예전 포스팅에서 Attention에 대해 다룬적이 있다
아래 포스팅들을 먼저 읽으면 도움이 될 것이다
Attenion 관련 지난포스팅
RNN 포스팅
조금 더 명확하고 구체적이게 다시한번 작성해보겠다.
Attention의 컨셉은 각 시점별로 (같은 가중치가 아닌) 더 중요하게 관찰하고자 하는 것이다. GNN에서는 이러한 Attention을 사용하여 GAT의 형태로 쓰인다.
해당 영상을 많이 참고했다.
고려대 김성범 교수님 랩실 유튜브
문장 번역의 예시를 통해 Attention을 이해해보자
0. RNN
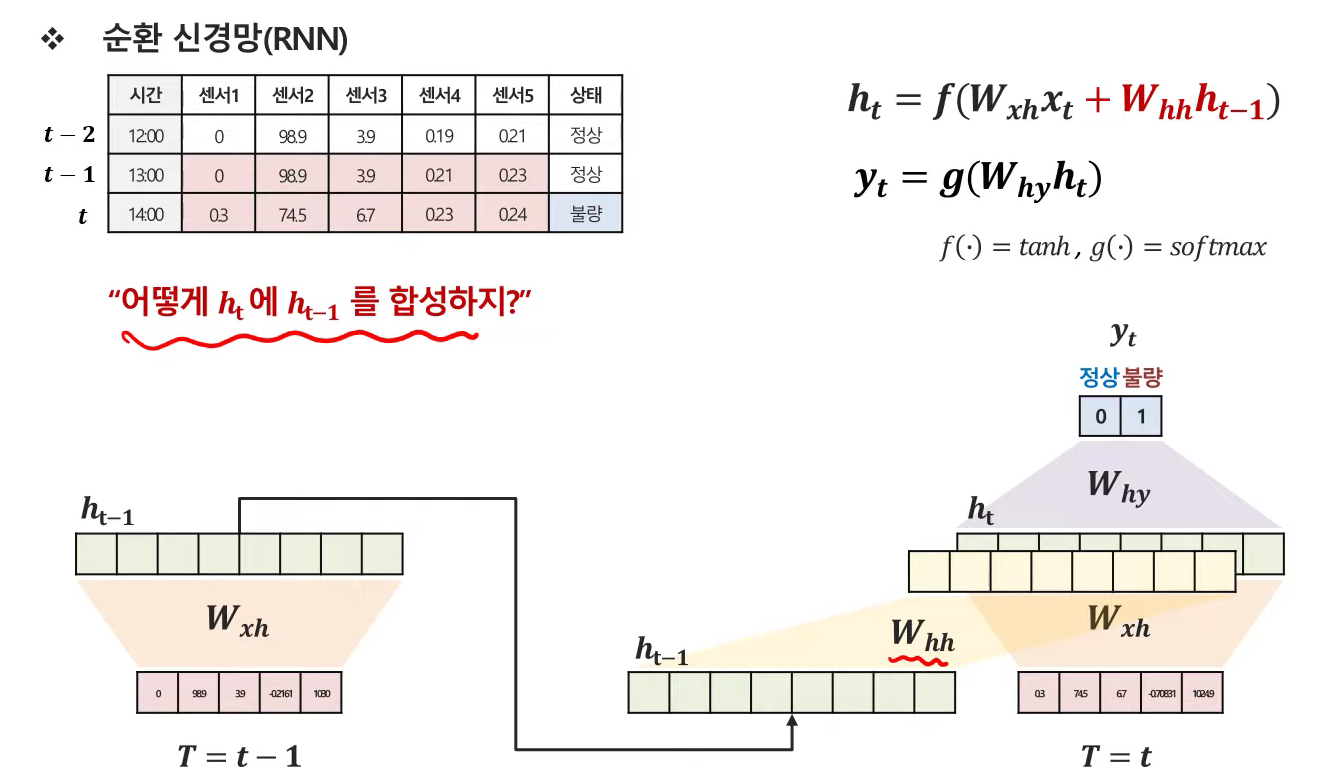
- 이전 정보를 갖고온다는 것은, hidden vector를 갖고와서 가중치를 곱해서 더해주는 것임.
