
이제 이 정리글을 TIL이라고 할 수 있는지 의문이다. 처음에 시작할 때 매일 꾸준히 정리하자는 의미에서 TIL을 사용했는데 이게 참 나라는 사람이 꾸준하지 못한 것 같다. N432도 분명 지난주에 배웠는데 주말이 지나고서야 정리를 시작한다.
ADsP자격증 시험도 신청했는데 허허허...그것도 지난주 목요일에 하루 공부하고 미루고 있다. 인터넷에 2주만에 따기 3일 공부하기 취득하기 이런 블로그 글들이 즐비하니까 뭔가 나도 할 수 있지 않을까 하는 생각에 마음이 느슨해지는 것 같다.
이번주 목요일부터는 다시 프로젝트 기간인데 그 전에는 컴퓨터 비전 쪽 노트는 다 정리해야지...
0. 학습목표
- Segmentation의 동작 방식 및 Semantic Segmentation/Instance Segmentation 을 구분하여 설명할 수 있다.
- Transpose Convolution의 필요성과 동작 방식에 대해 설명할 수 있다.
- 기존 모델을 사용하여 U-net 모델을 만든 코드를 이해하고 참고하여 다시 작성할 수 있다.
- Object Detection 의 2가지 방식과 지표에 대해 설명할 수 있다.
- Objection Detection 모델을 직접 구현한 코드를 보고 이해할 수 있다.
- U-net 을 직접 구현한 코드를 보고 이해할 수 있다.
- 여러 Object Detection 모델에 대해 알아보고 어떤 방식에 해당되는지 구분할 수 있으며 특정 모델의 적절한 예제를 선택하여 다른 데이터셋에 적용해 볼 수 있다.
1. Segmentation(분할)

분할(Segmentation)은 위 이미지와 같이 하나의 이미지에서 같은 의미를 가지고 있는 부분을 구분해내는 Task이다.
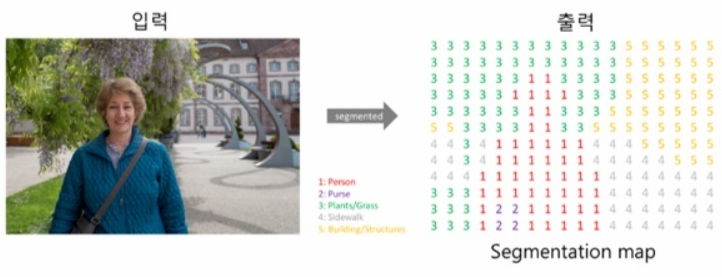
이미지 분류에서는 이미지를 하나의 단위로 레이블을 예측하였다면 Segmentation은 더 낮은 단위로 분류한다. 위의 이미지에서 볼 수 있듯이 동일한 의미마다 해당되는 픽셀이 모두 레이블링 되어있는 데이터셋을 픽셀 단위에서 레이블을 예측하게 된다.
이런 Segmentation에서 같은 의미를 가지는 개체들을 동일하게 라벨링을 하는지, 아니면 각 개체마다 다르게 라벨링을 하는지에 따라서 2가지로 나눌 수 있다. 바로 Semantic Segmentation과 Instance Segmentation이다.
Semantic Segmentation & Instance Segmentation
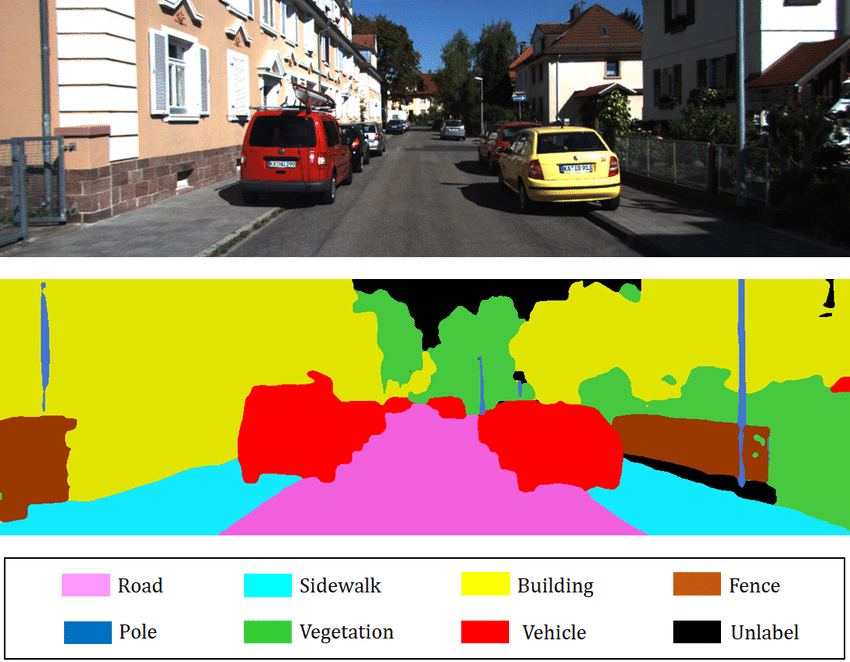
Semantic Segmentation에서 각 픽셀은 위의 그림에서 보는 것처럼 픽셀이 속한 객체의 클래스로 분류된다. 그리고 클래스가 같은 물체는 따로 구별하지 않는다. 예를 들자면 차종이 다 다르더라도 모든 자동차는 "자동차"라는 클래스로 분류되는 것이다.
이 픽셀을 분류하는 작업에 있어서 어려운 점은 이미지가 일반적인 CNN을 통과할 때 점진적으로 위치 정보를 잃는다는 것이다. 따라서 보통의 CNN은 이미지 왼쪽 아래 어딘가에 사람이 있다고 알 수 있지만 그보다 더 정확히 알지 못한다.
이 문제를 해결하기 위한 다양한 접근 방법이 있고 어떤 솔루션은 매우 복잡하다. 하지만 조너선 롱 등이 2015년 발표한 논문에서 매우 단순한 해결책을 제시하였다. 바로 Fully Convolutional Networks(FCN)이다. 이는 따로 아래에서 더욱 자세히 다루도록 하겠다.
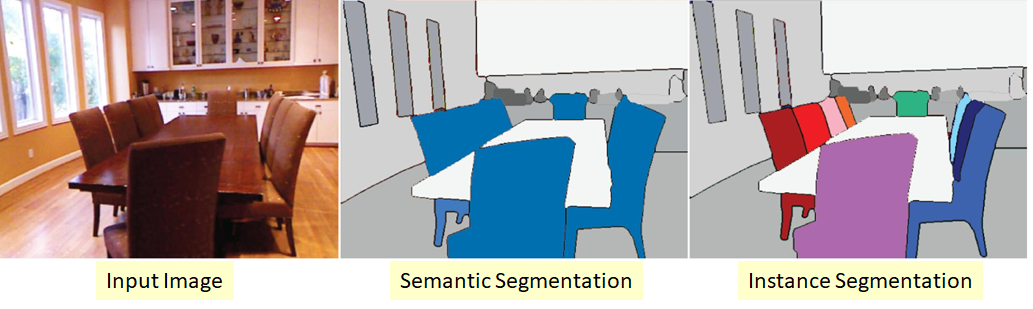
Instance Segmentation은 Semantic Segmentation과 비슷하지만 동일한 클래스 물체를 하나의 덩어리로 합치는 것이 아닌 각 물체를 구분하여 표시한다.
