❗ 이번 포스트는 화이트모드로 읽을 것.
0. 학습목표
Level 1.
- 자연어처리를 통해 할 수 있는 Task에는 어떤 것이 있는지 설명할 수 있다.
- 토큰화(Tokenization)에 대해 설명할 수 있으며 SpaCy라이브러리를 활용하여 토큰화를 진행할 수 있다.
- 불용어(Stop words), 어간 추출(Stemming)과 표제어 추출(Lemmatization) 등에 대해 설명할 수 있고 이를 적용하는 코드를 작성할 수 있다.
- Bag-of-words에 대해서 설명할 수 있으며 Scikit-learn라이브러리에서 이를 적용할 수 있다.
- TF-IDF에서 TF, IDF에 대해서 설명하고 IDF를 적용하는 이유에 대해서 설명할 수있다.
Level 2.
- N-gram의 개념에 대해 이해하고 Bag-of-words에 적용해 볼 수 있다.
Spacy라이브러리의 다른 기능을 텍스트에 적용하여 분석할 수 있다.
Level 3.
- LSA(잠재 의미 분석)에 대해 이해하고 코드로 적용해 볼 수 있다.
1. 자연어처리
자연어(Natural Language)혹은 자연 언어는 사람들이 일상적으로 쓰는 언어를 인공적으로 만들어진 언어인 인공어와 구분하여 부르는 개념이다. 쉽게 말해서 자연적으로 발생된 언어를 자연어라고 한다.
그리고 이런 자연어를 컴퓨터로 처리하는 기술을 자연어 처리(Natural Language Processing, NLP)라고 한다. 이는 넓은 의미로 음성 인식, 자연어 인식, 자연어 생성을 모두 의미한다. 하지만 일반적인 NLP는 다음과 같다.
- 토큰화(Tokenization)
- 구문 분석(Parsing)
- 정보 추출(Information extraction)
- 유사성(Similarity)
- 음성 인식(Speech recognition)
- 자연어와 음성 생성 등(Natural language and speech generations and many others)
자연어 처리를 비롯한 텍스트 마이닝의 중요한 요소들은 아래 그림과 같다.
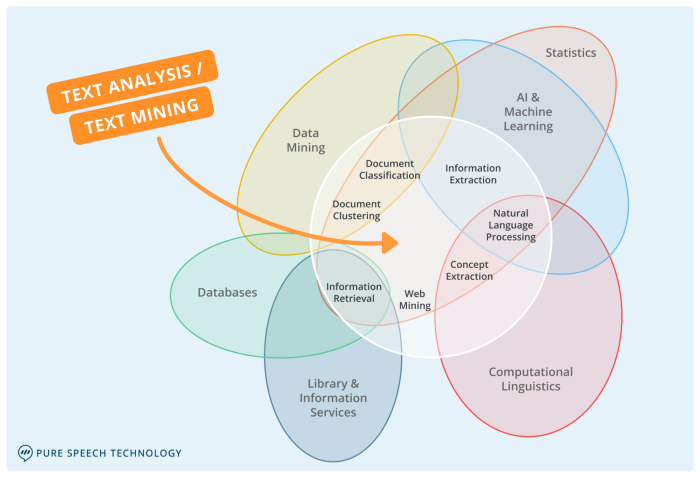
이런 자연어 처리로 할 수 있는 일들은 다양하다.
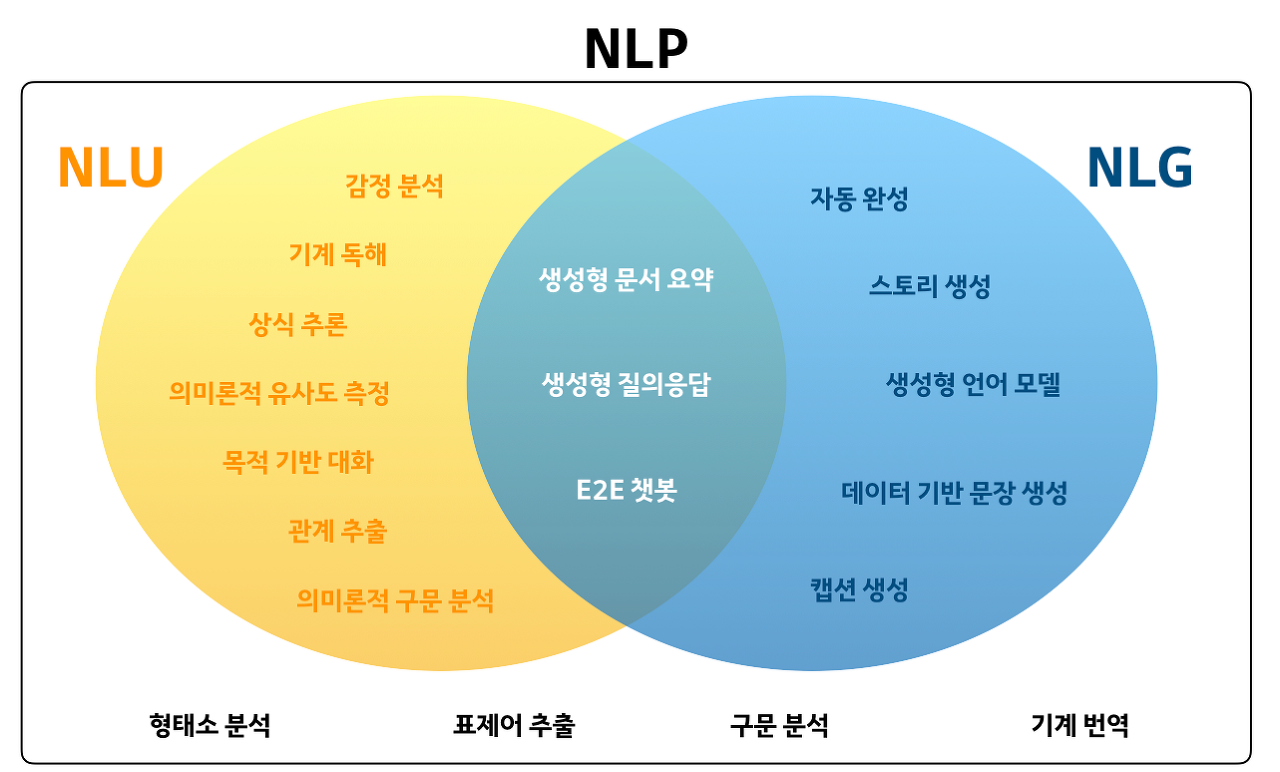
1. 자연어 이해(NLU, Natural Language Understanding)
NLU란 자연어 표현을 기계가 이해할 수 있는 다른 표현으로 변환시키는 것을 뜻한다. 결국 가장 인간 같은 기계를 만드는 것이 목적이다. 이 자연어 이해를 통하여 구현할 수 있는 Task들은 다음과 같다.
