
이책에 대한 내용들을 포스팅해보려고 하는데 분량이 581쪽이나 되기 떄문에 처음부터 모든 내용을 다 이해하려고 하는 것보다는 내가 관심있는 부분위주로 읽은 뒤 공부한 내용들을 정리해보려고 한다.

"92%의 인터넷 사용자들은 인터넷이 매일 생성되는 정보량을 얻기위해 굉장히 좋은 곳이라고 말한다."
가장 혁신적인 툴은 바로 월드와이드웹이다. (Wrold Wide Web)

1940년 Vaanevar Bush의 하이퍼텍스트의 발견과 1970년에는 시스템의 형성 그리고 1990년도에 월드와이드웹 (간단하게는 웹이라고 칭한다)의 형성으로 현재까지 굉장히 어마어마한 속도로 발전하였다 지금은 클라이언트 - 서버 디자인이 특징이 되겠다. 1. 서버는 클라이언트와 (http / hypertext transfer protocol)을 통해서 통신한다.
이 프로토콜에는 다양한 페이로드(payloads)가 존재한다 이는 텍스트,이미지, 오디오 비디오 파일등이 있다. 이들은 HTML이라고 하는 간단한 마크업 언어에 인코딩 되어 있는 상태로 존재한다.
- 클라이언트는 일반적으로 브라우저를 의미한다. GUI 환경에서의 어플리케이션을 말하며 이해하지 못하면 무시할 수 있다.
다음은 서버와 클라이언트간의 작동방식에 대한 설명이다.

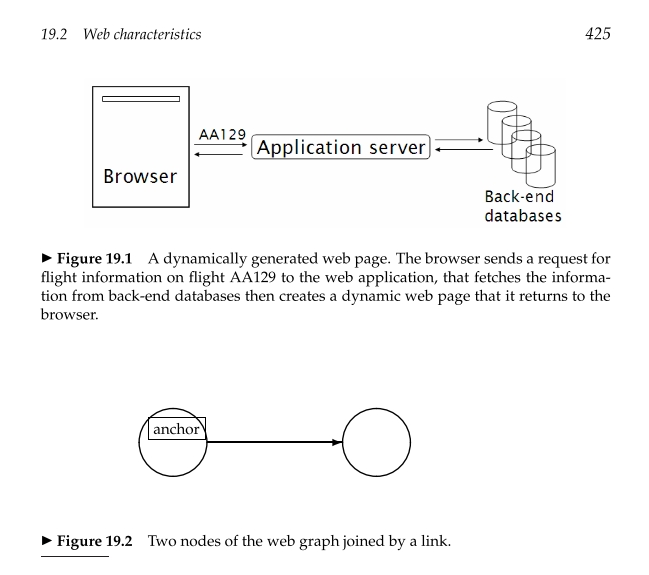
기본적인 작동방식은 다음과 같다. 클라이언트(브라우저)는 웹서버에 http 요청을 보낸다. 그러면 브라우저는 URL(Universal Resource Locator)를 받는데 예를들어, http://www.stanford.edu/home/atoz/contact.html. 이 된다. 여기서 예를든 URL의 string http는 데이터를 전송하기 위한 통신 프로토콜에 해당된다. 그리고 string에 해당하는 www.stanford.edu는 도메인에 해당하는 부분이며 웹페이지의 계층을 정의하게 된다. /home/atoz/contact.html은 이 계층에서의 경로가 되는데, 웹서버인 www.standford.edu의 요청에 대한 응답에 대한 정보들이 파일 contact.html에 저장되어 있다고 생각하면된다.
여기서 contact.html은 HTML의 인코딩 된 파일을 의미하는데 하이퍼링크와 스탠포드대학교로의 접근정보가 여기에 내재되어 있으며, 브라우저에서 이동할 때 필요한 룰들이 포함되어 있다고 생각하면 된다.
따라서 이와같은 http 요청은 페이지에 있는 정보를 가져오게끔하며, 문서와 기타 자료들을 가져오는데에 유용하게 작동한다.
출처:
Introduction to Information Retrieval Cambridge - 2009 -
Information Retrieval and Web Search
