- CNN의 구조는 다음과 같이 구성되어 있습니다.
- 이미지 input => 필터(=커널, & 패딩 : 피쳐맵) => 활성화함수(=액티배이션맵, 'relu') => 풀링 => Flatten & regression
- 출력층에서의 activation은 softmax(다중분류), sigmoid(이진분류) 등이 있음
1. CNN : what & why
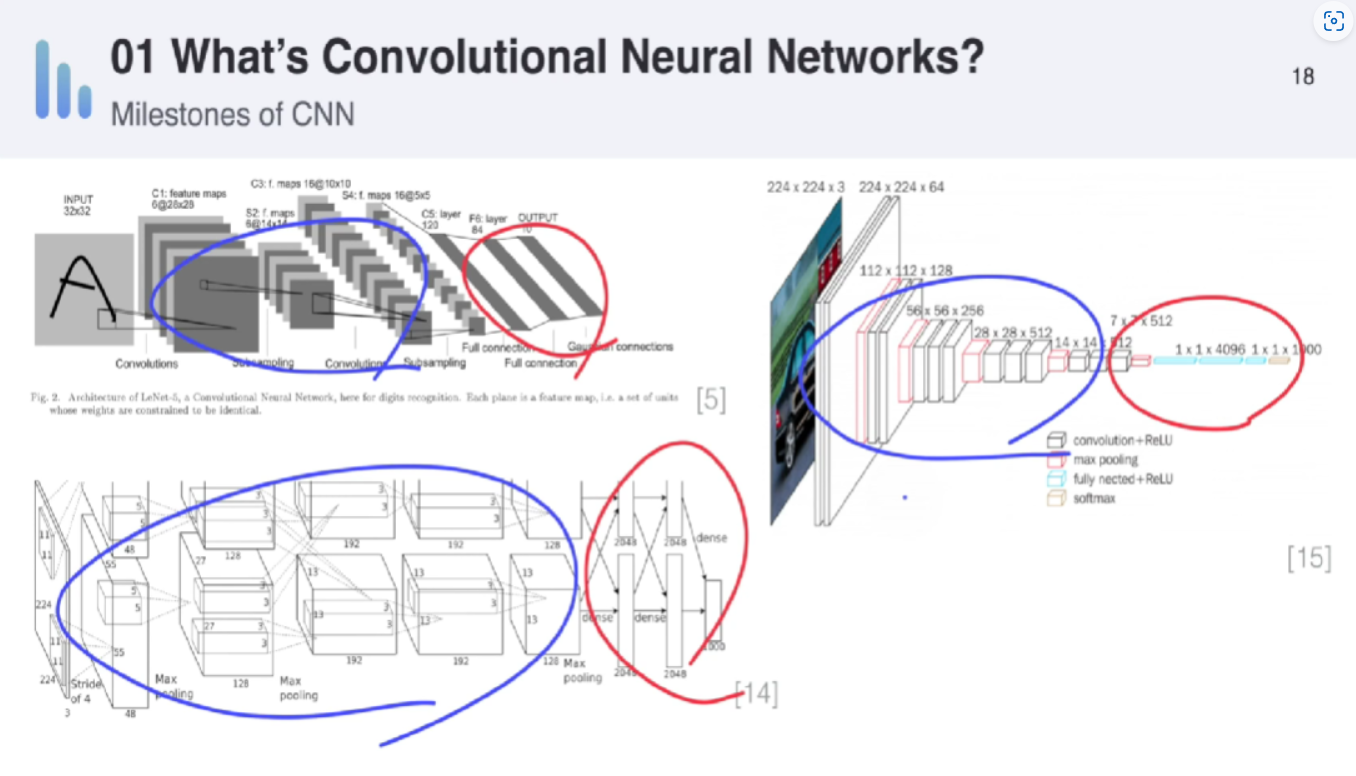
- 그동안은 분류를 할 때, feature extractor 와 classifier를 각각 따로 최적화 하였음
- 하지만 딥러닝의 경우 이 두가지를 한꺼번에 묶어서 global optimization할 수 있다는 것이 장점
- 그래서 보통 그림에서 파란색부분이 feature extractor부분이고 붉은색이 classifier부분
- feature 부분은 convolutional 하게 진행하고, classfier부분은 주로 fully connected layer로 진행하게 됨
- label이 10종류면 0~9 label이 확률값(0~1)로 나오게 됨
2. Convolutional 이란? (컨볼루션 연산이란)
- 곧 커널(=필터)를 사용한다는 것을 의미
-> 값이 비슷할 수록 더 커진다 : 이것이 CNN 커널에서의 핵심- 필터는 강조하고자 하는 영역이 서로 다르며, 한 이미지에도 여러개의 필터가 적용됨
- 커널이 이동할 때 적용되는 layer 입장에서는 'window'라는 용어를 사용
