❗️ 화이트 모드 권장
학습목표
- 중요한 자료구조인 Hash Table에 대해 학습한다.
- N531~N534의 방향은 기본적인 자료구조를 활용하여 다양한 프로그램을 위한 자료구조와 알고리즘에 대해서 익힌다.
💡 해시테이블(Hash Table)이란?
해시 테이블은 Key(키)를 활용하여 Value(값)에 직접 접근이 가능한 자료구조를 의미한다.
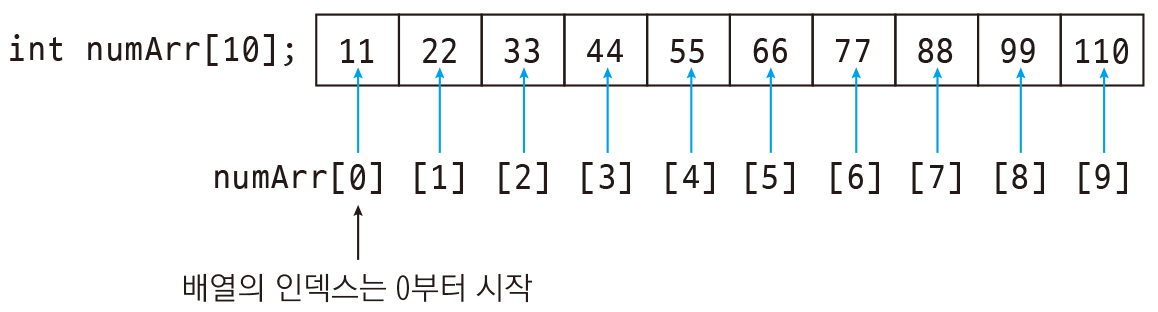
만일 정렬된 배열(array)에서 원소를 추가한다고 생각해보자. 원소의 수는 12개이고(이미지에서는 보이지 않는 공간이 있다고 생각), 앞에서부터 10개의 데이터가 오름차순으로 저장되어 있다. 여기에 만일 70을 추가한다고하면 과정은 다음과 같다.
- index 5번과 6번 사이에 값이 추가되도록 이진 검색법을 사용하여 검사
- 6번 이후의 모든 원소를 한 칸씩 뒤로 이동.
- 6번 인덱스에 70 대입
원소가 이동하는데 필요한 복잡도는 이고 그 비용은 결코 작지한다. 물론 데이터를 삭제하는 경우에도 똑같은 비용이 발생하며, 이런 프로세스는 파이썬에서 pop()을 사용할 때 ()안에 숫자를 넣게 되면 실행시간이 달라지는 이유이다.
해시법(Hashing)
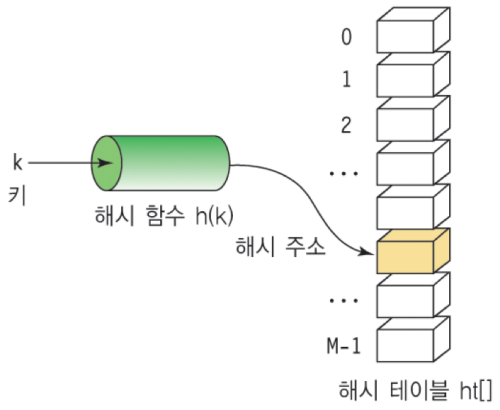
위에서 나타난 배열의 인덱스를 하나씩 미루어서 바꾸고 다시 데이터를 삽입하는 과정없이 바로 데이터를 넣기 위해 만들어진 방법이 해시법(Hashing)이다.
해시법은 "데이터를 저장할 위치 = 인덱스"를 간단한 연산으로 구하는 것을 말한다. 이 방법을 이용한다면 원소의 검색뿐 아니라 추가, 삭제도 효율적으로 수행할 수 있다. 정렬알고리즘과는 다르게 값을 정렬할 필요없이 해시함수(Hash Function)을 통해 해시값(Hash value)을 얻어서 값을 검색하는 것이 목적이다.
해시함수(Hash Function)는 말그대로 함수로, 나누기 연산 등 다양한 방식으로 구현할 수 있다. 이런 방식으로 값을 저장하면 원소를 이동할 필요없이 해시함수를 통해 출력된 해시값을 통해 저장된다. 그리고 이렇게 저장되어 만들어진 원소들을 Bucket이라고 한다.
그리고 이런 해시법을 이용하여 만들어진 자료구조를 Hash Table이라고 한다.
파이썬의 Dictionary는 내부적으로 해시테이블 구조로 구현되어 있다. 해시 테이블은 검색을 위한 역할도 하고, 딕셔너리르 위한 자료구조의 역할도 수행한다.
