 넣어서 그 비율을 0~1 사이 값으로 확인한다.
민감도가 높다는 것은 현실이 긍정일 때 그 예측도 제대로 잘 이루어지고 있다는 의미가 된다. 하지만 민감도는 현실이 부정일 때 예측이 어떻게 이루어지는에 대한 정보는 제공하지 않는다.
2-3. F beta-score
일 경우에는 score라고 한다. score는 정밀도와 재현율의 조화평균을 이용하는 평가용 지수이다. 만일 TP=FP=FN으로 세 셀의 빈도가 동일하다면 값은 0.5이다. 값은 FP의 빈도와 FN의 빈도의 총합이 같다면 두 거짓 셀의 빈도 격차가 아무리 크더라도 이를 반영하지 않는다.
값의 논리는 위에서도 설명했듯이 조화평균에 입각한 것으로, 정밀도와 재현율 사이에 하나가 높아지면 다른 하나가 낮아지는 상황이 자주 발생하기에 이를 보정하기 위해 개발되었다.
본래는 값의 일종으로, 값이 양수일 때는 재현율에, 음수일 때는 정밀도에 가중치를 부여한다. 즉, 우리가 조금 더 중점적으로 생각하는 성능지표에 가중치를 부여하는 것이다.
2-4. 정확도(Accuracy)
예측이 현실에 부합활 확률을 의미한다. 예측 결과 전체를 모두 모아서 분모에 넣고, 참긍정이든 참부정이든 제대로 예측하는 데 성공한 빈도가 전체 증의 얼마를 차지하는지 0~1사이 값으로 살펴본다. 정확도가 높다는 것은 곧 예측이 제대로 적중한 경우가 많다는 의막 되며, 정확도 높은 예측 알고리즘은 활용 가능성이 높다고 인정된다.
데이터의 관점에서 볼 때 정확도가 높을수록 그 데이터는 Bias가 낮으며, 따라서 활용도가 높은 데이터로 평가될 수 있다. 정밀도와는 상충관계에 있기 때문에 대부분의 데이터 분석은 이 둘을 적절히 절충하는 것을 목표로 하게 된다.
2-5. 특이도(Specificity)
현실이 실제로 부정일 때 예측 결과도 부정적일 확률이다. 여기서는 재현율과는 반대로 현실이 부정인 경우에만 관심을 가진다. 특이도의 분모는 참부정과 거짓긍정으로 구성되고, 분자에는 참부정만 들어가서 0~1 사이 값으로 결과를 산출한다.
특이도가 높다는 것은 현실이 부정일 때 그 예측도 제대로 잘 이루어지고 있다는 의미가 된다. 하지만 역시 민감도와는 반대로, 특이도는 현실이 긍정일 때 평가 정보는 제공하지 않는다.
또한 특이도는 참부정율이라고도 한다. 1-특이도를 계산을 하면 현실이 실제로 부정일 때 예측 결과는 긍정일 확률이 얻어지는데 이쪽은 거짓긍정율(FPR)이라고 한다. 거짓긍정율은 위의 민감도와 함께 ROC곡선을 산출하는 데 쓰인다.
3. ROC curve
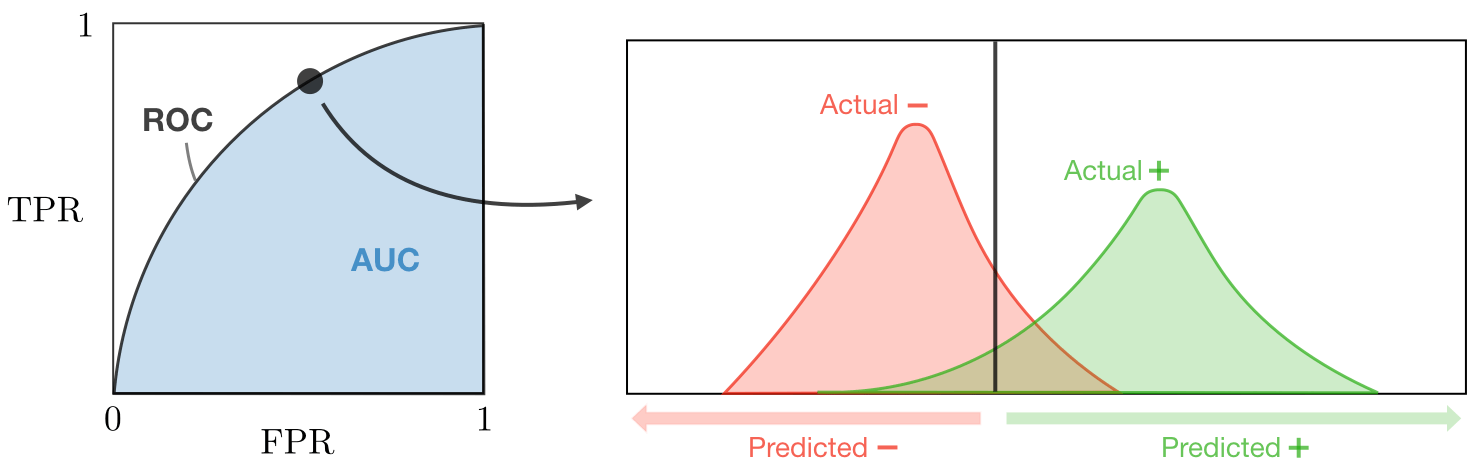
Receiver Operating Characteristic Curve로 수신자 조작 특성 곡선이라고 한다. 보통 이진적인 논리를 따르는 예측에 활용되며, 가로축에는 거짓긍정율(TNR), 세로축에는 민감도(참긍정율,TPR)가 배치되어 있고, 눈금은 두 축 모두 0~1 사이의 범위로 그어져 있다. 개별 관측치에 대해서 하나의 거짓긍정율과 하나의 민감도 수치를 산출하므로, 데이터를 통해 예측할 때마다 점이 하나씩 찍히게 된다. 이 점이 찍힌 위치가 2차원 평면의 어디쯤에 있는지를 보는 것이 ROC curve를 ROC를 활용한 평가방법이다.
