RAG 챗봇 아키텍쳐
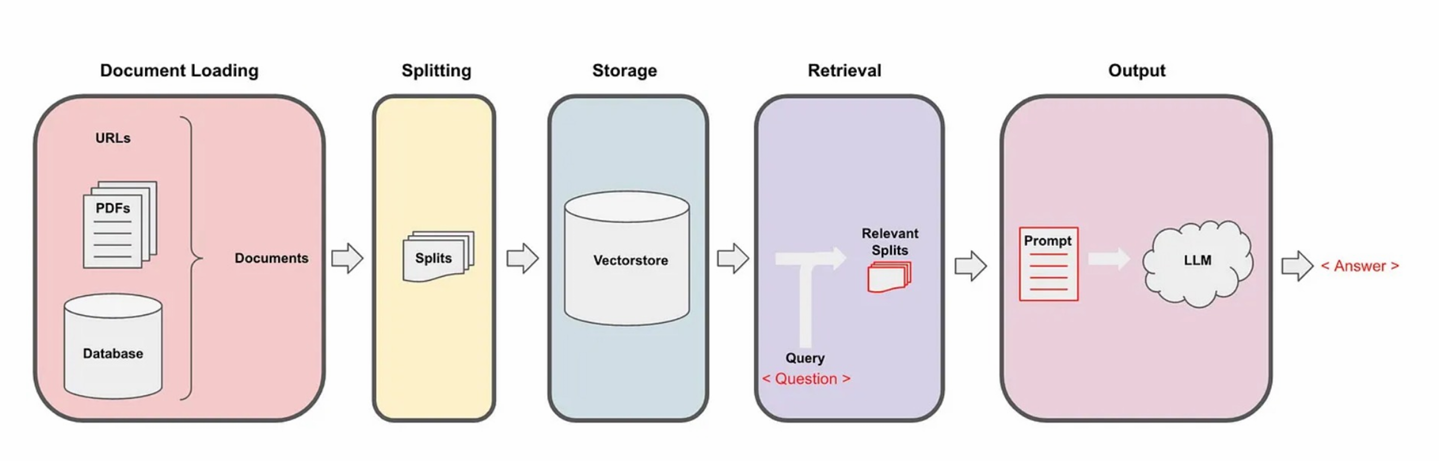
Raw unstructured data(e.g. pdf, txt, docs)를 QA chain으로 바꾸는 파이프라인
-
Loading:- 우리가 가진 데이터(pdf, txt, docs)를 로드한다.
- LangChain integration hub에 정말 많은 종류의 loader가 있다.
- input : pdf, txt, docs 등 파일
- output : raw text
-
Splitting:- 모든 텍스트를 전부 참고할 수 있으면 좋겠지만 LLM의 max length 제한 때문에 긴 문서를 잘게 쪼개야 됨
- Text splitters 로
Documents를 특정한 사이즈의 split으로 나눈다. - input : raw text
- output : splited passages
-
Embedding- 나중에 Retriever에서 Query와 Document의 유사도를 계산하기 위해 Embedding(자연어를 Vector로 바꿔주기)을 함
- Storage (일반적으로 vectorstore)에 저장한다.
- 종류로는 Sparse Embedding, Dense Embedding (이전 게시물 참고)
- Sparse Embedding
- 대부분의 값이 0, 몇몇 위치만 1인 벡터로 표현
- 문장에 나오는 단어의 빈도를 기준으로 벡터를 만든다.