📌 중간정리
- 해시(Hash)는 해시 함수를 통해 나온 값이다.
- 해시테이블은 키를 빠르게 저장 및 검색할 수 있는 테이블 형태의 자료구조이다.
- 해시함수는 여러 키를 분할하기 위해 키를 해시값(정수값)으로 매칭시키는 역할을 한다.
- 해싱(Hashing)은 쉽게 말해서 다 흩뜨려놓고, 키와 매칭되는 값을 검색하는 과정이다.
파이썬의 딕셔너리, 리스트와 튜플을 이용하여 해시테이블을 작성해보자.
import time
# case 1 - 딕셔너리로 활용되는 해시테이블을 확인할 수 있다.
test_dict = {i:chr(i) for i in range(1,91)}
time_1 = time.time()
print(test_dict[33])
print(test_dict[38])
print(test_dict[90])
time_2 = time.time()
time_interval = time_2 - time_1
print(time_interval)# case 2 - 리스트와 튜플을 활용해서 해시테이블을 확인한다.
test_list = [(i,chr(i)) for i in range(1,91)]
def insert(item_list, key, value):
item_list.append((key, value))
def search(item_list, key):
# 데이터를 검색하려면 딕셔너리보다 오래 걸린다.(키, 값 쌍이 없어서 개별 값으로 반복해서 검색하기 때문이다.)
for item in item_list:
if item[0] == key:
return item[1]
print('not matching')
time_1 = time.time()
print(search(test_list, 33))
print(search(test_list, 38))
print(search(test_list, 90))
time_2 = time.time()
time_interval = time_2 - time_1
print(time_interval)해시함수(Hash Function)

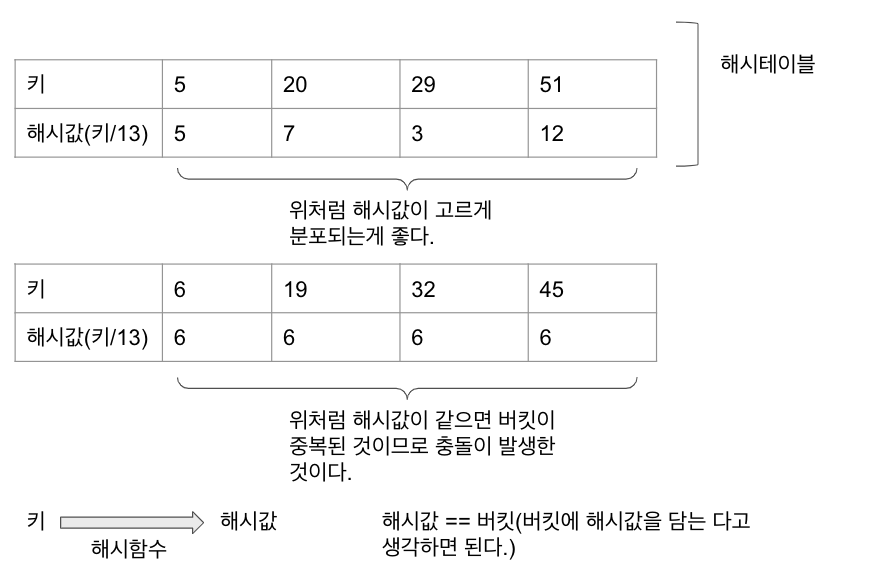
- 위의 그림처럼 해시함수는 키를 해시테이블 내의 버킷(=Hashes=해시값)으로 매핑시킨다.
- 해시함수: 입력값의 형태는 다양하고, 출력값의 형태는 정수이다.
- 해수함수 요구조건:
- 해시함수는 입력값이 같다면, 동일한 출력값을 받아야 한다.
- 입출력값이 일정하지 않다면 적절한 해시함수가 아니다.
- 예를 들어, 입력값 'aqua'가 4를 반환한다면, 입력값 'beige'는 4를 반환할 수 없다.
하지만 같은 경우가 출력될 수도 있는데 이를 해시충돌**이라고 한다.
- 해시함수는 특정 범위 안에 있는 숫자를 반환해야 한다.
- 하나의 해시함수가 입력 데이터별로 다른 숫자와 매핑된다면, 그것은 완벽한 해시함수이다.
- 해시함수가 입력데이터에 따라 다른 숫자를 반환하게 되면 해시충돌을 최소화하는 것이다.
해시함수는 보통은 문자열 입력값에 정수형 출력값을 반환한다. 정수형에서 문자열로 변환하기 위해서, 해시함수는 문자열에 해당하는 개별적인 단어를 활용한다.
