학습목표
- 깊이 우선 탐색(Depth-First Search, DFS)을 배우고 DFS 코드를 이해한다.
- 너비 우선 탐색(Breadth-First Serach, BFS)을 배우고 BFS 코드를 이해한다.
- 위의 개념과 기존에 배웠던 기본적인 스택, 재귀, 트리, 그래프 등을 연관지어 이해한다.
BFS & DFS
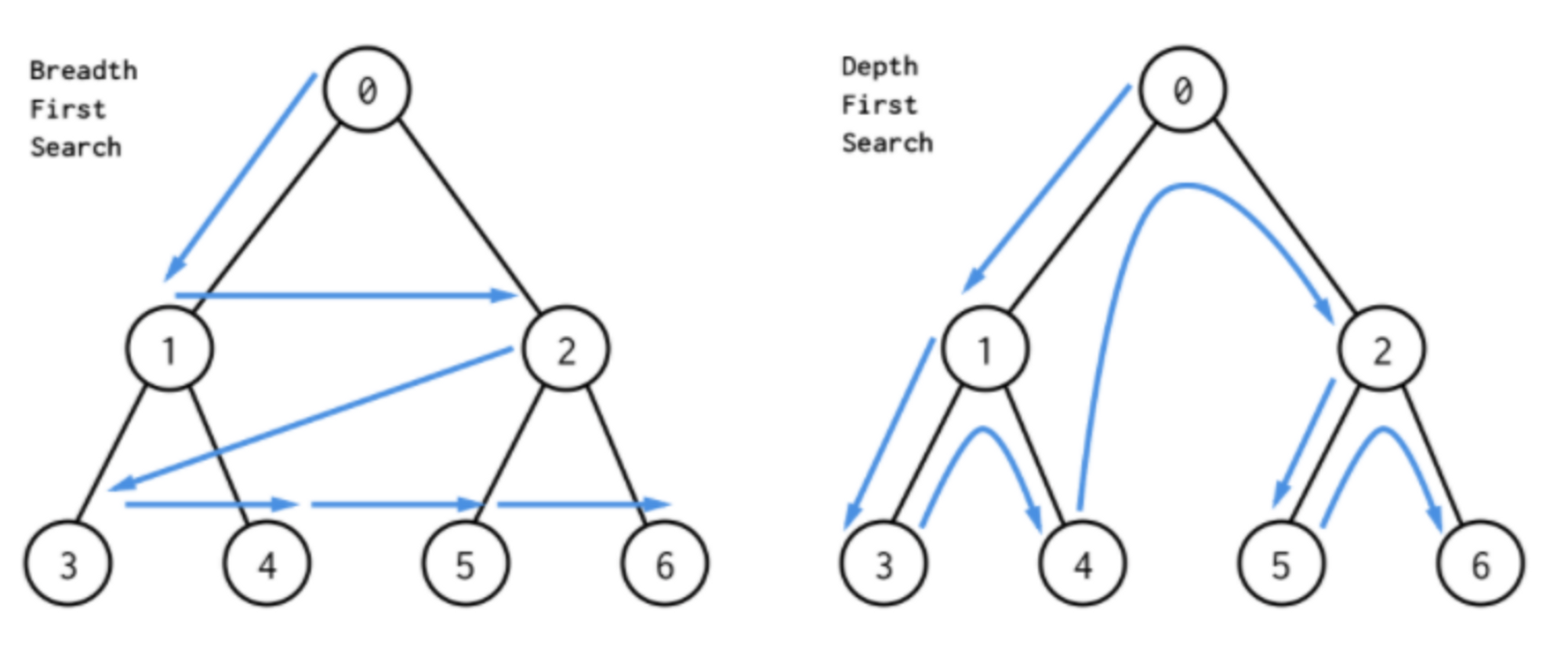
이전 시간에 그래프와 트리의 순회에 대해소 학습했다. 순회란 그래프에서 모든 노드를 방문하는 것을 말한다. 그리고 이러한 순회의 방법으로 DFS와 BFS가 있다.
-
목적: 모든 정점을 1번씩 방문하기 위한 것
-
순회(방문)하면서 탐색하는 탐색 알고리즘
-
출발 노드와 그래프/트리 구조에 따라 탐색하는 순서와 노드가 달라질 수 있다.