현재 텐서플로 모델 프로젝트에 포함된 인스턴스 분할 모델은 2017년 한 논문에서 제안된 Mask R-CNN이다. 이 모델은 Faster R-CNN모델을 확장하여 각 바운딩 박스에 대해 픽셀 마스크를 추가로 생성했다. 따라서 물체마다 클래스 추정 확률과 바운딩 박스를 얻는 것뿐만 아니라 바운딩 박스 안에 들어 있는 물체의 픽셀을 구분하는 픽셀 마스크도 얻을 수 있다.
2. Fully Convolutional Networks(FCN)
Fully Convolutional Networks(FCN)은 2015년 조너선 롱 등이 작성한 논문에서 처음 등장한 모델이다.
이 모델은 이미지 분류를 위한 신경망에 사용되었던 CNN의 분류기 부분, 즉 완전 연결 신경망(Fully Connected Layer)부분을 합성곱 층(Convolution Layer)로 대체한 모델이다.
앞서 말했듯이 Segmentation 은 픽셀 단위로 분류가 이루어지기 때문에 픽셀의 위치 정보를 끝까지 보존해주어야 한다. 하지만 CNN은 합성곱 층(Convolution Layer)을 통과할 때마다 이런 위치 정보를 잃게 된다. 이를 해결 하기 위해서 완전 연결 신경망(Fully Connected Layer)부분을 합성곱 층(Convolution Layer)로 대체한 것이다.
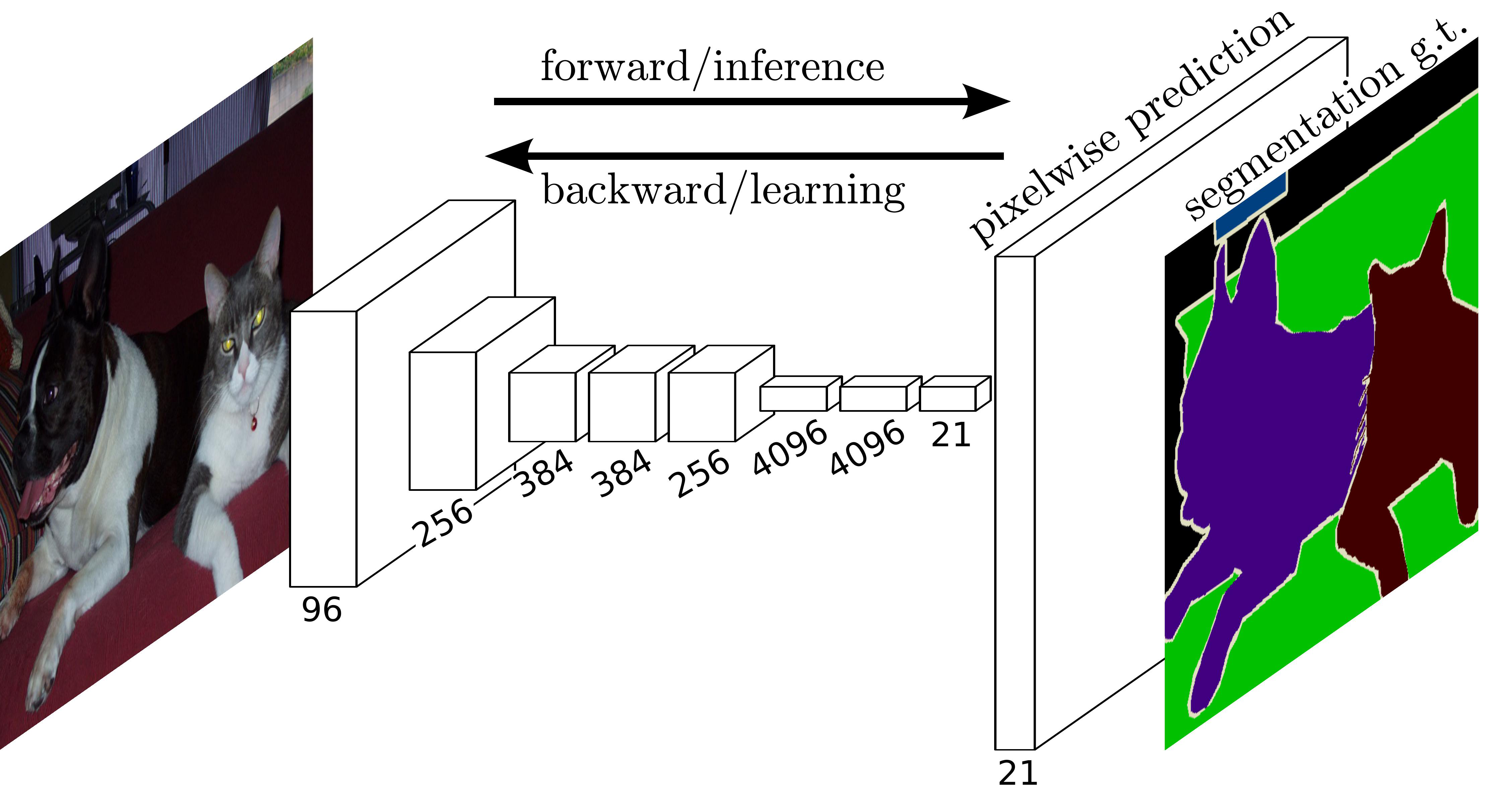
위 그림은 FCN의 구조를 도식화한 그림이다. 그림을 보면 이미지의 크기가 커지는 부분이 존재한다. 이는 Segmantation은 픽셀렬로 분류를 진행하기 때문에 마지막 층이 입력 이미지보다 작은 특성 맵을 출력한다. 이는 정보의 손실을 의미하기 때문에 원래 이미지와 비슷하게 크기를 키워주는(해상도를 늘리는) Upsampling을 해주어야 한다. 그리고 이런 Upsampling을 진행해주는 층을 Upsampling Layer라고 한다.
Upsampling
CNN에서 사용되는 것처럼 Convolution과 Pooling을 사용하여 이미지의 특징을 추출하는 과정을 Downsampling이라고 한다.
이와 반대로 원래 이미지 크기로 키우는 과정을 Upsampling(업샘플링)이라고 한다.
Upsampling에는 기존 Convolution과는 다른 Transpose Convolution이 적용된다. Transpose Convolution에서는 각 픽셀에 커널을 곱한 값에 Stride를 주어 나타냄으로써 이미지 크기를 키워나간다.
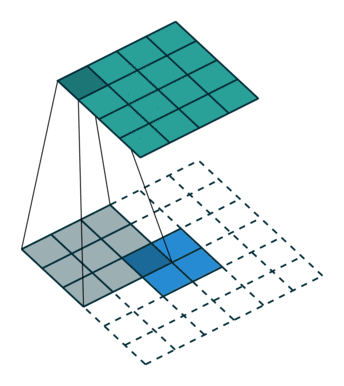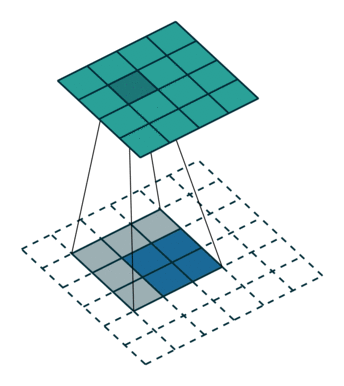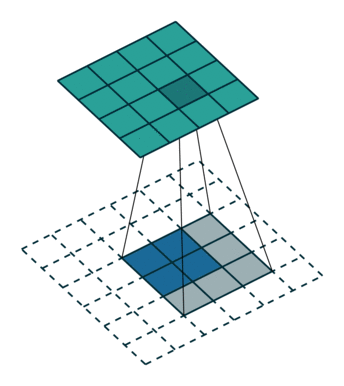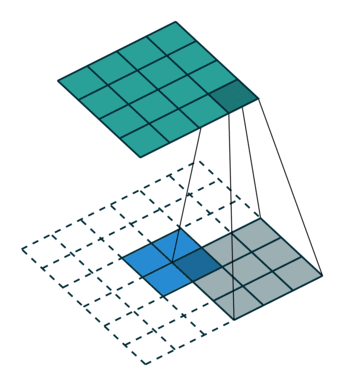
위는 2X2이미지가 입력되었을 때 3X3필터에 의하여 Transpose Convolution되는 과정을 나타낸 것이다.
