0.학습목표
- 지도학습(Supervised machin learning)모델을 학습하기 위한 훈련 데이터를 생성 한다.
- 지도학습을 위한 데이터 엔지니어링 방법을 이해하고 올바른 특성을 만들어 낼 수 있다.
1. 주요개념
이번 노트는 사실 새로운 내용은 전무하다고 할 수 있다. 대체로 Pandas, numpy등 각 종 라이브러리를 활용하여 데이터를 합치고, 원하는 내용을 추출하는 Data Wrangling방법이 주를 이루고 있다. 따라서 딱히 큰 개념 없이 Data Wrangling과 관련된 Sprint1의 Velog주소를 첨부한다.
2. 명령어
1. Library: glob
glob은 파일들의 리스트를 뽑을 때 사용한다. 파일의 경로명을 이용하여 사용자 마음대로 요리할 수 있다.
from glob import glob
glob('*.exe') # 현재 디렉터리의 .exe 파일
>>> ['python.exe', 'pythonw.exe']
glob('*.txt') # 현재 디렉터리의 .txt 파일
>>> ['LICENSE.txt', 'NEWS.txt']위의 glob()함수는 인자로 받은 패턴과 이름이 일치하는 모든 파일과 디렉터리의 리스트를 반환한다. 패턴을 그냥 *로 입력하면 모든 파일과 디렉터리를 볼 수 있다.
현재 경로가 아닌 다른 경로에 대해서도 조회 가능하다.
glob(r'C:\U*') # C:\에서 이름이 U로 시작하는 디렉터리나 파일을 찾기
>>> ['C:\\Users', 'C:\\usr']2. Library: Ipython.display
Ipython은 기본적으로 Python의 일종으로 대화형 방식의 파이썬을 의미한다. 복수의 프로그래밍 언어에서 상호작용적인 컴퓨팅을 하기 위한 명령 셸이며 파이썬 프로그래밍 언어용으로 처음 개발되었다. 자가 검사, 대화형 매체, 셸 문법, 탭 완성, 히스토리를 제공한다. display모듈은 이런 Ipython의 공개 display tool API이다.
대체로 명령어를 사용할 때 그 코드에서 실행 시 값을 출력하거나 보기 위해서, print()함수를 많이 사용하는데, 이 Print()함수는 object 형식으로 값을 출력하여 보여준다. 따라서 데이터 프레임의 경우 Pandas에서 보여주는 데이터프레임 형식으로 보고 싶으면 display를 사용하면 된다.
도표를 보여주는 것뿐만 아니라 오디오 파일 등 다양한 파일 형식을 지원하는 거 같은데 킹식문서를 참고하자.
💡 Ipython.display 공식문서
사이트 주소: https://ipython.readthedocs.io/en/stable/api/generated/IPython.display.html
# 사용예시
from IPython.display import display
import pandas as pd
def preview():
for filename in glob('*.csv'):
df = pd.read_csv(filename)
print(filename, df.shape)
display(df.head())
print('\n')<실행 결과>
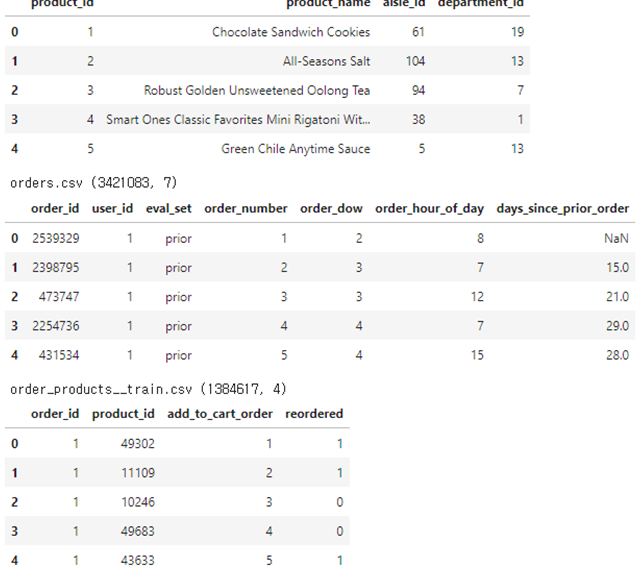
아래에 2개의 Dataframe이 더 출력되나 생략하였음.
