본 포스팅에 사용된 이미지는 허민석님 유튜브 채널에서 참고하였음을 밝힙니다.
이전 포스팅인 RNN에서 LSTM을 소개하기 전 딥러닝에서 기울기 소실,폭발 이란 개념에 대해 알아보겠습니다
기울기 소실과 폭발
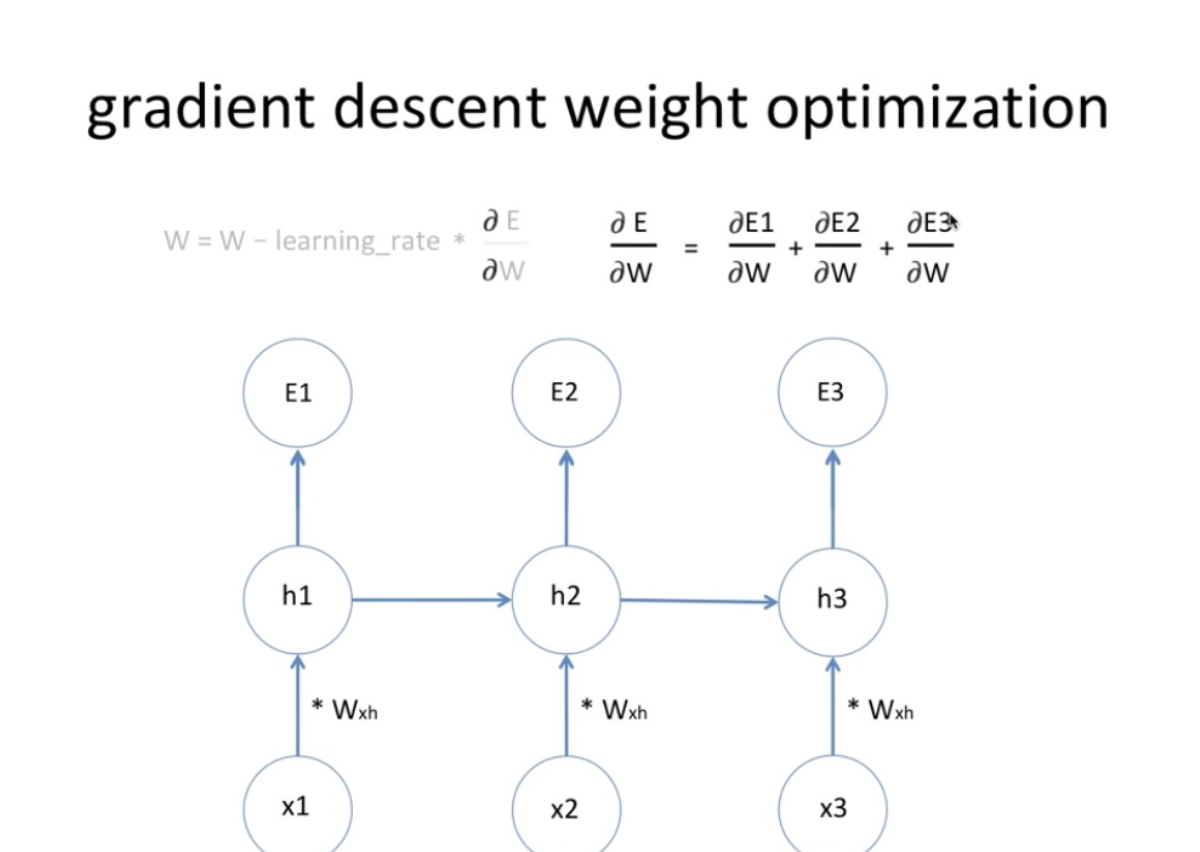
- 딥러닝의 학습은 w,b를 역전파의 과정으로 갱신해나가는 것입니다.