-
주의사항: 방문한 노드인지 아닌지에 대한 확인이 필요하다.
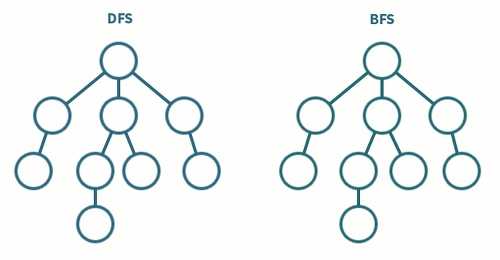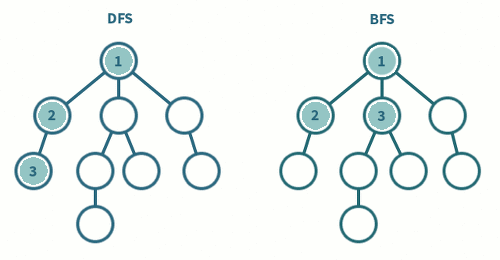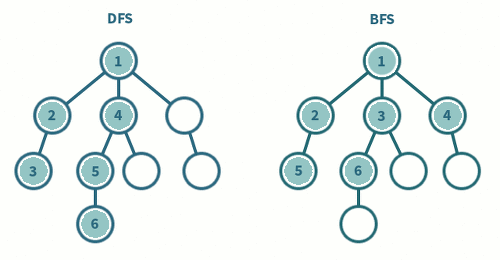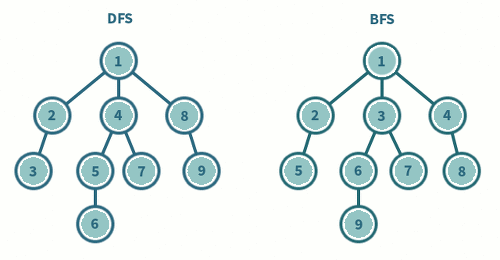
깊이 우선 탐색(Depth-First-Serach, DFS)
깊이 우선 탐색이란 현재 정점에서 갈 수 있는 점들까지 최대한 깊게 들어가면서 탐색한다. 자료구조 중 스택(Stack) 또는 재귀를 이용하여 구현할 수 있다.
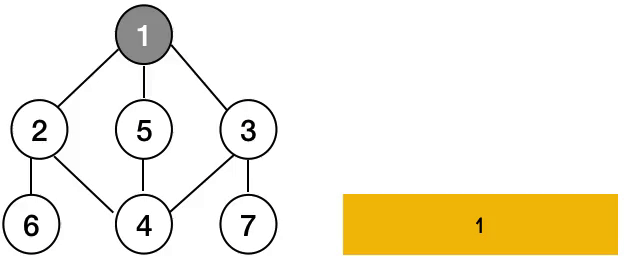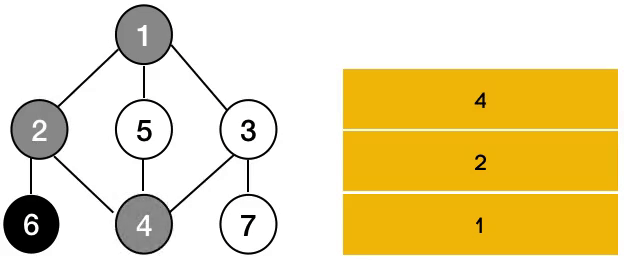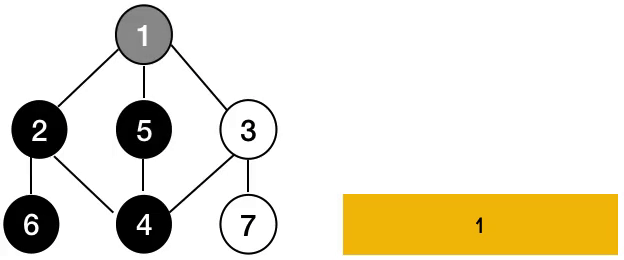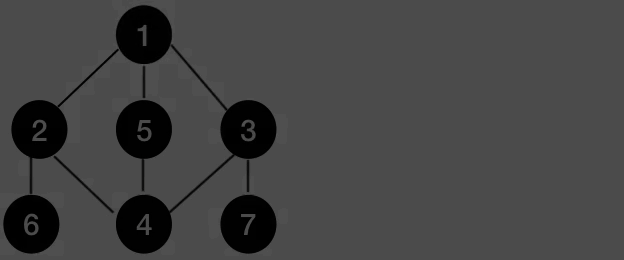
- 시작 정점으로부터 하나의 분기를 전부 방문한 후 다음 분기로 넘어가는 방식
- DFS는 깊이를 우선적으로 탐색 후, 재귀적으로 아래에서부터 탐색하지 않은 정점이 있는지 확인하는 방법 - 이전 경로의 정보가 필요한 경우나, 모든 노드를 방문하는 경우 사용된다.
