데이터 전처리란 직역하면 미리 진행하는 프로세스, 즉 분석하기 전에 그에 맞게 데이터를 가공하는 것을 말한다
데이터를 아무리 많이 수집하더라도 그것은 어디까지나 날 것의 데이터(Raw Data)이다
수집 과정에서 오류 발생하여 결측치가 있을 수도, 유난히 튀는 이상치가 발생할 수도 있다
혹은 중복 데이터가 너무 많을 수도 있다
이처럼 데이터를 올바르게 가공하거나, 분포를 고르게 하는 작업을 전처리라고 한다
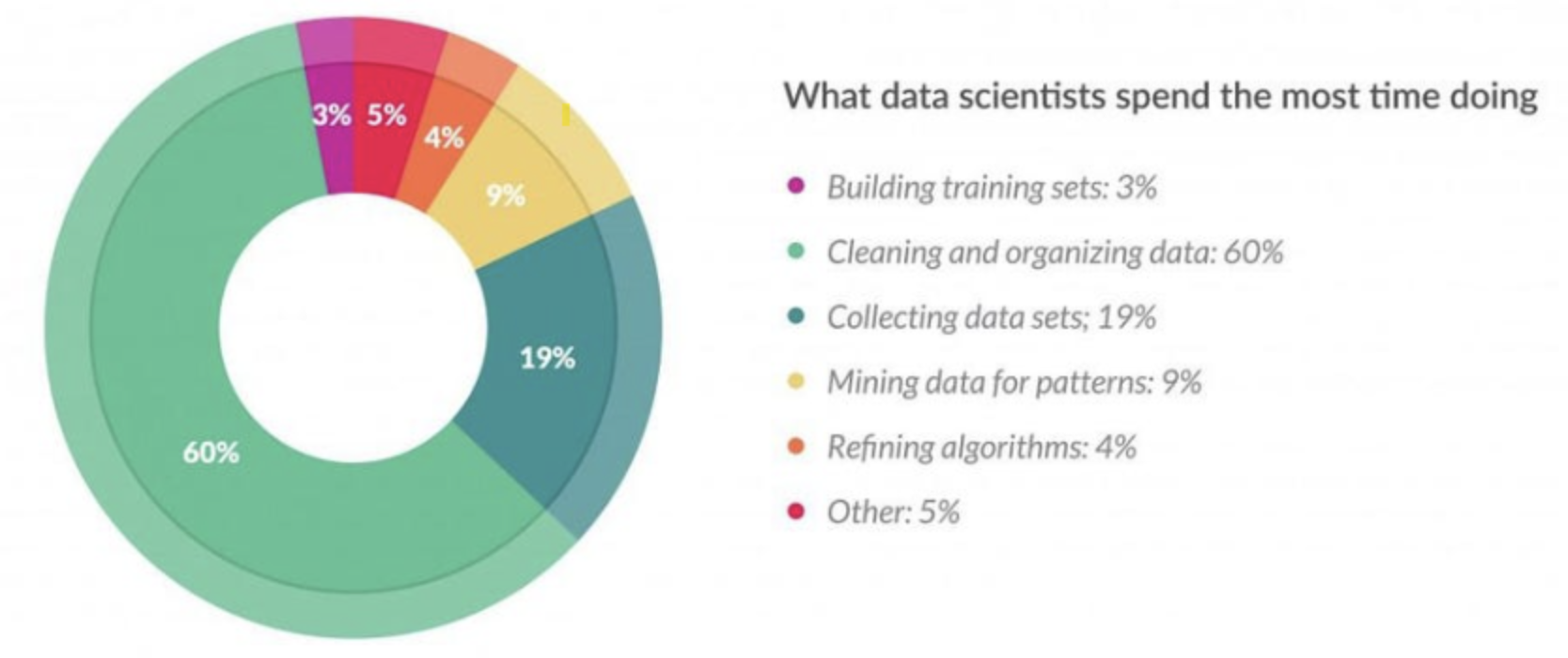
출처: https://modulabs.co.kr/blog/data-preproccesing/
위의 그림을 보면 데이터를 수집하는 것 다음으로 매우 많은 비중을 차지하는 것을 알 수 있다
1. 전처리 순서
이러한 데이터 전처리에도 어떻게 처리해야 하는지 그 순서가 존재한다
1. 데이터 정제
1차적으로 우선 지저분한 데이터들을 처리하는 단계이다
결측치, 중복값 등 올바르지 않은 값들을 제거 및 수정하거나, 뚜렷한 결과를 내기위해 잡음(Noise)을 제거하는 작업을 진행한다
Z-Score, IQR, 정규화, One-Hot Encoding 등
2. 데이터 통합
데이터는 한 곳에서만 얻어지는 것이 아니다
굉장히 다양한 경로로 수집되는 데이터들은 대부분 feature 단위나 형식이 다를 것이다
이런 데이터들의 단위나 이름을 일관되게 정리하여 데이터를 하나로 통합하는 작업을 진행한다
3. 데이터 축소
다음 단계인 분석에서 할 것은 전반적인 데이터들의 관계와 추이를 보는 것이다
그런데 데이터가 너무 많아져버리면 이런 것들을 한눈에 보기가 어렵다
따라서 샘플링 등의 방법을 통해 데이터를 축소시키는 단계이다
이 단계는 어떻게 원본을 잘 대변하는 축소 데이터들을 뽑아낼지가 중요하다
4. 데이터 변환
앞선 단계는 어떻게보면 데이터를 정제하고 간편하게 줄이는 등의 정리 과정에 가깝다고 생각한다
하지만 그럼에도 원본 데이터 자체가 분석에 적합하지 않을 경우가 있다
분포가 고르지 않다거나, 데이터 형식이 원하는 모델링에 맞지 않는 등이 그 이유이다
이럴 때 평탄화, 형식 변환 등의 데이터를 조정하는 작업을 진행하는 것이 바로 이 단계이다
정규화, 형식 변환, 로그 변환 등
참고
강의
코드잇(https://www.codeit.kr)
전처리
https://partrita.github.io/posts/tidy-data/
https://wikidocs.net/16582
https://kr.mathworks.com/discovery/data-preprocessing.html
https://modulabs.co.kr/blog/data-preproccesing/
https://velog.io/@kphantom/2.-%EB%8D%B0%EC%9D%B4%ED%84%B0%EC%A0%84%EC%B2%98%EB%A6%AC%EB%9E%80
https://yeouido-developer.tistory.com/entry/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%A0%84%EC%B2%98%EB%A6%AC%EC%9D%98-%EC%A2%85%EB%A5%98