1. Seq2Seq
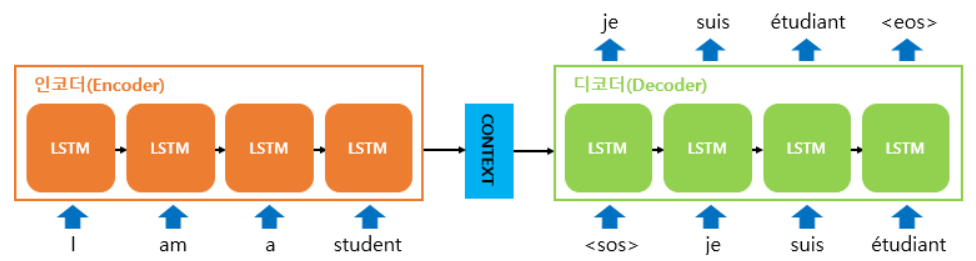
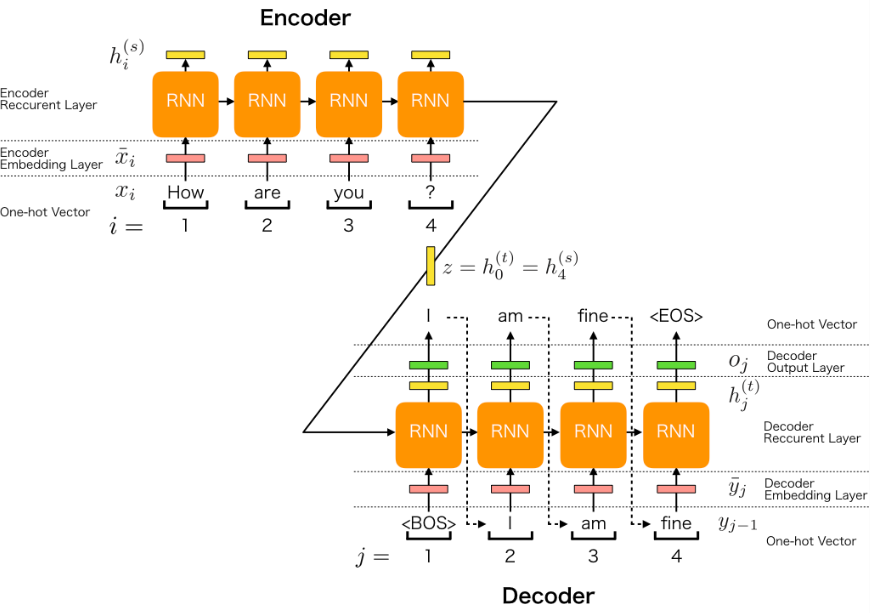
- Encoder : 입력 문장의 단어들을 순차적으로 입력 받은 뒤, 각 토큰은 RNN셀의 입력이 된다. 인코더 셀의 마지막 시점의 hidden state는 디코더 셀로 넘어가는데 이를 Context Vector라 한다
- 이 때 Context Vector는 I ~ stdent까지의 모든 정보를 갖고있는 하나의 Vector인데, 디코더에서 번역을 할때 이 하나의 Context Vector 만을 활용해서 번역하게 된다
- 고정된 Context Vector 를 사용하면 각 단어 예측 시 더 중요하게 집중해야하는 인코더 부분의 단어가 다른데, 뭘 번역하든지 다 똑같은것만 참고하게 되니까 이러한 중요도를 반영할 수가 없는 문제점이 있다