- w_new = 기존w - learing rate*기울기(=w가 전체 오차에 얼마나 영향을 주는가)
- 기울기 = e1이 영향을 미치는정도 + e2가 영향을 미치는 정도 + e3이 영향을 미치는 정도
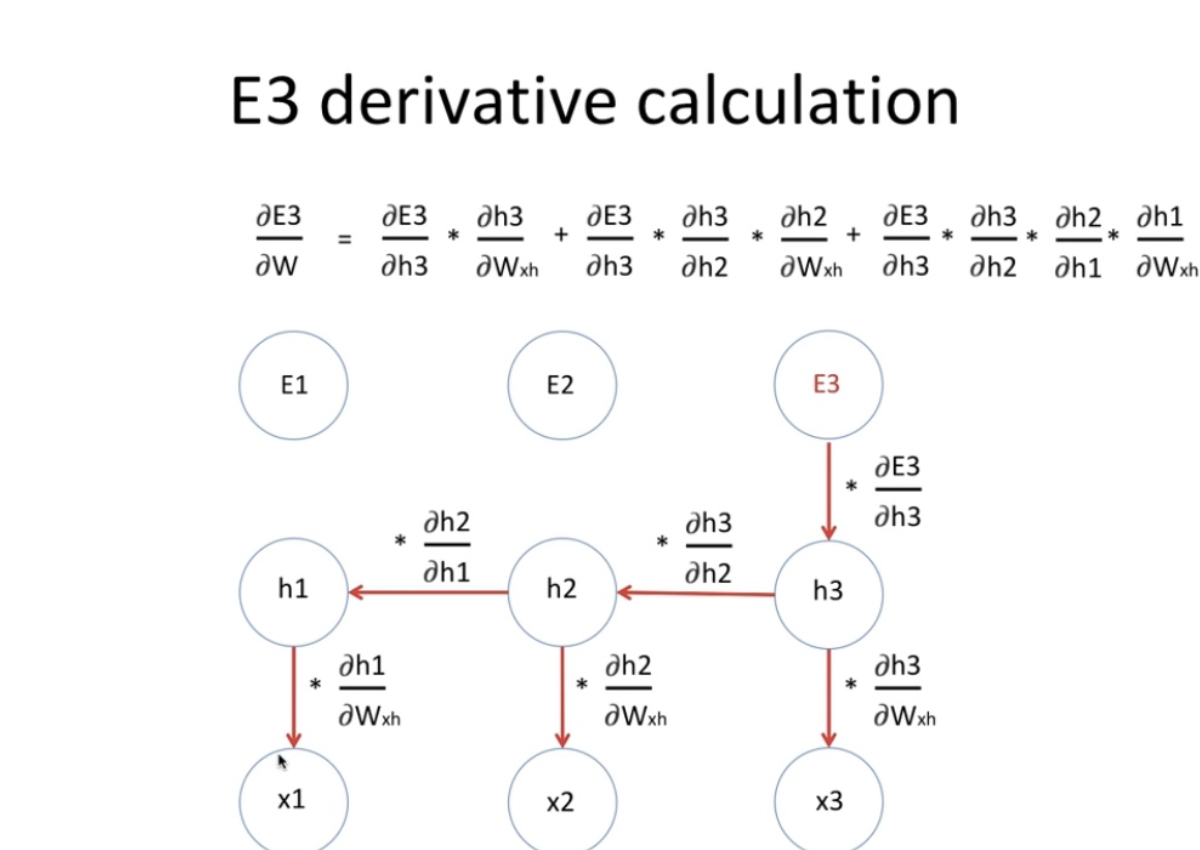
- e3에 영향 미치는정도 = state3 미분값 정보 + state2 미분값 정보 + state1 미분값 정보
- 이렇게 연쇄적으로 길어짐
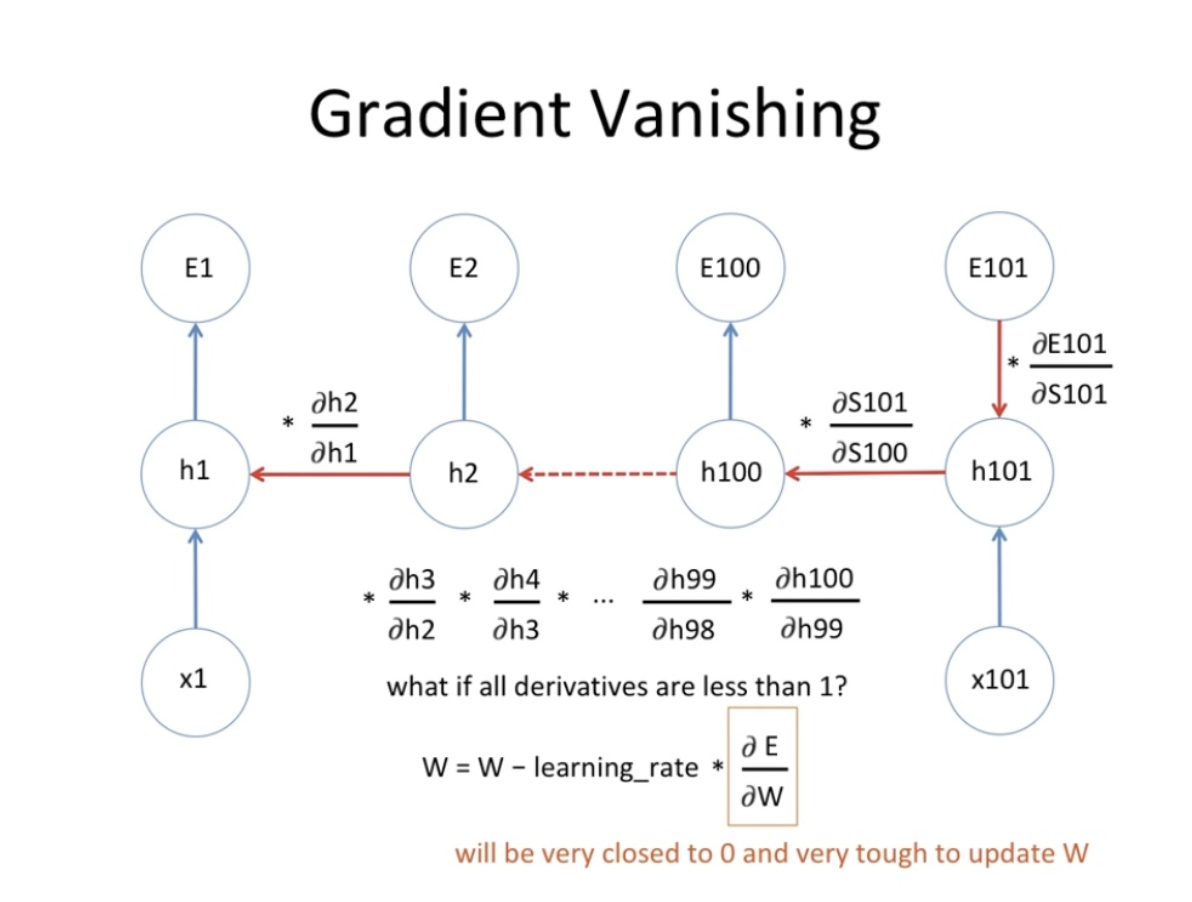