- 활용예시
- 가중 그래프의 최소 스패닝 트리 찾기
- 길 찾기
- 그래프에서 주기 감지
- 미로 문제💡 DFS 절차(재귀)
1. 노드를 방문 리스트에 기록
2. 현재 노드에 인접한 노드를 기준으로 반복
3. 노드의 인접리스트가 비었을 경우 종료(Base Case)
4.방문하지 않은 노드인 경우 DFS함수 재귀호출
def dfs_recur(start, graph, visited=[]):
# 방문리스트에 체크
visited.append(start)
# 현재 노드에 인접한 노드를 기준으로 반복
for node in graph[start]:
# 방문하지 않은 노드인 경우:
if node not in visited:
# dfs 재귀 수행
dfs_recur(node, graph, visited)
return visited💡 DFS 절차(Stack)
1. 방문 리스트에 시작 노드 기록
2. Stack에 시작 노드의 인접 노드 삽입(Push)
3. Stack에서 노드를 POP하면서 방문처리(출력) 한다.
4. 꺼내온 노드와 이웃한 노드를 Stack에 넣는다.(Push) 그 후 방문했던 노드인지 아닌지 체크한다.
5. Stack에 아무것도 남지 않을 때까지 2~4를 반복한다.
6. 모든 노드를 방문할때까지 1~5를 반복한다.def dfs_stack(start_node, graph): visited = [] # 방문 리스트 stack = [start_node] # 반복문(스택 안에 값이 있는 동안 반복): while stack: # 스택에서 pop node = stack.pop() # 방문 리스트에 없는 경우: if node not in visited: # 스택에 인접 노드 push visited.append(node) # 방문리스트에 기록 stack.extend(graph[node]) return visited
위 두 코드를 실행하면 사실 다른 결과가 나온다.
# 테스트 해보기
graph_0 = {
1: [2,3,4],
2: [5],