-
분류(Classification)
뉴스 기사 분류, 감성 분석(Positive/Negative) -
자연어 추론(NLI, Natural Language Inference)
"A는 B에게 암살당했다", 가설 : "A는 죽었다" -> True or False? -
기계 독해(MRC, Machine Reading Comprehension), 질의 응답(QA, Question&Answering)
비문학 문제 풀기
2. 자연어 생성(NLG, Natural Language Generation)
자연어 생성(NLG)과정은 자연어이해의 반대로써 생각하면 된다. 정보를 나타내는 구조를, 원하는 언어로 올바른 String으로 Mapping 시켜야 한다. 그러나 경우에 따라서는 전달할 정보가 어디로부터 얻어지는가를 생각하는 것도 중요한 문제이다. 자연어 생성에 대한 전체 과정은 다음과 같이 세 부분으로 나뉘어 질 수 있다.
- 전달할 정보를 나타내는 구조의 구성: 무엇을 말할 것인가를 결정
- 문장의 순서를 정하기 위한 대화 구조 및 문장에 대한 규칙을 적용
- 실제 문장을 생성하기 위하여, 단어에 대한 정보 및 문장론적 규칙을 적용한다.
3. NLU & NLG
두 가지를 조합하여 사용하면 다음과 같은 다양한 Task를 처리할 수 있다.
-
기계 번역(Machine Translation)
-
요약(Summerization)
-
생성 요약(Absractive Summerization)
해당 문서를 요약하는 요약문을 생성 👉 NLG에 가깝다. -
추출 요약(Extractive Summerization)
문서 내에서 해당 문서를 가장 잘 요악하는 부분을 찾아냄. 👉 NLU에 가깝다.
-
-
Chatbot
- Open Domain Dialog(ODD): 정해지지 않은 주제를 다루는 일반대화 챗봇
- Task Oriented Dialog(TOD): 특정 Task를 처리하기 위한 챗봇
4. 자연어 처리 용어 정리
말뭉치(Corpus)
자연어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합을 의미한다. 컴퓨터의 발달로 말뭉치 분석이 용이해졌으며 분석의 정확성을 위해 해당 자연언어를 형태소 분석하는 경우가 많다. 확률/통계적 기법과 시계열적인 접근으로 전체를 파악한다. 언어의 빈도와 분포를 확인할 수 있는 자료이며, 현대 언어학 연구에 필수적인 자료이다.
문장(Setence)
여러 개의 토큰(단어, 형태소 등)으로 구성된 문자열을 의미한다. 생각이나 감정을 말과 글로 표현할 때 완결된 내용을 나타내는 최소의 독립적인 형식단위이다. 마침표, 느낌표 등의 기호로 구분한다.
문서(Document)
문장(Sentences)들의 집합이다. 기승전결이 완성된 하나의 글을 뜻하는 것이 아니라 그냥 하나의 데이터 단위이며, 형태 상으로는 문단(paragraph)에 가깝다. 그러므로, 문장(Sentence)을 하나 또는 그 이상 포함한다면 문서로 볼 수 있다.
다시 정리하자면 우리가 일반적으로 생각하던 문서는 말뭉치에 가깝다. 믈론 말뭉치는 문서 다발인 경우가 대부분일 것이다. 그리고 문서 내의 문장들이 여기서 말하는 문서가 될 것이다. 예를 들어, 어떤 문서가 100문장으로 되어 있고 문장끼리 특별한 묶음이 없다면 그 문서는 100개의 문서로 구성된 말뭉치가 될 것이다.
어휘집합(Vocabulary)
말뭉치에 있는 모든 문서, 문장을 토큰화한 후 중복을 제거한 토큰의 집합을 의미한다.
2. 토큰화(Tokenization)
자연어처리에서 얻은 말뭉치(Corpus) 데이터가 필요에 맞게 전처리되지 않은 상태라면, 해당 데이터를 사용하고자하는 용도에 맞게 토큰화(tokenization) & 정제(cleaning) & 정규화(normalization)하는 일을 하게 된다.
주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업을 토큰화(tokenization)라고한다. 토큰의 단위가 상황에 따라 다르지만, 보통 의미있는 단위로 토큰을 정의한다.
3. 벡터화(Vectorize)
컴퓨터는 자연어 자체를 받아들일 수 없다. 그래서 컴퓨터가 이해할 수 있도록 벡터로 만들어주어야 한다. 이 과정을 벡터화(Vectorize)라고 한다. 벡터화 방식은 자연어 처리 모델의 성능을 결정하는 중요한 역할을 한다.
자연어를 벡터화하는 방법은 크게 2가지로 나눌 수 있다.
Count-based Representation(횟수 기반 표현)
단어가 문서(혹은 문장)에 등장하는 횟수를 기반으로 벡터화하는 방법이다.
- Bag-of-Words(
CounterVectorizer) - TF-IDF(
TfidfVectorizer)
Distributed Representation(분산 기반 표현)
타겟 단어 주변에 있는 단어를 기반으로 벡터화하는 방법이다. "비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다"라는 분포가설 가정 하에 만들어진 표현 방법이다.
이 방법으로 표현된 벡터들은 One-Hot Vector처럼 벡터의 차원이 단어 집합의 크기일 필요가 없으므로, 벡터의 차원이 상대적으로 저차원으로 줄어든다.
- Word2Vec
- GloVe
- fastText
4. Text Preprocessing(텍스트 전처리)
텍스트 데이터를 전처리하는 것은 자연어 처리의 시작이자 절반 이상을 차지하는 중요한 과정이다. 실제 텍스트 데이터를 다룰 때에는 데이터를 읽어보면서 어떤 특이사항이 있는지 파악해야 한다.
횟수 기반의 벡터 표현에서는 전체 말뭉치에 존재하는 단어의 종류가 데이터셋의 Feature, 즉 차원이 된다. 따라서, 단어의 종류(Feature)를 줄여주어야 차원의 저주를 어느 정도 해결할 수 있다. 차원의 저주에 대해서는 N132에서 다루었으니 확인하자. 정의만 간략하게 설명하면 다음과 같다.
