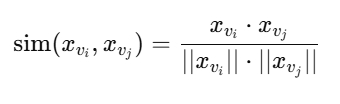VOPRec: Vector Representation Learning of Papers with Text information and Structural Identity for Recommendation
Paper Review
해당 논문은 중국 Dailian University of Technology에서 발표하고 IEEE에 게재된 논문이다.

Keyword - Network representation learning, paper recommendation, graph learning, scholarly big data
--> 본연구는 텍스트 정보 + 구조 정보를 모두 고려하여 논문을 인용 네트워크 상에서 표현 학습하는 최초의 연구
이 논문은 특이하게도 Related Work (관련 연구)가 experiment 다음에 나오고 이후에 conclusion으로 끝맺는다.
Background
학술 빅데이터 시대에 방대한 양의 학술정보로 인해 연구자들이 관련 논문을 찾는것이 어려워졌다.
이를해결하기 위해 과거에는 관련 논문을 연구자에게 추천하는 논문 추천시스템이 개발되었지만 기존의 논문 추천 방식은 대부분 사람이 직접 설계한 feature를 기반으로 유사도를 계산하여 유연성이 떨어지는 한계가 있다.
--> 이 문제를 해결하기 위해 VOPRec은 text 및 network representation learning 분야의 최신 연구를 활용해 비지도 학습 기반의 자동 특징 설계를 가능하게 한다.
- 논문의 텍스트 정보를 word embedding을 통해 표현함으로써 유사한 연구주제를 가진 논문을 찾는다.
여기서 논문의 structural identity가 vector로 변환되어 유사한 network 구조를 가진 논문을 찾는 데 사용된다. - 인용 네트워크를 통해 text information과 structural identity를 연결함으로써 논문의 vector 표현을 network embedding으로 학습한다.
- 학습된 논문 벡터간의 유사도에 따라 Top-Q recommender list를 생성한다.
활용한 데이터셋 : APS(American Physical Society)
Precision(정밀도), Recall(재현율), F1-score, NDCG(Normalized Discounted Cumulativ Gain) 지표에서 기존의 최첨단 논문 추천 모델들을 능가함
Introduction
최근 수년동안 SCI논문의 생산량이 급증하면서, 학술 데이터의 폭팔적인 성장이 이루어지며 이에 따라 Scholarly Big data(학술 빅데이터)라는 용어가 생겨났다. 여기서 말하는 학술 빅데이터는 수백만명의 저자, 논문, 인용, 표 그리고 방대한 규모의 관련 데이터 (인용 네트워크)를 포함한다. 연구자들의 경우 특정 연구를 시작하려면 기존의 관련 논문들을 읽고 분석해야 하지만, publications들이 급격하게 증가하게 되면서 서지 검색만으로 관련 논문들을 찾는 일은 매우 어려고 복잡한 문제가 되었다.
문제를 해결하기 위해 학술 검색 엔진(springer Nature, Elsevier)등에서는 논문 추천 시스템을 활발히 개발하고 있다. ex) springer nature의 digital research assistant는 사용자가 nature.com 및 springerlink에서 최근에 나온 100개의 논문을 분석하여 개인 맞춤형 논문 추천을 제공한다.
지난 16년간 200편이상의 논문 추천 시스템 관련 연구 논문이 발표되었다.
논문 추천 시스템은 주로 사용된 기법에 따라 세가지 범주로 나눌 수 있다.
- 콘텐츠 기반 필터링(Content-Based Filtering)
- 협업 필터링(Collaborative Filtering)
- 그래프 기반 추천(Graph-Based Recommendation)
논문 추천의 핵심은 논문간의 유사도 계산에 있다.
Related Work
Big data era에 접어들면서 학술 데이터셋은 점점 더 방대해지고 있고, 이로인해 information overload 현상이 발생하고 있다. 이를 해결하기위해서 학술 추천시스템이 개발되었으며, 이들은 연구자들에게 관련있고 적합한 item (협업자, 학회/저널, 논문)을 추천해준다.
