
❖ 파이썬에서 CSV데이터 읽기
CSV(Comma-Separated Values) 파일
- 표 형태(스프레드 시트 등)의 데이터를 대표하는 일반적인 방식
- 쉼표(,)로 분류된 값
- excel 프로그램에서 만들거나 편집할 수 있음
- .csv 확장자로 파일 다운 (
File→Download→.csv)
- .csv 확장자로 파일 다운 (
파이썬에서 CSV 파일 열기
- 파이참에서 프로젝트 열기
- 해당 프로젝트 폴더에 .csv 파일 넣기
- 파일을 더 쉽게 볼 수 있도록 돕는 플러그인은 설치하지 않음
(원시 데이터 그대로 사용)
📄 weather_data.csv
day,temp,condition
Monday,12,Sunny
Tuesday,14,Rain
Wednesday,15,Rain
Thursday,14,Cloudy
Friday,21,Sunny
Saturday,22,Sunny
Sunday,24,Sunnycsv : CSV를 지원하는 파이썬 내장 라이브러리
- reader( file, delimiter ) : CSV파일을 읽을 때 사용하는 함수(반복문으로 각 행을 불러와야 함)
file: 파일 객체delimiter: 파일의 구분자로, 생략 시 디폴트 값 적용 ( 디폴트 값 = , )
⌨️ main.py
import csv
with open("weather_data.csv") as data_file:
# CSV파일 읽기
data = csv.reader(data_file)
# 한 줄씩 전체 출력
for row in data:
print(row)
# 특정 열 출력
temperatures = []
for row in data:
if row[1] != "temp": # 온도 관련 행의 레이블인 문자열 제외하기
temperatures.append(int(row[1]))
print(temperatures)# 한 줄씩 전체 출력
['day', 'temp', 'condition']
['Monday', '12', 'Sunny']
['Tuesday', '14', 'Rain']
['Wednesday', '15', 'Rain']
['Thursday', '14', 'Cloudy']
['Friday', '21', 'Sunny']
['Saturday', '22', 'Sunny']
['Sunday', '24', 'Sunny']
# 특정 열 출력
[12, 14, 15, 14, 21, 22, 24]
🐼 Pandas 라이브러리
표 형태로 된 데이터를 분석하는데 유용하고 효과적인 라이브러리(설치 필요)
⌨️ main.py
import pandas
# 판다스로 CSV파일 읽기
data = pandas.read_csv("weather_data.csv")
# 전체 출력 (데이터 프레임)
print(data)
# 특정 열 출력 (시리즈)
print(data["temp"]) # 방법 1
print(data.temp) # 방법 2 (객체에 가깝게 취급하는 방법)
# 데이터 프레임과 시리즈로 특정 행 출력
print(data[data["day"] == "Monday"]) # 1. 전체 표에서 검색하는 것이 있는 열 찾기
# 2. 열에서 검색하는 것과 같은 값이 있는 행을 체크[ 출력 결과 ]
# 전체 출력 (데이터 프레임)
day temp condition
0 Monday 12 Sunny
1 Tuesday 14 Rain
2 Wednesday 15 Rain
3 Thursday 14 Cloudy