차원의 저주를 해결할 전처리 방법은 다음과 같은 것들이 있다.
- 내장 메서드를 사용한 전처리(
lower,replace,...)- 정규 표현식(Regular expression Regex)
- 불용어(Stop words) 처리
- 통계적 트리밍(Trimming)
- 어간 추출(Stemming) 혹은 표제어 추출(Lemmatization)
간단한 예시를 통해 전처리가 어떻게 단어의 수를 줄일 수 있는지 알아보겠다.
내장 메서드, 정규표현식을 사용한 전처리
import pandas as pd
df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/amazon/Datafiniti_Amazon_Consumer_Reviews_of_Amazon_Products_May19_sample.csv')
df['brand'].value_counts()
-------------------------
Amazon 5977
Amazonbasics 4499
AmazonBasics 7
Name: brand, dtype: int64데이터의 출력을 확인하여 보면 Amazonbasics와 AmazonBasics는 같은 것을 지칭하는 단어임에도 대소문자 차이로 다른 카테고리로 취급되었다. 대소문자를 통일하여 둘을 같은 범주로 만들어 줄 수 있다.
df['brand'] = df['brand'].apply(lambda x: x.lower()) # 대문자로 바꾸고 싶을 때는 upper()
df['brand'].value_counts()
-------------------------------------
amazon 5977
amazonbasics 4506
Name: brand, dtype: int64다음으로는 정규표현식이다. 구두점이나 특수문자 등 필요없는 문자가 말뭉치 내에 있을 경우 토큰화가 제대로 이루어지지 않는다. 이를 제거하기 위해서 정규표현식을 사용한다.
a-z(소문자), A-Z(대문자), 0-9(숫자)를 ^제외한 나머지 문자를 regex에 할당한 후, .sub메서드를 통해서 공백 문자열 ""로 치환한다.
# 파이썬 정규표현식 패키지 이름은 re 입니다.
import re
# 정규식
# []: [] 사이 문자를 매치, ^: not
regex = r"[^a-zA-Z0-9 ]"
subst = ""
# 정규표현식을 통한 데이터 가공 후 대소문자 통일 -> 공백 문자 기준으로 분리
def tokenize(text):
"""text 문자열을 의미있는 단어 단위로 list에 저장합니다.
Args:
text (str): 토큰화 할 문자열
Returns:
list: 토큰이 저장된 리스트
"""
# 정규식 적용
tokens = re.sub(regex, subst, text)
# 소문자로 치환 후 분리
tokens = tokens.lower().split()
return tokens위에서 다룬 아마존 리뷰 데이터 중 reviews.text 열에 tokenize 함수를 적용하여 전처리 해보겠다. 각 리뷰텍스트를 토크나이즈 하여 tokens 칼럼으로 만든다.
df['tokens'] = df['reviews.text'].apply(tokenize)이제 결과를 분석해보겠다.
from collections import Counter
# Counter 객체는 리스트요소의 값과 요소의 갯수를 카운트 하여 저장하고 있습니다.
# 카운터 객체는 .update 메소드로 계속 업데이트 가능합니다.
word_counts = Counter()
# 토큰화된 각 리뷰 리스트를 카운터 객체에 업데이트 합니다.
df['tokens'].apply(lambda x: word_counts.update(x))
# 가장 많이 존재하는 단어 순으로 10개를 나열합니다
word_counts.most_common(10)
----------------------------------------------------------------------
[('the', 10514),
('and', 8137),
('i', 7465),
('to', 7150),
('for', 6617),
('a', 6421),
('it', 6096),
('my', 4119),
('is', 4111),
('this', 3752)]이제 다시 위 코드를 변형하여 말뭉치의 전체 워드 카운트, 랭크 등 정보가 담긴 DataFrame을 반환하는 함수를 구현하고 적용해보겠다.
def word_count(docs):
""" 토큰화된 문서들을 입력받아 토큰을 카운트 하고 관련된 속성을 가진 데이터프레임을 리턴합니다.
Args:
docs (series or list): 토큰화된 문서가 들어있는 list
Returns:
list: Dataframe
"""
# 전체 코퍼스에서 단어 빈도 카운트
word_counts = Counter()
# 단어가 존재하는 문서의 빈도 카운트, 단어가 한 번 이상 존재하면 +1
word_in_docs = Counter()
# 전체 문서의 갯수
total_docs = len(docs)
for doc in docs:
word_counts.update(doc)
word_in_docs.update(set(doc))
temp = zip(word_counts.keys(), word_counts.values())
wc = pd.DataFrame(temp, columns = ['word', 'count'])
# 단어의 순위
# method='first': 같은 값의 경우 먼저나온 요소를 우선
wc['rank'] = wc['count'].rank(method='first', ascending=False)
total = wc['count'].sum()
# 코퍼스 내 단어의 비율
wc['percent'] = wc['count'].apply(lambda x: x / total)
wc = wc.sort_values(by='rank')
# 누적 비율
# cumsum() : cumulative sum
wc['cul_percent'] = wc['percent'].cumsum()
temp2 = zip(word_in_docs.keys(), word_in_docs.values())
ac = pd.DataFrame(temp2, columns=['word', 'word_in_docs'])
wc = ac.merge(wc, on='word')
# 전체 문서 중 존재하는 비율
wc['word_in_docs_percent'] = wc['word_in_docs'].apply(lambda x: x / total_docs)
return wc.sort_values(by='rank')wc = word_count(df['tokens'])
wc.head()
-----
word word_in_docs count rank percent cul_percent word_in_docs_percent
51 the 4909 10514 1.0 0.039353 0.039353 0.468282
1 and 5064 8137 2.0 0.030456 0.069809 0.483068
26 i 3781 7465 3.0 0.027941 0.097750 0.360679
123 to 4157 7150 4.0 0.026762 0.124512 0.396547
19 for 4477 6617 5.0 0.024767 0.149278 0.427072cur_percent열을 활용하여 단어의 누적 분포 그래프를 그려보겠다.
import seaborn as sns
sns.lineplot(x='rank', y='cul_percent', data=wc);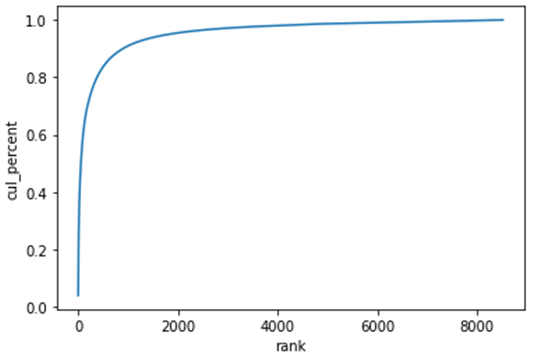
wc[wc['rank'] <= 1000]['cul_percent'].max()
--------------------------------------------
0.9097585076280484Squarify라이브러리를 사용하여 등장 비율 상위 20개 단어의 결과를 시각화하여 보겠다.