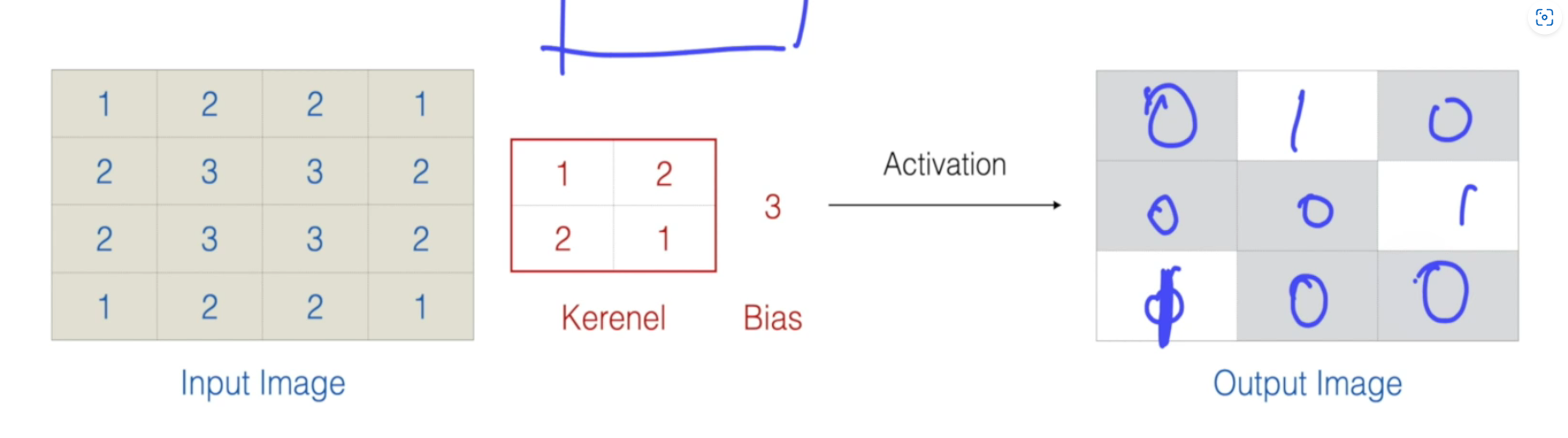
- input * kernel + bias를 활성화함수 (특정값 미만이면 0, 초과면 1) 등을 씌워서 활성화/비활성화로 만들어버릴 수 있다
=> 딥러닝으로 학습한다는건 반복하면서 kernel과 bias값을 바꿔간다는 것! - "필터뱅크" : 필터가 여러개 있는거
- (이미지 하나당이여도) 필터는 항상 여러개임 : 필터마다 w,b 다름
❗ 차원은 이 필터뱅크가 차원별로 그 만큼 있는거임! - 이퀄라이저 연상
- 저주파꺼 올리면 낮은음 더 잘들리게 하고
- 고주파꺼 올리면 높은음 더 잘들리게 함 : bandpass
- 즉 각 필터는 필터마다 이미지에서 강조하고자 하는 영역이 다르단거임
⇒ 그리고 이 필터뱅크들을 인풋값에 적용한 결과들을 모아둔게 feature map
⇒ feature map은 activate 적용 전 개념. activate 적용 후는 activated map
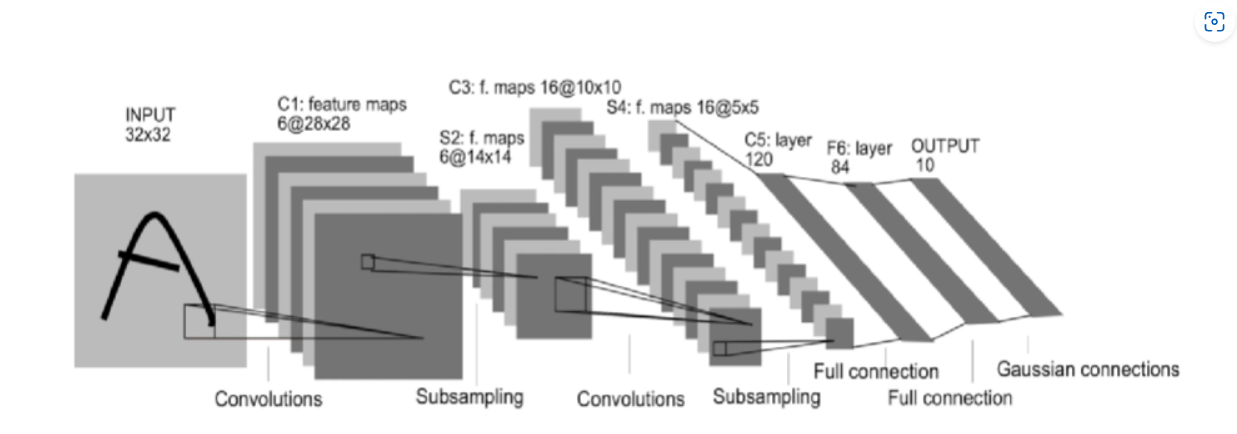
- (이미지 하나당이여도) 필터는 항상 여러개임 : 필터마다 w,b 다름
- (위에선 activated map 표기는 생략됨)
- 첫번째는 6개의 필터뱅크, 이후 풀링
- 두번째는 16개의 필터뱅크, 이후 풀링
- 이렇게 필터뱅크의 수는 하이퍼파라미터임
⇒ CNN은 이렇게 여러번의 필터뱅크를 반복적용 하는거임!