다음 예시는 파이썬에서 encode()메소드를 활용하여 문자열에서 바이트 코드로 인코드하는 것이다. 인코딩 된 후에 정수형은 각 단어를 나타낸다.
# 인코딩 예제
bytes_representation = "hello".encode()
for byte in bytes_representation:
print(byte)
----
>
104
101
108
108
111이제 정수값의 합을 반환하는 방법을 활용하여 여러개의 정수들을 하나의 문자열로 변환하여보자.
# 정수값의 합 반환
bytes_representation = "hello".encode()
sum = 0
for byte in bytes_representation:
sum += byte
print(sum)
----
> 534# 해시함수를 만들고 활용해보자.
def my_hashing_func(str, list_size):
bytes_representation = str.encode()
sum = 0
for byte in bytes_representation:
sum += byte
return sum % list_size
print(my_hashing_func('hello',5))
----
> 2위의 해시함수를 활용하는 예시를 더 보여주면 다음과 같다.
먼저 5개의 빈 슬롯이 들어가는 리스트를 초기화 시킨 후 리스트에 있는 적합한 인덱스에 색상 이름 문자열이 매핑되기 위해 해시함수를 사용하며, 인덱스에 해당 헥사코드값을 저장하면 해시함수를 사용하여 값을 검색할 수 있다.
# 위의 my_hashing_func이라는 해시함수를 활용하여 아래처럼 값을 확인할 수 있다.
my_list = [None] * 5
# 해시테이블 값을 입력
my_list[my_hashing_func("aqua", len(my_list))] = "#00FFFF"
# 해시테이블 있는 값을 출력
print(my_list[my_hashing_func("aqua", len(my_list))])
# 전체 해시테이블 출력
print(my_list)
---
#00FFFF
[None, None, None, None, '#00FFFF']좋은 해시함수란?
- 해시함수를 어떻게 구현하는지에 따라서 해시의 성능이 결정된다.
- 좋은 해시함수의 조건
- 키와 값의 계산과정이 쉬워야 한다.
- 충돌을 피할 수 있어야 한다.
- 해시함수는 가능한 해시값의 전체 집합에 데이터를 균일하게 배포한다.
- 해시함수는 유사한 문자열에 대해 다른 해시값을 생성한다.
해시성능
해시테이블 자체는 해시충돌을 해결해주지는 않는다.
만일 해시충돌로 인해서 모든 Bucket의 Value를 찾아야해서 반복문이 필요한 경우를 제외하고는 해시테이블 자체는 시간복잡도 안에 검색, 삽입, 삭제를 할 수 있다. 검색/삽입/삭제 무엇을 하든지 해시함수는 키를 통해 저장된 값에 연관된 인덱스를 반환하기 때문이다.
해시충돌
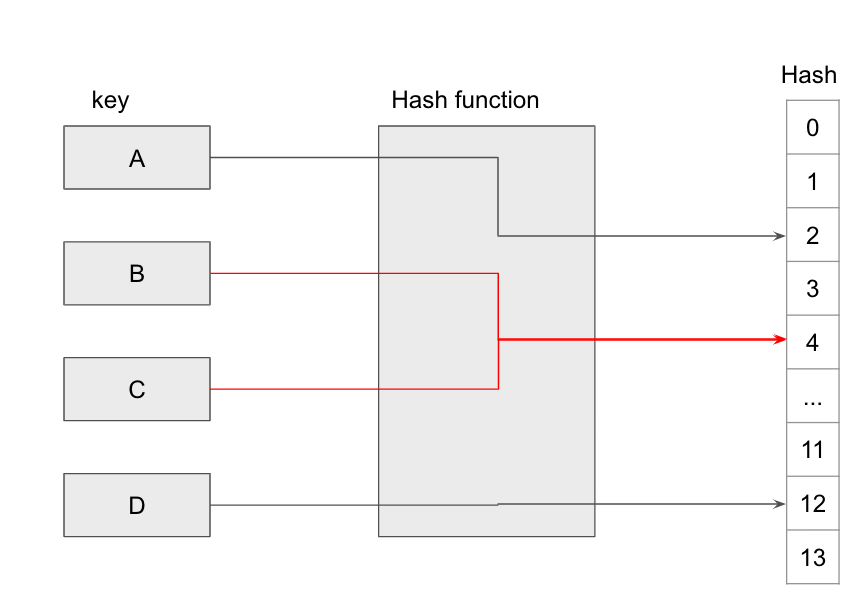
일반적인 경우에서 모든 입력에 대해서 1:1로 대응되는 해시함수는 존재하지 않는다. 일반적으로는 n:1의 관계이다. 이처럼 저장할 버킷이 중복되는 현상을 충돌(Collision)이라고 한다. 그리고 이런 충돌이 가장 적은 해시함수를 만드는 것이 해시테이블의 가장 중요한 목적이다.