4 Friday 21 Sunny
5 Saturday 22 Sunny
6 Sunday 24 Sunny
# 특정 열 출력 (시리즈) → 자동으로 첫 번째 행을 각 열의 제목으로 사용
0 12
1 14
2 15
3 14
4 21
5 22
6 24
Name: temp, dtype: int64
# 데이터 프레임과 시리즈로 특정 행 출력
day temp condition
0 Monday 12 Sunnycsv 모듈을 사용했을 때보다 간단하고 빠르게 데이터를 다룰 수 있음
🐼 데이터 프레임과 시리즈: 행과 열
판다스의 2가지 주요 데이터 구조(클래스)
- 데이터 프레임(DataFrame) : 전체 표
- DataFrame.to_dict( orient='dict', *, into=<class 'dict'>, index=True ) :
데이터 프레임 클래스의 객체를 딕셔너리로 변환하여 반환orient: 딕셔너리의 값의 자료형을 지정 ( 디폴트 값 = dict )- dict : { column -> {index -> value} }
- list : { column -> [values] }
- series : { column -> Series(values) }
- split : { ‘index’ -> [index], ‘columns’ -> [columns], ‘data’ -> [values] }
- tight : { ‘index’ -> [index], ‘columns’ -> [columns], ‘data’ -> [values],‘index_names’ -> [index.names], ‘column_names’ -> [column.names] }
- records : [ {column -> value}, … , {column -> value} ]
- index : { index -> {column -> value} }
into: 반환값의 모든 매핑에 사용되는 collections.abc.Mapping 하위클래스( 디폴트 값 = dict )index: orient가 split 또는 tight일 때만 False 가능 ( 디폴트 값 = True )
- DataFrame.to_csv( path_or_buf=None, ... ) : 객체를 CSV 파일로 변환
path_or_buf: 파일을 저장할 경로- … 생략
- DataFrame.to_dict( orient='dict', *, into=<class 'dict'>, index=True ) :
- 시리즈(Series) : 표의 한 열
- Series.to_list() : 시리즈 클래스의 객체를 리스트로 변환하여 반환
(리스트와 똑같이 생겼지만 자료형이 다름) - Series.mean( axis=0, skipna=True, numeric_only=False, **kwargs ) :
해당 시리즈에 대한 평균값 반환axis:시리즈에서는 사용되지 않음 ( 디폴트 값 = 0 )skipna: NA/null 값을 배제 ( 디폴트 값 = True )numeric_only:시리즈에서는 사용되지 않음 ( 디폴트 값 = False )**kwargs: 함수에 인수로 전달될 키워드 추가
- Series.max( axis=0, skipna=True, numeric_only=False, **kwargs ) :
해당 시리즈에서 가장 큰 값 반환
- Series.to_list() : 시리즈 클래스의 객체를 리스트로 변환하여 반환
⌨️ main.py
import pandas