2-1. Multi Input 경우 (RGB채널 등)
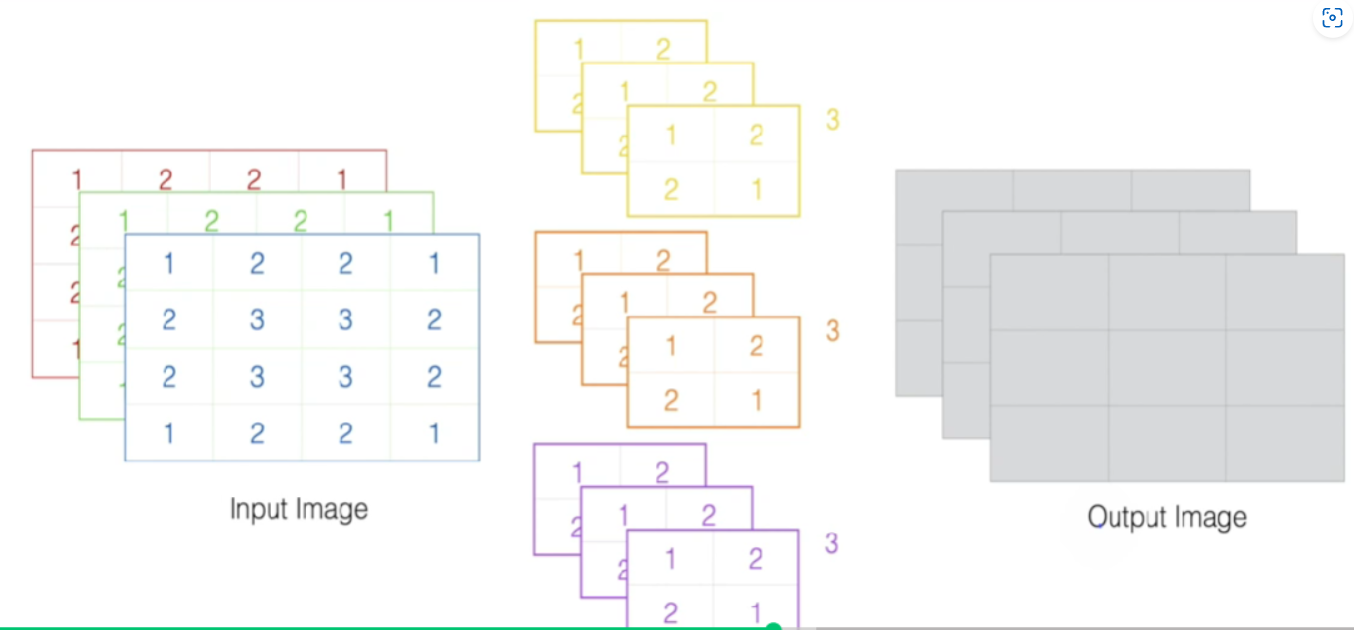
- 멀티인풋은 기본적으로 필터뱅크가 그 차원 수 만큼 (차원 하나 당 전문으로 맡는 필터뱅크가 있다) 있음. RGB처럼 3채널이라면 필터도 3개
- 필터뱅크는 이 3개를 통으로 갖는 것임! 구분해야 함.
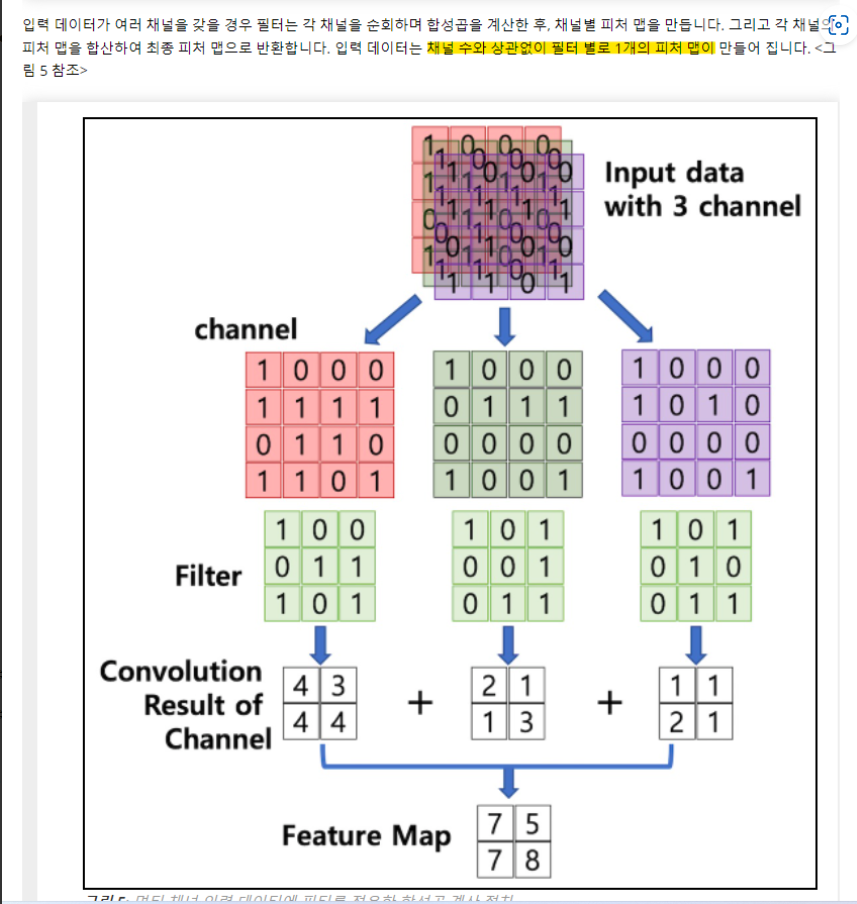
- 필터뱅크는 이 3개를 통으로 갖는 것임! 구분해야 함.