그리고 이런 충돌이 발생하는 경우 다음 2가지 방법으로 대처할 수 있다.
1. 체인법(Chaining): 해시값이 같은 원소를 연결 리스트로 관리
2. 오픈 주소법(Open adressing): 빈 버킷을 찾을 때까지 해시를 반
체인법(Chaining)
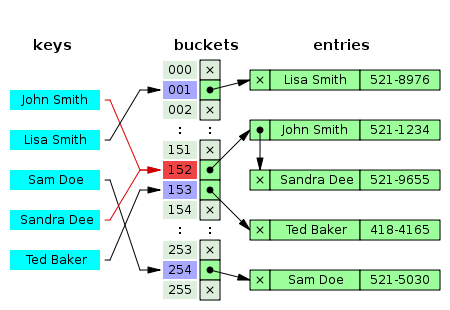
체인법은 해시값이 같은 데이터를 체인(chain)모양의 연결 리스트로 연결하는 방법을 말하며 오픈 해시법(Open hashing)이라고도 한다.
해시테이블에서 동일한 해시값에 대해 충돌이 일어나면, 그 위치에 있던 버킷에 키값을 뒤이어 연결한다. 데이터의 형태는 위의 그림처럼 연결리스트의 형태를 갖게 된다.
💡 Chaining의 원리
1. 키의 해시값을 계산한다.
2. 해시값을 이용해 리스트의 인덱스를 구한다.
3. 같은 해시값이 있다면(충돌한다면) 리스트로 연결한다.
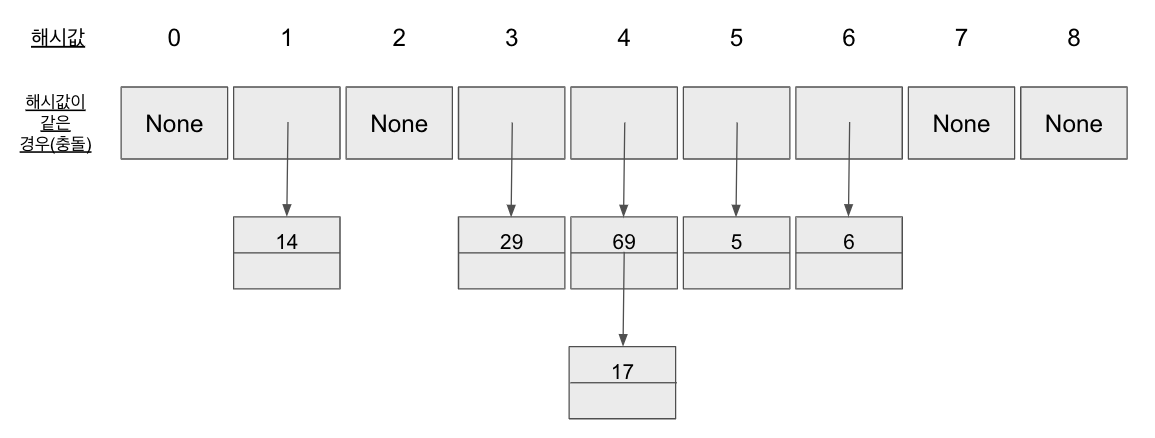
위의 그림은 나누기 방법(Division method)을 사용한 것인데, 나누기 방법은 쉽기 때문에 많이 사용되는 기본적인 해시함수로서 키값이 정수로 가정된다. 위 그림에서 해시함수의 공식은 이다. 69와 17 두 수 모두 13으로 나눈 나머지가 4이기 때문에 해시값 4에서 충돌이 발생하여 체이닝을 통해 연결되는 것을 확인할 수 있다.
# 체이닝을 예시코드로 배워보자.
# 아래와 같이 리스트안에 중첩되는 리스트를 만들어서 연결개념으로 해시테이블을 생성한다.
chain_hash_table = [[] for _ in range(10)] # 이번에는 10의 길이로 테스트를 진행한다.(0~9, 총 10개의 인덱스)
print(chain_hash_table)
---
> [[], [], [], [], [], [], [], [], [], []]# 해시함수는 위와 동일하게 테스트할 수 있다.
def chain_hash_func(key):
return key % len(chain_hash_table)
print(chain_hash_func(10))
print(chain_hash_func(20))
print(chain_hash_func(25))
---
>
0
0
5# append를 활용해서 키-값 쌍을 해시테이블에 삽입한다.