3. .set()
집합(Set)은 파이썬 2.3부터 지원하기 시작한 자료형으로, 집합에 관련된 것을 쉽게 처리하기 위해 만든 자료형이다.
.set()명령어는 이런 집합 자료형을 만들기 위한 명령어이다.
s1 = set([1,2,3])
s1
>>> {1, 2, 3}
s2 = set("Hello")
s2
>>> {'e', 'H', 'l', 'o'}4. .isdisjoint()
두 set의 공통요소가 존재하는지 확인하여 Bool값을 반환하는 명령어이다. 공통요소가 있으면 False 없으면 True를 반환한다.
x = {"Python", "코드스테이츠", "코딩강의"}
y = {"HTML", "CSS", "JS"}
res = x.isdisjoint(y)
print(res)
>>> True5. .mode()
.mode()메서드는 대상 행/열의 최빈값을 구하는 메서드이다. 최빈값이 여러개일 경우 모두 표시한다.
list_1 = [1,1,2,3,3,3]
list_1.mode()
>>> 0 3
axis:{0:index / 1:columns}최빈값을 구할 축이다.
numeric_only:True일 경우 숫자, 소수, 부울값만 있는 열에 대해서만 연산을 수행한다.
dropna:결측치를 계산에서 제외할지 여부이다.False일 경우 결측치도 계산에 포함된다.
6. .any()
any()함수는 인자로 받은 반복가능한 자료형(iterable)중 단 하나라도 참(True)이 있으면 참(True)를 반환하는 함수이다. 반대로 모든 요소가 거짓(False)인 경우에만 거짓(False)을 반환한다.
any([False, False, False])
>>> False
any([False, True, False])
>>> True7. .rename()
Pandas라이브러리의 모듈로 Column 또는 index와 같은 축의 이름을 변경하여 주는 함수이다.
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
df.rename(columns={"A": "a", "B": "c"})
>>>
a c
0 1 4
1 2 5
2 3 6
df.rename(index={0: "x", 1: "y", 2: "z"})
>>>
A B
x 1 4
y 2 5
z 3 6💡 rename() 공식문서
사이트 주소: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.rename.html
8. .count()
각 열 또는 행에 대해서 NA(결측치)가 아닌 셸의 수를 계산한다. None,NaN,NaT 및 선택적으로 numpy.inf(Pandas.options.mode.use_inf_as_na에 따라 달라짐)가 NA로 간주된다.
df = pd.DataFrame({"Person":
["John", "Myla", "Lewis", "John", "Myla"],
"Age": [24., np.nan, 21., 33, 26],
"Single": [False, True, True, True, False]})
df
>>>
Person Age Single
0 John 24.0 False
1 Myla NaN True
2 Lewis 21.0 True
3 John 33.0 True
4 Myla 26.0 False
df.count()
>>>
Person 5
Age 4
Single 5
dtype: int64💡 count 공식문서
사이트 주소: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.count.html
9. .agg()
지정된 축에 대해서 하나 이상의 작업을 사용하여 집계한다.
df = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['A', 'B', 'C'])
df.agg(['sum', 'min'])
>>>
A B C
sum 12.0 15.0 18.0
min 1.0 2.0 3.0
# 열마다 집계가 다르다.
df.agg({'A' : ['sum', 'min'], 'B' : ['min', 'max']})
>>>
A B
sum 12.0 NaN
min 1.0 2.0
max NaN 8.0💡 agg 공식문서
사이트 주소: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.agg.html
3. 회고
뭔가 왜인지 모르겠는데 계속 쳐진다. 의욕은 있는데 아무것도 하기 싫고 그렇다. 운동을 너무 안해서 그런가? 내일부터는 그래도 한시간이라도 산책을 해야겠다. 그리고 주말에는 명령어 총 정리를 깔끔하게 해봐야겠다.
그리고 스챌도 해야하고, Kaggle모델도 다시 만들어서 해봐야해고, DACON도 한 번 제출 해봐야하는데 이거 적다보니까 내가 욕심이 과하네? 그래도 뭐 일단 하는데까지 해봐야겠다.