3. U-Net
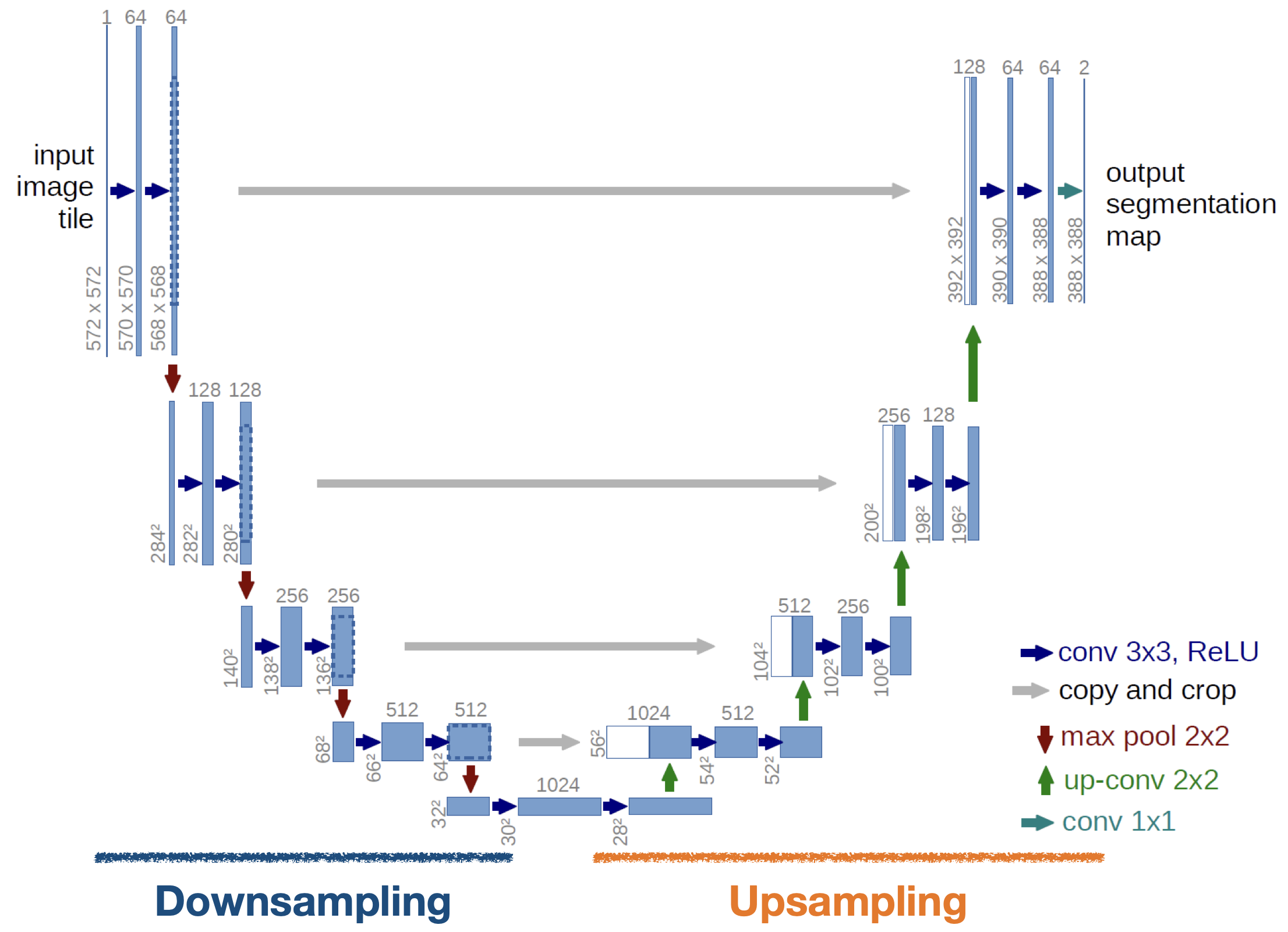
U-Net은 Biomedical분야에서 이미지 분할(Image Segmentation)을 목적으로 제안된 End-to-End방식의 FCN(Fully-Convolutional Network)기반 모델이다. 위의 이미지에서 볼 수 있듯이 네트워크의 구성 형태가 "U"자형 이라서 U-Net이라는 이름이 붙여졌다.
U-Net은 이미지의 전반적인 컨텍스트 정보를 얻기 위한 네트워크와 정확한 지역화(Localization)을 위한 네트워크가 대칭 형태로 구성되어 있다.
전반적인 컨텍스트 정보를 얻기 위한 네트워크는 Downsampling을 진행한다. 그리고 정확한 지역화를 위한 네트워크인 Expanding Path의 경우 Upsampling을 진행한다. Upsampling에서는 Convolution 과 Transpose Convolution을 거치면서 원본 이미지와 비슷한 크기로 복원한다.
다시 말하자면, Coarse Map(=Feature Map)에서 Dense Prediction을 얻기 위한 구조인 것이다. U-Net은 FCN(Fully convolutional network)을 토대로 확장한 개념이기 때문에 명확한 이해를 돕기 위해 우선적으로 FCN을 이해하는 것이 좋다.
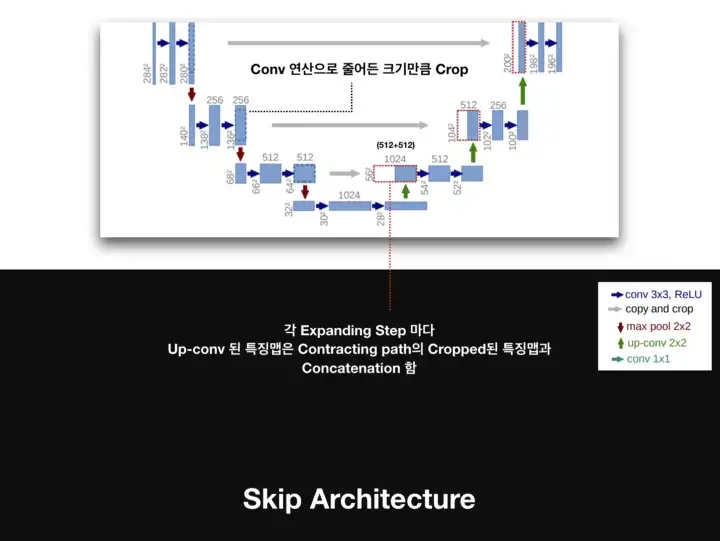
또한 Coarse Map to Dense Map 개념 뿐만 아니라 U-Net은 FCN의 Skip Architecture 개념도 활용하여 얕은 층의 특징맵을 깊은 층의 특징맵과 결합하는 방식을 제안하였다. 위의 U-Net이미지의 사진을 보면 Copy and Crop이라고 색인되어 있는 회색 선을 볼 수 있다. 바로 이 부분이 Skip Architecture이다.
