0. 학습목표
Level 1.
- 임베딩(Embedding)의 개념과 One-Hot Encoding과 비교되는 장점에 대해 설명할 수 있다.
- Word2Vec의 두 방법(CBoW, Skip-gram)의 차이와 Word2Vec으로 임베딩한 단어 벡터의 특징에 대해 설명할 수 있다.
Level 2.
- FastText에서 적용된 철자 단위 임베딩(Character-Level Embedding)방법의 장점에 대해 설명할 수 있다.
Level 3.
- 임베딩(Embedding)이 다른 도메인에서는 어떻게 사용되는지 폭넓게 이해하며 예시를 들어 설명할 수 있다.
1. 분산 기반 표현(Distributed Representation)
지난 노트에서 등장 횟수 기반 표현(Count-based Representation)에 대해서 학습하였다.
이번 노트에서는 단어 자체를 벡터화하는 방법에 대해서 다룬다. Word2Vec에서는 벡터화하고자 하는 타겟 단어(Target word)의 표현이 해당 단어 주변 단어에 의해 결정된다. 단어 벡터를 이렇게 정의하는 이유는 분포 가설(Distribution hypothesis)때문이다.
💡 분포 가설
"비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다"
즉, 다시 정리하면 비슷한 의미를 지닌 단어는 주변 단어 분포 역시 비슷하다고 가정하는 것이 분포 가설의 핵심이다.
이 분포 가설에 기반하여 주변 단어 분포를 기준으로 단어의 벡터 표현이 결정되기 때문에 분산 표현(Distributed Representation)이라고 부른다. 이렇게 표현된 벡터들은 원-핫 벡터처럼 벡터의 차원이 단어 집합(vocabulary)의 크기일 필요가 없으므로, 벡터의 차원이 상대적으로 저차원으로 줄어든다.
본격적인 분산 표현을 학습하기에 앞 서 원-핫 인코딩(One-Hot Encoding)을 다시 한 번 읽고오자. 원-핫 인코딩은 범주형 변수를 벡터로 나타내는 방법 중 하나로, 쉽게 이해할 수 있는 직관적인 방법이지만 단어 간 유사도를 구할 수 없다는 치명적인 단점이 있다. 단어 간 유사도를 구할 때에는 코사인 유사도(Cosine Similarity)가 자주 사용된다. 그 식은 다음과 같다.
위 식에 원-핫 인코딩을 적용한 서로 다른 두 벡터를 대입하면 항상 0이 된다. 따라서 두 단어 사이의 유사도를 계산할 수 없게 된다. 다음과 같은 코드로 간단하게 구현도 가능하다.
import numpy as np
def cos_sim(a, b):
"""
코사인 유사도를 구하는 함수입니다.
Args:
a, b : 토큰 벡터입니다 -> array
"""
arr_a = np.array(a)
arr_b = np.array(b)
result = np.dot(arr_a, arr_b)/(np.linalg.norm(arr_a)*np.linalg.norm(arr_b))
return result
print(f"I 와 am 의 코사인 유사도 : {cos_sim(word_dict['I'], word_dict['am'])}")
print(f"I 와 student 의 코사인 유사도 : {cos_sim(word_dict['I'], word_dict['student'])}")
------------------------------------------------------------------------------
I 와 am 의 코사인 유사도 : 0.0
I 와 student 의 코사인 유사도 : 0.0Embedding(임베딩)
단어 사이의 관계를 나타낼 수 없다는 원-핫 인코딩의 단점을 해결하기 위해 등장한 것이 바로 임베딩(Embedding)이다. 단어를 고정 길이의 벡터, 즉 차원이 일정한 벡터로 나타내기 때문에 "Embedding(=박다, 끼워넣다)"이라는 이름이 붙었다.
임베딩을 거친 단어는 One-Hot Encoding을 거친 단어와는 다른 형태의 값을 가진다.
[0.04227, -0.0033, 0.1607, -0.0236, ...]위와 같이 벡터 내의 각 요소가 연속적인 값을 가지게 된다. 이런 벡터를 만드는 방법 중 가장 널리 알려진 임베딩 방법으로 Word2Vec이 있다.
2. Word2Vec
2013년에 고안된 Word2Vec은 말 그대로 단어를 벡터로(Word to vector) 나타내는 방법으로 가장 널리 사용되는 임베딩 방법 중 하나이다.