2. Attention
- 시점마다 Context Vector 를 다르게 생성하고 : 디코더의 매 부분마다 새로운 Context Vector 생성
- 이를 중요도(유사도 => Cos 내적연산)를 통해 생성한다
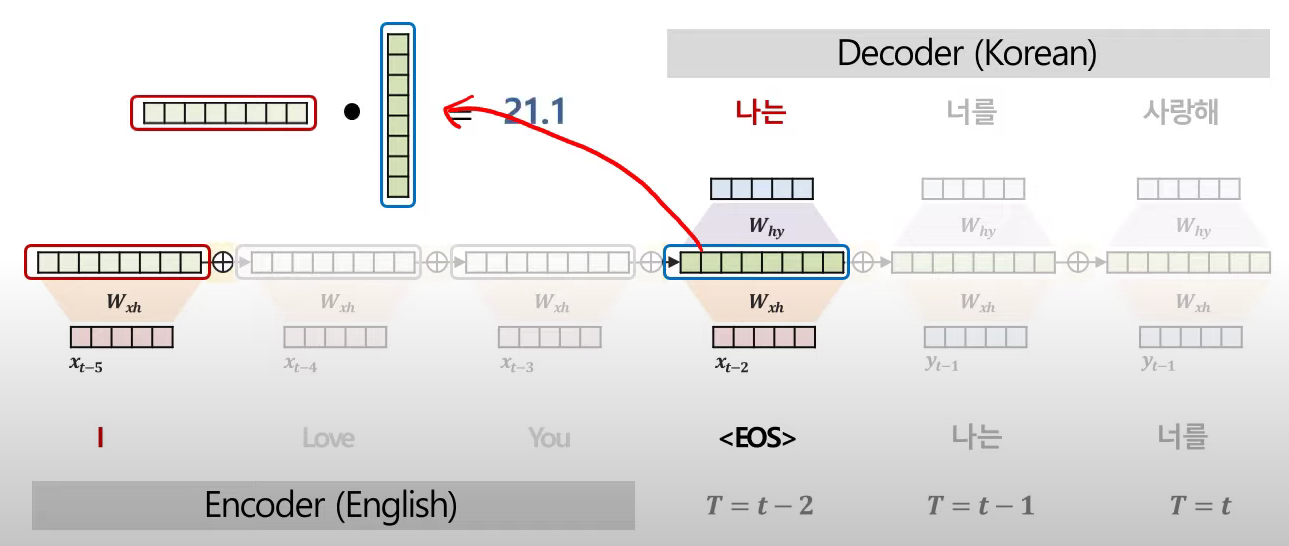
- 첫번째 시점(t-2 시점)에서의 Context Vector를 생성하기 위해 인코더 부분의 단어 벡터들과 각각 Cos 유사도(내적)를 계산하여 얼마나 유사한지(중요한지)를 산출한다.
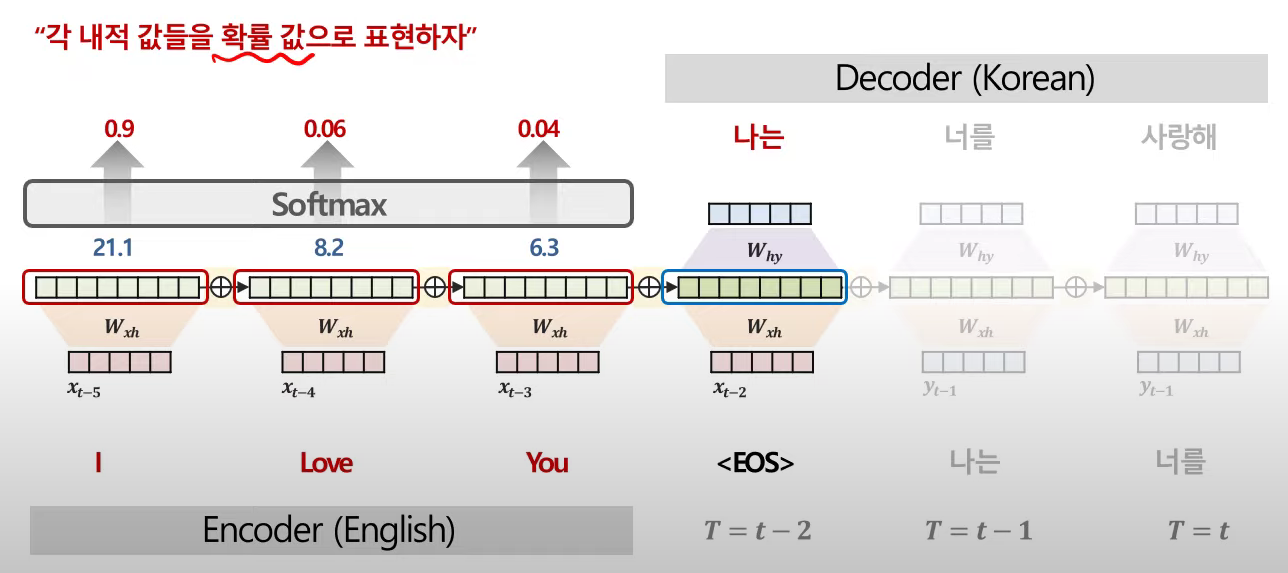
- 각 단어들에 대해 위의 과정을 진행하고, 이를 softmax를 통과시켜 확률 값으로 표현한다
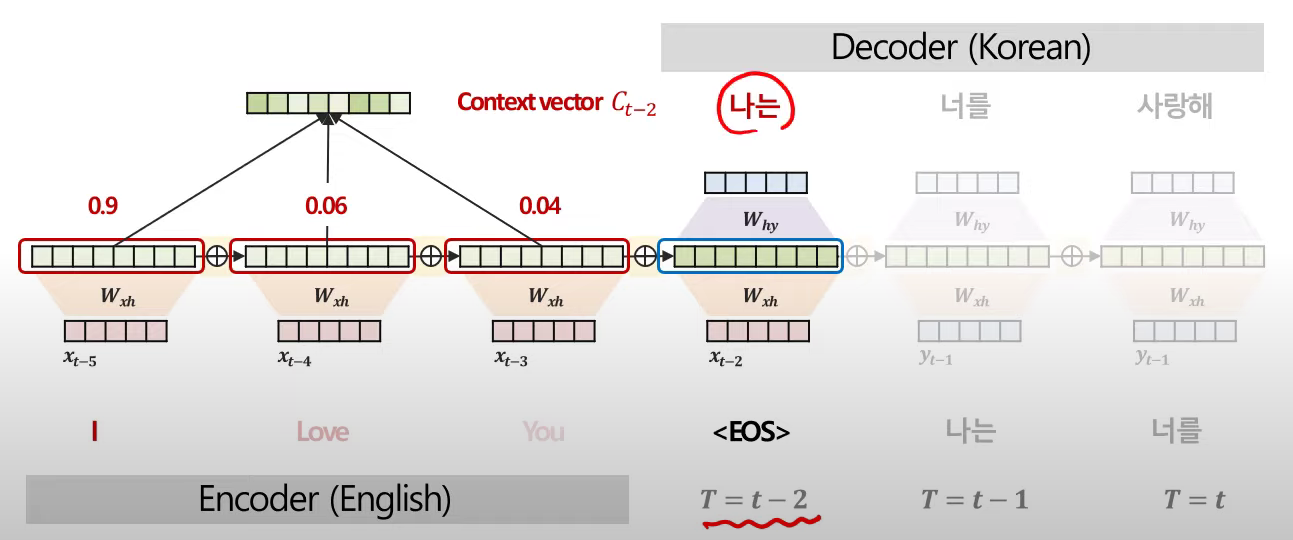