def chain_insert_func(chain_hash_table, key, value):
hash_key = chain_hash_func(key)
chain_hash_table[hash_key].append(value)
chain_insert_func(chain_hash_table, 10, 'A')
print(chain_hash_table)
chain_insert_func(chain_hash_table, 25, 'B') # 5번째 인덱스에 B가 삽입된다.
print(chain_hash_table)
# 아래 결과값과 같이 중첩되는 결과값이 있더라도 값이 대체(충돌)되는 것이 아니다.
# 리스트 메소드 개념(list.append)이 활용되어 값을 이어 붙인다.('A' -> 'C')
chain_insert_func(chain_hash_table, 20, 'C')
print(chain_hash_table)
---
[['A'], [], [], [], [], [], [], [], [], []]
[['A'], [], [], [], [], ['B'], [], [], [], []]
[['A', 'C'], [], [], [], [], ['B'], [], [], [], []]위의 코드는 체인법의 개념을 초기에 이해하기에 좋은 예시코드이다. 실제로 Class와 함수를 이용하여 체인법을 구성하면 다음과 같이 구성할 수 있다.
from __future__ import annotations # 변수의 type에 대한 주석
from typing import Any, Type # 타입힌트를 지원하는 모듈
import hashlib # 문자열을 해싱할 때 사용하는 모듈구현 시 사용할 라이브러리들이다. 대체로 어노테이션과 관련된 라이브러리로 타입힌트 등을 사용하지 않으면 hashlib라이브러리를 제외하고 사용하지 않아도 이상이 없을 것으로 예상한다.
class Node:
'''해시를 구성하는 노드'''
def __init__(self, key:Any, value: Any, next: Node) -> Node:
'''초기화'''
self.key = key #키
self.value = value # 값
self.next = next # 뒤쪽 노드를 참조Node 클래스는 개별 버킷을 나타낸다. Node 클래스는 키와 값이 짝을 이루는 구조이다. 키에 해시 함수를 적용하여 해시값을 구한다.
class ChainedHash:
"""
체인법으로 해시 클래스 구현
"""
def __init__(self, capacity: int)-> None:
'''초기화'''
self.capacity = capacity # 해시 테이블의 크기를 지정
self.table = [None]*self.capacity # 해시 테이블(리스트)를 선언
def hash_value(self, key: Any) -> int:
'''해시값을 구함'''
if isinstance(key, int):
return key % self.capacity
return(int(hashlib.sha256(str(key).encode()).hexdigest(), 16) % self.capacity)
def search(self, key:Any) -> Any:
hash = self.hash_value(key) # 검색하는 키의 해시값
p = self.table[hash] # 노드를 주목
while p is not None:
if p.key == key:
return p.value # 검색 성공
p = p.next # 뒤쪽 노드를 주목
return None
def add(self, key:Any, value:Any) -> bool:
'''키가 key이고 값이 value인 원소를 추가'''
hash = self.hash_value(key)
p = self.table[hash]
while p is not None:
if p.key == key:
return False # 추가실패
p = p.next
temp = Node(key, value, self.table[hash]) # self.table[hash]는 None이 된다.
self.table[hash] = temp # 노드를 추가
return True
def removes(self, key:Any) -> bool:
'''키가 key인 원소를 삭세'''
hash = self.hash_value(key)
p = self.table[hash]
pp = None
while p is not None:
if p.key == key:
if pp is None:
self.table[hash] = p.next
else:
pp.next = p.next
return True # key 삭제 성공
pp = p
p = p.next # 뒤쪽 노드를 주목
return False # 삭제 실패(key가 존재하지 않음)그리고 각각의 기능을 클래스에 구현하여 주었다. 다른 설명은 제외하고 hash_value함수의 key가 int형이 아닌 경우에 대해서 설명하겠다.
Key가 정수가 아닌 경우에는 그 값으로는 바로 나눌 수 없다. 그래서 sha256알고리즘, encode()함수, hexdigets()함수, int()함수 등의 표준 라이브러리로 형 변환을 해야 해시값을 얻을 수 있다.
- sha256 알고리즘
hashlib모듈에서 제공하는 sha256은 RSA의 FIPS알고리즘을 바탕으로 하며, 주어진 바이트(byte) 문자열의 해시값을 구하는 해시 알고리즘의 생성자(Constructor)이다. Hashlib모듈은 sha256외에도 MD5 알고리즘인 md5 등 다양한 해시 알고리즘을 제공한다.- encode( )함수
hashlib.sha256에는 바이트 문자열의 인수를 전달해야 한다. 그래서 Key를 str형 문자열로 변환한 뒤 그 문자열을encode()함수에 전달하여 바이트 문자열을 생성한다.- hexdigest( )함수
sha256알고리즘에서 해시값을 16진수 문자열로 꺼낸다.- int(문자열,16) 함수
hexdigest()함수로 꺼낸 문자열을 16진수 문자열로 하는 int형으로 변환한다.