Word2Vec은 특정 단어 양 옆에 있는 두 단어(Window size = 2)의 관계를 활용하기 때문에 분포 가설을 잘 반영하고 있다.
Word2Vec에는 CBoW와 Skip-gram의 2가지 방법이 있다. 두 가지 방법에 대해 알아보자.
CBoW와 Skip-gram
CBoW와 Skip-gram의 차이는 다음과 같다.
1. 주변 단어에 대한 정보를 기반으로 중심 단어의 정보를 예측하는 모델 -> CBoW(Continuous Bag-of-Words)
2. 중심 단어의 정보를 기반으로 주변 단어의 정보를 예측하는 모델 -> Skip-gram
아래 그림과 예시를 통하여 두 방식의 차이를 좀 더 잘 이해해 보겠다.
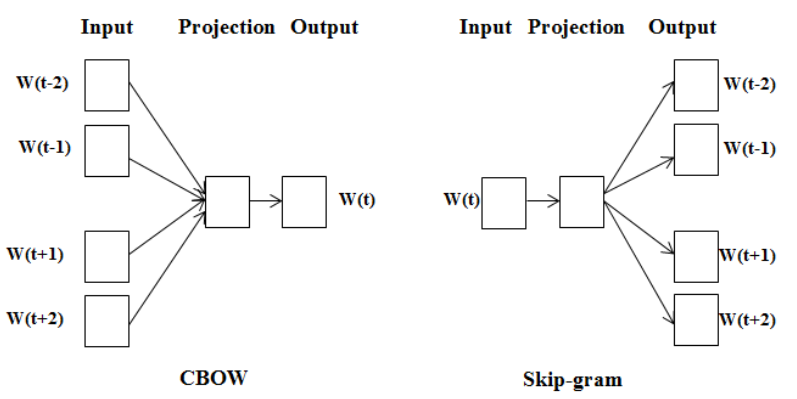
다음 예시는 <별 헤는 밤>의 일부분에 형태소 분석기를 적용하여 토큰화한 것이다.
표시된 언어 정보를 바탕으로 아래의 [---]에 들어갈 단어를 예측하는 과정으로 학습이 진행된다.
👉 CBoW
“… 나 는 [ -- ] 하나 에 … “
“… 는 별 [ ---- ] 에 아름다운 …”
“… 별 하나 [ -- ] 아름다운 말 …”
“… 하나 에 [ -------- ] 말 한마디 …”
👉 Skip-gram
“… [ -- ][ -- ] 별 [ ---- ][ -- ] …”
“… [ -- ][ -- ] 하나 [ -- ][ -------- ] …”
“… [ -- ][ ---- ] 에 [ -------- ][ -- ] …”
“… [ ---- ][ -- ] 아름다운 [ -- ][ ------ ] …”
더 많은 정보를 바탕으로 특정 단어를 예측하기 때문에 CBoW의 성능이 더 좋을 것으로 생각하기 쉽지만, 역전파 관점에서 보면 Skip-gram에서 훨씬 더 많은 학습이 일어나기 때문에 Skip-gram의 성능이 조금 더 좋게 나타난다.
물론 계산량이 많기 때문에 Skip-gram에 드는 리소스가 더 큰 것도 사실이다.
Word2Vec 모델의 구조
성능 덕분에 조금 더 자주 사용되는 Skip-gram을 기준으로 Word2Vec의 구조에 대하여 알아보겠다.
- 입력: Word2Vec의 입력은 One-Hot Encoding된 단어 벡터이다.
- 은닉층: 임베딩 벡터의 차원수 만큼의 노드로 구성된 은닉층이 1개인 신경망이다.
- 출력층: 단어 개수 만큼의 노드로 이루어져 있으며 활성화 함수로 소프트맥스를 사용한다.