- softmax를 거친 값들을 weighted sum하여 현재 시점(t-2시점)에 대한 Context Vector를 생성한다
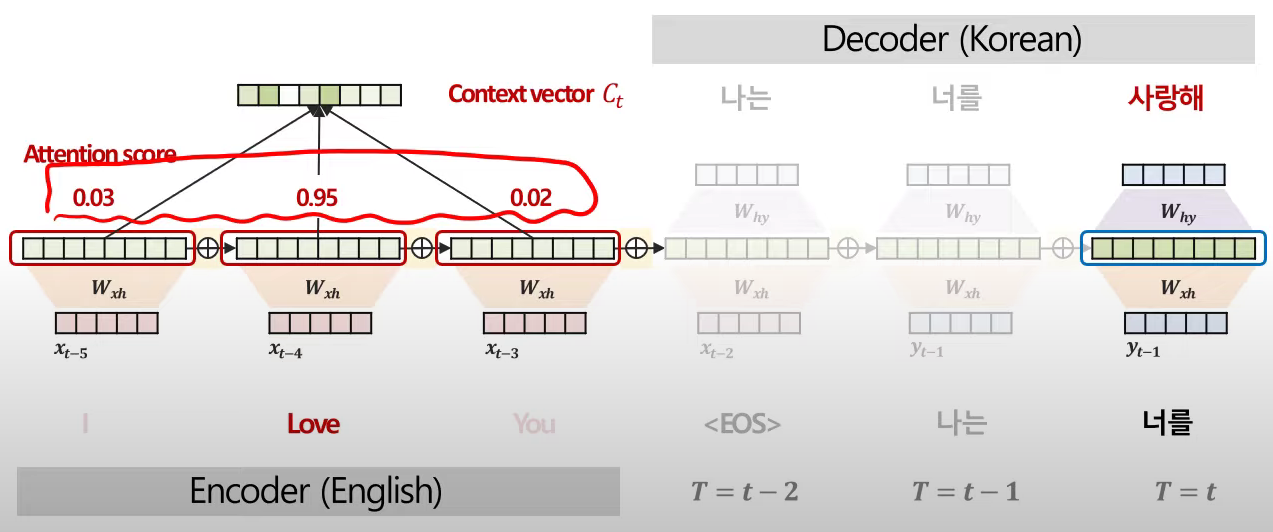
- 위의 과정을 디코더 단어별로 진행한다 : 시점 별로 각기 다른 내적 값, Context Vector 를 얻게된다
- 이때 cos 유사도를 softmax에 넣어 얻은 확률값을 'Attention score'라 한다
3. Feedforward Attention Mechanism
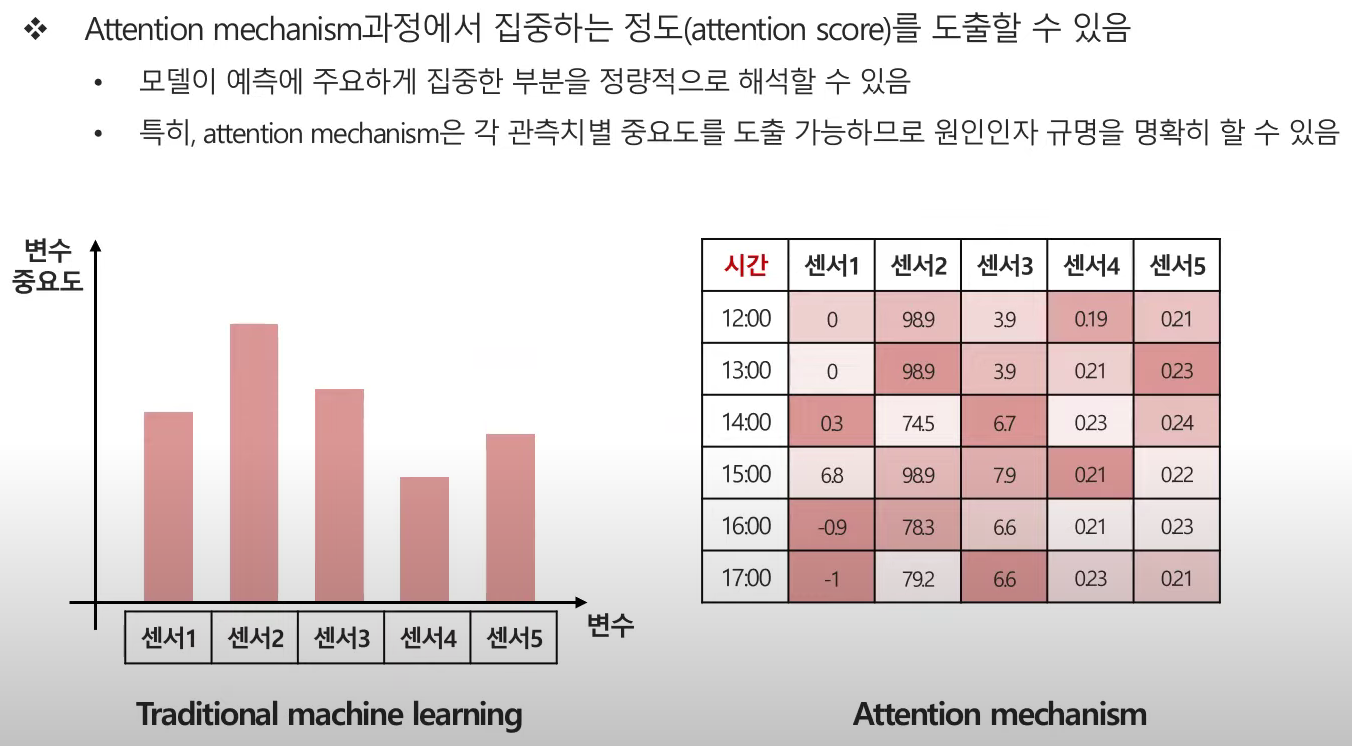
- As - Is : 전체 시점에서 어떤 변수가 중요한지를 얻을 수 있었음. 즉 Overall한 feature importance였음
- To - Be : 전체 시점 뿐만 아니라, 각 시점별로 중요도를 알 수 있게 되었음 => 특징 시점에 문제 발생시 원인 도출 및 빠른 대처가 가능해짐
- 이와 관련해서 다변량 시계열 데이터에서 변수간 상관관계를 학습하는 연구도 많이 이루어짐
- graph neural network-based anomaly detection in multivariate time series(2021, AAAI) 관련하여 추후 포스팅 예정
- 시점별로 평균처리하면 attention도 overall한 중요도 역시 당연히 구할 수 있음
- 이러한 부분들이 딥러닝의 단점인 '설명력'을 보완하는 부분이 됨. 모델을 통한 성능에 대해 시간에 따라 어떤 센서(어떤 변수)가 영향을 어떻게 주고 받았는지 해석할 수 있음.

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..