이러한 CNN 네트워크의 특성 계층의 결합을 통해 Segmentation이 내제하는 Localization과 Context(Semantic Information) 사이의 트레이드 오프를 해결할 수 있다.
이제 Contracting Path(Downsampling)과 Expanding Path에 대해서 더 자세히 알아보자.
Contracting Path
- 3X3 Convolutions을 두 차례씩 반복(패딩 없음)
- 활성화 함수는 ReLU 이용
- 2X2 max-pooling, 이때
stride는2 - Down-sampling 마다 채널의 수를 2배로 늘림
Expanding Path
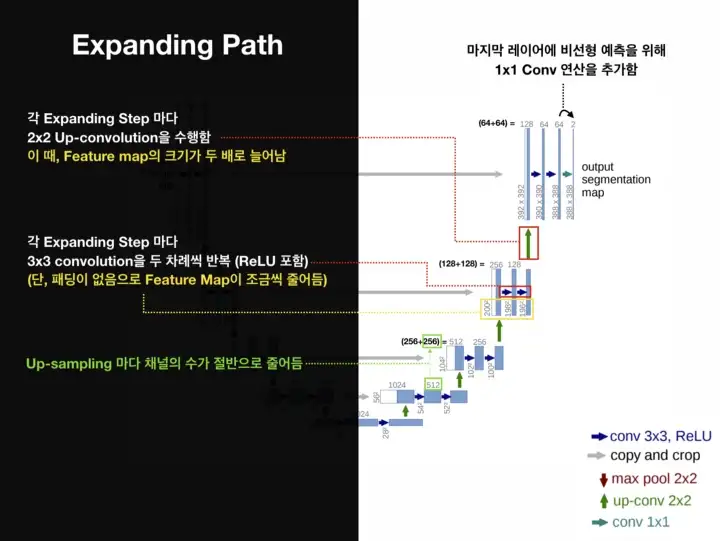
Expanding Path는 Contracting Path와 반대의 연산으로 특징맵을 확장한다.
- 2x2 convolution (“up-convolution”)
- 3x3 convolutions을 두 차례씩 반복 (패딩 없음)
- Up-Conv를 통한 Up-sampling 마다 채널의 수를 반으로 줄임
- 활성화 함수는 ReLU
- Up-Conv 된 특징맵은 Contracting path의 테두리가 Cropped된 특징맵과 concatenation 함
- 마지막 레이어에 1x1 convolution 연산
위와 같은 구성으로 총 23-Layers Fully Convolutional Networks구조이다. 주목해야하는 점은 최종출력인 Segmentation Map의 크기는 Input Image크기보다 작다는 것이다. Convolution연산에서 패딩을 사용하지 않았기 때문이다.
U-Net 정리에 있어서 이미지와 많은 글들을 아래 참고자료의 3번 블로그를 참조했다. 더 자세한 사항은 참고자료에서 링크를 통해 볼 수 있다.
💡 용어설명
- End-to-End
종단간 기계학습이라고도 불리며, 입력에서 출력까지 "파이프라인 네트워크"없이 신경망으로 한 번에 처리하는 방식을 의미한다.
- Dense Prediction
Semantic Segmentation과 같은 의미로, 이미지의 각 픽셀이 어느 클래스에 속하는에 대해서 이미지 내의 모든 픽셀에 대해 예측을 진행하기 때문에 Segmentation을 Dense Prediction이라고 부르기도 한다.
- Localization과 Context(Semantic Information) 사이의 트레이드 오프를 해결할 수 있다?
일반적으로 이미지를 볼 때 패치를 슬라이딩 하면서 보게 된다. 이런 방식의 단점 중 하나가 바로 Localization 정확도와 Context정보간에 Trade-off가 발생한다는 것이다. 큰 패치를 사용하면 더 큰 Max-Pooling layer를 요구하는데 이는 localization accuracy를 감소시키게 되고, 그렇다고 패치를 작게하면 Context를 거의 활용하지 못하게 되는 것이다.
쉽게 말하자면 작은 창으로 작은 부분까지 보면 그 픽셀의 위치정보를 정확히 알 수는 있지만, 그 옆에 뭐가있는지 큰 맥락은 알지 못하게 되는 것이다. 크게 보면 대충 이런 것들이 여기 있는지는 알지만 정확이 그 큰 창 안 어디에 있는지 알지 못하게 된다고 할 수 있다.
U-Net 예제 1.(수정된 U-Net)
TensorFlow의 공식문서를 참조하여 작성된 예제이다. 따라서 더 상세한 설명은 공식문서를 참고하면 볼 수 있다.
!pip install git+https://github.com/tensorflow/examples.gitimport tensorflow as tf
import tensorflow_datasets as tfdspip으로 설치해주는 것은 pix2pix라는 예제에서 구현된 업샘플 블록을 사용하기 위하여 설치해주는 것이다. 그 후 우선 텐서플로우와 데이터를 import해준다.
다음으로는 pix2pix와 시각화에 필요한 라이브러리를 import한다.
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt이제 tfds를 통해서 Oxford-IIIT Pets데이터를 다운로드 하여 준다. 세분화 마스크는 버전 3+에 포함되어 있기 때문에 버전 3이상의 데이터를 다운로드한다.
이 데이터세트는 37개의 애완동물 품종의 이미지로 구성되어 있으며 품종당 200개의 이미지가 있다(훈련 및 테스트 분할에 각각 ~100개). 각 이미지에는 해당 레이블과 픽셀 단위 마스크가 포함된다. 여기서 마스크는 각 픽셀에 대한 클래스 레이블을 의미한다. 그리고 각 픽셀에는 세 가지 범주 중 하나가 지정된다.
- 클래스 1: 애완 동물에 속하는 픽셀
- 클래스 2: 애완동물과 접하는 픽셀
- 클래스 3: 위에 속하지 않음/주변 픽셀
이미지 색상 값은 [0,1] 범위로 정규화된다. 편의를 위해 세분화 마스크에서 1을 빼면 {0, 1, 2}와 같은 레이블이 생성된다.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_maskdef load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask데이터세트에는 이미 필요한 훈련 및 테스트 분할이 포함되어 있으므로 동일한 분할을 계속 사용하면 된다.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZEtrain_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)그 후 이미지를 무작위로 뒤집어 간단한 이미지 증강을 수행한다.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels입력을 일괄 처리한 후에 증강을 적용하여 입력 파이프라인을 빌드한다. 이때 테스트 이미지에는 증강을 적용하지 않는다.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)이미지 예제와 해당 이미지의 실제 마스크를 시각화 한다.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])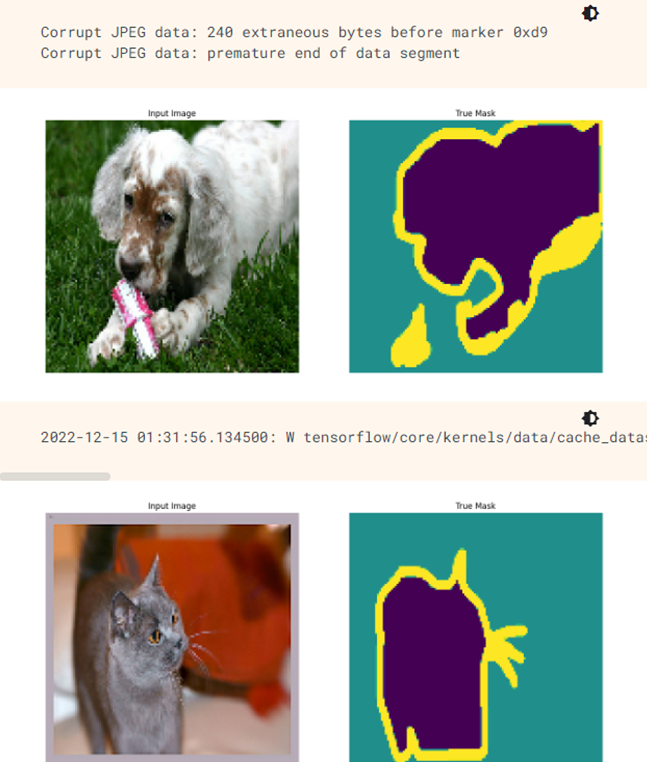
이제 모델을 정의하여 준다. U-Net은 인코더(다운 샘플러)와 디코더(업샘플러)로 구성된다.