# squarify설치 과정은 스킵
import squarify
import matplotlib.pyplot as plt
wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6)
plt.axis('off')
plt.show()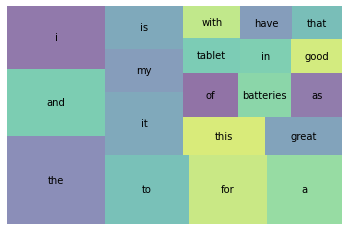
Spacy를 사용하여 더욱 쉽게 처리하기
SpaCy는 문서 구성요소를 다양한 구조에 나누어 저장하지 않고 요소를 색인화하여 검색 정보를 간단히 저장하는 라이브러리이다. 그렇기 때문에 실제 배포 단계에서 기존에 많이 사용되었던 NLTK라이브러리보다 SpaCy가 더 빠르다.
SpaCy라이브러리를 사용하여 토큰화하는 방법에 대해서 알아보겠다.
# 필요한 모듈을 import 합니다
import spacy
from spacy.tokenizer import Tokenizer
nlp = spacy.load("en_core_web_sm")
tokenizer = Tokenizer(nlp.vocab)
# 토큰화를 위한 파이프라인을 구성합니다.
tokens = []
for doc in tokenizer.pipe(df['reviews.text']):
doc_tokens = [re.sub(r"[^a-z0-9]", "", token.text.lower()) for token in doc]
tokens.append(doc_tokens)
df['tokens'] = tokens
df['tokens'].head()
---------------------------------------------------------------------------
0 [though, i, have, got, it, for, cheap, price, ...
1 [i, purchased, the, 7, for, my, son, when, he,...
2 [great, price, and, great, batteries, i, will,...
3 [great, tablet, for, kids, my, boys, love, the...
4 [they, lasted, really, little, some, of, them,...
Name: tokens, dtype: object# word_count 함수를 사용하여 단어의 분포를 나타내어 봅시다.
wc = word_count(df['tokens'])
wc.head()
-------------------------------------------------------
word word_in_docs count rank percent cul_percent word_in_docs_percent
51 the 4909 10514 1.0 0.039229 0.039229 0.468282
1 and 5064 8137 2.0 0.030360 0.069589 0.483068
26 i 3781 7465 3.0 0.027853 0.097442 0.360679
124 to 4157 7150 4.0 0.026678 0.124120 0.396547
19 for 4477 6617 5.0 0.024689 0.148809 0.427072SpaCy로 토큰화 한 문장에 대하여 등장 비율 상위 20개 단어의 결과를 시각화하면 다음과 같다.
wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6 )
plt.axis('off')
plt.show()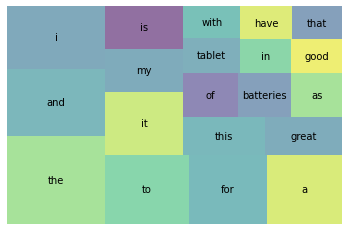
불용어(Stop words) 처리
위의 사진을 보면 i,and,of같은 제품 리뷰를 이해하는데 별 도움이 되지 않는 단어들이 높은 등장 비율을 가지고 있는 것을 볼 수 있다. 이런 것들을 Stop words(불용어)라고 한다. 다시 말하면 자주 등장하지만 분석 하는 것에 있어서 큰 도움이 되지 않는 단어들을 의미한다.
따라서 분석 시 해당 단어를 제외하고 진행한다. 대부분의 NLP 라이브러리는 접속사, 관사, 부사, 대명사, 일반동사 등을 포함한 일반적인 불용어를 내장하고 있다. 다음과 같은 명령어로 불용어를 확인할 수 있다.
print(nlp.Defaults.stop_words)해당 불용어를 제외하고 토크나이징을 진행한 결과는 다음과 같다.
tokens = []
# 토큰에서 불용어 제거, 소문자화 하여 업데이트
for doc in tokenizer.pipe(df['reviews.text']):
doc_tokens = []
# A doc is a sequence of Token()
for token in doc:
# 토큰이 불용어와 구두점이 아니면 저장
if (token.is_stop == False) & (token.is_punct == False):
doc_tokens.append(token.text.lower())
tokens.append(doc_tokens)
df['tokens'] = tokens
df.tokens.head()
-----------------------------------------------------------------
0 [got, cheap, price, black, friday,, fire, grea...
1 [purchased, 7", son, 1.5, years, old,, broke, ...
2 [great, price, great, batteries!, buying, anyt...
3 [great, tablet, kids, boys, love, tablets!!]
4 [lasted, little.., (some, them), use, batterie...
Name: tokens, dtype: objectwc = word_count(df['tokens'])
wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6)
plt.axis('off')
plt.show()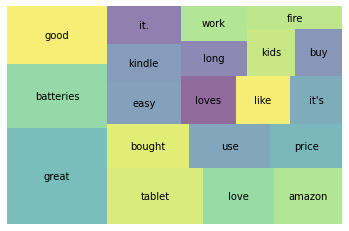
불용어들이 모두 제거가 되어 왼전히 다른 단어들이 상위에서 보이는 것을 확인할 수 있다.
그리고 불용어는 사용자가 직접 추가할 수도 있다. union이라는 메서드를 통해서 추가할 수 있다.
STOP_WORDS = nlp.Defaults.stop_words.union(['batteries','I', 'amazon', 'i', 'Amazon', 'it', "it's", 'it.', 'the', 'this'])tokens = []
for doc in tokenizer.pipe(df['reviews.text']):
doc_tokens = []
for token in doc:
if token.text.lower() not in STOP_WORDS:
doc_tokens.append(token.text.lower())
tokens.append(doc_tokens)
df['tokens'] = tokens
wc = word_count(df['tokens'])
wc.head()
---------------------------------------------------
word word_in_docs count rank percent cul_percent word_in_docs_percent
58 great 2709 3080 1.0 0.024609 0.024609 0.258418
14 good 1688 1870 2.0 0.014941 0.039549 0.161023
68 tablet 1469 1752 3.0 0.013998 0.053547 0.140132
64 love 1183 1287 4.0 0.010283 0.063830 0.112849
103 bought 1103 1179 5.0 0.009420 0.073250 0.105218wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6)
plt.axis('off')
plt.show()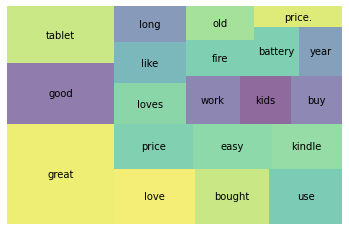
통계적 트리밍(Trimming)
불용어를 직접 제거하는 대신 통계적인 방법을 통해 말뭉치 내에서 너무 많거나, 너무 적은 토큰을 제거하는 방법도 있다. 단어들의 누적분포 그래프를 다시보면 다음과 같다.