기존방식은 크게 3가지 범주로 나뉜다.
- 콘텐츠 기반 필터링
- 협업 필터링
- 그래프 기반 추천
A. Content-Based Paper Recommendation
- 논문 추천 분야에서 가장 일반적이고 기본적인 추천 기법
- 이 방식의 핵심은 scholar profiling인데, 연구자의 과거 논문 내용을 기반으로 관심사를 추론하고 이를 통해 추천을 수행
- 추천 리스트는 연구자 프로필과 후보 논문간의 코사인 유사도, 벡터 공간 모델 등을 계산하여 생성된다.
특징
- 텍스트는 논문 제목, 초고, 키워드, 본문 등에서 추출되며, 주로 단어 기반 특징을 사용
- 일부 연구는 단어 기반 특징을 확장하여 n-gram, topic, concept 등의 고차원 특징을 사용하며 이는 LDA (latent Dirichlet Allocation)등을 통해 추출된다.
- 대표적인 연구로, sugiyama와 kan은 저자의 과거 논문들이 해당 연구자의 잠재적 관심사를 반영한다는 가정하에, 참고문헌 및 피인용 논문 정보를 함께 반영해 추천 정확도를 향상 시켰다.
B. Collaborative Filtering-Based Paper Recommendation
- 협업 필터링은 데이터 추천에서 가장 성공적인 방법 중 하나로, 다른 유사한 사용자들의 의견을 기반으로 항목을 추천한다.
- 사용자가 동일한 항목에 대해 비슷한 평가를 할 경우, 그들은 유사한 성향을 가진것으로 간주되며, 해당 항목이 추천된다.
문제점
- cold start 문제가 크다. 대부분의 연구자들은 읽거나 인용한 논문에 대해 명시적인 평가를 하지 않는다.
- 일부 reference 관리도구(endnote)에서 평가 기능을 제공하기 하지만, 데이터가 작아 신뢰도 있는 추천생성에는 부족하다.
해결방안
implicit ratings(암묵적 평가) 활용
- 논문을 인용했다면 이는 긍정적인 평가로 간주한다.
- 두명의 연구자가 같은 논문을 인용했다면, 그들은 유사한 성향을 가진것으로 간주한다.
- Liu 등은 문맥 기반 협업 필터링을 제안했고, 인용된 논문이 서로 자주 공통으로 등장하면 두 논문이 유사하다고 판단한다.
C. Graph-Based Paper Recommendation
- 이 기법은 인용 네트워크에서 논문 간 연결 관계를 기반으로 한다. 즉, 한 논문이 다른 논문을 인용하면 두 논문이 연결된다.
- 네트워크 상에서의 추천은 citation link prediction 문제로 간주된다
--> 일부는 heterogeneous academic networks를 구성하여 저자, 학회, 논문 등 다양한 entity를 고려한다.
기존 연구들은 주로 degree(차수), common neighbors(공통 이웃수) 등 수작업 특징(hand-engineered features)을 사용해 논문의 유사도를 계산함
최근에는 network representation learning이 등장하면서 논문 간 구조정보를 embedding으로 학습하여 추천 정확도를 높이고 있다.
대표적인 연구로, strohman은 텍스트 특징 + 인용 그래프 특징을 조합한 추천 시스템을 제안하였는데, 특히 논문 간 참고문헌 유사도와 네트워크 내 거리 (katz distance)가 중요 특징임을 확인하였다.
Sugiyama등은 협업 필터링을 사용해 citation network 내에서 potential citation papers을 식별하였다.
논문의 어느 section이 추천에 유리한지를 분석하여 논문 구조 자체에 대한 분석도 수행하였다.