만일 위에서 원소를 출력하여 보고 싶다면 다음과 같은 함수를 추가하면 된다.
def dump(self) -> None:
for i in range(self.capacity):
p = self.table[i]
print(i, end="")
while p is not None:
print(f' -> {p.key}({p.value})', end ="")
p = p.next
print()다음과 같이 객체를 생성하여 테스트하면 다음과 같이 출력된다.
hash_table = ChainedHash(13)
hash_table.add(1, 14)
hash_table.add(3, 29)
hash_table.add(4, 69)
hash_table.add(9, 17)
hash_table.add(19, 5)
hash_table.add(6, 6)
hash_table.add("이것은 Key", 46)
hash_table.add(15, 20)
hash_table.add(23, 33)
hash_table.add("key", "value")
hash_table.dump()
---
0
1 -> 이것은 Key(46) -> 1(14)
2 -> 15(20)
3 -> 3(29)
4 -> 4(69)
5 -> key(value)
6 -> 6(6) -> 19(5)
7
8
9 -> 9(17)
10 -> 23(33)
11
12오픈 주소법(Open addressing)
해시 충돌이 발생할 때 해결하는 또 다른 방법으로 오픈 주소법open addressing이 있다. 오픈 주소법은 충돌이 발생했을 때 재해시rehashing를 수행하여 빈 버킷을 찾는 방법을 말하며 닫힌 해시법closed hashing이라고도 한다.
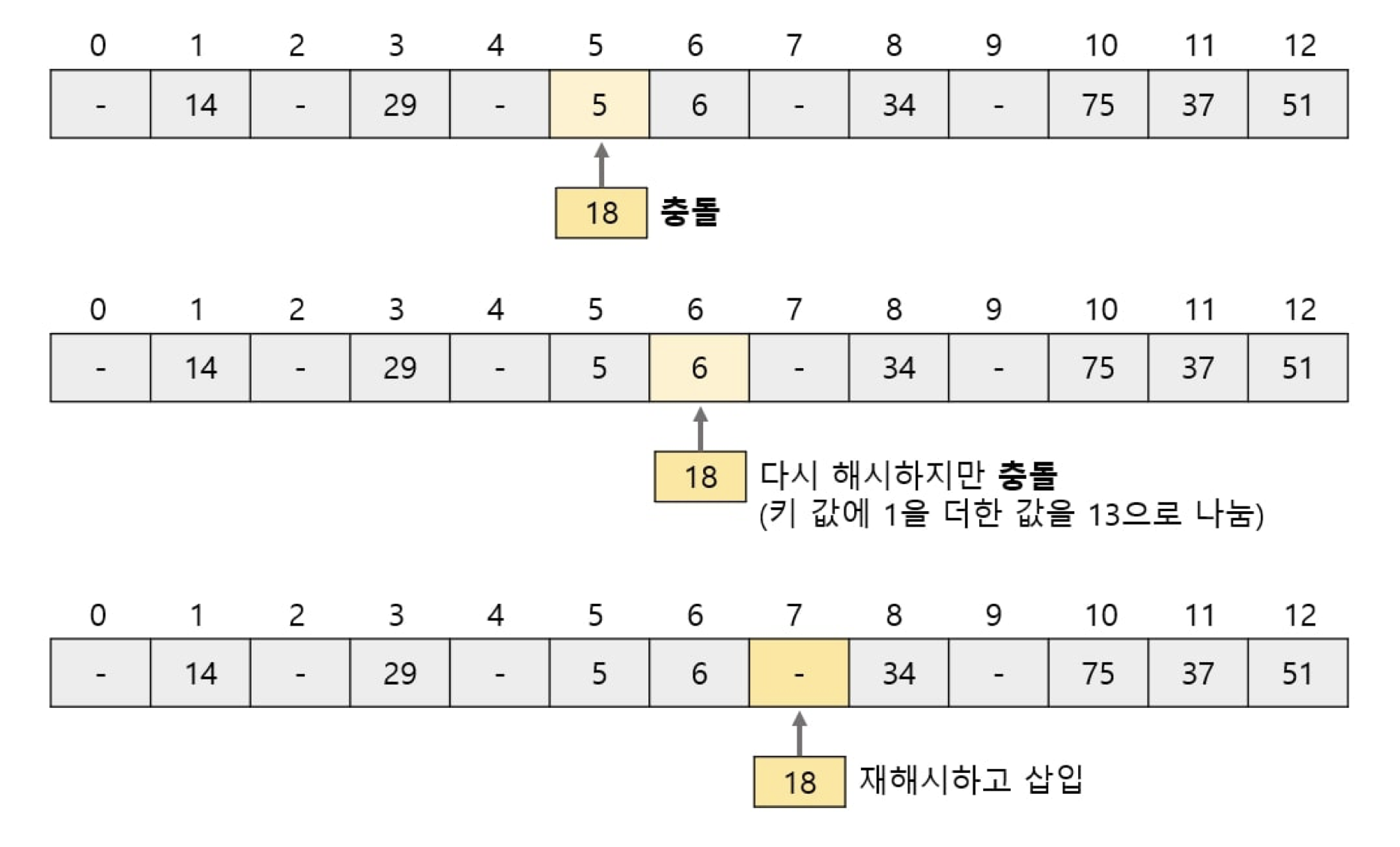
위의 그림처럼 오픈 주소법은 빈 버킷이 나올 때까지 재해시를 반복하므로 선형 탐사법linear probing이라고도 한다.