- 그러나 다차원 인풋이여도 최종 피쳐맵은 하나로만 나옴
- activation map = 활성화함수(fature map)
3. Convolutional Layers
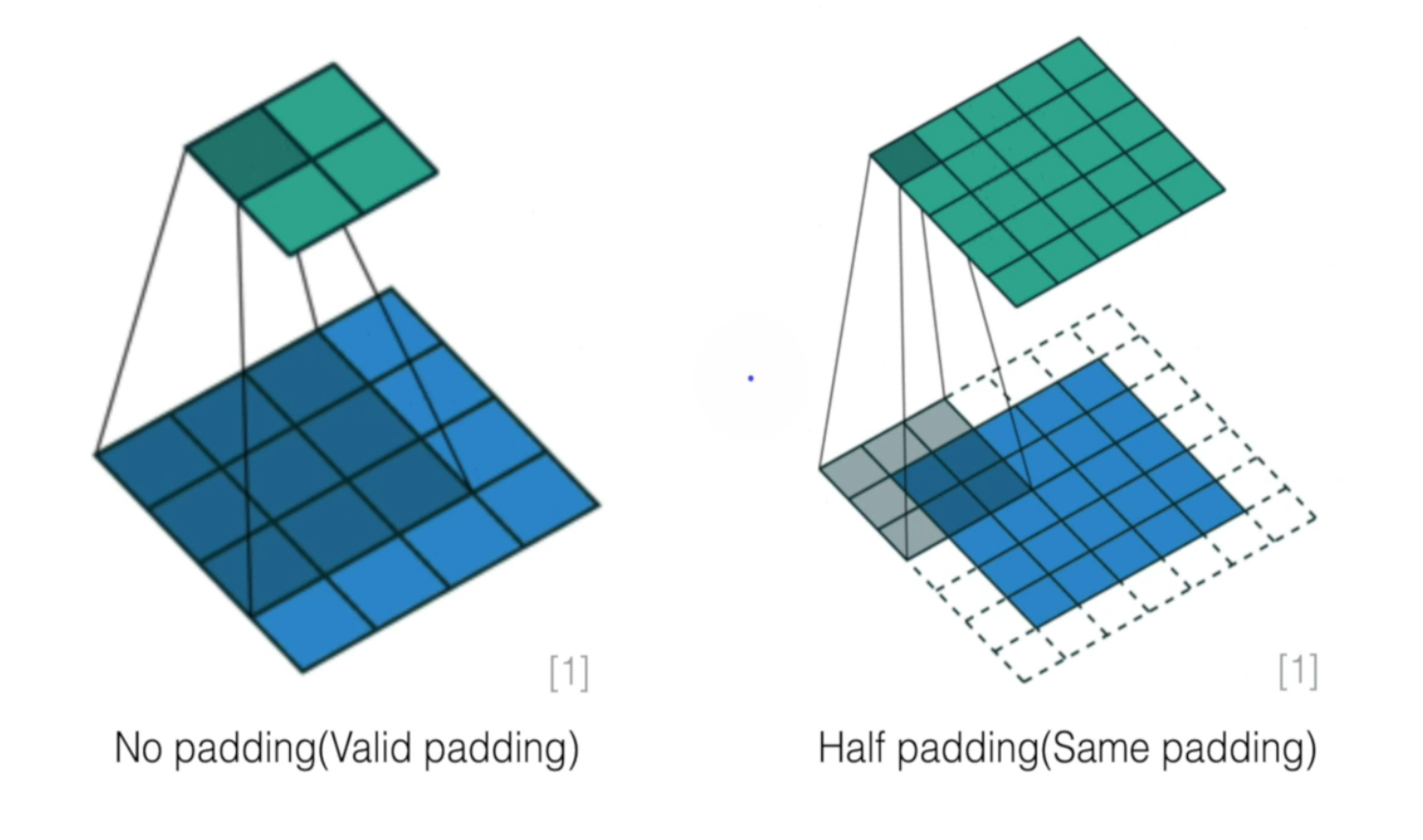
- 커널사이즈가 동일하게 3*3 이지만 padding 유무로 output shape(초록색의 크기) 달라짐
3-1. Padding
- 인풋 이미지의 사이즈 유지 위해 : 앞으로 계속 계산 반복해야하는데 데이터 처음부터 작아져버리면 안됨
- edge가 한번만 계산되는 걸 막기위해 : 똑같은 횟수로 계산해줌
- 그리고 이 Padding이 원하는 효과를 기대하려면 공식이 성사되어야함
- [커널크기/2] (가우시안 : 내림_int) == padding 크기
- 즉 커널크기가 3x3이면 padding은 1여야함