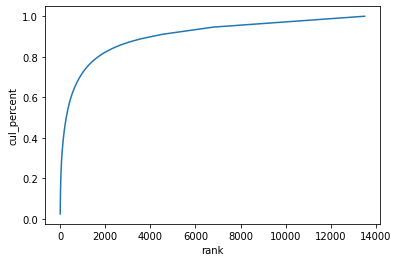
이 그래프에서 알 수 있는 것은 몇몇 소수의 단어들이 전체 말뭉치의 80%를 차지한다는 것이다. 그래프 결과에서 나타나는 단어의 중요도를 다음과 같이 두가지로 해석할 수 있다.
- 자주 나타나는 단어들 (그래프의 왼쪽)
여러 문서에 두루 나타나기 때문에 문서 분류 단계에서 통찰력을 제공하지 않는다. - 자주 나타나지 않는 단어들 (그래프의 오른쪽)
너무 드물게 나타나기 때문에 큰 의미가 없을 확률이 높다.
위의 가정을 바탕으로 랭크가 높거나 낮은 단어들을 제거하여 보겠다. describe()등의 함수로 값을 출력하는 것은 생략하고 그래프를 출력하고 제거하는 코드만 작성하였다.
# 문서에 나타나는 빈도
sns.displot(wc['word_in_docs_percent'],kind='kde')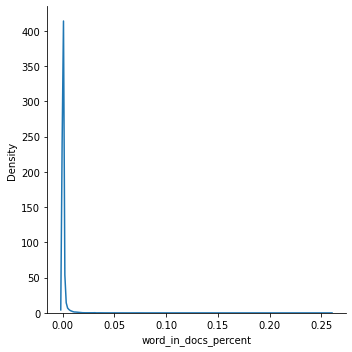
# 최소한 1% 이상 문서에 나타나는 단어들만 선택합니다.
wc = wc[wc['word_in_docs_percent'] >= 0.01]
sns.displot(wc['word_in_docs_percent'], kind='kde');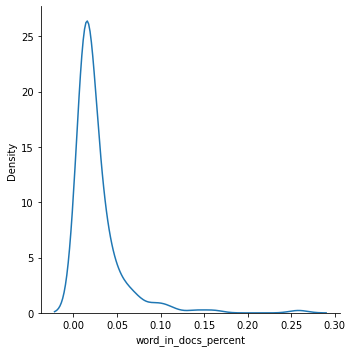
어간 추출(Stemming)과 표제어 추출(Lemmatization)
토큰화된 단어들을 보면 batteries, battery와 같이 어근(root)이 동일한 단어를 볼 수 있다. 이런 단어들은 어간 추출(stemming)이나 표제어 추출(lemmatization)을 통해 정규화(Normalization) 해주어 단어의 수를 줄일 수 있다.
어간 추출(Stemming)
어간(Stem)이란 단어의 의미가 포함된 부분으로 접사등이 제거된 형태이다. 이는 어근이나 단어의 원형과 같이 않을 수 있다. 예를 들자면 argue, argued, arguing, argus의 어간은 단어들의 뒷 부분이 제거된 argu가 어간이다. 어간 추출은 ing,ed,s 등과 같은 부분을 제거하게 된다.
Stemming 방법에는 Poter, Snowball, Dawson등의 알고리즘이 있다. 하지만 Spacy라이브러리는 Stemming을 제공하지 않고 Lemmatization만 제공한다. 그렇기 때문에 이번에는 nltk를 사용하여 Stemming을 제공하여 보겠다.
tokens = []
for doc in df['tokens']:
doc_tokens = []
for token in doc:
doc_tokens.append(ps.stem(token))
tokens.append(doc_tokens)
df['stems'] = tokens
wc = word_count(df['stems'])
wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6 )
plt.axis('off')
plt.show()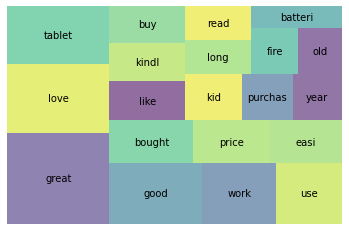
Stemming은 단어의 끝 부분을 자르는 역할을 하기 때문에 사전에 없는 단어가 많이 나오게 된다. 이상하긴 해도 현실적으로 사용하기에 성능이 나쁘지 않다. 알고리즘이 간단하여 속도가 빠르기 때문에 속도가 중요한 검색 분야에서 Stemming을 많이 사용한다.
표제어 추출(Lemmatization)
표제어 추출(Lemmatization)은 단어들의 기본 사전형 단어 형태인 Lemma(표제어)로 변환된다.
명사의 복수형은 단수형으로, 동사는 모두 타동사로 변환된다. 이렇게 단어들로부터 표제어를 찾아가는 과정은 Stemming보다 많은 연상이 필요하다.
Spacy를 통하여 Lemmatization을 진행해 보겠다.
# Lemmatization 과정을 함수로 구현
def get_lemmas(text):
lemmas = []
doc = nlp(text)
for token in doc:
if ((token.is_stop == False) and (token.is_punct == False)) and (token.pos_ != 'PRON'):
lemmas.append(token.lemma_)
return lemmas위 함수를 적용하여 텍스트 데이터 정규화를 진행한다.
df['lemmas'] = df['reviews.text'].apply(get_lemmas)
df['lemmas'].head()
------------------------------------------------------
0 [get, cheap, price, black, friday, fire, great...
1 [purchase, 7, son, 1.5, year, old, break, wait...
2 [great, price, great, battery, buy, anytime, n...
3 [great, tablet, kid, boy, love, tablet]
4 [last, little, use, battery, lead, lamp, 2, 4,...