Baseline Methods
1. Doc2Vec
- 텍스트를 벡터로 표현하기 위한 텍스트 기반 방법으로, 3계층 신경망을 기반으로 한다. PV-DM모델은 대상 단어 주변의 문맥을 입력으로 사용하고, 매핑 계층에서 가중치를 적용한 후 대상 단어를 출력
2. Struc2Vec
- 네트워크 상의 노드 구조적 유사성을 고려하여 노드의 구조적 정체성(structural Identity)을 포착하는 표현 학습 방법. 다중 계층 그래프를 고려
3. DeepWalk
- 네트워크 기반 표현 학습 방법으로, 네트워크 상에서 임의의 경로를 생성해 이를 문장으로 간주하고, 노드를 단어처럼 취급하여 Skip-Gram 알고리즘을 적용해 노드 표현을 학습한다.
4. CCF (Context-Based Collaborative Filtering)
- 인용 문맥으로부터 각 인용 논문의 표현을 추출한 후 협업 필터링 알고리즘을 적용하여 논문 추천을 수행하는 문맥 기반 협업 필터링 방법
Network Embedding(네트워크 임베딩) 접근 방식
신경망 기반의 비지도 학습을 통해 저차원의 잠재 vector를 생성하는 접근방식
내용정보 + 구조 정보를 혼합하려는 시도도 있었다. 이러한 흐름에 영향을 받아 인용 네트워크에서 논문의 벡터표현(Vector representation of papers)을 학습하여 텍스트 정보와 네트워크 구조를 모두 반영한 논문 추천 수행
Main Idea: 논문을 인용네트워크에서 vector로 표현함으로써 논문간의 유사도를 vector간 거리 (코사인 유사도)로 계산할 수있도록 하는 것
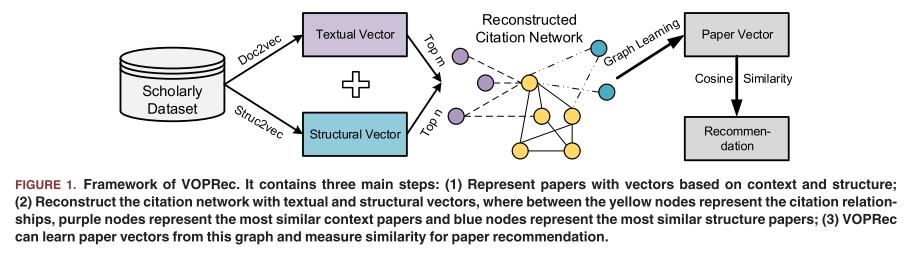
Figure 1 VOPRec의 전체구조
- 논문의 text information으로 부터 text embedding vector를 생성
- 논문의 structural identity(구조적 정체성)으로부터 구조 vector를 생성한 다음,
- 텍스트 기반 이웃(m-nearest neigh bors)과 구조 기반 이웃(n-nearest neighbors)을 연결하여 인용 네트워크를 재구성
- 재구성된 네트워크에서 vector 표현을 학습
- vector간 코사인 유사도를 계산하여 논문 추천 결과를 도출
Contribution
- 문서 임베딩과 단어 임베딩을 결합하여 논문의 텍스트 표현을 학습하고, 이를 통해 논문 간의 주제 및 맥락 유사도를 평가할 수 있는 방법을 제시
- multi layer citation network를 활용하여 논문간 구조 유사도를 측정할 수 있는 구조 표현 학습 방법 제시
- 텍스트 정보와 구조적 정체성을 모두 고려한 가중 인용 네트워크 기반 논문 벡터 표현 학습 모델인 VOPRec 제안
- 실제 APS dataset을 활용한 광범위한 실험을 통해 콘텐츠 기반, 협업 필터링 기반, 네트워크 표현 학습 기반 기법들과 비교하여 우수한 성능 검증
citation network는 논문 추천에서 매우 중요한 역할을 한다. 인용 네트워크를 G = (V,E)로 정의할 때, 각 엣지 e∈E와 vi와 vj사이의 인용관계를 의미한다. 본 연구에서는 인용방향(들어오는 인용과 나가는 인용)을 구분하지 않으므로, 그래프 G는 무방향 그래프로 간주된다. 추천의 정확도를 높이기 위해 인용한 논문과 인용받은 논문 모두를 포함한다.