3: [6],
4: [],
5: [7],
6: [5],
7: [6]
}
print(dfs_recur(1, graph_0, visited=[])) # [1, 2, 5, 7, 6, 3, 4]
print(dfs_stack(1, graph_0)) # [1, 4, 3, 6, 5, 7, 2]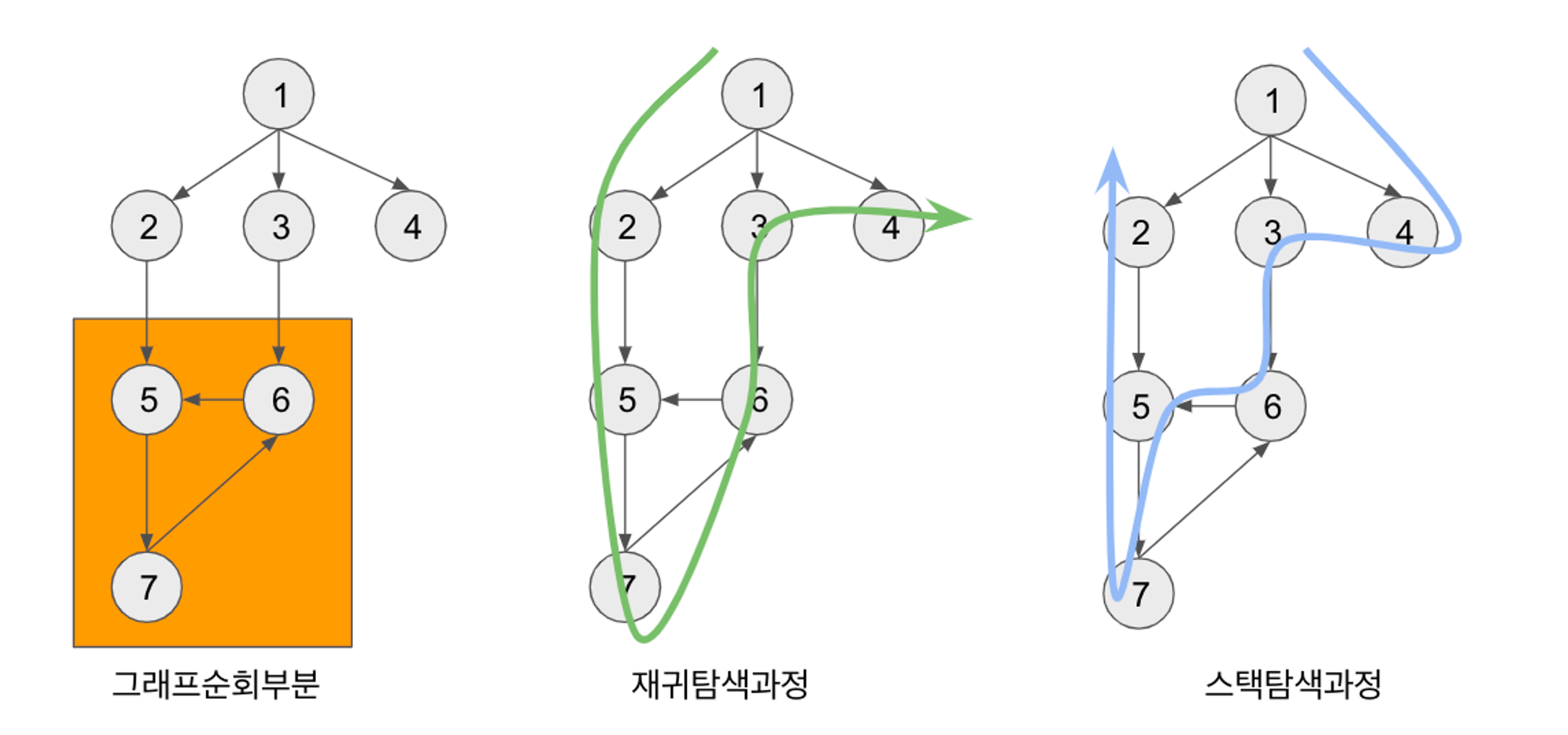
이는 Stack의 경우 POP이라는 명령어를 이용해서 제일 끝 단 노드를 꺼내오면서 탐색을 시작하기 때문이다. 만일 재귀함수로 구현한 DFS와 Stack을 통해 구현한 DFS의 결과값을 동일하게 하고 싶다면 다음과 같이 코드를 수정해주면 된다.
# 재귀와 똑같이 하려면? 순서를 바꾸면 됨.
# DFS 구현 2. 스택
def dfs_stack(start_node, graph):
visited = [] # 방문 리스트
stack = [start_node]
# 반복문(스택 안에 값이 있는 동안 반복):
while stack:
# 스택에서 pop
node = stack.pop()
# 방문 리스트에 없는 경우:
if node not in visited:
# 스택에 인접 노드 push
visited.append(node)
# 방문리스트에 기록
stack.extend(graph[node][::-1])# 이 부분 변경
# [::-1] : 연결리스트 안에있는 노드를 역순으로 꺼내면 됨
return visited
print(dfs_stack_2(1, graph_0)) # [1, 2, 5, 7, 6, 3, 4]재귀와 스택의 차이점
- 로직이 직관적이고 이해하기 쉽다.
- 스택은 리스트의 메소드만을 활용하였기 때문에 위에서 아래로 코드를 해석하면 되므로 - 스택이 실행 속도 또한 재귀보다 빠르다.
- 스택의 특징인 후입선출 개념을 적용하였기 때문에, 마지막에 삽입된 노드를 기준으로 깊이우선탐색을 진행한다. - 재귀구현의 경우는 자기함수를 호출하는 형태이기 때문에 코드가 간결해진다는 장점이 있다.