모델을 구성함에 있어서 사전학습 모델은 MobileNetV2를 인코더로 사용한다. 디코더의 경우에는 앞서 언급한 TensorFlow 예제 레포지토리의 Pix2Pix예제에서 이미 구현된 업샘플 블록을 사용한다.
인코더는 모델 중간 레이어에서 얻어지는 특정 출력으로 구성되며, 학습 과정에서 훈련하지 않고 사전 훈련된 가중치를 그대로 사용한다.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False다음은 디코더(다운샘플러)의 코드이다.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]이제 앞에서 정의한 인코더와 디코더를 이용하여 U-Net모델을 생성한다. 이때 마지막 레이어의 필터 수는 Output_channels수로 설정된다. 이것은 클래스당 하나의 출력 채널이 된다.
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)이제 모델을 컴파일하고 훈련한다. 이때 이번 예제는 다중 클래스 분류 문제이기 때문에 from_logits인수가 True로 설정된 tf.keras.losses.CategoricalCrossentropy손실 함수를 사용한다. 레이블은 모든 클래스의 각 픽셀에 대한 점수 벡터가 아닌 정수 스칼라이기 때문이다.
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])tf.keras.utils.plot_model을 사용하면 모델 아키텍처를 볼 수 있다.
tf.keras.utils.plot_model(model, show_shapes=True)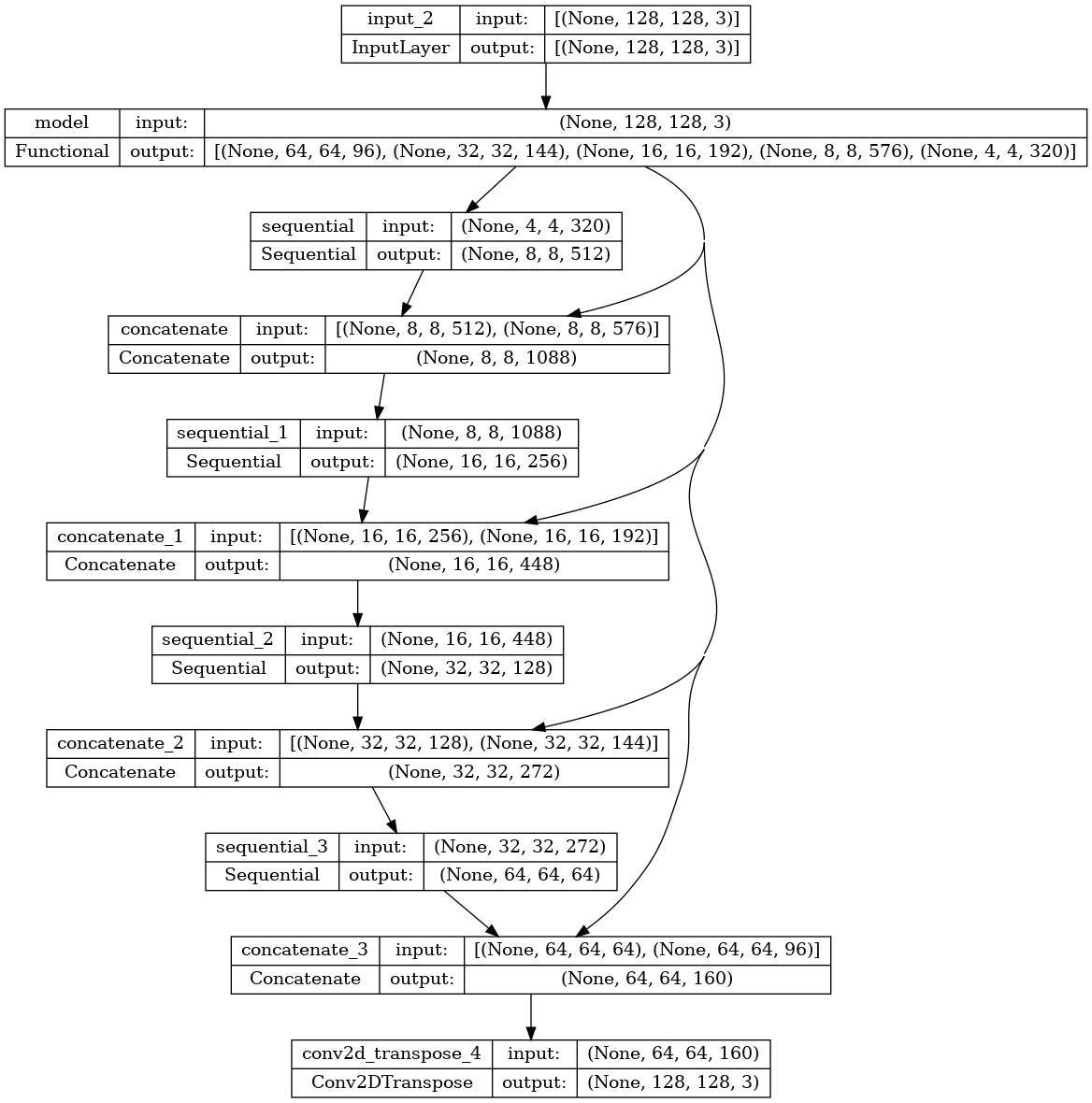
다음으로 각 픽셀에 값이 가장 높은 채널을 할당하는 Create_mask함수를 생성한다.
def create_mask(pred_mask):
pred_mask = tf.math.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]모델을 훈련하기 전에 기본적인 모델이 어떻게 예측하는지 확인해보기 위해서 다음 코드를 실행해 볼 수 있다.