- stride는 커널층은 주로 1
3-2. Pooling
- 피쳐값을 보존하면서 자원을 줄일 수 있다 (이게 사용 주 목적)
- 풀링층에서는 strid == pooling 크기
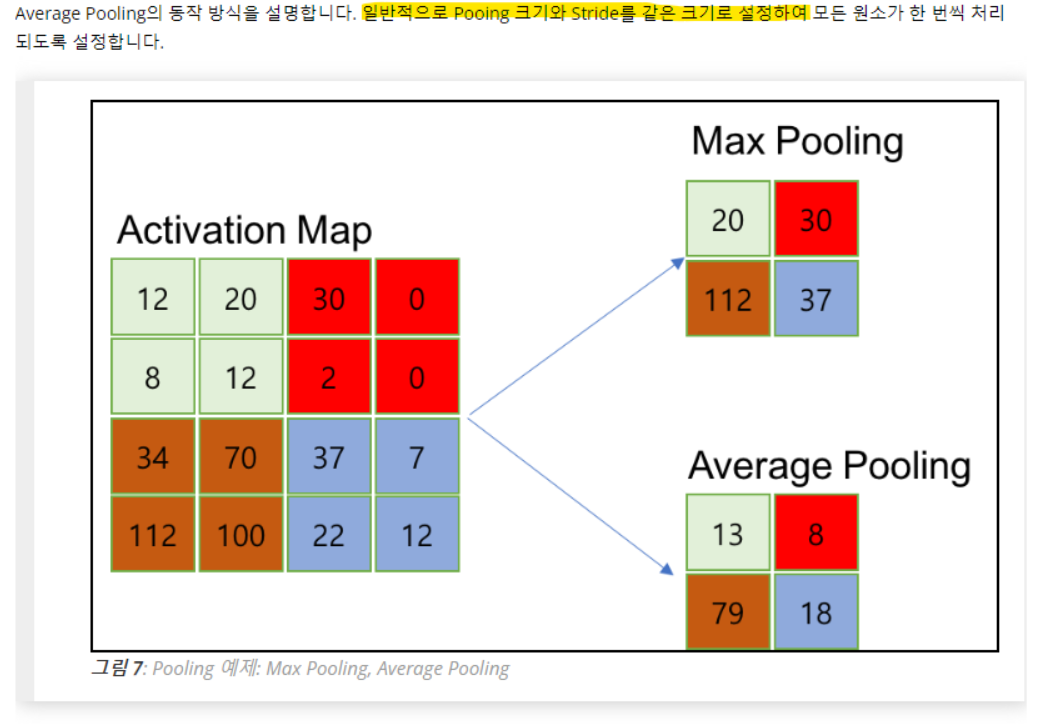
- Average말고 Max를 주로 쓰는 이유
- 활성화 함수 구간에서 activation이 일어났다, 일어나지 않았다는 중요한 정보인데 평균을 때려버리면 아웃라이어의 영향으로 activation 정보를 왜곡할 수 있기 때문
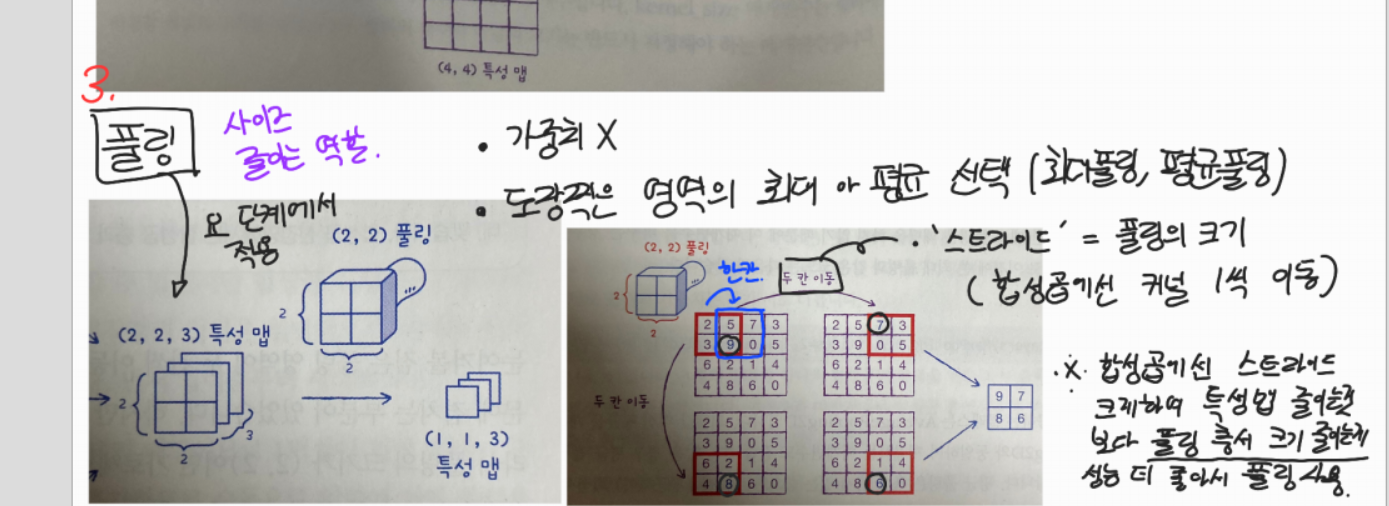
- 활성화 함수 구간에서 activation이 일어났다, 일어나지 않았다는 중요한 정보인데 평균을 때려버리면 아웃라이어의 영향으로 activation 정보를 왜곡할 수 있기 때문
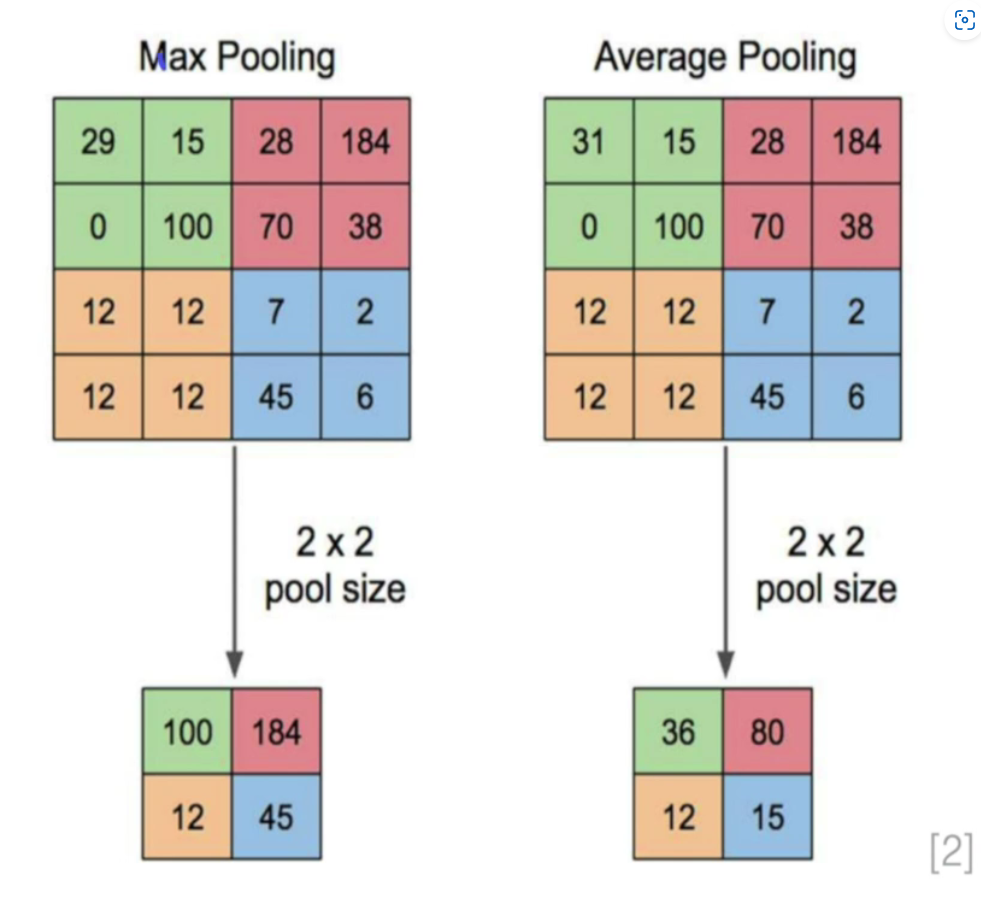