- tf-idf, BM25 등
- 겹치는 단어가 있다면 유사도가 높게 나오겠지만 단어간 의미적인 관계를 포착하지 못한다. - Dense Embedding
- 의미를 나타내는 실수 값들로 이루어진 벡터로 표현
- BERT와 같은 Pretrained Language Model이 주로 사용됨
-
Storage- 임베딩의 효율적인 저장 및 검색을 지원하는 데이터베이스
- input : splited passages, vectors
- output : Vector Database index
-
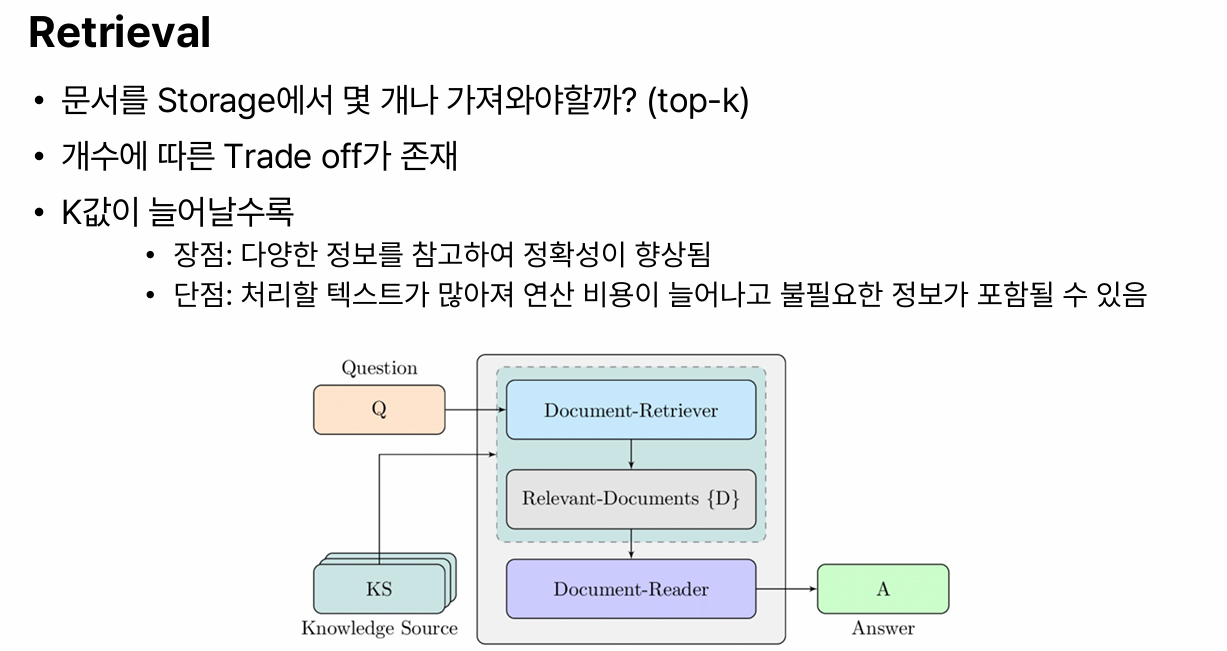
Retrieval:- 사용자의 input question이랑 유사한 임베딩 벡터를 찾아 관련있는 splits을 검색한다.
- 사용자에게 질문이 들어오면 그 질문과 관련있는 Splits를 Storage에서 가져온다.
- input : query
- output : relevent passages
-
Generation:- LLM은 유저의 질문과 retrieved된 문서를 참고해 답변을 생성한다.
- input : query, relevent passages
- output : 답변
Code Snippets
import streamlit as st
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
from langchain.callbacks.base import BaseCallbackHandler
from langchain.schema import ChatMessage
from dotenv import load_dotenv
load_dotenv()
# handle streaming conversation
class StreamHandler(BaseCallbackHandler):
def __init__(self, container, initial_text=""):
self.container = container
self.text = initial_text
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.text += token
self.container.markdown(self.text)
'''
RAG 챗봇 아키텍쳐
(1) Loading : 갖고있는 데이터를 로드함(pdf 등), loader 종류도 정말 많다
(2) Splitting : llm에는 max length가 있어 참고할 수 있는 텍스트가 한계가 있다. => input : raw text / output : splited passages
(3) Stroage : 자연어를 벡터로 바꿔서(임베딩) 저장한다 => 추후 input question과 유사도 계산을 하기위해 vector로 바꾸는것.