- 재귀와 스택 방법의 차이점을 찾을 수 있도록 각 방법의 특징을 이해해야 한다.
DFS와 백트랙킹(Backtracking)
DFS는 가능한 모든 경로(후보)를 탐색한다. 따라서, 불필요할 것 같은 경로를 사전에 차단하는 등의 행동이 없으므로 경우의 수를 줄이지 못한다.
탐색하는 방향에 답이 없다고 판단되면, 되돌아가서 다른 방향을 탐색하는 기법을 바로 백트래킹이라고 한다. 즉, 반목문의 횟수를 줄일 수 있으므로 효율적이다. 이를 가지치기라고 하는데, 불필요한 부분을 쳐내고 최대한 올바른 쪽으로 간다는 의미이다.
❗️ 백트래킹 예시 문제: 백준 9663번 (문제 링크)
너비 우선 탐색(Breadth-First Search, BFS)
현재 정점에 연결된 가까운 점들부터 최대한 넓게 탐색한다. 자료구조 중 큐(Queue)를 이용해 구현할 수 있다.
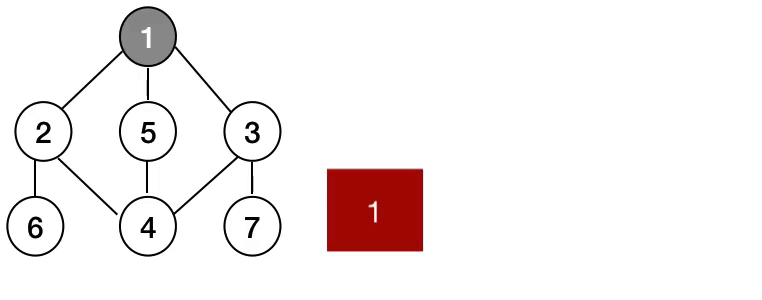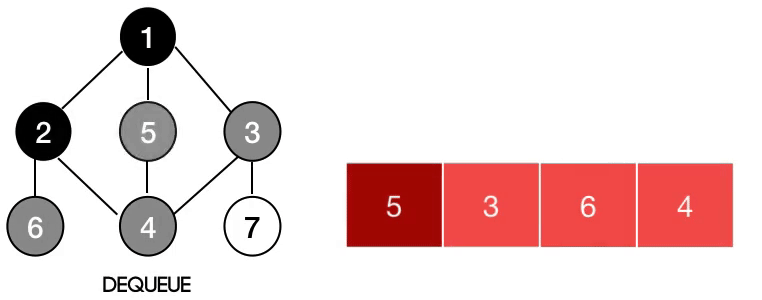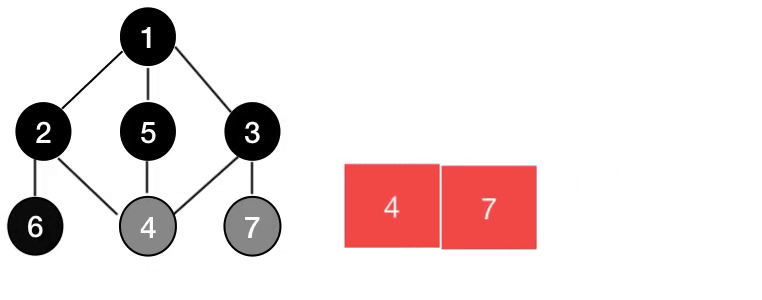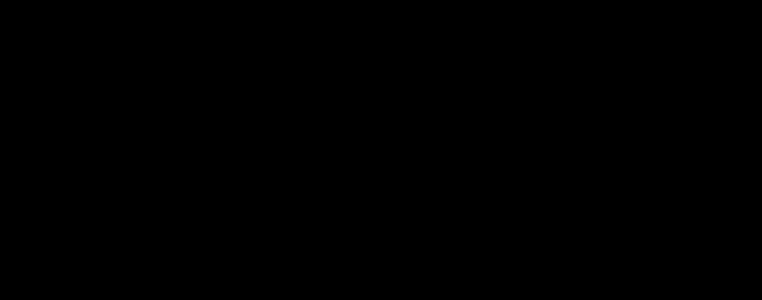
- 노드가 적은 그래프를 순회하거나, 최단경로를 탐색할 때 유용
- 단점: Queue를 활용하므로 노드가 많아지는 경우 필요한 메모지 저장공간이 증가한다.