이처럼 재해시를 하게되면 원소를 삭제할 때 문제가 발생한다. 위의 그림의 가장 마지막 배열에서 5를 삭제한다고 가정해보자. 인덱스가 5인 버킷을 비우기만 하면 될 것 같지만 실제로는 그렇지 않다. 해시값이 같은 18을 검색할 때 해시값이 5인 데이터는 존재하지 않는다고 착각하여 검색에 실패하기 때문이다. 18이 재해시한 것으로 보이지만 해시함수 자체는 변하지 않기 때문에 방금 추가한 18의 해시값은 여전히 5이기 때문이다.
이러한 오류를 방지하기 위해서 각 버킷에 다음과 같은 속성을 부여한다.
- 데이터가 저장되어 있음(숫자)
- 비어 있음(-)
- 삭제 완료(⭐️)
속성이 부여되면 인덱스가 5인 버켓의 데이터가 삭제되도 삭제 완료라는 속성으로 인해서 재해시를 진행하여 검색하는 값이 나올 때까지 탐색하게 된다.
위의 그림에서도 알 수 있듯이 오픈 주소법은 체이닝과 다르게 저장공간이 정해져 있다.
❗️ 파이썬의 해시충돌 해결법은?
파이썬에서 해시테이블로 구현된 자료형은 딕셔너리(Dictionary)이다. 그렇다면 이 딕셔너리 자료형은 해시충돌이 발생했을 때 어떤 방식으로 해결할까?
파이썬의 경우 내부적으로 오픈 주소법 방식을 활용한다고 한다. 파이썬에서 오픈 주소법을 활용하기 때문에 빈 공간이 없는 경우 시간이 오래 걸릴 수 있다. 따라서 로드 팩터를 작게 설정하여 성능 저하 문제를 해결한다.
그렇다면 또 이런 의문이 들것이다. 이에 대해 찾아보니 공식문서 QnA에서 그저 크기 조정이 가능한 해시테이블로 구현한다고 나와있다. 여기서부터는 정확하지 않지만 어느 정도의 기본적인 크기를 지정하고 해시테이블이 모두 채워지면 더 많은 버킷을 가진 테이블을 새로 생성하는 것 같다.
Load Factor(로드 팩터)?