Name: lemmas, dtype: objectwc = word_count(df['lemmas'])
wc_top20 = wc[wc['rank'] <= 20]
squarify.plot(sizes=wc_top20['percent'], label=wc_top20['word'], alpha=0.6 )
plt.axis('off')
plt.show()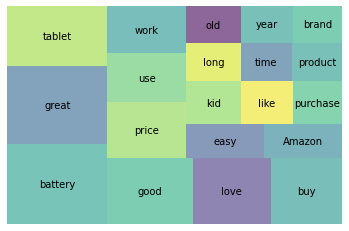
5. 등장 횟수 기반 단어표현(Count-based Representation)
등장 횟수 기반의 단어표현(Count-based Representation)은 단어가 특정 문서(혹은 문장)에 들어있는 횟수를 바탕으로 해당 문서를 벡터화한다.
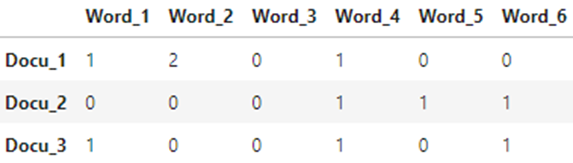
문서-단어 행렬(Document-Term Matrix, DTM)
벡터화 된 문서는 문서-단어 행렬(Document-Term Matrix, DTM)의 형태로 나타내어진다. 문서-단어 행렬이란 각 행에는 문서(Document)가, 각 열에는 단어(Term)가 있는 행렬이다. 대표적인 방법으로는 Bag-of-Words(TF, TF-IDF)방식이 있다.
TF(Term Frequency)
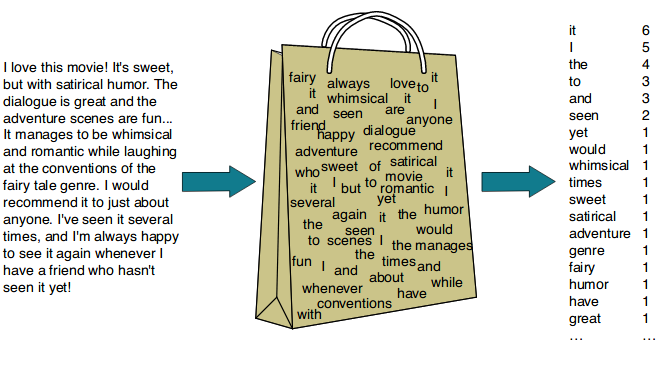
Bag-of-Words(BoW)는 가장 단순한 벡터화 방법 중 하나이다. 문서(혹은 문장)에서 문법이나 단어의 순서 등을 무시하고 단순히 단어들의 빈도만 고려하여 벡터화한다. 위의 사진처럼 단어를 넣어놓은 가방(Bag of Words)을 두고 각 문장에 어떤 단어가 몇 번 나오는지를 세어서 해당 값을 문장의 벡터로 사용한다.
사이킷런(Scikit-learn, Sklearn) 의 CounterVectorizer 를 사용하면 Bag-of-Words 방식의 벡터화를 사용할 수 있다.
# 모듈에서 사용할 라이브러리와 spacy 모델을 불러옵니다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.neighbors import NearestNeighbors
from sklearn.decomposition import PCA
import spacy
nlp = spacy.load("en_core_web_sm")# 예제로 사용할 text를 선언합니다.
text = """In information retrieval, tf–idf or TFIDF, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.
It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling.
The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word,
which helps to adjust for the fact that some words appear more frequently in general.
tf–idf is one of the most popular term-weighting schemes today.
A survey conducted in 2015 showed that 83% of text-based recommender systems in digital libraries use tf–idf."""# spacy의 언어모델을 이용하여 token화된 단어들을 확인합니다.
doc = nlp(text)
print([token.lemma_ for token in doc if (token.is_stop != True) and (token.is_punct != True)])
---------------
출력결과는 생략하였다. 토큰화된 단어들이 나오게 된다.from sklearn.feature_extraction.text import CountVectorizer
# 문장으로 이루어진 리스트를 저장합니다.
sentences_lst = text.split('\n')
# CountVectorizer를 변수에 저장합니다.
vect = CountVectorizer() # Stop_words나, max_features 등의 인자를 설정할 수 있다.
# 어휘 사전을 생성합니다.
vect.fit(sentences_lst)
# text를 DTM(document-term matrix)으로 변환(transform)
dtm_count = vect.transform(sentences_lst).vocabulary_메서드를 활용하면 vocabulary(모든 토큰)와 맵핑된 인덱스 정보를 확인할 수 있다.
vect.vocabulary_
-----------------
{'2015': 0,
'83': 1,
'adjust': 2,
'and': 3,
'appear': 4,
'appears': 5,
'as': 6,
'based': 7,
'by': 8,
:
:get_feature_names()를 사용하면 추출된 토큰을 볼 수 있으며, get_feature_names()메서드를 사용하면 추출된 토큰의 수를 알 수 있다. 사용 예시는 생략한다.
다음으로 dtm_count타입과 실제 출력을 살펴보겠다.
# CountVectorizer 로 제작한 dtm을 분석해 봅시다.
print(type(dtm_count))
print(dtm_count)
----------------------------------------------
<class 'scipy.sparse.csr.csr_matrix'>
(0, 9) 1
(0, 12) 1
(0, 14) 2
(0, 18) 1
(0, 19) 2
: :
: :dtm_count 의 타입을 보면 CSR(Compressed Sparse Row matrix) 로 나오게 된다. 해당 타입은 행렬(matrix)에서 0을 표현하지 않는 타입이다. dtm_count 를 출력한 결과에서도 (row, column) count 형태로 출력되는 것을 확인할 수 있다.
만일 그대로의 numpy.matrix타입으로 보고 싶을 경우에는 .todense()메서드를 통해서 확인할 수 있다.
print(type(dtm_count))
print(type(dtm_count.todense()))
dtm_count.todense()
----------------------------------
<class 'scipy.sparse.csr.csr_matrix'>
<class 'numpy.matrix'>
matrix([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 2, 0, 0, 0, 1, 2, 0,
0, 0, 1, 1, 1, 2, 0, 1, 1, 1, 3, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 2, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1,
0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0,
1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 2, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 0, 2, 1,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1,
6, 1, 1, 0, 0, 0, 0, 1, 0, 0, 2, 0],
[0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1,
1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1,
1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0,
0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0,
1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 2, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]])DataFrame으로 변환하여 확인하고 싶을 경우에는 다음과 같이 코드를 구성할 수 있다.
dtm_count = pd.DataFrame(dtm_count.todense(), columns=vect.get_feature_names())TF-IDF (Term Frequency - Inverse Document Frequency)
다른 문서에 등장하지 않는 단어. 즉, 특정 문서에만 등장하는 단어에 가중치를 두는 방법이 TF-IDF(Term Frequency-Inverse Document Frequency)이다.