data = pandas.read_csv("weather_data.csv")
# data를 딕셔너리 유형으로 변경
data_dict = data.to_dict()
print(data_dict)[ 출력 결과 ]
{
'day': {0: 'Monday', 1: 'Tuesday', 2: 'Wednesday', 3: 'Thursday', 4: 'Friday', 5: 'Saturday', 6: 'Sunday'},
'temp': {0: 12, 1: 14, 2: 15, 3: 14, 4: 21, 5: 22, 6: 24},
'condition': {0: 'Sunny', 1: 'Rain', 2: 'Rain', 3: 'Cloudy', 4: 'Sunny', 5: 'Sunny', 6: 'Sunny'}
}⌨️ main.py
import pandas
data = pandas.read_csv("weather_data.csv")
# temp 열을 리스트 유형으로 변경
temp_list = data["temp"].to_list()
print(temp_list)
# 이번 주의 평균 온도 구하기 (열)
print(data["temp"].mean())
# 이번 주의 최고 온도 구하기 (열)
print(data["temp"].max())
# 월요일의 날씨 상태 구하기 (행)
monday = data[data.day == "Monday"]
print(monday.condition)
# 월요일의 온도를 화씨로 바꿔서 구하기 (행)
monday_temp = monday.temp
monday_temp_F = (monday_temp * 9/5) + 32
print(monday_temp_F)[ 출력 결과 ]
[12, 14, 15, 14, 21, 22, 24]
17.428571428571427
24
0 Sunny
Name: condition, dtype: object
0 53.6
Name: temp, dtype: float64⌨️ main.py
import pandas
# 파이썬에서 생성하는 데이터로부터 데이터 프레임 생성하기
data_dict = {
"students": ["Amy", "Ben", "Carter"],
"scores": [76, 56, 65]
}
data = pandas.DataFrame(data_dict)
# 생성한 데이터 프레임을 CSV 파일로 변환
data.to_csv("new_data.csv")📄 new_data.csv
,students,scores
0,Amy,76
1,Ben,56
2,Carter,65🐼 다람쥐 데이터 분석
- CSV 파일 다운
- 추출할 값 : 털 색깔(grey, cinnamon, black) 별 다람쥐 개체 수
⌨️ main.py
import pandas
data = pandas.read_csv("2018_Central_Park_Squirrel_Census_-_Squirrel_Data.csv")
grey_squirrels_count = len(data["Primary Fur Color"] == "Grey")
cinnamon_squirrels_count = len(data["Primary Fur Color"] == "Cinnamon")
black_squirrels_count = len(data["Primary Fur Color"] == "Black")
data_dict = {
"Fur Color": ["Grey", "Cinnamon", "Black"],