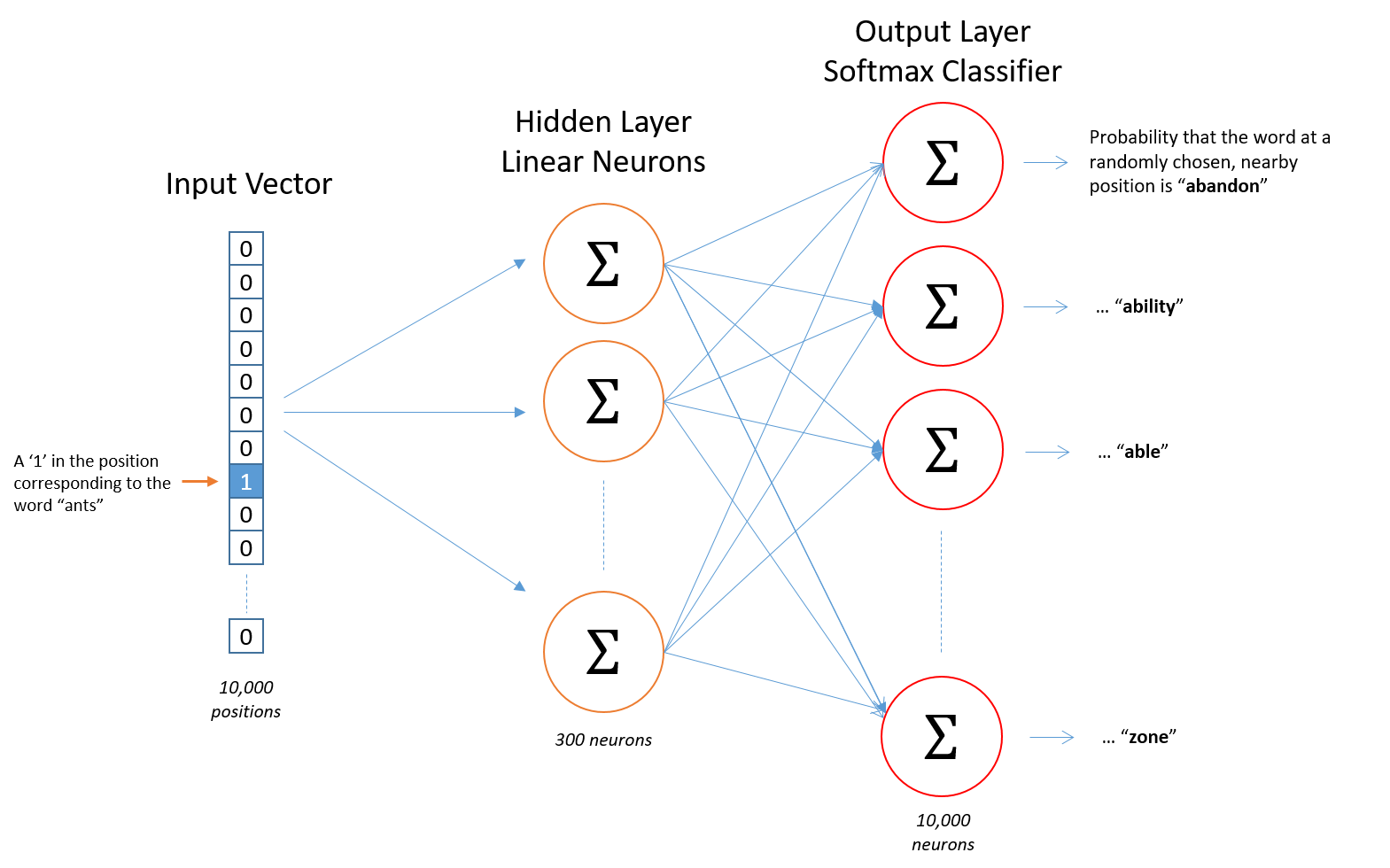
해당 그림은 논문에서 구성한 Word2Vec모델의 개략적인 구조로, 총 10,000개의 단어에 대해서 300차원의 임베딩 벡터를 구했기 때문에 신경망 구조가 위와 같이 구성된다.
Word2Vec 학습을 위한 학습 데이터 디자인
효율적인 Word2Vec학습을 위해서는 학습 데이터를 잘 구성해야 한다. Window사이즈가 2인 Word2Vec이므로 중심 단어 옆에 있는 2개 단어에 대해 단어쌍을 구성한다.
예를 들어,"The tortoise jumped into the lake"라는 문장에 대해 단어쌍을 구성해보겠다. 윈도우 크기가 2인 경우 다음과 같이 Skip-gram을 학습하기 위한 데이터 쌍을 구축할 수 있다.