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])show_predictions()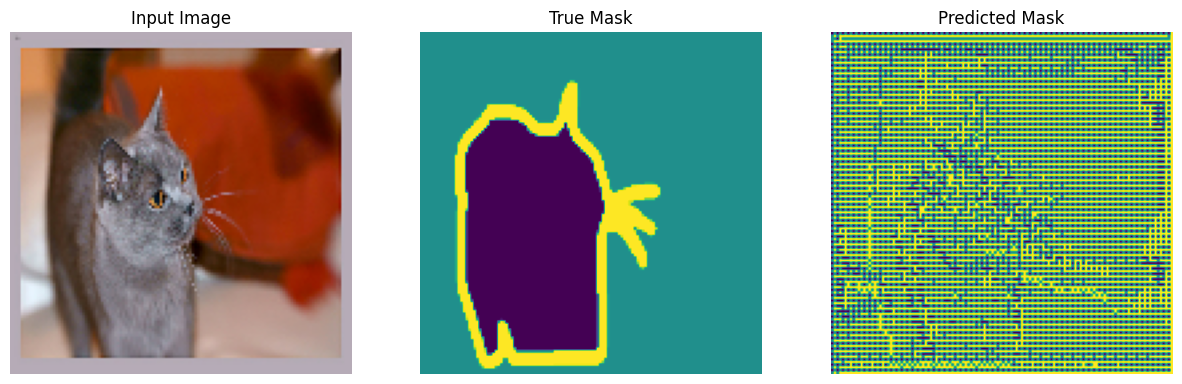
다음으로 모델이 훈련되는 동안 어떻게 개선되는지 관찰하기 위하여 콜백함수를 선언하여 준다.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])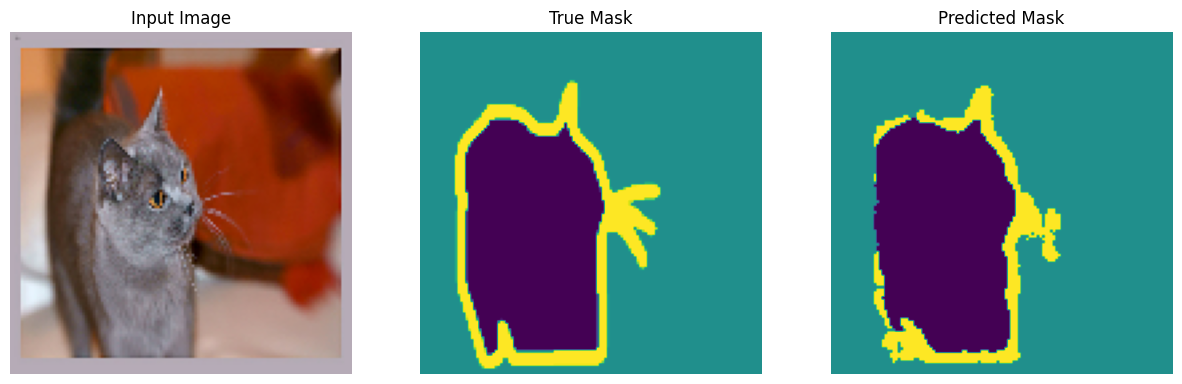
실제로 코드를 구동시켜보면 각 에포크에 따라서 점점 Predicted Mask가 변하는 것을 확인할 수 있다.
다음으로 Train세트의 Loss와 Validation세트의 Loss를 확인하는 그래프를 출력하는 함수를 생성하여 준다.
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()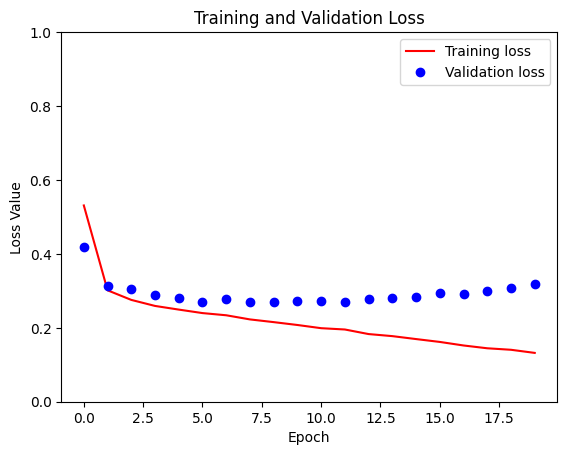
이제 훈련이 끝났기 때문에 다음과 같이 예측을 진행할 수 있다.
show_predictions(test_batches, 3)
위에 작성한 코드는 살짝 수정된 U-Net으로 실제 U-Net의 구조와는 약간의 차이가 존재한다.
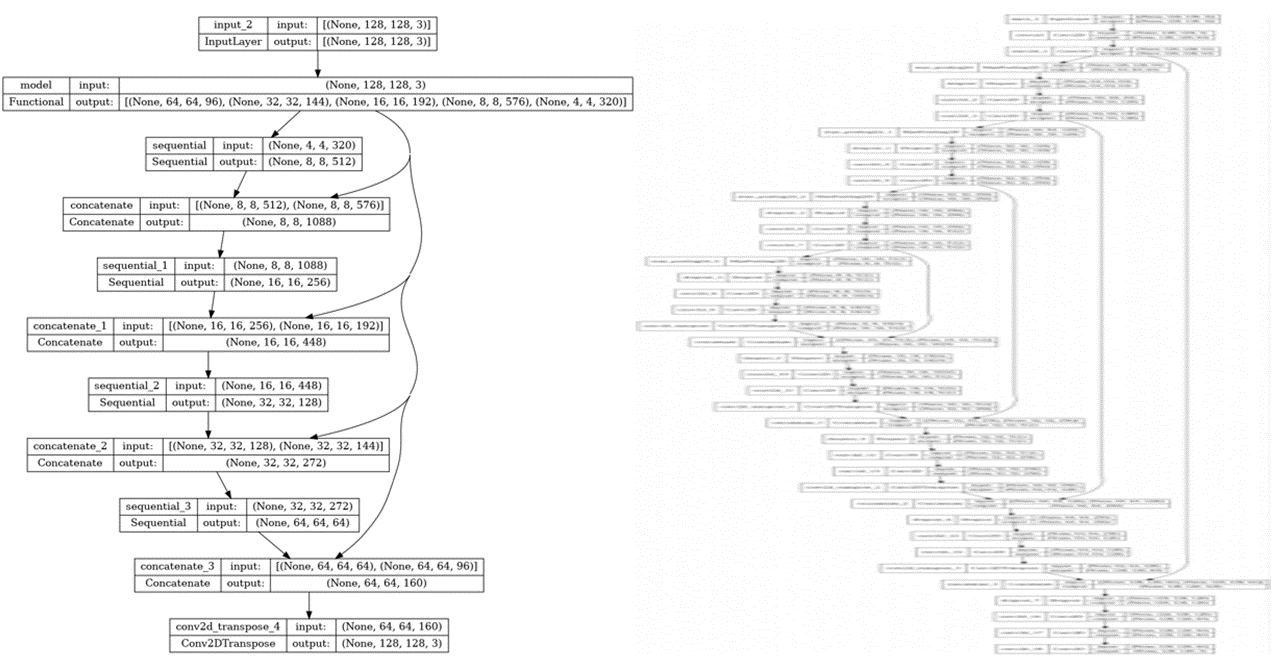
좌측은 위의 코드로 만든 모델이고, 우측이 실제 U-Net의 구조이다. 따라서 실제 U-Net과 같은 구조로 만들기 위해서는 다음과 같은 코드로 U-Net을 구축할 수 있다.
먼저 Conv2D-ReLU-Conv2D-ReLU로 구성된 층을 만드는 함수를 생성하여 준다. 이 함수는 인코더와 bottleneck에 사용된다.
def double_conv_block(x, n_filters):
# Conv2D then ReLU activation
x = layers.Conv2D(n_filters, 3, padding = "same", activation = "relu",
kernel_initializer = "he_normal")(x)
# Conv2D then ReLU activation
x = layers.Conv2D(n_filters, 3, padding = "same", activation = "relu",
kernel_initializer = "he_normal")(x)
return x다음으로는 특징 추출을 위한 다운샘플러를 만들어 주는 함수를 생성한다.
def downsample_block(x, n_filters):
f = double_conv_block(x, n_filters)
p = layers.MaxPool2D(2)(f)
p = layers.Dropout(0.3)(p)
return f, p마지막으로 디코더에 사용되는 업샘플링 함수를 생성하여 준다.
def upsample_block(x, conv_features, n_filters):
# upsample
x = layers.Conv2DTranspose(n_filters, 3, 2, padding="same")(x)
# concatenate
x = layers.concatenate([x, conv_features])
# dropout
x = layers.Dropout(0.3)(x)
# Conv2D twice with ReLU activation
x = double_conv_block(x, n_filters)
return x이제 위에서 만든 함수들을 이용하여 U-Net의 구조를 생성하여 준다.
