세가지를 통해 딥러닝 성능에 관한 이야기를 해보겠다
1. 오버피팅 (과적합)
오버피팅이란, 훈련데이터셋에서만 성능이 좋고 테스트셋에서는 성능이 안 좋은 상황을 의미한다.
=> 훈련데이터의 내용을 외우다시피해서 디테일부분까지 잡아버려서 다른 데이터셋(테스트셋) 에 대한 general한 성능이 좋지않은 경우이다
1-1. 규제항 추가
파라미터의 크기가 너무 커지지않도록 규제항을 추가한다 => [loss : mse + 규제항]
- mse만 있던 기존의 상황은 train set기준으로 설정된 즉, local minimum을 구하는 상황이다
- train set 기준으로만 loss를 구하게 되어있으므로 다른 데이터셋에 적용을 하면 그 상황에 대해선 최적 minimum이 아닐 것이다
- 그러므로 [기존 mse + 규제항] 으로 loss를 설정하면, 각각의 로컬미니멈 두개가 섞여서 중화 되는듯한 느낌으로 이해할 수 있다.
1-2. 드롭아웃
특정확률로 node를 꺼버리는 것이다
- 꺼버린 노드에서 주는 weight은 0이 된다
- 강제적으로 구해야하는 파라미터 수가 줄어든다 : 복잡하게 예측을 안하게 된다
- 무엇이 꺼지느냐에 따라 결국 다른 모델이 되는셈이다
- 꺼진 노드들이 예측하는 간단한 결과들이 합쳐진 성능같은 느낌. 앙상블 기법의 일종이라 볼 수 있다.
- 테스트셋에서는 다 켜놓고한다!
- validation, test에서는 드롭아웃 사용안한다!
2. 배치정규화
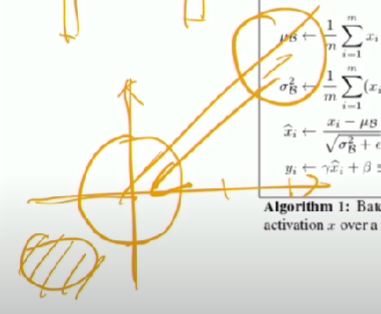
위 그림과 같이 활성화함수에 넣기 전, 값을 정규화시켜서 활성화함수 특정위치로 이동시켜 넣고자 함이다
- 활성화 함수를 쓰는 이유가, 사용하지 않으면 결국 선형꼴(층 하나만 사용한 꼴)과 같아서 쓰는 것이다.
- 이 때 활성화함수 끝에 있으면 (특정 부분에 없으면 : 시그모이드 끝부분에서 학습 잘 안일어나는 것처럼) 활성화 함수 안쓴거랑 같은 셈이라, 특정위치로 모아주는 역할이다
- 정규화할때 구체적으로 batch들의 어떤 평균과 분산을 쓸지는 학습을 통해서 결정한다
- 한층의 노드당 새로 학습해야할 파라미터가 두개씩 생기는 셈이다
- test set은 batch를 사용하지 않으니까 평균 분산을 못구한다
- (예시) train set에서 배치별 미니배치 사이즈가 32고 총 데이터 3200 경우 => 배치개수인 100개. 100개만큼의 평균과 분산을 이용해서 test set에 배치정규화한다
❗ 사용 시 주의사항
- 순서 : 층 => 활성화 => 배치정규화 => dropout
- 배치정규화 : layer마다 사용
- dropout : 처음과 마지막 층에선 사용금지!
- 검증, 테스트셋에선 사용하지 않는다
def forward(self, x): x = self.act(self.fc1(x)) for i in range(len(self.linears)): # 순서 : 층 => 활성화 => bn => dropout x = self.act(self.linears[i](x)) x = self.bns[i](x) # layer마다 평균과 편차가 다르므로 각각 다르게 사용해줘야함 x = self.dropout(x) # dropout : 처음과 마지막 layer에선 사용금지! 중간만 사용가능 x = self.fc2(x) return x
3. Validaion 사용이유
- 하이퍼파라미터를 바꿔보면서 결과를 비교할때 test acc를 참고하다보면 test acc를 위해 하이퍼파라미터를 바꾸게 된다
- 즉 test set에 맞추는식으로 사용자가 파라미터를 조절하게 된다
- 이는 학생에게 미리 수능문제가 유출된 것과 같은상황이다!
즉 하이퍼파라미터는 validation을 통해 바꾸고, 정말 객관적으로 general한 경우에도 성능이 좋은지 확인하고 싶을때 test set을 쓰는 것이다

금융권에 가고싶은 김코다입니다. 취업을 하면 기타치며 조르바처럼 살고파요. -> 금융권 왔다. 취업도 했다. 그러나 여전히 조르바처럼..