- 중심 단어 : The, 주변 문맥 단어 : tortoise, jumped
- 학습 샘플: (the, tortoise), (the, jumped)
- 중심 단어 : tortoise, 주변 문맥 단어 : the, jumped, into
- 학습 샘플: (tortoise, the), (tortoise, jumped), (tortoise, into)
- 중심 단어 : jumped, 주변 문맥 단어 : the, tortoise, into, the
- 학습 샘플: (jumped, the), (jumped, tortoise), (jumped, into), (jumped, the)
- 중심 단어 : into, 주변 문맥 단어 : tortoise, jumped, the, lake
- 학습 샘플: (into, tortoise), (into, jumped), (into, the), (into, lake)
이를 DataFrame 형태로 정리하면 다음과 같은 데이터쌍이 만들어 진다.

Skip-gram에서는 중심단어를 입력으로, 문맥단어를 레이블로 하는 분류(Classification)를 통해 학습한다고 생각하면 된다.
Word2Vec의 결과
학습이 모두 끝나면 10000개의 단어에 대해 300차원의 임베딩 벡터가 생성된다. 만약에 임베딩 벡터의 차원을 조절하고 싶다면 은닉층의 노드 수를 줄이거나 늘릴 수 있다.
아래 그림은 신경망 내부에 있는 크기의 가중치 행렬에 의해서 10000개 단어에 대한 300차원의 벡터가 생성되는 모습을 나타낸 이미지이다.
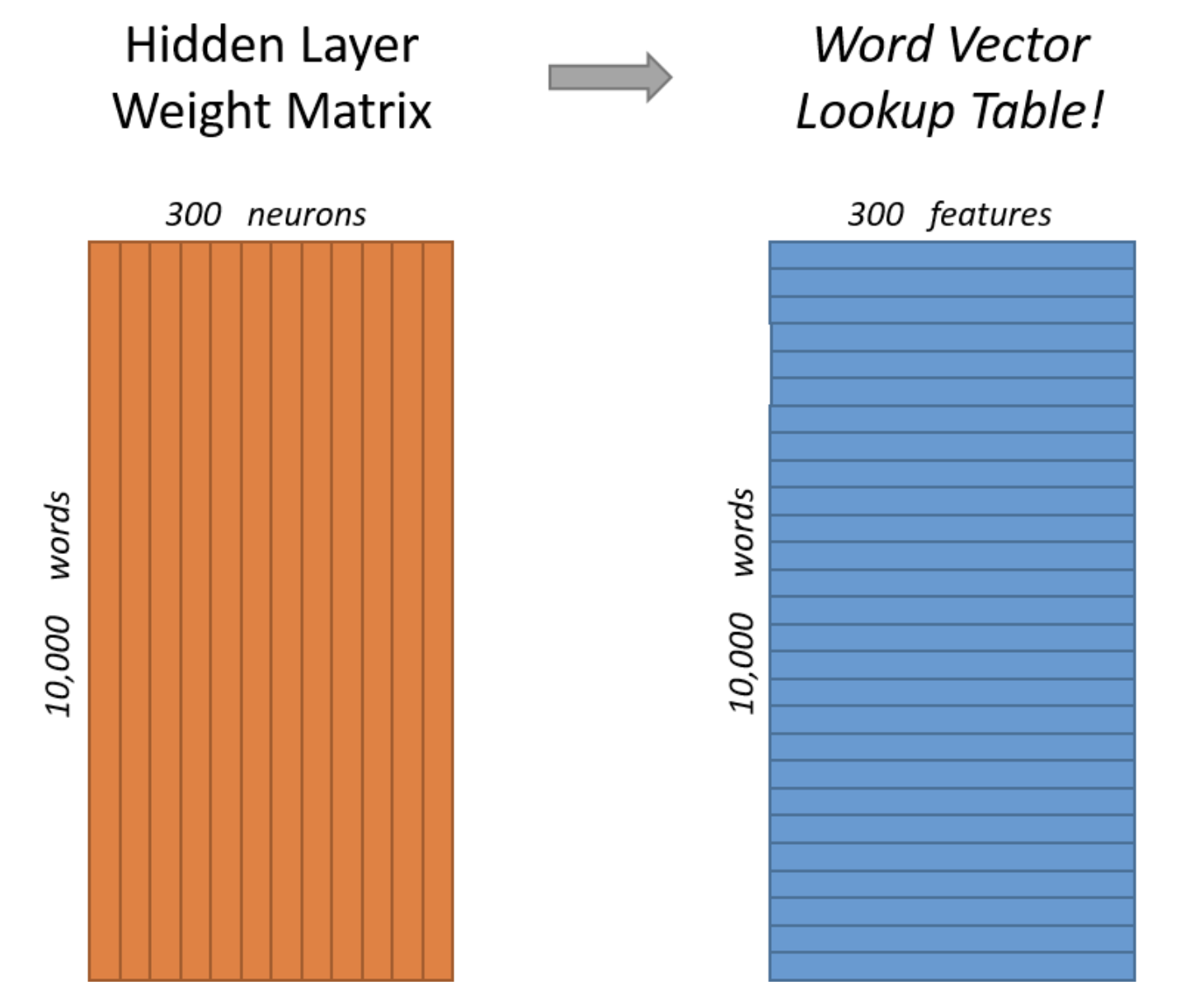
학습과정에서 Word2Vec의 계산량을 줄이기 위해 사용하는 기법들이 있지만 이 Sprint에서는 다루지 않는다. 추후 추가적인 학습을 원한다면 다음과 같은 키워드를 통해서 학습하면 된다고 한다.