def bulid_unet_model():
# inputs
inputs = layers.Input(shape=(128,128,3))
# encoder: contracting path - downsample
# 1 - downsample
f1, p1 = downsample_block(inputs, 64)
# 2 - downsample
f2, p2 = downsample_block(p1, 128)
# 3 - downsample
f3, p3 = downsample_block(p2, 256)
# 4 - downsample
f4, p4 = downsample_block(p3, 512)
# 5 - bottleneck
bottleneck = double_conv_block(p4, 1024)
# decoder: expanding path - upsample
# 6 - upsample
u6 = upsample_block(bottleneck, f4, 512)
# 7 - upsample
u7 = upsample_block(u6, f3, 256)
# 8 - upsample
u8 = upsample_block(u7, f2, 128)
# 9 - upsample
u9 = upsample_block(u8, f1, 64)
# outputs
outputs = layers.Conv2D(3, 1, padding="same", activation = "softmax")(u9)
# unet model with Keras Functional API
unet_model = tf.keras.Model(inputs, outputs, name="U-Net")
return unet_model위와 같이 작성하면 실제 U-Net모델을 구현할 수 있다. 이때 자세한 사항은 코드를 긁어온 사이트를 참고하자.
💡 코드사이트 주소
https://pyimagesearch.com/2022/02/21/u-net-image-segmentation-in-keras/
4. Obejct Detection(객체 탐지/인식)
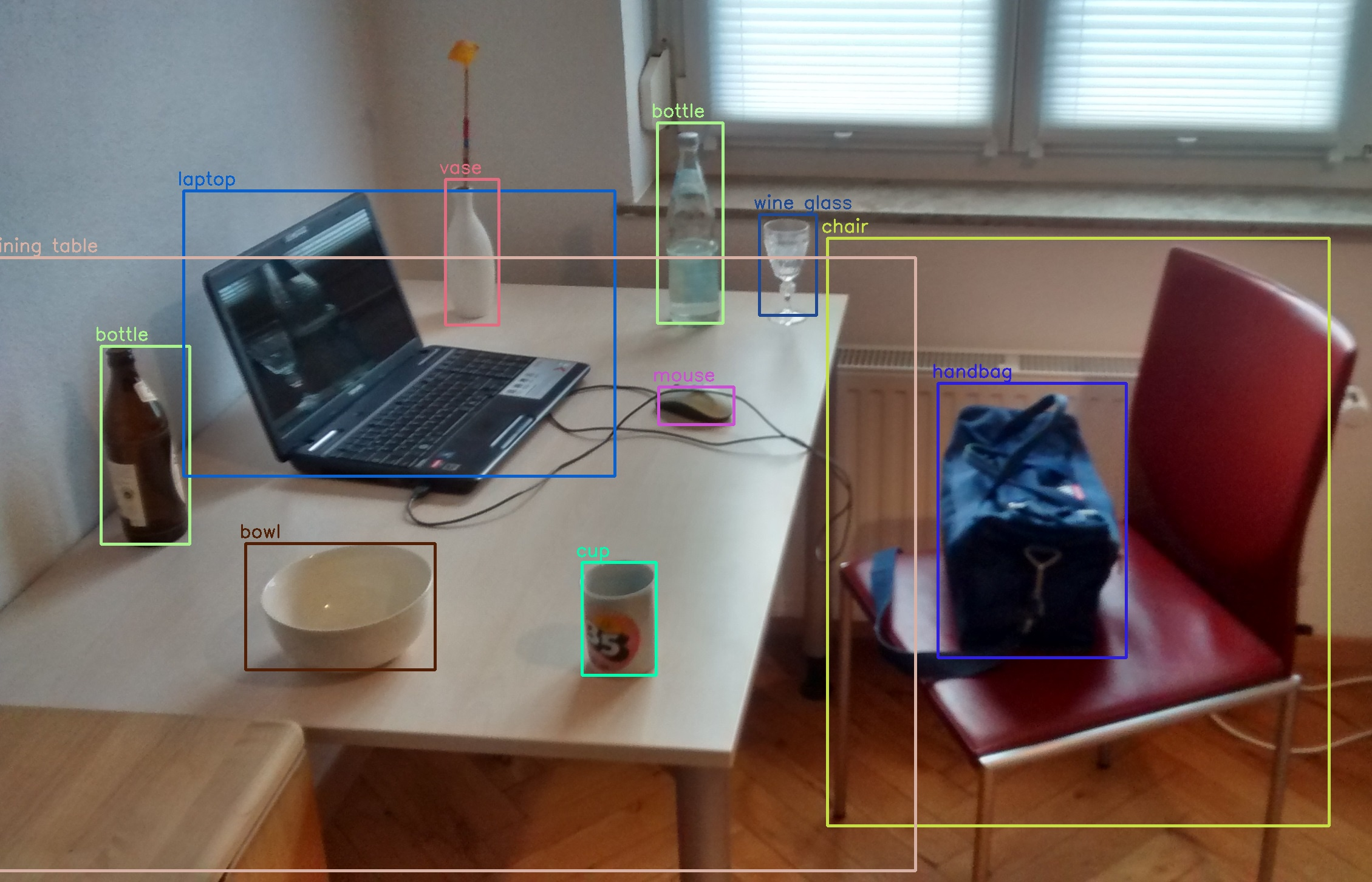
하나의 이미지에서 여러 물체를 분류하고 위치를 추정하는 작업을 Object Detection(객체 탐지)라고 한다.
과거에 널리 사용되던 방식은 하나의 물체를 분류하고 위치를 찾는 분류기를 훈련한 다음에 이미지 전체를 훑는 방식을 주로 사용했다. 이 방식은 매구 간단하지만 조금씩 다른 위치에서 동일한 물체를 여러번 감지하기 때문에 불필요한 바운딩 박스를 제거하기 위한 사후 처리가 필요하다. 흔히 사용하는 방법으로는 NMSnon-max suppression이 있다.
이런 간단한 객체 탐지 방식은 상당히 잘 동작하지만 CNN을 여러 번 실행시켜야 해서 많이 느리다는 단점이 있다. 다행히 앞에서 다룬 FCN(완전 합성곱 신경망)을 사용하면 CNN을 훨씬 빠르게 이미지에 슬라이딩 시킬 수 있다.
대표적인 객체 탐지 모델은 아래와 같이 발전하여 왔다.

객체 탐지 모델들은 어떤 단계를 거쳐 분류가 진행되는지에 따라서 Two Stage방식과 One Stage방식으로 나눌 수 있다.
One Stage Dector
One Stage Detector는 특정 지역을 추천받지 않고 입력 이미지를 Gride등의 같은 작은 공간으로 나눈 뒤에 해당 공간을 탐색하며 분류를 수행하는 방식이다. 즉, Regional Proposal과 Classification이 동시에 이루어지는 것이다.
그림으로는 아래와 같이 나타낼 수 있다.
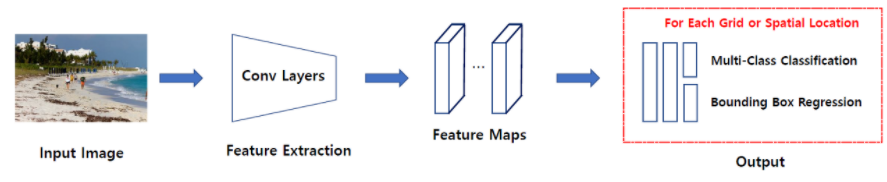
지역 추천을 먼저 받지 않고 동시에 이루어지기 때문에 Two stage방식보다는 빠르다는 장점이 있다. 하지만 빠른만큼 정확도가 낮다는 단점이 존재한다.