(4) Retrieval : 사용자 input question => (3)의 벡터 중 유사한 것을 찾아 관련있는 splits를 검색한다
(5) Generation => LLM : input question과 (4)로 얻은 retrieved data를 바탕으로 알맞은 답변을 생성한다 => input : query, relevent passages / output : 답변
'''
# Function to extract text from an PDF file
from pdfminer.high_level import extract_text
def get_pdf_text(filename):
raw_text = extract_text(filename)
return raw_text
# document preprocess
def process_uploaded_file(uploaded_file):
# Load document if file is uploaded
if uploaded_file is not None:
# (1) loader
raw_text = get_pdf_text(uploaded_file)
# (2) splitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 1000, # 청크가 포함할 수 있는 최대 문자 수
chunk_overlap = 200, # 인접한 두 청크 간에 겹칠 수 있는 문자 수
)
all_splits = text_splitter.create_documents([raw_text])
print("총 " + str(len(all_splits)) + "개의 passage")
# (3) storage
vectorstore = FAISS.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
return vectorstore, raw_text
return None
# generate response using RAG technic
def generate_response(query_text, vectorstore, callback):
# (4) retriever
docs_list = vectorstore.similarity_search(query_text, k=3) # 질문에 대한 유사도 높은 top - K 개의 splits들을 갖고온다
docs = ""
for i, doc in enumerate(docs_list):
docs += f"'문서{i+1}':{doc.page_content}\n"
# (5) generator
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0, streaming=True, callbacks=[callback])
# chaining
rag_prompt = [
SystemMessage( # SystemMessage란? : 모델에게 페르소나 및 답변의 조건을 정의하는 부분
content="너는 문서에 대해 질의응답을 하는 '문서봇'이야. 주어진 문서를 참고하여 사용자의 질문에 답변을 해줘. 문서에 내용이 정확하게 나와있지 않으면 대답하지 마." # 모델에 페르소나 및 지시사항
),
HumanMessage(
content=f"질문:{query_text}\n\n{docs}"
),
]
response = llm(rag_prompt)
return response.content
def generate_summarize(raw_text, callback): # 요약이라고 입력받을 때 수행되는 부분!
# generator
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0, streaming=True, callbacks=[callback])
# prompt formatting
rag_prompt = [
SystemMessage( # notion느낌으로 mark down을 활용해서 요약되는것이다.
content="다음 나올 문서를 'Notion style'로 요약해줘. 중요한 내용만."
),
HumanMessage(
content=raw_text
),
]
response = llm(rag_prompt)
return response.content
# page title
st.set_page_config(page_title='🦜🔗 문서 기반 요약 및 QA 챗봇')
st.title('🦜🔗 문서 기반 요약 및 QA 챗봇')
# file upload
uploaded_file = st.file_uploader('Upload an document', type=['pdf'])
# file upload logic
if uploaded_file:
vectorstore, raw_text = process_uploaded_file(uploaded_file)
if vectorstore:
st.session_state['vectorstore'] = vectorstore
st.session_state['raw_text'] = raw_text
# chatbot greatings
if "messages" not in st.session_state:
st.session_state["messages"] = [
ChatMessage(
role="assistant", content="안녕하세요! 저는 문서에 대한 이해를 도와주는 챗봇입니다. 어떤게 궁금하신가요?"
)
]
# conversation history print
for msg in st.session_state.messages:
st.chat_message(msg.role).write(msg.content)
# message interaction
if prompt := st.chat_input("'요약'이라고 입력해보세요!"):
st.session_state.messages.append(ChatMessage(role="user", content=prompt))
st.chat_message("user").write(prompt)
with st.chat_message("assistant"):
stream_handler = StreamHandler(st.empty())
# 1) 입력이 요약일경우 => generate_summarize 수행
if prompt == "요약":
response = generate_summarize(st.session_state['raw_text'],stream_handler)
st.session_state["messages"].append(
ChatMessage(role="assistant", content=response)
)
# 2) 그외 => generate_response 수행
else:
response = generate_response(prompt, st.session_state['vectorstore'], stream_handler)
st.session_state["messages"].append(
ChatMessage(role="assistant", content=response)
)https://github.com/langchain-ai/langchain
- LangChain 튜토리얼

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..