- Sub-sampling
- Negative-sampling
결과적으로 Skip-gram 모델을 통하여 10000개 단어에 대한 임베딩 벡터를 얻을 수 있다. 이렇게 얻은 임베딩 벡터는 문장 간의 관련도 계산, 문서 분류같은 작업에 사용할 수 있다.
Word2Vec으로 임베딩한 벡터 시각화
Word2Vec을 통해 얻은 임베딩 벡터는 단어 간의 의미적, 문법적 관계를 잘 나타낸다. 이를 대표적으로 잘 보여주는 것이 아래 그림이다.
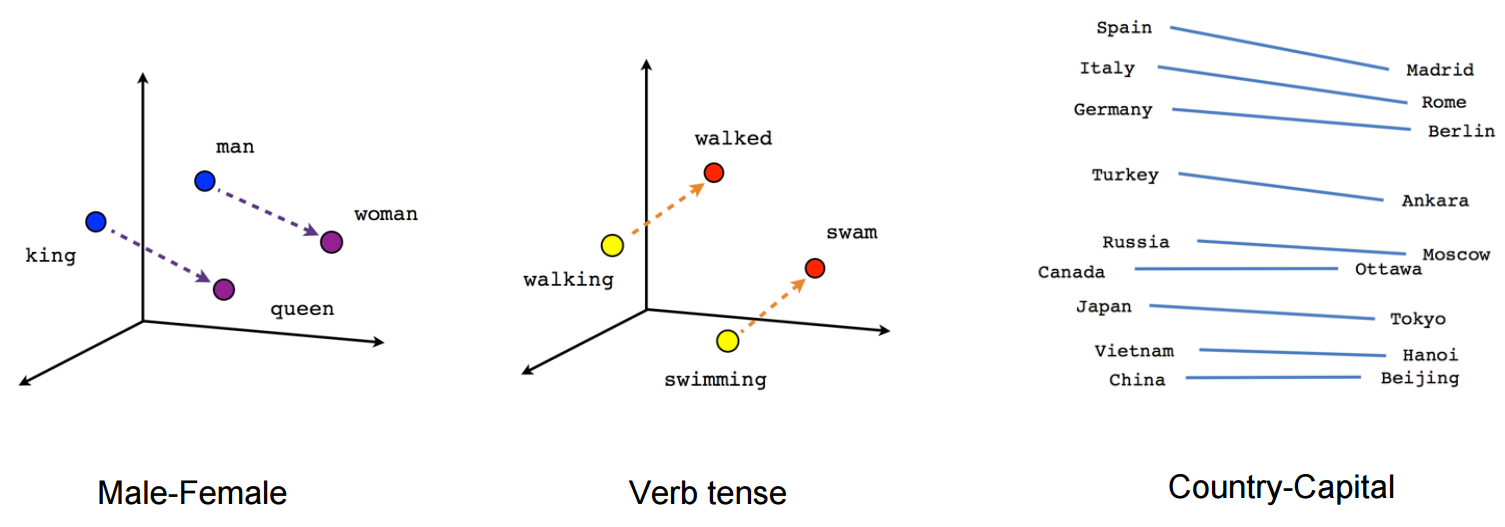
1. man - woman 사이의 관계와 King-queen사이의 관계가 매우 유사하게 나타난다. 이를 통하여 생성된 임베딩 벡터가 단어의 의미적(Semantic)관계를 잘 표현하는 것을 확인할 수 있다.