그래프 G를 기반으로 논문들을 벡터로 표현한 잠재표현 행렬을 학습하는데, 논문의 문맥 의미(context-semantic)와 network structural의 관계를 포착하기 위해 새로운 그래프를 구성한다. E'은 새로 생성된 edge들의 집합이다.
Matrix Factorization
Yang의 연구에 의하면, network representation learning은 Matrix factorization으로부터 유도된다.
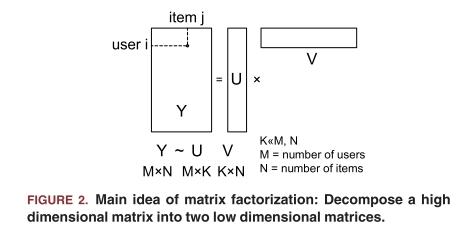
기존 추천 시스템에서는 사용자와 아에템이 각각이 고유의 특징 벡터를 가진다.
행렬분해의 기본 아이디어는 사용자-속성 행렬과 아이템-속성 행렬을 평점 행렬로부터 분해하는 것이다.
이방식은 차원을 축소하고 동시에 사용자의 선호도와 아이템의 특성을 파악할 수 있는 장점이 있다.

기본적인 행렬분해 공식은 아래의 수식으로 표현된다.
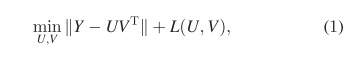
여기서 L(U,V)는 편향-분산 균형을 위한 정규화 항이다. 논문 네트워크 표현의 경우 각 논문은 k-차원의 벡터 r로 임베딩되며, 문맥노드 v는 c로 표현된다.
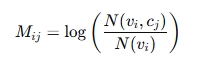
skip-gram with negative sampling을 기반으로 행렬 M을 정의하였는데, 여기서 N(v,c)는 무작위 보행(random walk)을 통해 두 노드가 동시에 등장한 횟수이며, N(v)는 노드 v가 등장한 총 횟수이다.
확률은 아래와 같이 계산 된다.

여기서 A는 전이행렬(transition matrix) ei는 초기 상태 벡터, t는 보행의 단계 수를 의미한다. 따라서 이식은 노드 i에서 시작해 t단계 내에 노드 j로 이동할 평균 확률을 나타낸다.
VOPREC Framwork
논문 텍스트 정보로부터 context representation을, 인용 네트워크로부터 node representation을 학습하여 대상 논문에 대해 관련 논문을 추천하는 framework를 제안한다.
- Text Learning
- document embedding과 word embedding을 결합하여 논문들의 text표현을 생성한다.
- 논문간의 context similarity를 평가할 수 있다.
- Structure Learning
- multi layer citation network로부터 각 논문의 구조적 context를 생성
- 단일 층 내 유사도 뿐만이 아니라, 층 간 구조 유사도를 고려한다.
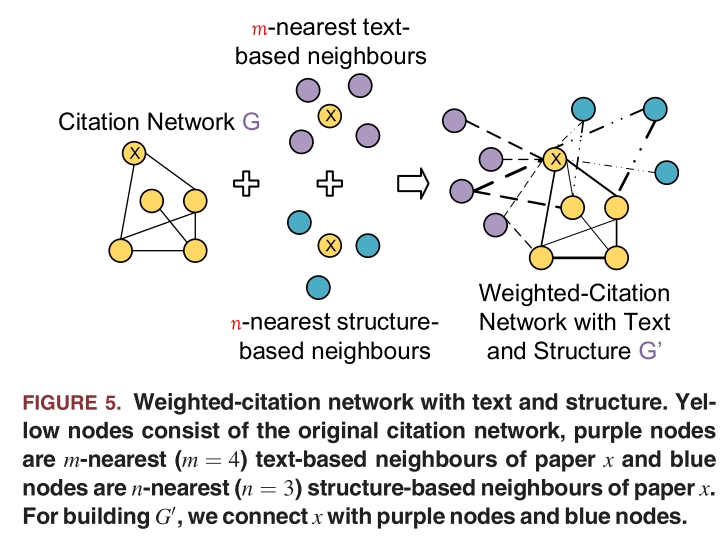
- Brdging Weighted-citation graph with text and structure
- 텍스트 기반 최근접 이웃 m개, 구조기반 최근접 이웃 n개를 인용 네트워크 상에서 연결
edge에 text, structure, citation 정보 기반의 가중치를 부여하여 가중 그래프를 구축
- Learning from graph
- 가중 그래프 위에서 randomwalk로 생성된 논문 경로를 neighbour function에 추가