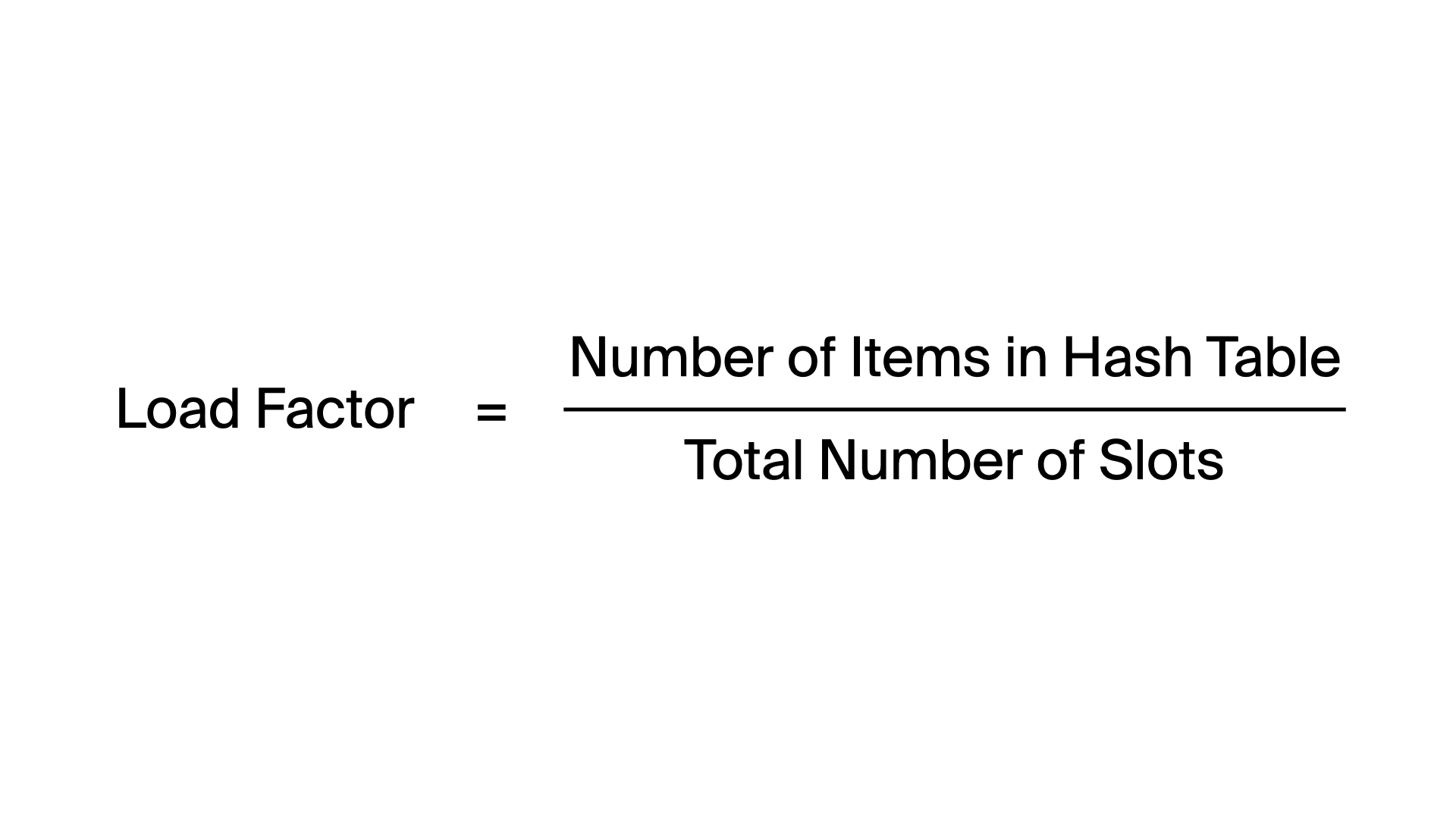
- 해시 테이블에 저장된 항목 수(해시 테이블에 입력된 키 갯수)를 슬롯 수(해시 테이블 전체 인덱스 갯수)로 나눈 값이다.
- 오픈 주소법을 사용하면 최대 로드 팩터는 1정도 나온다.
- 체이닝을 사용하면 로드 팩터는 오픈 주소법보다 좋은 성능(Load Factor <= 1)을 보일 수 있다. 하지만 체이닝 기법에 필요한 연결 리스트 구현에 큰 오버헤드가 요구된다.
- 로드 팩터를 낮추면 해시값이 비어있는 슬롯을 가르킬 확률이 높기 때문에 해시에 대한 성능이 올라간다.
- 위의 공식에 나와있는 방식으로 로드 팩터를 계산하여 비율에 따라 해시함수 재작성 여부, 해시테이블 크기 조정 여부가 결정된다.
- 로드 팩터값을 통해 해시 테이블의 성능정도를 파악할 수 있다.
- 하지만 어디까지나 대략적인 성능측정도구로 절대적이지 않다.
- 로드 팩터에는 해시 테이블의 상황, 입출력의 상황, 메모리에 적재되는 시간 등 영향을 주는 요소가 다양하다.
- 로드 팩터에서 발생할 수 있는 상대성을 고려하며 개념을 활용하기 보다 이러한 개념이 있다는 것을 인지하여야 한다.
💡 해시테이블의 다양한 실생활 사례
- 전화번호부(사람의 이름을 전화 번호에 매핑)
- DNS확인(웹 주소를 IP주소에 매핑)
- 학생 기록(고유한 학생 ID가 학생 정보에 매핑)
- 도서관 시스템(책의 고유 식별자가 자세한 책 정보에 매핑)
정리
❗️참고자료
1. 코드스테이츠 교육자료
2. 파이썬 딕셔너리(네이버 블로그)
3. 파이썬 공식문서
4. BohYoh Shibata, 옮긴이 강민, DO it! 자료구조와 함께 배우는 알고리즘 입문 파이썬 편, 서울:이지스퍼블리싱, 2022