- 시퀀스가 매우 길어진 경우 다음과 같은 문제가 발생할 수 있습니다 (들어가는 문장이 100개 정도로 구성되는 경우)
- 기울기값이 1보다 작은 경우
- 100번 곱하면 0에 가까워짐 ⇒ 기존 w와 차이가 없어지는셈 (lr에 0이 곱해지는 셈)
- 기울기값이 1보다 큰 경우
- 100번 곱하면 w가 매우 커짐 , 그리고 왔다갔다 함 ⇒ 한곳으로 수렴하지가 않음
- 기울기값이 1보다 작은 경우
LSTM
위와 같은 문제를 해결하기 위해서 기억을 할 수 있다는 개념인 'MEMORY CELL'이 있는 LSTM이 도입됨
LSTM : 셀의 정보를 어떤걸 기억하고 어떤것을 잊을지 결정하는 알고리즘
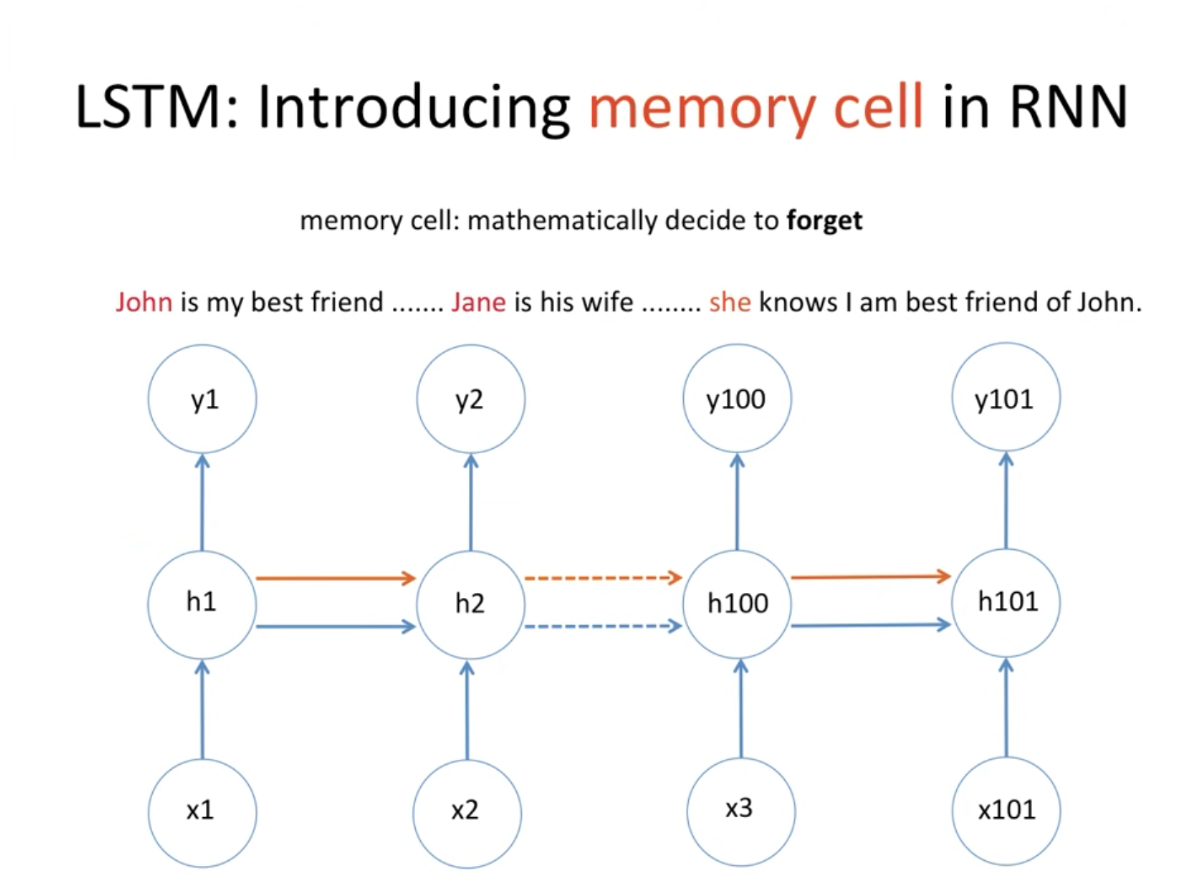
- 주황색 선이 memory cell인데, 앞에 문장에 따라 빈칸에 대명사를 유추한다고 할 때 John은 남자이지만 jane이 등장함에따라 John정보는 잊고, Jane정보는 기억하고 있어야함
- 이렇게 무엇을 잊고 무엇을 기억해야 할지에 대해 수학적으로 공식이 있음