2. walking-walked 사이의 관계와 swimming - swam사이의 관계가 매우 유사하게 나타난다. 이를 통하여 생성된 임베딩 벡터가 단어의 문법적(혹은 구조적, Syntactic)인 관계도 잘 표현하는 것을 확인할 수 있다.
3. 고유명사에 대해서도 나라-수도와 같은 관계를 잘 나타내고 있는 것을 확인할 수 있다.
gensim 패키지로 word2Vec 실습하기
gensim은 word2Vec으로 사전 학습된 임베딩 벡터를 쉽게 사용해볼 수 있는 패키지이다. gensim을 사용하여 Word2Vec의 결과가 어떻게 도출되는지 알아보겠다.
0. gensim패키지 업그레이드
--upgrade 셀을 실행하여 gensim 패키지를 업그레이드 한 후, Coloab의 메뉴 탭에서 "런타임 > 런타임 다시 시작"을 클릭하여 런타임을 재시작 해준다.
이후 아래 .__version__을 활용하여 업그레이드가 잘 되었는지 확인한다.
!pip install gensim --upgradeimport gensim
gensim.__version__1. 구글 뉴스 말뭉치로 학습된 Word2Vec벡터를 다운받는다.
import gensim.downloader as api
wv = api.load('word2vec-google-news-300')2. 0~9 인덱스에 위치한 단어가 무엇인지 확인해본다.
for idx, word in enumerate(wv.index_to_key):
if idx == 10:
break
print(f"word #{idx}/{len(wv.index_to_key)} is '{word}'")
-----
word #0/3000000 is '</s>'
word #1/3000000 is 'in'
word #2/3000000 is 'for'
word #3/3000000 is 'that'
word #4/3000000 is 'is'
word #5/3000000 is 'on'
word #6/3000000 is '##'
word #7/3000000 is 'The'
word #8/3000000 is 'with'
word #9/3000000 is 'said'3. 임베딩 벡터의 차원과 값을 눈으로 확인해보자.
"king"이라는 단어의 벡터의 Shape를 출력하여 임베딩 벡터의 차원을 확인해본다. 그리고 결과를 통해 Word2Vec을 통해 학습된 임베딩 300차원이며, 벡터의 요소가 One-Hot Encoding과는 다르다는 것을 확인할 수 있다.
vec_king = wv['king']
print(f"임베딩 벡터의 차원 수 : {vec_king.shape}\n")
print(f"'king' 의 임베딩 벡터 \n\n {vec_king}")
-----
임베딩 벡터의 차원 수 : (300,)
'king' 의 임베딩 벡터
[ 1.25976562e-01 2.97851562e-02 8.60595703e-03 1.39648438e-01
-2.56347656e-02 -3.61328125e-02 1.11816406e-01 -1.98242188e-01
5.12695312e-02 3.63281250e-01 -2.42187500e-01 -3.02734375e-01
-1.77734375e-01 -2.49023438e-02 -1.67968750e-01 -1.69921875e-01
.
.
.
.
.]4. 말뭉치에 등장하지 않는 단어의 임베딩 벡터를 확인해 본다.
"cameroon"이라는 단어는 사전에 지정해 준 단어 집합(Vocabulary,vocab)에 등장하지 않는 단어(Unknown token)이다. 이 단어를 "King"같이 임베딩 벡터화 해보면 KeyError가 발생한다. 이처럼 Word2Vec은 단어 집합에 지정하지 않은 단어는 벡터화 할 수 없다는 단점이 있다.
unk = 'cameroon'
try:
vec_unk = wv[unk]
except KeyError:
print(f"""단어 "{unk}"은 해당 모델에는 등장하지 않는 단어입니다.""")
-----
단어 "cameroon"은 해당 모델에는 등장하지 않는 단어입니다.5. 단어 간 유사도를 파악해보자.
gensim 패키지가 제공하는 .similarity를 활용하면 단어 간 유사도를 파악할 수 있다.