- skip gram model을 적용해 각 논문의 latent representation을 학습
- 학습된 vector를 기반으로 논문 간 유사도 계산 및 추천


절차 요약
- Doc2vec로부터 각 논문의 text vector WR을 학습
- Struc2vec로부터 각 논문의 structure vector SR을 학습
- 각 논문에 대해 text 유사도가 높은 m개의 논문을 찾는다
- 구조 유사도가 높은 n개의 논문을 찾는다
- text/structure기반 edge를 이용해 가중 인용 그래프 G'을 구성
- 각 edge의 가중치 계산
- G'에서 randomwalk로 논문 경로들 생성
- skip-gram으로 논문 vector 학습
- 각 논문에 대해 유사한 q개의 논문 추천
A. Text Learning
- 각 논문에 대한 텍스트 기반 벡터를 얻는다.
논문 텍스트 표현학습은 Paper2vec의 방법에서 영감을 받았고, 논문의 텍스트 정보 = 제목, 초록, 또는 본문으로 구성된다. 텍스트정보를 모아 T = {t1,t2, ... , tv}라는 말뭉치를 구축한다.
Doc2vec 기반으로 각 논문의 정보를 하나의 문서로 간주하고 학습한다. 각 논문은 행렬 P의 열로 표현되고 각 단어는 행렬 WD의 열 vector로 매핑된다.
논문 vector는 실제로 하나의 단어 vector처럼 작용하여 문맥 내 빈 공간을 채우는 역할을 한다. 학습 데이터로는 윈도우 win내의 단어 sequence를 사용하여 문맥을 예측한다. 목표는 다음과 같은 평균 로그 확률을 최대화하는 것이다.
예측은 hierarchical softmax 방식으로 수행되며 번번한 단어에 짧은 이진 코드가 할당된다. 여기서 h는 단어 벡터와 문서 벡터의 평균으로 구서오디고 모든 논문은 PV-DM 모델을 통해 훈련되며 최종적으로 벡터 공간 R에 매핑된다. 이 공간에서 유사한 논문들은 가까이 위치한다.
B. Structure Learning
- Struc2vec 알고리즘을 기반으로 인용 네트워크에서 각 논문의 구조적 벡터를 얻는다. 다른 속성 없이 순수히 네트워크 구조만으로 node간의 유사성을 측정한다.
C. Bridging with Citation Graph
- 논문들의 텍스트 및 구조 기반 벡터를 얻은 뒤, 이를 인용 네트워크에 통합한다.
텍스트 기반 이웃과 구조 기반 이웃을 edge로 추가하여 새로운 네트워크 G''을 생성한다.
edge 가중치 설정
텍스트 기반 or 구조 기반 이웃: 0.5
두 조건을 모두 만족하면: 0.5 + 0.5 = 1.0
인용 관계: 기본적으로 0.5 + Amsler 유사도 적용
D. Learning from Graph
새로 구성된 가중치 네트워크 G''에서 각 논문 vi에 대해 가중치 기반 randomwalk를 수행한다.
DeepWalk 방식과 유사하게 이러한 randomwalk sequence를 생성하고 Skip-Gram model로 학습한다.
목표함수 (hierarchical sofmax 기반)는 확률적 경사 하강법 (SGD)로 최적화되며 최종 논문 vector x를 얻는다.
최종적으로 각 논문 vi에 대해 vector xvi가 얻어졌고, 모든 논문 간 코사인 유사도를 계산하여 가장 유사한 Q개의 논문을 추천한다.