- 풀링 원리 이 그림을 통해서 다시 체크할 수 있음. 풀링에서의 stride 이해가능
3-4. Fully connected layer
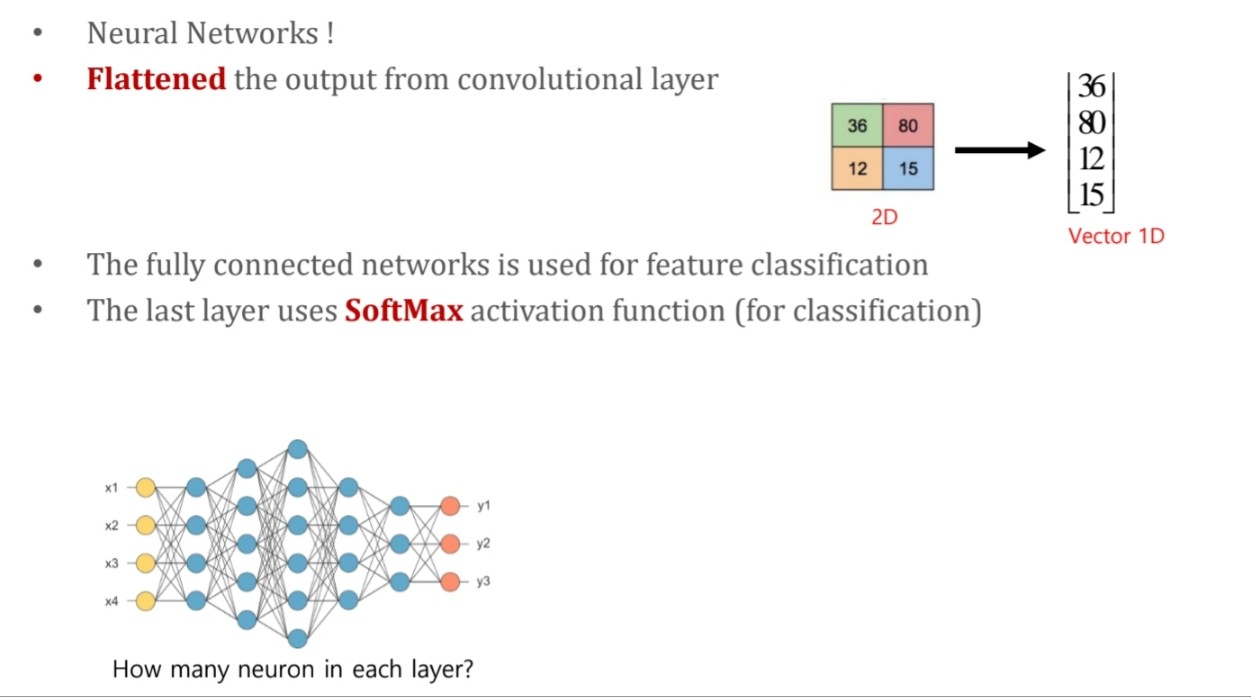

- 마지막의 layer를 1D로 변경 후, 여기에 Softmax를 취하여 확률값으려 변경해준다
- 가장 높은 값을 갖는 것이 pred class가 된다
3-5. 전체구조
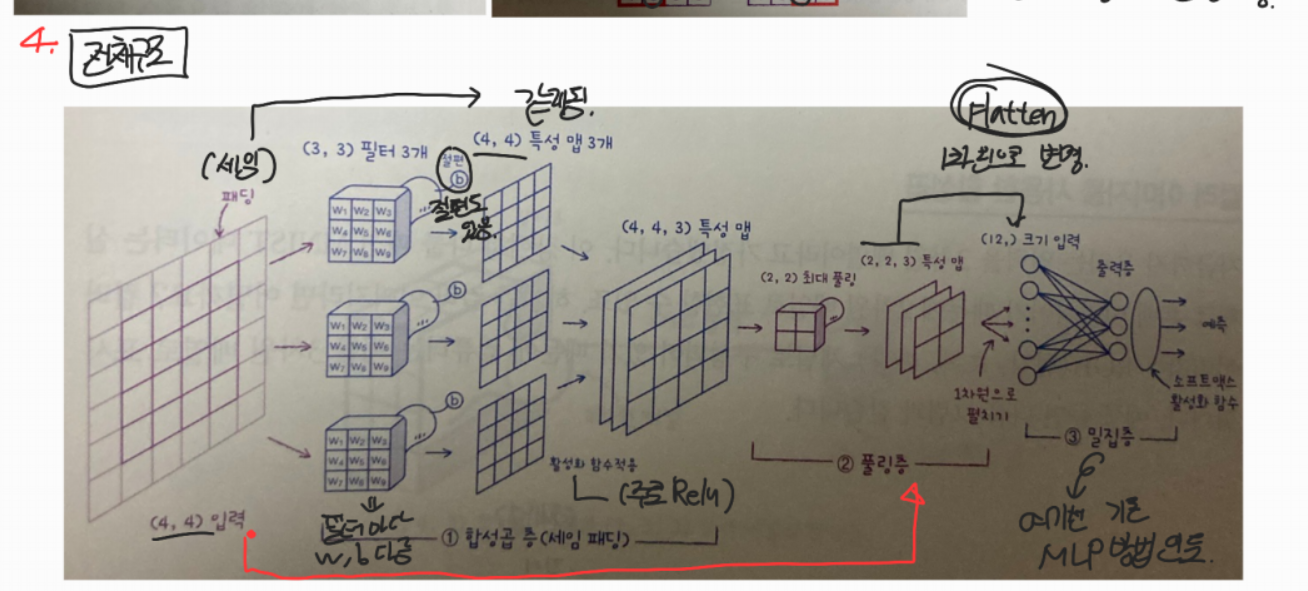
=> 28x28 사이즈의 이미지 하나를 flatten 하는 것으로 시작하여 해당 이미지가 0~9의 숫자 중 어떤 값을 가질 지 각 값별 확률을 도출하는 과정.
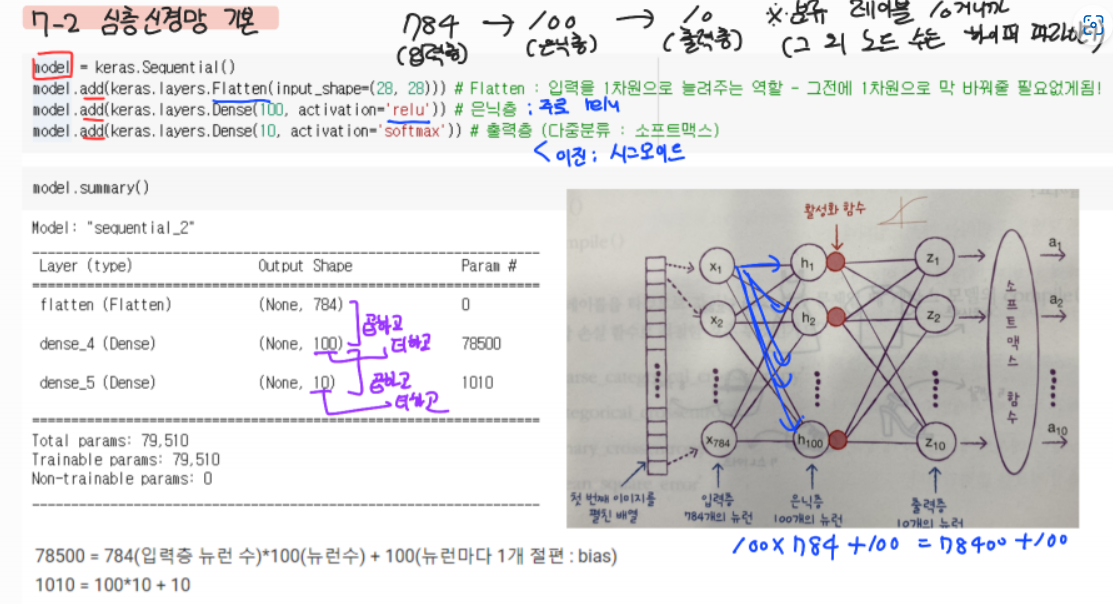
4. 입출력층 shape 맞추기