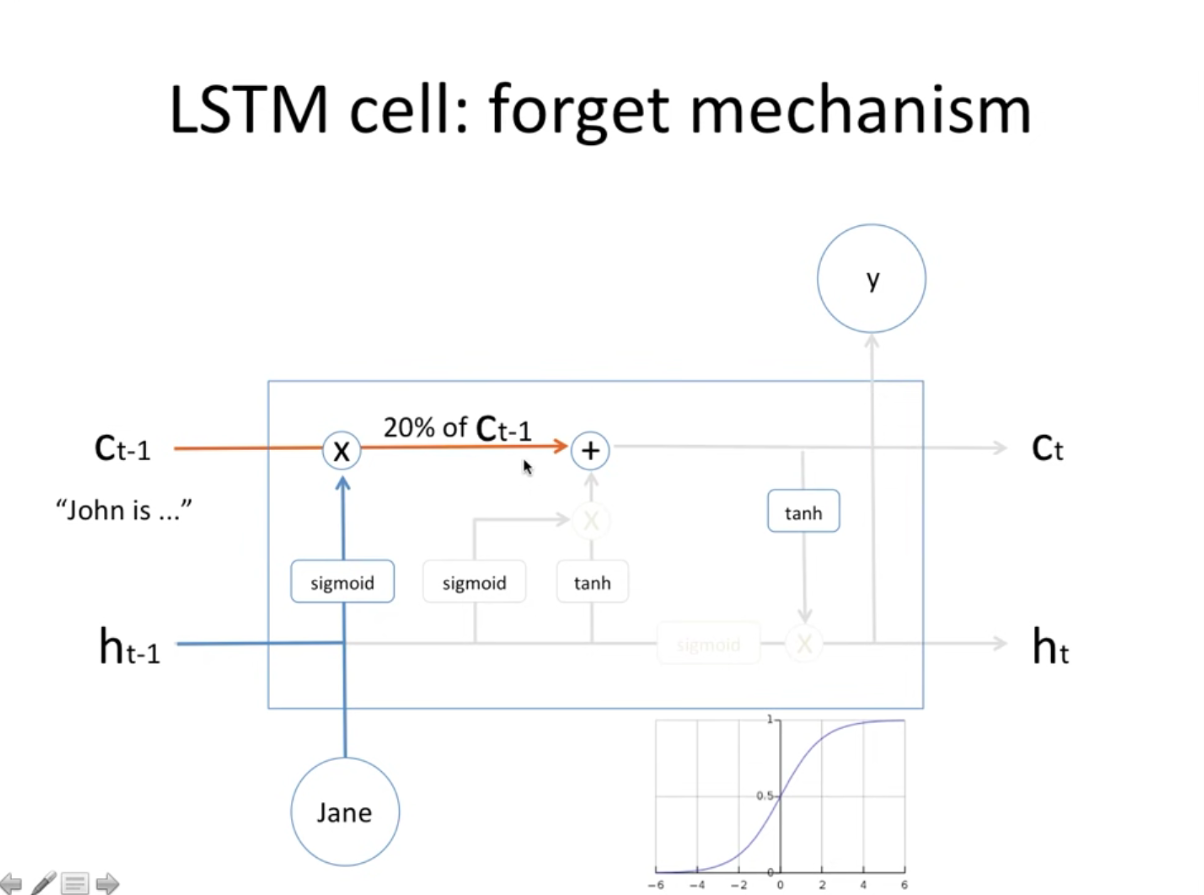
- 시그모이드는 0~1 (곧 확률값) : Jane이란 정보가 등장함에 따라 그 전에 기억하고 있는 정보(C t-1=john)는 sigmoid(Jane)과 곱해진채로 20%를 기억하게됨 (잊게 된다는거)
- 시그모이드 전에 당연히 w,b 다 있음
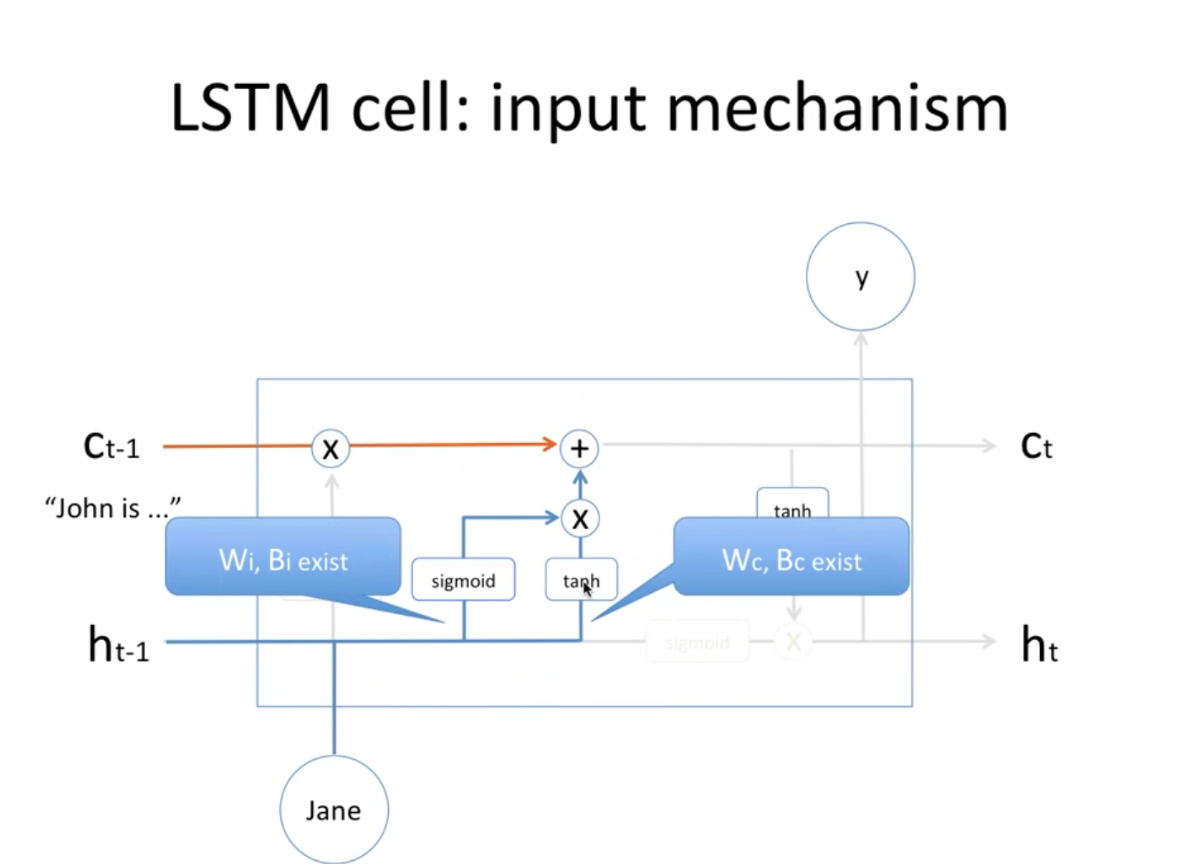