One-Hot encoding과 다르게 임베딩 벡터는 단어 간 유사도를 구했을 때 0이 아닌 값이 나오게 된다. 아래는 'car'와 몇몇 단어의 유사도를 비교한 결과이다.
pairs = [
('car', 'minivan'),
('car', 'bicycle'),
('car', 'airplane'),
('car', 'cereal'),
('car', 'democracy')
]
for w1, w2 in pairs:
print(f'{w1} ======= {w2}\t {wv.similarity(w1, w2):.2f}')
------------------------
car ======= minivan 0.69
car ======= bicycle 0.54
car ======= airplane 0.42
car ======= cereal 0.14
car ======= democracy 0.08.most_similar 메서드를 사용하여 'car' 벡터에 'minivan' 벡터를 더한 벡터와 가장 유사한 5개의 단어를 뽑아보겠다.
for i, (word, similarity) in enumerate(wv.most_similar(positive=['car', 'minivan'], topn=5)):
print(f"Top {i+1} : {word}, {similarity}")
-----------------------
Top 1 : SUV, 0.8532192707061768
Top 2 : vehicle, 0.8175783753395081
Top 3 : pickup_truck, 0.7763688564300537
Top 4 : Jeep, 0.7567334175109863
Top 5 : Ford_Explorer, 0.7565720081329346시각화에서 확인한 것처럼 king벡터에 women벡터를 더한 뒤 men벡터를 빼준 벡터와 가장 유사한 벡터로 queen이 나오는 것과 walking벡터에 swam벡터를 더한 뒤 walked벡터를 빼준 벡터와 가장 유사한 벡터로 swimming이 나오는 것을 확인할 수 있다.
print(wv.most_similar(positive=['king', 'women'], negative=['men'], topn=1))
print(wv.most_similar(positive=['walking', 'swam'], negative=['walked'], topn=1))
------------------
[('queen', 0.6525818109512329)]
[('swimming', 0.7448815703392029)].doesnt_match메서드를 사용하면 가장 관계없는 단어를 뽑아낼 수 있다.
print(wv.doesnt_match(['fire', 'water', 'land', 'sea', 'air', 'car']))
----
car임베딩 벡터를 활용한 문장분류
이번 예제에서는 이미 학습된 임베딩 벡터를 사용하여 문장 분류를 수행하는 코드에 대해 알아보겠다. 아래 코드에서는 문서에 있는 단어 벡터의 평균을 해당 문서의 벡터로 사용하여 분류 문제를 수행한다.
예를 들어, "I am a student"라는 문장을 구성하는 단어의 임베딩 벡터가 아래와 같다고 해보겠다.
이때, "I am a student"라는 문장을 분류하기 위해서 최종적으로 아래 벡터를 사용한다.
이게 되나? 의문이들 정도로 간단하지만, 간단한 문서 분류 문제에서는 꽤 좋은 성능을 보이기 때문에 Baseline모델로 많이 사용된다.
1. 필요한 모듈 imoport
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.datasets import imdb
2. 시드를 정해준다.
tf.random.set_seed(42)3. 데이터셋을 split 해준다.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=20000)
print(f"Train set shape : {X_train.shape}")
print(f"Test set shape : {X_test.shape}")
----------
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17465344/17464789 [==============================] - 0s 0us/step
17473536/17464789 [==============================] - 0s 0us/step
Train set shape : (25000,)
Test set shape : (25000,)4. 데이터셋이 어떻게 생겼는지 눈으로 확인해본다.
print(X_train[0])
print(type(X_train[0]))
5. 인덱스로 된 데이터를 텍스트로 변경하는 함수를 구현한다.
첫 번째 데이터를 텍스트로 변경하고 확인하여 본다.
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
"""
word_index 를 받아서 text 를 sequence 형태로 반환하는 함수입니다.
Args:
text: 텍스트 시퀀스입니다 -> str
"""
return ' '.join([reverse_word_index.get(i, '?') for i in text])decode_review(X_train[0])
----
>
"the as you with out themselves powerful lets loves their becomes reaching had journalist of lot from anyone to have after out atmosphere never more room and it so heart shows to years of every never going and help moments or of every chest visual movie except her was several of enough more with is now current film as you of mine potentially unfortunately of you than him that with out themselves her get for was camp of you movie sometimes movie that with scary but pratfalls to story wonderful that in seeing in character to of 70s musicians with heart had shadows they of here that with her serious to have does when from why what have critics they is you that isn't one will very to as itself with other tricky in of seen over landed for anyone of and br show's to whether from than out themselves history he name half some br of 'n odd was two most of mean for 1 any an boat she he should is thought frog but of script you not while history he heart to real at barrel but when from one bit then have two of script their with her nobody most that with wasn't to with armed acting watch an for with heartfelt film want an"6. keras의 tokenizer에 텍스트를 학습시킨다.
sentences = [decode_review(idx) for idx in X_train]
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)# 단어 집합(vocab)의 크기를 입력합니다. 패딩()을 고려하여 tokenizer의 단어 수에서 +1 해줍니다.
vocab_size = len(tokenizer.word_index) + 1
print(vocab_size)
-----
199997. pad_sequence를 통해 패딩 처리해준다.