- p 패딩, k 커널사이즈 (필터 수 아님) , s 스트라이드
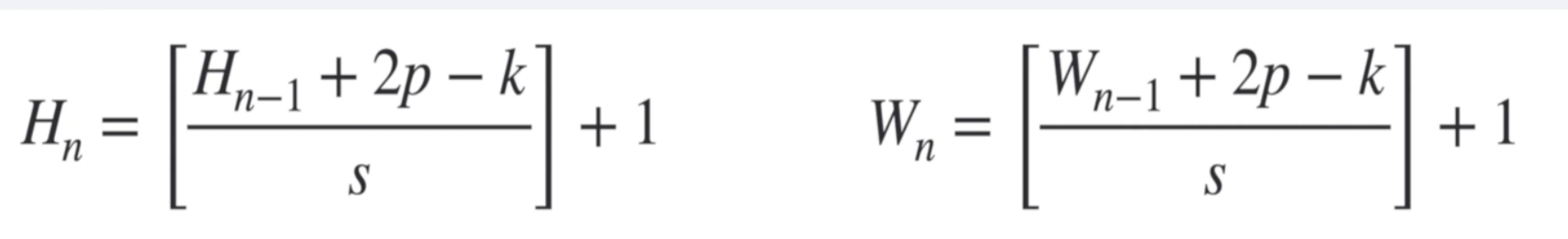
- 가로 세로 당연히 공식같고.. 오로지 w, h에 대한 공식이라서 차원 수는 이거로 안됨
- 커널층 : 세임패딩 경우 → [커널/2] → 크기 같은셈 (뒤에 +1까지 적용해서 그런듯)
- 게다가 커널층은 주로 스트라이드 1이라서 ㅇㅇ
- 풀링층 : 똑같음 (풀링땐 패딩 안하니까 p=0이라고 생각하면 됨)
- p = 0 , 스트라이드하고 풀링크기가 같으므로 s = k 인듯
- 외우는것도 아니고 공식유도할 필요도 없고 그냥 받아들이기만 하면 되는듯
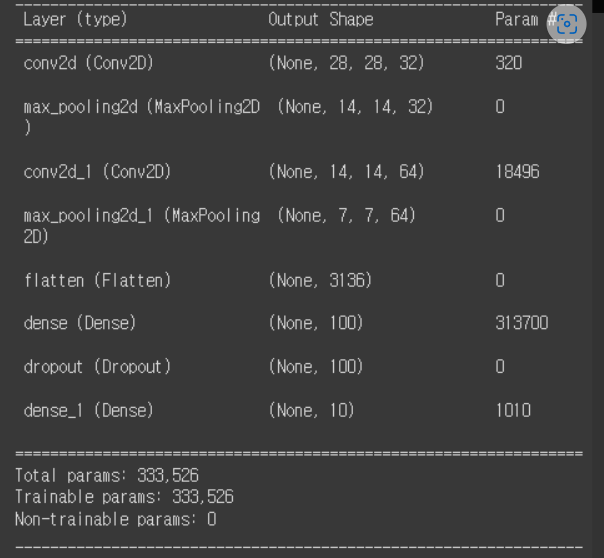
- Param 이거는 w,b 이거임
- 커널 사이즈 (33) x 필터 수(32) + bias 수(32) = 932+32 = 320