- 인접한 노드의 정보를 모두 가진 상태에서 밑으로 내려간다. - 활용예시
- 길 찾기, 라우팅
- BitTorrent와 같은 P2P 네트워크에서 인접 노드 찾기
- 웹 크롤러
- 소셜 네트워크에서 멀리 떨어진 사람 찾기
- 그래프에서 주변 위치 찾기
- 네트워크에서 방송
- 그래프에서 주기 감지
- 연결된 구성 요소 찾기
- 몇 가지 이론적 그래프 문제 풀기💡 BFS 절차
1. 방문 리스트에 시작 노드 기록
2. Queue에 시작 노드의 인접 노드 삽입(Enqueue)
3. Queue에서 노드를 Dequeue하면서 방문처리(출력)한다.
4. 꺼내온 노드와 인접한 노드를 큐에 넣는다.(Enqueue) 그 후 방문했던 노드인지 아닌지 체크한다.
5. Queue에 아무것도 남지 않을 때까지 2~4를 반복한다.
6. 모든 노드를 방문할때까지 1~5를 반복한다.
# deque 라이브러리를 활용한 queue 구현하기
# 우선 deque를 위해 자료구조의 큐에서 배웠던 내용을 복습한다.
from collections import deque
queue = deque(["Eric", "John", "Michael"])
queue.append("Terry") # append: 오른쪽끝 삽입
queue.append("Graham")
# print(queue.pop())
print(queue.popleft()) # popleft: 왼쪽끝 빼오기 pop(0)와 같은 역할이지만 상수시간 보장
# print(queue.popleft())
print(queue)# BFS 구현 - deque 사용
"""
1. 방문 리스트에 시작 노드를 기록
2. Queue에 시작노드의 인접 노드를 삽입(enqueue)
3. 큐에서 노드를 Dequeue하면서 방문처리(출력)한다.
4. 꺼내온 노드와 이웃한 노드를 큐에 넣는다.(enqueue)
방문했던 노드인지 아닌지 체크한다.
5. 큐에 아무 것도 남지 않을때까지 2-4 반복
6. 모든 노드를 방문할때까지 1-5를 반복
"""
# deque 라이브러리 불러오기
from collections import deque
# BFS 메서드 정의
def bfs(start_node, graph):
# 방문 처리용 리스트 만들기
visited = []
# 시작 노드를 큐에 삽입
queue = deque([start_node])
# 큐가 완전히 빌 때까지 반복
while queue:
# 큐에서 값을 뽑아낸다.
cur_node = queue.popleft() # 리스트의 queue.pop(0)과 같다. 그러나 시간복잡도 상수시간 보장
# 해당 노드가 방문처리 된 노드라면
if cur_node not in visited:
# 방문처리용 큐에 노드 추가
visited.append(cur_node)
# 해당 노드의 인접한 노드를 큐에 추가
queue.extend(graph[cur_node])
return visited정리
-
먼저 생각해볼 점
- 각 알고리즘이 요구하는 메모리는 주어진 자료구조(그래프, 트리 등)의 행태와 알고리즘의 목적(탐색, 정렬 등)에 따라 달라질 수 있다. -
DFS
- Search할 노드의 세로 위치가 깊을 수록, BFS보다 노드를 찾는 속다가 빠르다.- 노드의 갯수가 주어진 컴퓨터의 자원(메모리, 소프트웨어 등)이 감당할 수 있는 범위 이상으로 증가하는 경우, Stack과 재귀방법을 활용하여 탐색을 진행하기 때문에 무한루프 에러가 발생할 확률이 높아진다.
-
BFS
- Search할 노드가 가로 위치로 인접한 경우, DFS보다 효과적일 수 있다.- Queue를 이용해 노드를 저장하는데, Queue는 탐색할 모든 노드를 저장하는 특징이 있다.
- 때문에 메모리를 벗어날 정도로 노드의 갯수가 증가하는 경우 DFS보다 메모미를 많이 소비할 수 있다.
❗️참고자료
1. 코드스테이츠 교육자료