수식은 다음과 같다.
TF(Term-Frequency)는 특정 문서에서 단어 w가 쓰인 빈도이다. 분석할 문서에서 단어가 등장하는 횟수를 구하게 된다.
IDF(Inverse Document Frequency)는 분류 대상이 되는 모든 문서의 수를 단어 가 들어있는 문서의 수로 나누어 준 뒤 로그를 취해준 값이다. 로그를 취해주는 이유는 지프의 법칙에 대해서 찾아보자.
이론적인 식은 위와 같지만 실제 계산에서는 0으로 나누어 주는 것을 방지하구 위하여 분모에 1을 더해준 값을 사용한다. 분류 대상이 되는 모든 문서의 수(단어 가 들어있는 문서의 수)를 라 하면 IDF는 다음과 같이 구해진다.
위 식에 따라 자주 사용하는 단어라도, 많은 문서에 나오는 단어들은 IDF가 낮아기 때문에 TF-IDF로 벡터화 했을 때 작은 값을 가지게 된다.
사이킷런(Scikit-learn, Sklearn) 의 TfidfVectorizer를 사용하면 TF-IDF벡터화도 사용할 수 있다.
# TF-IDF vectorizer. 테이블을 작게 만들기 위해 max_features=15로 제한하였습니다.
tfidf = TfidfVectorizer(stop_words='english', max_features=15)
# Fit 후 dtm을 만듭니다.(문서, 단어마다 tf-idf 값을 계산합니다)
dtm_tfidf = tfidf.fit_transform(sentences_lst)
dtm_tfidf = pd.DataFrame(dtm_tfidf.todense(), columns=tfidf.get_feature_names())
dtm_tfidf
TfidfVectorizer를 사용하여 생성한 문서-단어 행렬(DTM)의 값을 CountVectorizer를 사용하여 생성한 DTM의 값과 비교하여 보자.
vect = CountVectorizer(stop_words='english', max_features=15)
dtm_count_vs_tfidf = vect.fit_transform(sentences_lst)
dtm_count_vs_tfidf = pd.DataFrame(dtm_count_vs_tfidf.todense(), columns=vect.get_feature_names())
dtm_count_vs_tfidf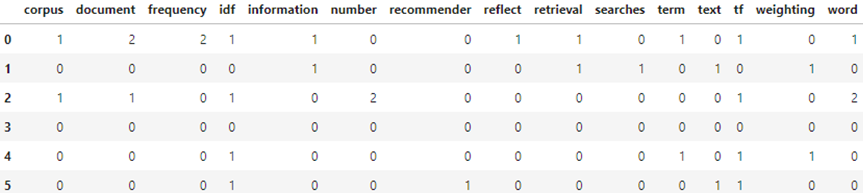
이번에는 하이퍼파라미터를 튜닝해보고, SpaCy tokenizer를 사용해서 벡터화를 진행하여 보겠다.
# SpaCy 를 이용한 Tokenizing
def tokenize(document):
doc = nlp(document)
return [token.lemma_.strip() for token in doc if (token.is_stop != True) and (token.is_punct != True) and (token.is_alpha == True)]
"""
args:
ngram_range = (min_n, max_n), min_n 개~ max_n 개를 갖는 n-gram(n개의 연속적인 토큰)을 토큰으로 사용합니다.
min_df = n : int, 최소 n개의 문서에 나타나는 토큰만 사용합니다.
max_df = m : float(0~1), m * 100% 이상 문서에 나타나는 토큰은 제거합니다.
"""
tfidf_tuned = TfidfVectorizer(stop_words='english'
,tokenizer=tokenize
,ngram_range=(1,2)
,max_df=.7
,min_df=3
)
dtm_tfidf_tuned = tfidf_tuned.fit_transform(df['reviews.text'])
dtm_tfidf_tuned = pd.DataFrame(dtm_tfidf_tuned.todense(), columns=tfidf_tuned.get_feature_names())
dtm_tfidf_tuned.head()
유사도를 이용한 문서 검색
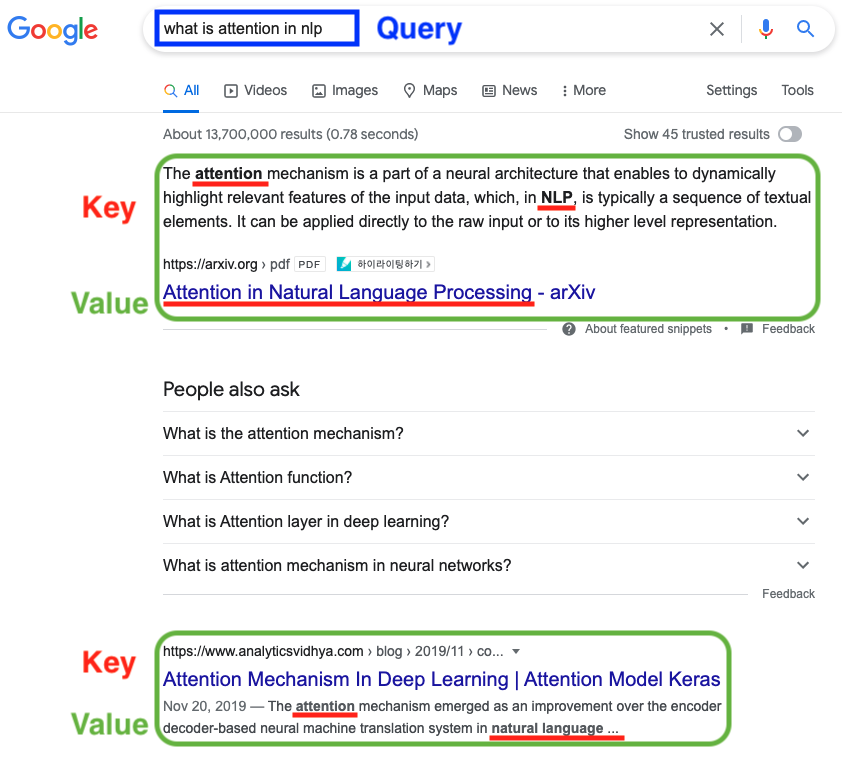
검색 엔진은 검색어(Query,쿼리)와 문서에 있는 단어(key,키)를 매칭(Matching)하여 결과를 보여준다. 매칭 방법에는 방법은 여러 가지가 있으나 이번에는 가장 클래식한 방법인 "유사도 측정 방법"을 시도해 보겠다.