"Count": [grey_squirrels_count, cinnamon_squirrels_count, black_squirrels_count]
}
df = pandas.DataFrame(data_dict)
df.to_csv("squirrel_count.csv")📄 squirrel_count.csv
,Fur Color,Count
0,Grey,3023
1,Cinnamon,3023
2,Black,3023🗂️ Day25 프로젝트 : 미국 주 게임
실존하는 미국의 주 이름을 입력하면 지도에 해당 구역이 표시되는 게임
sporcle - US States 게임 링크
1. 게임 셋업
🔍 유의 사항
- turtle 그래픽과 CSV파일의 데이터를 이용
- turtle 모듈에서는 .gif 확장자만 사용 가능
- addshape( name, shape=None ) : shape를 추가하는 메소드
name: ① gif 파일의 이름, ② 임의의 이름 ③ 임의의 이름shape: ① 생략, ② 좌표값들로 이루어진 튜플 ③ (compound) Shape 객체- 지도를 통해 각 주의 좌표를 구하는 방법
- onscreenclick( fun, btn=1, add=None ) : 마우스 클릭을 감지하면 함수를 호출하는 이벤트 리스너
fun: 화면에서 클릭한 지점의 좌표를 인수로 받는 함수btn: 왼쪽 마우스 클릭 횟수 ( 디폴트 값 = 1 )add: True/False- mainloop() : 코드 실행이 끝나도 화면을 닫지 않는 메소드로, exitonclick()을 대체할 수 있음
# 함수 def get_mouse_click_coor(x, y): print(x, y) # 마우스 클릭할 때마다 함수 호출 turtle.onscreenclick(get_mouse_click_coor) # 화면을 닫지 않고 유지하기 turtle.mainloop()
🖼️ blank_states_img.gif
📄 50_states.csv
state,x,y
Alabama,139,-77
Alaska,-204,-170
…
Wyoming,-134,90⌨️ main.py
import turtle
screen = turtle.Screen()
screen.title("U.S. States Game")
# 배경화면을 지도 이미지로 바꾸기
image = "blank_states_img.gif"
screen.addshape(image)
turtle.shape(image)
# 주 이름을 물어보는 팝업창 띄우기
answer_state = screen.textinput(title="Guess the State",
prompt="What's another state's name?")
# 입력값을 콘솔창에서 확인
print(answer_state)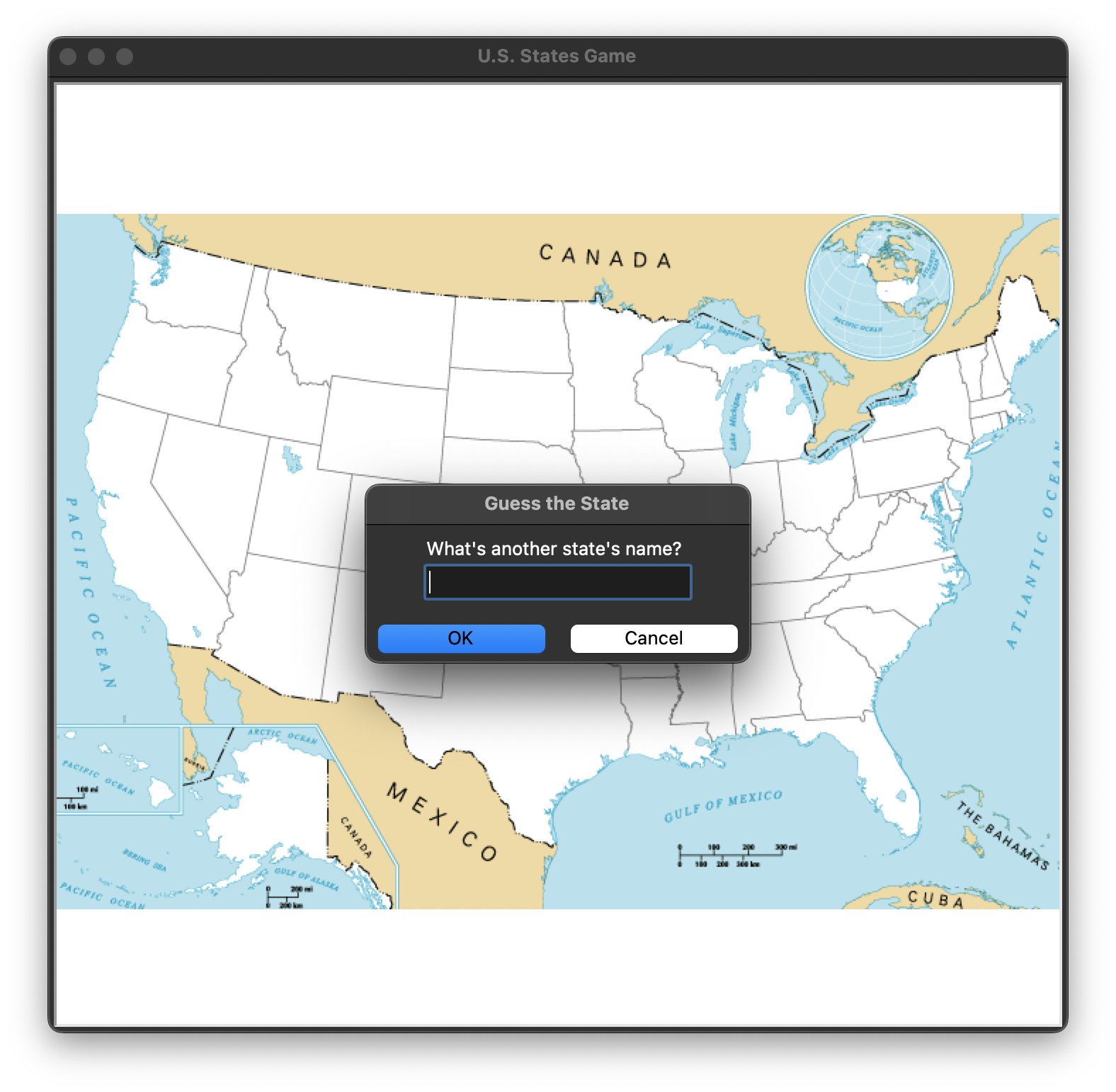
2. CSV파일을 활용
🔍 유의 사항
- 유저의 답과 CSV파일 안의 주 이름이 일치하는지 체크
- 예약어 in 으로 특정 값이 리스트에 속해 있는지 확인 가능
- 철자만 맞게 입력하면 대소문자 구별은 무시하기
(day3 - ❖ 문자열 관련 함수)- 유저가 이름을 맞추면, 그 주가 위치한 곳의 화면에 주 이름이 표시되어야 한다
- 입력창 제목에서는 50개 중 몇 개나 맞췄는지 숫자를 계속 업데이트
- 50개를 다 맞췄을 시 게임 종료
- 유저가 이름을 틀리면, 입력창이 다시 나타나서 새로 입력해야 한다
⌨️ main.py