여기서 '전부 긍정', '전부 부정' 따위의 무식한 방식으로는 이상적인 예측 결과를 산출할 수 없다는 것이다. 제대로 된 예측을 하고 싶다면 때로는 부정을 예측할 수 있어야 한다. 이것을 문턱값 혹은 역치, 임계값(Threshold)라고 한다. 역치는 알고리즘과 함께 예측에 있어서 중요한 이슈이다. 동일한 알고리즘을 적용하더라도 역치가 높으면 (0,0)점에 가까이 내려가고, 역치가 너무 낮으면 (1,1)점에 가까이 올라간다. 그래서 점이 왼쪽 아래에 찍혔다면 알고리즘을 너무 조심스럽게 적용한 셈이고, 오른쪽 위에 찍혔다면 너무 마구잡이로 적용한 셈이다.
그렇다면 동일한 알고리즘이 무한히 다양한 역치들 사이에서 찍을 수 있는 점들의 위치를 연속적으로 쭉 이을 수 있을 것이다. 이렇게 하면 (0,0)점과 (1,1)점에 접하면서 왼쪽 위로 볼록한 형태의 곡선이 만들어지는데 이것이 바로 ROC curve이다. 이상적인 예측 결과를 산출하는 알고리즘은 그만큼 ROC 곡선의 중앙부가 왼쪽 위의 (0,1)점에 가까이 이끌려 있다. 반면 무작위로 선택되는 알고리즘이 만드는 ROC곡선은 y=x 대각선에 매우 근접해 있다. ROC 곡선이 (0,1)점을 향해 바짝 달라붙어 있다는 이야기는, 다시 말하면 그 알고리즘이 긍정인 상황과 부정인 상황을 그만큼 잘 구별해 내고 있다는 이야기다.
이 ROC curve를 이용하여 예측 알고리즘의 성능을 평가하기 위하여 활용하는 지표가 AUC(Area Under ROC)이다. 말 그대로 ROC 곡선의 아래 면적을 의미한다. 일반적으로 정도의 기준이 채택되는 경향이 있다.
2. 명령어
1. module: sklearn.metrics
1-1. ConfusionMatrixDisplay
혼동행렬을 시각화하여 주는 명령어이다. 뒤에 .from_estimator를 사용하거나 from_predictions를 사용하여 생성하여 주는 것이 좋다.
앞서 말했듯이 "시각화" 해주는 명령어이기 때문에 앞의 메소드를 추가적으로 입력하여 혼동행렬을 만들어 주는 것이다. 위 방법 외에도 confusion_matrix라는 명령어를 통해서 혼동행렬을 직접 생성할 수도 있다.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=clf.classes_)❗ ConfusionMatrixDisplay 공식 문서
사이트 주소: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.ConfusionMatrixDisplay.html
1-2. Classification_report
기본 분류 지표를 보여주는 텍스트 보고서를 출력하여 준다. 각 클래스에 대한 정밀도, 재현율, f1-score, Macro 평균, 가중 평균 등이 담겨있다.
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
>>> precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
accuracy 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5❗ Classification_report 공식 문서
사이트 주소: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html
1-3. roc_curve
ROC를 계산하여 출력하여 준다. 이 명령어는 이진 분류 작업에서만 사용할 수 있다.
from sklearn.metrics import roc_curve
# roc_curve(타겟값, prob of 1)
fpr, tpr, thresholds = roc_curve(y_val, y_pred_proba)❗ roc_curve 공식 문서
사이트 주소: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html
2. Libarary: numpy
2-1. diag()
행렬에서 대각선 요소를 추출하거나, 대각행렬을 생성한다.
x = np.arange(9).reshape((3,3))
x
>>> array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
np.diag(x)
>>> array([0, 4, 8])2-2. argmax()
축에서의 최대값을 가지는 인덱스를 반환한다.
a = np.arange(6).reshape(2,3) + 10
a
array([[10, 11, 12],
[13, 14, 15]])
np.argmax(a)
>>> 55. pipeline.classes_
어떤 클래스로 분류하는지 클레스 라벨을 반환한다. 단, 이 속성을 쓰기 위해서는 pipe Line의 마지막 단계가 분류기여야 한다.
from sklearn.pipeline import make_pipeline
from category_encoders import OrdinalEncoder
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 파이프라인을 만들어 봅시다.
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(n_estimators=100, random_state=2, n_jobs=-1)
)
pipe.classes_
>>> array([0, 1])6. predict_proba()
각 클래스에 대한 예측 확률을 반환하여 주는 명령어이다.
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fix(X,y)
clf.predict_proba(X_test)
>>> "각 레이블에 대한 예측 확률"3. 회고
토요일까지 마무리하고 끝내려했는데 어제 아침부터 제사지내고 운전하고 올라왔더니 갑자기 컨디션이 맛이나가서 두통에 시달려서 못끝냈다. 일단 정리는 다 끝냈으니까 못다한 도전과제 하면서 모델이나 더 잘 만들어봐야겠다.
❗ 참고자료
1. 혼동행렬,평가지표,ROC,AUC
2. ROC