코사인 유사도(Cosine Similarity)
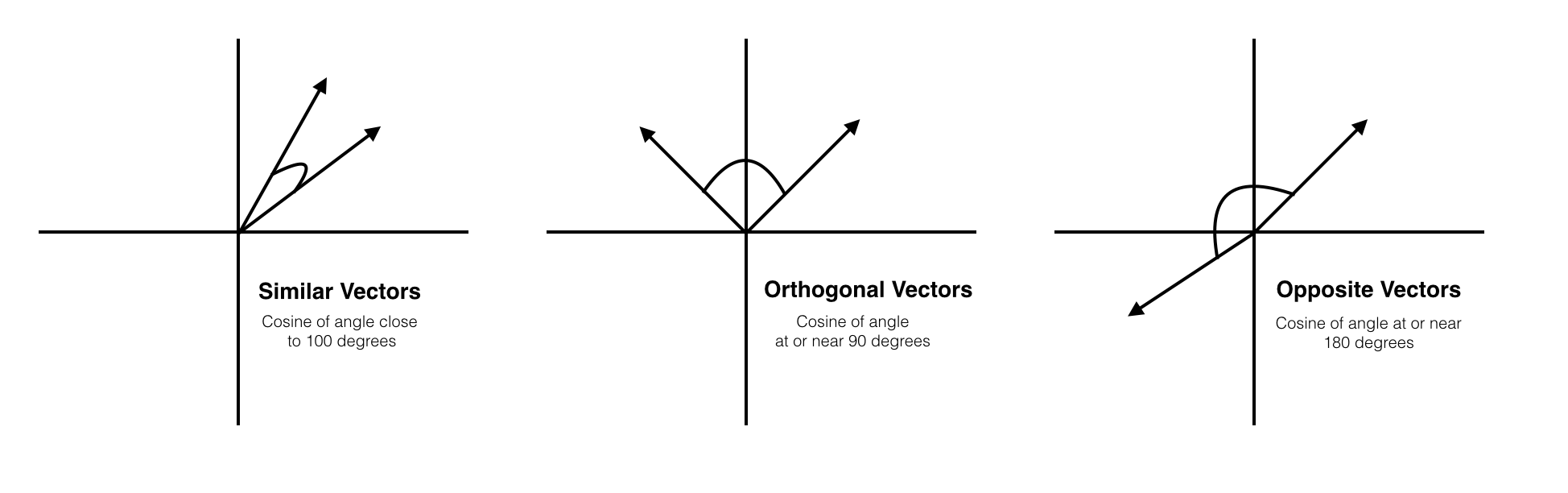
코사인 유사도는 가장 많이 쓰이는 유사도 측정방법이다. 두 벡터가 이루는 각의 코사인 값을 이용하여 구할 수 있는 유사도 이다.
- 완전히 같을 경우: 1
- 90도의 각을 이룰 경우: 0
- 완전히 반대방향일 경우: -1
NearestNeighbor(K-NN,K-최근접 이웃)
K-최근접 이웃법은 쿼리와 가장 가까운 상위 K개의 근접한 데이터를 찾아서 K개 데이터의 유사성을 기반으로 점을 추정하거나 분류하는 예측 분석에 사용된다. 사이킷런 sklearn의 NearestNeighbors를 사용하면 K-최근접 이웃 알고리즘을 사용할 수 있다.
from sklearn.neighbors import NearestNeighbors
# dtm을 사용히 NN 모델을 학습시킵니다. (디폴트)최근접 5 이웃.
nn = NearestNeighbors(n_neighbors=5, algorithm='kd_tree')
nn.fit(dtm_tfidf_amazon)
# 2번째 인덱스에 해당하는 문서와 가장 가까운 문서(0포함) 5개의 거리와 문서의 인덱스 출력
nn.kneighbors([dtm_tfidf_amazon.iloc[2]])
--------------------------------------------
(array([[0. , 0.64660432, 0.73047367, 0.76161463, 0.76161463]]),
array([[ 2, 7278, 6021, 1528, 4947]]))print(df['reviews.text'][2][:300])
print(df['reviews.text'][7278][:300])
-------------------------------------------------
Great price and great batteries! I will keep on buying these anytime I need more!
Always need batteries and these come at a great price문서 검색 예제
Amazon Review의 Sample을 가져와서 문서검색에 사용하여 보겠다.
# 출처 : https://www.amazon.com/Samples/product-reviews/B000001HZ8?reviewerType=all_reviews
sample_review = ["""in 1989, I managed a crummy bicycle shop, "Full Cycle" in Boulder, Colorado.
The Samples had just recorded this album and they played most nights, at "Tulagi's" - a bar on 13th street.
They told me they had been so broke and hungry, that they lived on the free samples at the local supermarkets - thus, the name.
i used to fix their bikes for free, and even feed them, but they won't remember.
That Sean Kelly is a gifted songwriter and singer."""]학습된 TfidfVectorizer를 통해 Sample Review를 변환하여 보겠다.
new = tfidf_vect.transform(sample_review)
nn.kneighbors(new.todense())
-------------------------------------------
(array([[0.69016304, 0.81838594, 0.83745037, 0.85257729, 0.85257729]]),
array([[10035, 2770, 1882, 9373, 3468]]))# 가장 가깝게 나온 문서를 확인합니다.
df['reviews.text'][10035]
-------------------------------
"Doesn't get easier than this. Good products shipped to my office free, in two days:)"회고
어렵다. 너무 어렵다. 다루는 코드도 많아지고 방식들도 다양해지다보니까 머리에 잘 들어오지 않는 것 같다. 설상가상으로 코로나도 걸려서 집중도 잘 안되는 것 같다. 빨리 정신차리고 복습해야하는데 그게 잘 안되는 것 같다. 코로나로 몸이 힘든 것도 맞는데 좋은 핑계가 생겨서 게임하고, 유튜브보고 딴 짓을 너무 많이 하는 것 같다. 정신차리자.... 설날에 공부 좀 해야겠다.
❗ 참고자료
1. 자연어 생성
2. 말뭉치
3. 문서
4. 품사 태깅(POS tagging)
5. 개체명 인식(Named Entity Recognition)
6. 토큰화(Tokenization)