import turtle
import pandas
…
data = pandas.read_csv("50_states.csv")
all_states = data.state.to_list()
guessed_states = []
while len(guessed_states) < 50:
answer_state = screen.textinput(title=f"{len(guessed_states)}/50 States Correct",
prompt="What's another state's name?").title()
if answer_state in all_states:
guessed_states.append(answer_state)
# 맞는 좌표에 글씨를 쓸 터틀 객체
pin = turtle.Turtle()
pin.hideturtle()
pin.penup()
state_data = data[data.state == answer_state]
pin.goto(int(state_data.x), int(state_data.y))
pin.write(answer_state)3. CSV파일에 저장
🔍 유의 사항
- 입력창에 exit 이라고 입력할 경우
- 게임을 끝낼 때까지 맞추지 못한 주 이름이 포함된 CSV파일 생성
- 게임 종료
⌨️ main.py
import turtle
import pandas
screen = turtle.Screen()
screen.title("U.S. States Game")
image = "blank_states_img.gif"
screen.addshape(image)
turtle.shape(image)
screen.tracer(0)
data = pandas.read_csv("50_states.csv")
all_states = data.state.to_list()
guessed_states = []
while len(guessed_states) < 50:
screen.update()
answer_state = screen.textinput(title=f"{len(guessed_states)}/50 States Correct",
prompt="What's another state's name?").title()
# Exit 입력 시
if answer_state == "Exit":
missing_states = []
for state in all_states:
if state not in guessed_states:
missing_states.append(state)
# CSV파일 생성
new_data = pandas.DataFrame(missing_states)
new_data.to_csv("states_to_learn.csv")
break
if answer_state in all_states:
guessed_states.append(answer_state)
pin = turtle.Turtle()
pin.hideturtle()
pin.penup()
state_data = data[data.state == answer_state]
pin.goto(int(state_data.x), int(state_data.y))
pin.write(answer_state)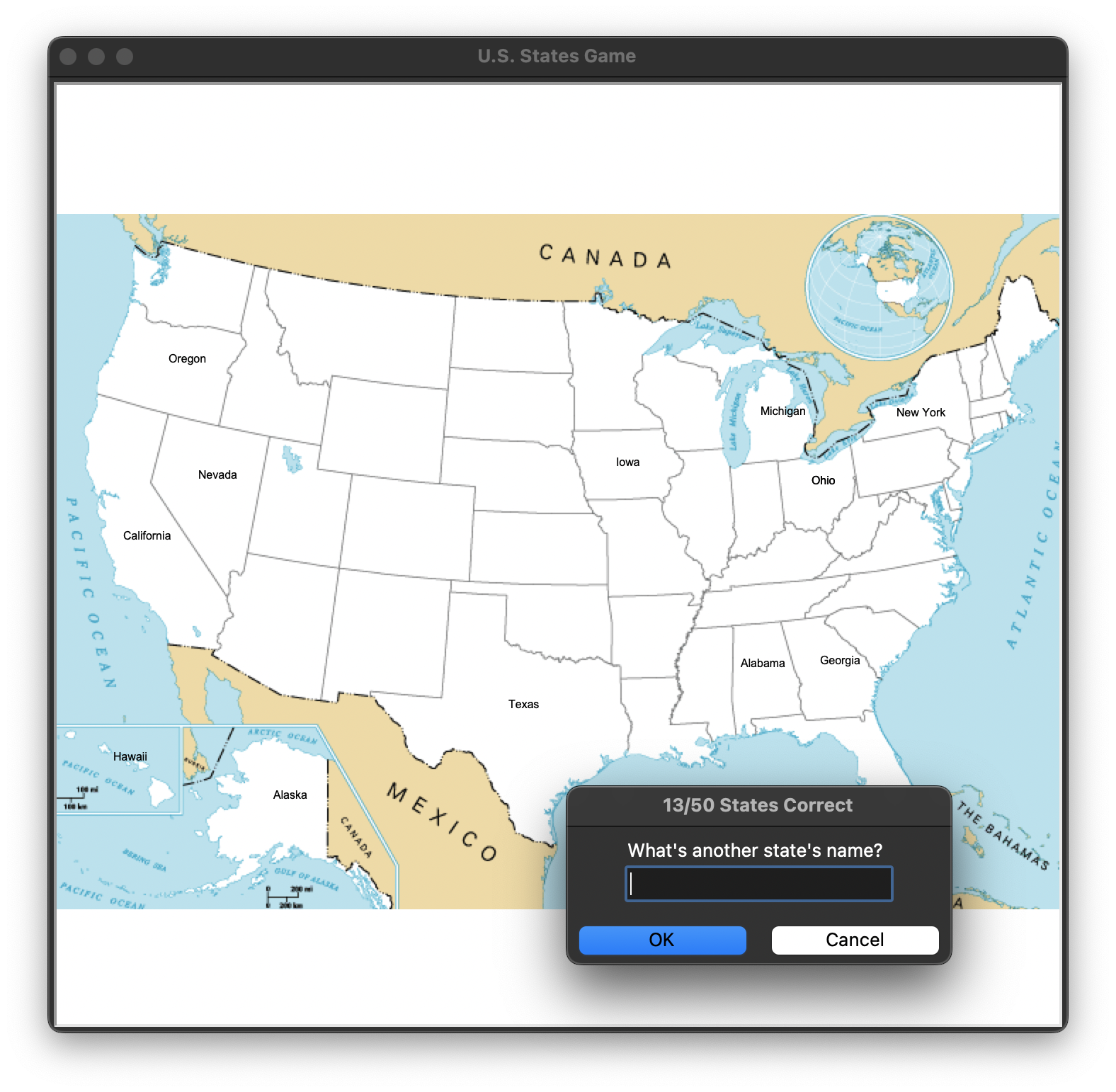
📄 states_to_learn.csv
,0
0,Arizona
1,Arkansas
2,Colorado
…
37,Wyoming