- 이렇게 그전 메모리셀 정보는 0.2만큼 곱해져서 더해지게 되고, 그전 state는 (h t-1) sigmoid와 tahn 거쳐서 새로운 메모리셀에 담게됨
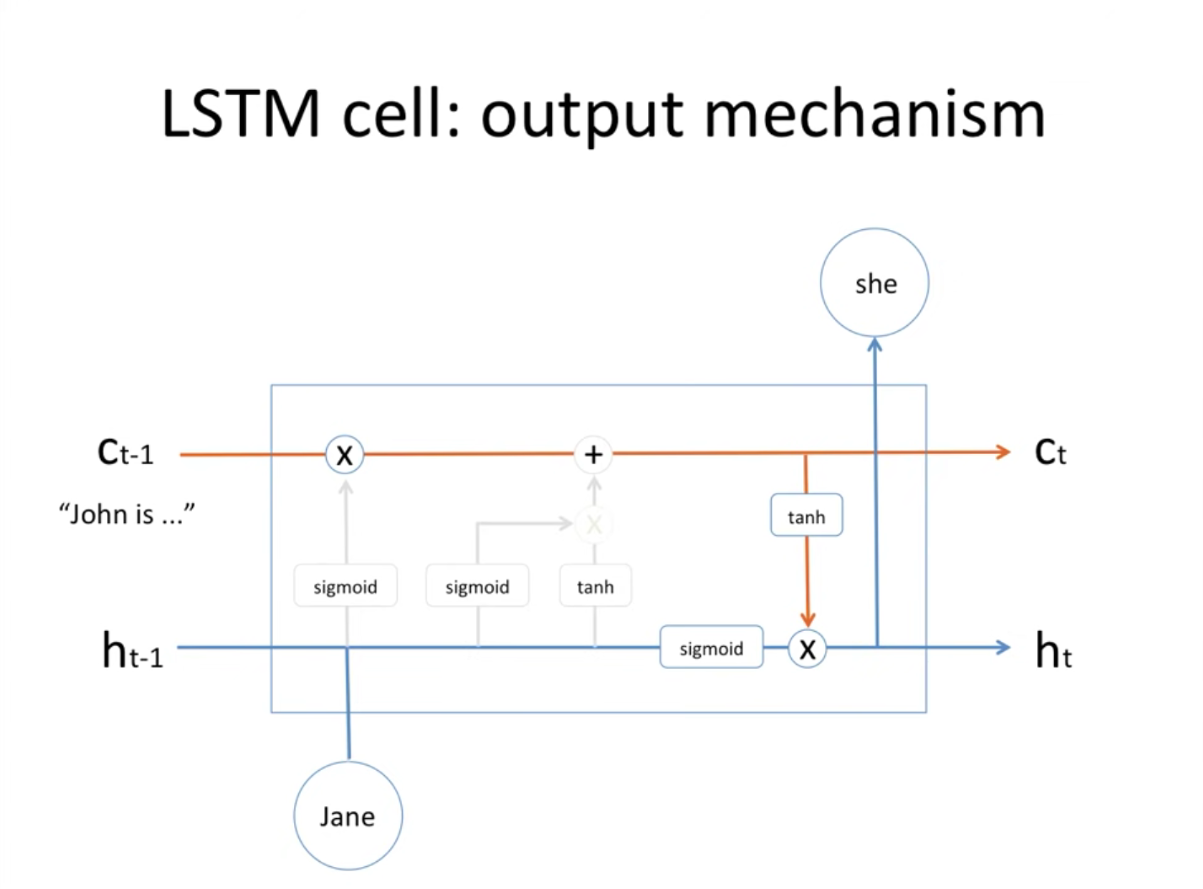
- 이렇게 올라가게 된 메모리셀 정보가 tanh 거쳐서 sigmoid(이전 state)와 곱해져서 state가 갱신되고 output으로 ‘she’라는 값도 내놓는것임

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..