5. CNN 동작원리 요약
- input 이미지를 CNN layer에 넣는다
- filter size, strides, padding 등의 파라미터를 설정하여 이미지에 convolution 연산을 수행하고 ReLU 활성화를 적용한다
- dimensionality size를 줄이기 위해 pooling을 수행한다
- 성능향상을 위해 위와 같은 cnn 과정을 여러번 수행한다
- output을 flatten하고 FC layer에 넣는다
- softmax를 적용하여 output class를 산출하고 해당 이미지를 맞는 레이블로 분류한다
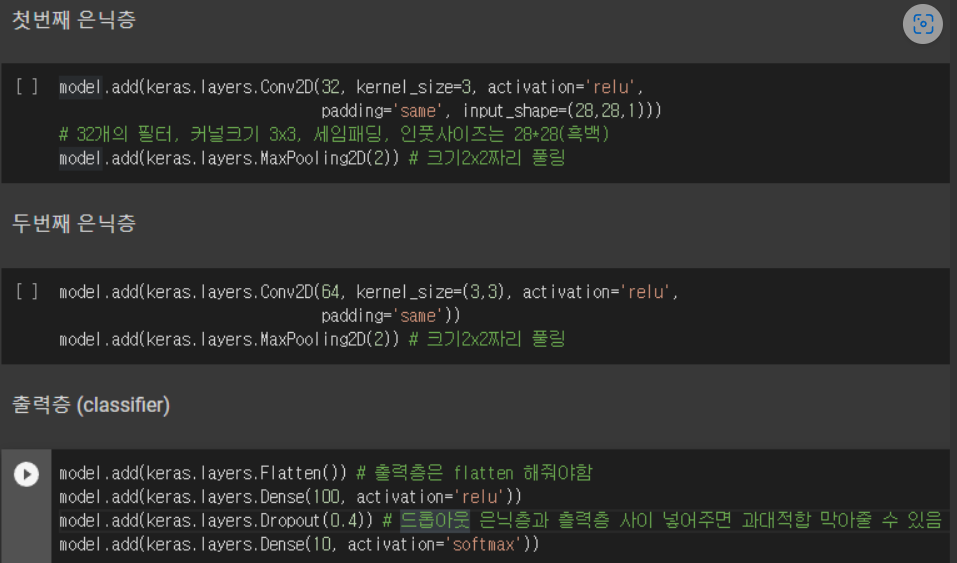
6. 실습 소스코드

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..