대표적인 모델로는 SSD(Single Shot multibox Detector)계열과 최근 자율주행 등에서 각광을 받고있는 YOLO(You Only Look Once)계열의 모델이 있다.
Two Stage Dector
Two Stage Detector는 일련의 알고리즘을 통해서 객체가 있을 만함 곳을 추천받은(Regional Proposal) 뒤에 추천받은 Region, 즉 RoI(Region of Interest)에 대해 분류를 수행하는 방식이다.
앞에서도 언급하였지만 Regional Proposal 이란 기존에 이미지를 탐색하는 방식의 비효율성을 개선하기 위하여 등장한 것이다. 기존에는 이미지에서 object detection을 위해 sliding window방식을 이용했었다. Sliding window 방식은 이미지에서 모든 영역을 다양한 크기의 window (differenct scale & ratio)로 탐색하는 것이다. 말 그대로 모든 영역을 탐색하기 때문에 물체가 없는 부분까지 탐색하여 비효율적이다.
이런 비효율성을 개선하기 위해서 "물체가 있을만한"영역을 빠르게 찾아내는 알고리즘들을 Region proposal이라고 하며, 대표적으로 Selective search, Edge boxes들이 있다.
Two Stage Dector를 그림으로 나타내면 다음과 같이 나타낼 수 있다.
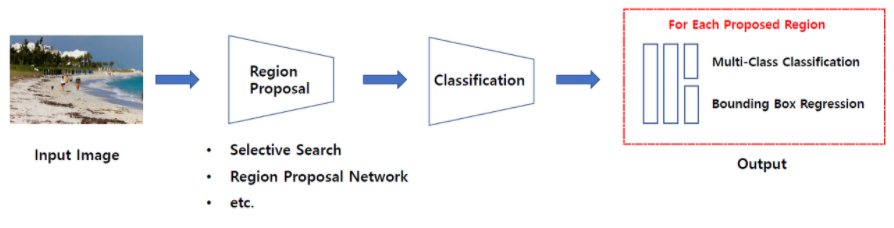
대표적인 Two stage모델로는 R-CNN계열(R-CNN,Fast R-CNN, Faster R-CNN 등)의 모델이 있다.
객체 탐지 성능지표(IoU, mAP)
객체 탐지의 결과는 우리가 지금까지 사용한 지표와는 다른 지표를 사용한다. IoU(Intersection over Union)과 mAP(mean Average precision)이 그 예이다.
IoU

위 그림의 초록색 박스처럼 정답에 해당하는 Bounding Box를 Ground-truth라고 한다. 모델이 빨간색 박스처럼 예측했을 때 IoU는 다음과 같은 식을 사용하여 구할 수 있다.
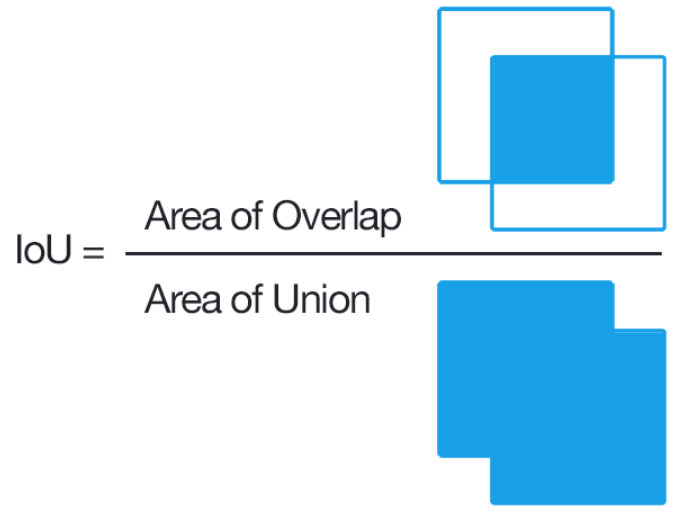
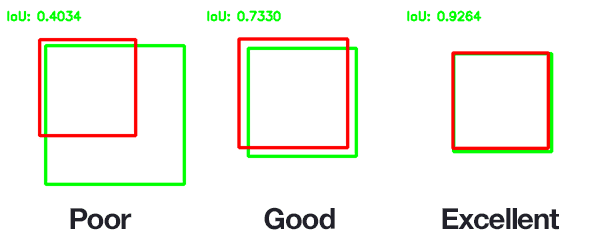
IoU 를 사용하면 객체가 포함되어 있지만 너무 큰 범위를 잡는 문제를 해결할 수 있다. 아래 그림은 Ground-truth/Prediction에 해당하는 Bounding Box 에 따라 IoU가 구해지는 예시를 나타내고 있다.
mAP

객체 탐지에서 널리사용되는 성능지표이다. "Mean Average"라는 표현은 의미가 중복된 것처럼 보인다.
이 지표를 이해하기 위해서는 정밀도와 재현율을 이해하고 있어야 한다. 이 두 지표는 Trade-off관계에 있다. 따라서 이 두 값을 정밀도/재현율 곡선으로 그려볼 수 있다. 이 곡선을 하나의 숫자로 요약하려면 곡선의 아래 면적(AUC)를 계산한다.
하지만 정밀도/재현율 곡선에서 재현율이 증가할 때 정밀도도 상승하는 영역이 포함될 수 있다. 특히 재현율 값이 낮을 때 그러하다. 이것이 바로 mAP지표가 만들어진 이유 중 하나이다.
한 분류기가 10%재현율에서 90% 정밀도를 달성하고 20% 재현율에서는 96%의 정밀도를 달성한다고 가정해보자. 여기서는 Trade-off가 없다. 재현율과 정밀도가 모두 상승하기 때문에 10%재현율보다는 20%재현율의 분류기를 사용하는 것이 당연하다. 따라서 10% 재현율에서 정밀도를 보는 것이 아니라 최소 10%재현율에서 분류기가 제공할 수 있는 최대 정밀도를 찾아야 한다. 이값은 90%가 아니라 96%이다. 따라서 공정한 모델의 성능을 측정하는 한 가지 방법은 최소 0% 재현율에서 얻을 수 있는 최대 정밀도, 그 다음 10%, 20%에서 100%까지 재현율에서의 최대 정밀도를 계산한다. 그 다음 이 최대 정밀도를 평균한다. 이를 평균 정밀도average precision(AP)라고 부른다. 만일 두 개 이상의 클래스가 있다면 각 클래스에 대해 AP를 계산단 다음 평균 AP를 계산한다. 이것이 바로 mAP이다.
객체 탐지의 경우 조금 더 복잡해진다. 시스템에 정확한 클래스를 탐지했지만 위치가 잘못됐다면 이는 올바른 예측으로 볼 수 없다. 이를 위한 한 가지 방법은 IOU임계점을 정의하는 것이다. 예를 들어 IoU가 0.5보다 크고 예측 클래스가 맞다면 올바른 예측으로 간주한다. 이에 해당하는 mAP는 일반적으로 mAP@0.5라고 쓴다.
❗ 참고자료
1. 오렐리앙 제옹, 핸즈온 머신러닝(2판), 서울:한빛미디어,O⋅REILLY, 2020
2. CodeStates Lecture Note - N432
3. U-Net논문 리뷰
4. Semantic Segmentation
5. mAP
