

연구자들의 경우에 다양한 이유로 자신들의 논리를 펼치기 위해 다른 논문들을 인용하게 된다.
- 논문내의 다양한 인용들
- 위치가 반영된 인용문맥
- self-attention mechanism을 적용한 citation network
- Self-attention mechanism
-Transformer 모델에서 사용되는 핵심 구성요소
-입력 시퀸스 내의 각 요소(단어)가 다른 모든 요소들과의 관계를 고려하여 정보를 처리할 수 있게 해줌
- 핵심구성요소
Query (질의) : 현재 토큰이 다른 토큰과 얼마나 관련되어 있는지 묻는 역할
Key (키) : 다른 토큰들이 가진 정보의 특징
Value (값) : 실제 전달되는 정보
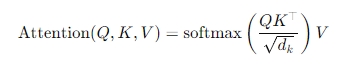
-
스케일된 점곱 (Scaled Dot-Product)
-각 토큰의 Query와 다른 토큰들의 key사이의 내적 (dot product)를 계산한 후, 이 값을 key벡터 차원의 제곱근으로 나누어 안정적인 학습을 도움 -
Softmax 함수
-계산된 유사도 값을 확률분포로 변환하여 중요한 토큰에 더 높은 가중치 부여 -
Multi-head attention
-Self attention을 여러 'head'로 나누어 동시에 다양한 관점에서 관계를 학습
--> 각 head는 서로 다른 부분공간에서의 관계를 학습하고, 이후 이들을 다시 결합하여 더 풍부한 표현을 생성 -
장점
-병렬처리 가능성: RNN과 달리 순차적 처리가 필요없으므로 학습 및 추론속도가 빠름
-긴 거리 관계 포착: 시퀸스 내에서 먼 거리에 있는 단어들간의 관계도 효과적으로 학습할 수 있음

기존 연구들: frequency-based / content-based approaches 중심
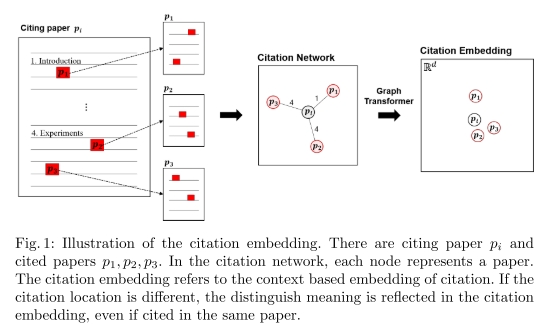
해당 그림을 해석해보면, 각 노드는 각 논문에 해당된다. 만약에 인용된 장소가 다르다면, 1. introduction(서론)
4. Experiment(실험) 즉, 어디서 인용 되었는지에 따라서 그에 대응하는 의미또한 달라진다. 이게 바로 citation embedding이다.
해당논문에서는 인용 맥락을 citation network상에서 고려한 embedding method를 제안한다. self-attention 메카니즘에 기반한 전통적인 GCN 모델보다 더 적은 수의 layer들을 사용하여 global citation features들을 표현할 수 있는 장점이 있다.

--> 해당 논문에 따르면 graph-transformer는 인용된 논문들간의 관계와 영향을 고려하여 pre-training된 citation vectors을 활용한다.

해당 부분이 Contectual citation embdding model에 대해서 자세히 설명해준다.
- Contextual Citation Embedding Model
-인용문과 그 주변 문맥의 의미를 함께 고려하여 인용문을 보다 정밀하게 표현하는 임베딩 모델로 학술연구 및 정보 검색분야에서 인용문의 역할과 유사성을 효과적으로 분석
-인용문의 의미와 역할을 고차원벡터(임베딩)으로 표현하는 모델 --> 인용이 사용된 배경, 목적, 그리고 인용문이 위치한 논리적 흐름들을 반영하여 학술 문서내에서 인용문 간의 의미적 유사성을 더욱 정밀하게 파악할 수 있음
해당 모델을 3가지 특징이 있다.
1. 인용된 컨텍스트를 추출
2. citation embedding의 적용
3. graph-transformer 기반의 encoder

- Node Sampling Approach
-그래프 데이터에서 전체 노드를 모두 처리하는 대신 일부 노드와 그 주변 이웃들을 선택(샘플링)하여 학습이나 분석을 수행하는 방법, 특히 대규모 그래프에서 계산 비용과 메모리 사용을 줄이기 위해 중요하게 사용

여기서 Weisfeiler-Lehman (WL) algorithm 에 대해 설명한다 (6)번 공식을 확인하면 알 수 있다.
해당 알고리즘은 그래프 동형성(Graph Isomorphism)을 판별하거나 그래프의 구조적 특징을 추출하기 위해 사용된다.
주로, color refinement 기법으로 불리며, 노드의 라벨(색깔)을 반복적으로 업데이트하여 그래프의 구조적 정보를 세밀하게 반영한다.
여기서 말하는 그래프 동형성을 판별한다는 의미는 서로다른 두 그래프가 구조적으로 동일한지 판별하는 데 사용된다는 의미이다.

해당 논문의 결론은 다음과 같다.
서로 다른 논문의 섹션마다 샘플링을하여 두어 인용의 문맥을 반영하였다.
각 논문마다 인용하는 목적은 다르고 매우 동적이다. 인용의 의미는 시간이 흐름에 따라 변화한다. 또한 저명한 저널이나 글을 쓴 연구자가 누구냐에 따라서 인용 수가 달라진다.