자연어 처리를 하다보면 각 문장(또는 문서)은 서로 길이가 다를 수 있다. 그런데 기계는 길이가 전부 동일한 문서들에 대해서는 하나의 행렬로 보고, 한꺼번에 묶어서 처리할 수 있다. 다시 말해서 병렬 연산을 위해 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업이 필요할 때가 있다. 그리고 이러한 작업을 패딩(Padding)이라고 한다.
그리고 pad_sequence는 Keras에서 패딩을 위해서 제공하는 메서드이다.
X_encoded = tokenizer.texts_to_sequences(sentences)
max_len = max(len(sent) for sent in X_encoded)
print(max_len)
------
2494print(f'학습 데이터에 있는 문서의 평균 토큰 수: {np.mean([len(sent) for sent in X_train], dtype=int)}')
----
학습 데이터에 있는 문서의 평균 토큰 수: 238pad_sequences의 파라미터인 maxlen을 평균보다 조금 더 긴 400으로 설정해준다.
maxlen_pad = 400
X_train=pad_sequences(X_encoded, maxlen=maxlen_pad, padding='post')
y_train=np.array(y_train8. word2vec의 임베딩 가중치 행렬을 만들어줍니다.
사전 학습된 모든 단어(300만개)에 대해 만들 경우 너무 행렬이 커지기 때문에 개인 로컬환경에서 실행하기에는 무리가 있으므로 Vocab에 속하는 단어에 대해서만 만들어지도록 한다.
embedding_matrix = np.zeros((vocab_size, 300))
print(np.shape(embedding_matrix))
----
(19999, 300)def get_vector(word):
"""
입력 단어가 vocab 에 있는 단어일 경우 임베딩 벡터를 반환
Args:
word: 입력 단어 -> str
"""
if word in wv:
return wv[word]
else:
return Nonefor word, i in tokenizer.word_index.items():
temp = get_vector(word)
if temp is not None:
embedding_matrix[i] = temp9. 신경망을 구성하기 위한 keras 모듈을 불러온 후 학습을 수행한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Flattenmodel = Sequential()
model.add(Embedding(vocab_size, 300, weights=[embedding_matrix], input_length=maxlen_pad, trainable=False))
model.add(GlobalAveragePooling1D()) # 입력되는 단어 벡터의 평균을 구하는 함수입니다.
model.add(Dense(1, activation='sigmoid'))GlobalAveragePooling1D층은 입력되는 행렬의 평균을 구하는 층, 즉 입력되는 단어 벡터의 평균을 구하는 층으로 알아두면 된다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
model.fit(X_train, y_train, batch_size=64, epochs=20, validation_split=0.2)
----
Epoch 1/20
313/313 [==============================] - 7s 18ms/step - loss: 0.6924 - acc: 0.5242 - val_loss: 0.6908 - val_acc: 0.5852
Epoch 2/20
313/313 [==============================] - 5s 17ms/step - loss: 0.6902 - acc: 0.5735 - val_loss: 0.6884 - val_acc: 0.5944
.
.
.
Epoch 19/20
313/313 [==============================] - 5s 17ms/step - loss: 0.6675 - acc: 0.6215 - val_loss: 0.6642 - val_acc: 0.6272
Epoch 20/20
313/313 [==============================] - 5s 18ms/step - loss: 0.6666 - acc: 0.6237 - val_loss: 0.6633 - val_acc: 0.6270
<keras.callbacks.History at 0x7f37c6967c50>test_sentences = [decode_review(idx) for idx in X_test]
X_test_encoded = tokenizer.texts_to_sequences(test_sentences)
X_test=pad_sequences(X_test_encoded, maxlen=400, padding='post')
y_test=np.array(y_test)model.evaluate(X_test, y_test)
-------------------------------
782/782 [==============================] - 6s 8ms/step - loss: 0.6679 - acc: 0.6102
[0.6679435968399048, 0.6101999878883362]회고
NLP는 어렵고, 이걸 작성하는 지금 처음보는 것처럼 느껴진다. 정말 NLP공부 안했다는걸 다시금 느낀다.
❗️ 참고자료
1. 코드스테이츠 N422 Lecture Note
