제 글을 몇 차례 읽어본 분들은 이미 아시겠지만, 제가 속한 동아리 BcsdLab은 2019년부터 한국기술교육대 학생들을 대상으로 코인이라는 학교 커뮤니티 서비스를 운영하고 있습니다. 현재 코인은 월간 활성 사용자(MAU) 3~4,000명 규모의 서비스입니다.
 |  |
|---|
"동아리에서 운영하는 서비스가 과연 실무일까?"라고 생각하실 수도 있지만, 저희는 실제 스타트업처럼 서비스를 운영하는 것을 목표로 하기 때문에 실무라고 표현했습니다..ㅎㅎ
Redisson의 도입 배경
따닥 요청
동아리에서 진행하는 작업 중에, 제가 기존에 속해 있던 팀이 아닌 학교 내부 관련 서비스를 담당하는 '캠퍼스' 팀에서 제가 이전부터 해보고 싶었던 '공지사항 키워드 알림' 서비스를 스프린트 주제중 하나로 진행하게 되었습니다. 전과 이전부터 간절히 원했던 서비스이기도 했고, 이미 전과하기 전에 구현해 본 경험이 있어 캠퍼스 팀에 부탁해 적극적으로 해당 스프린트에 참여했습니다.
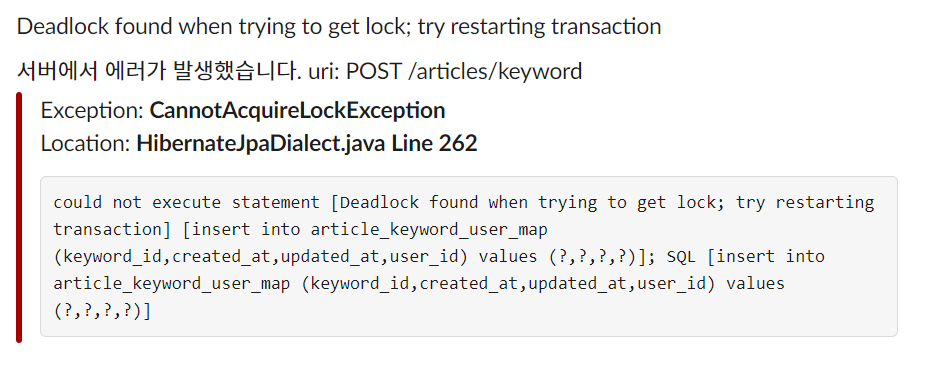
평화롭게 대부분의 API를 구현하고, 클라이언트의 작업을 기다리던 어느 날, 슬랙의 스테이지 에러 채널에서 '키워드 추가 API'에 데드락이 걸렸다는 알림이 쏟아지기 시작했습니다. 로직이 간단해 빈번히 발생할 상황이 아니었는데, 원인을 찾아보니 클라이언트에서 추천 키워드를 클릭할 때마다 동시에 여러 개의 추가 요청이 보내져 데드락이 걸린 것이었습니다.(데드락이 걸렸던 이유가 궁금한 분들이 있을텐데 추후 포스팅 예정) 흔히 말하는 '따닥 요청'이 발생한 것이었죠.
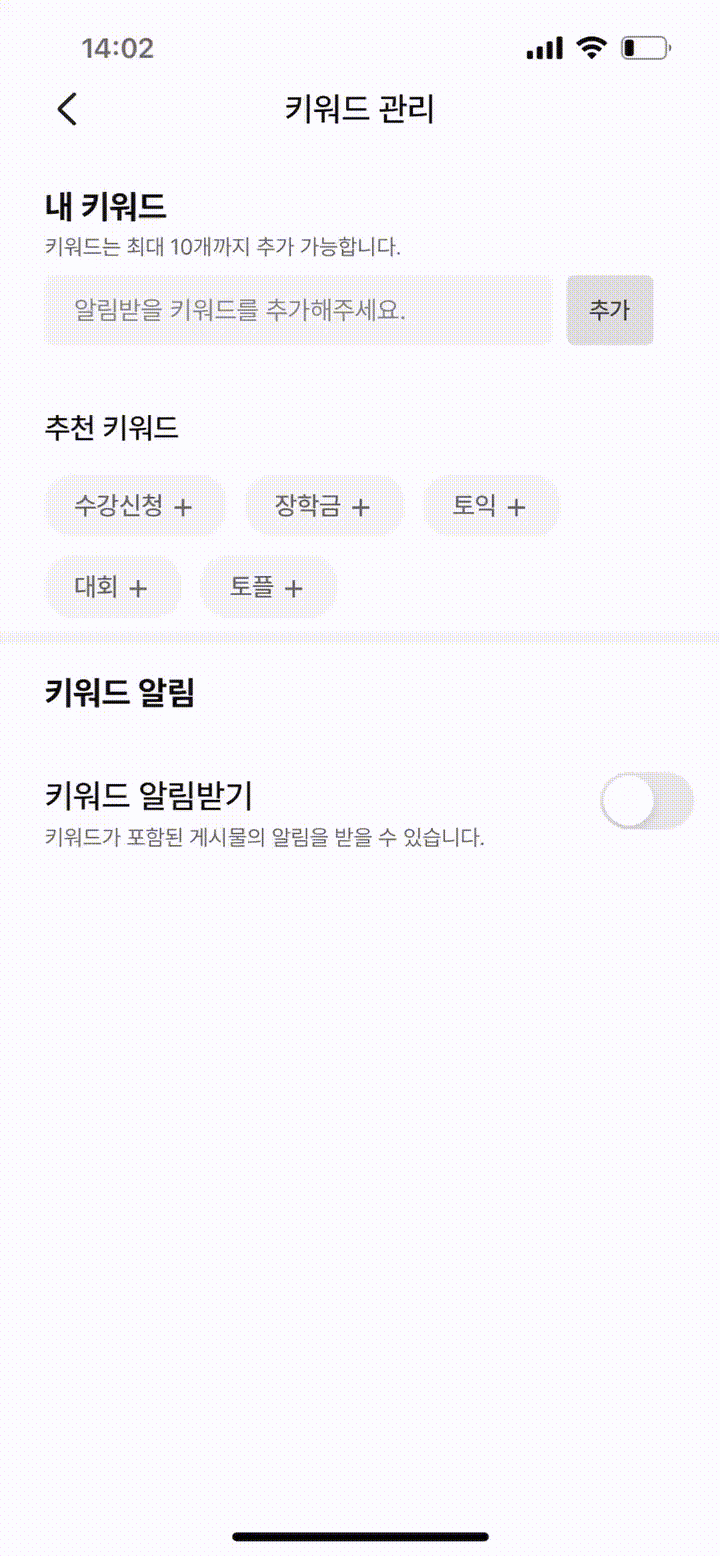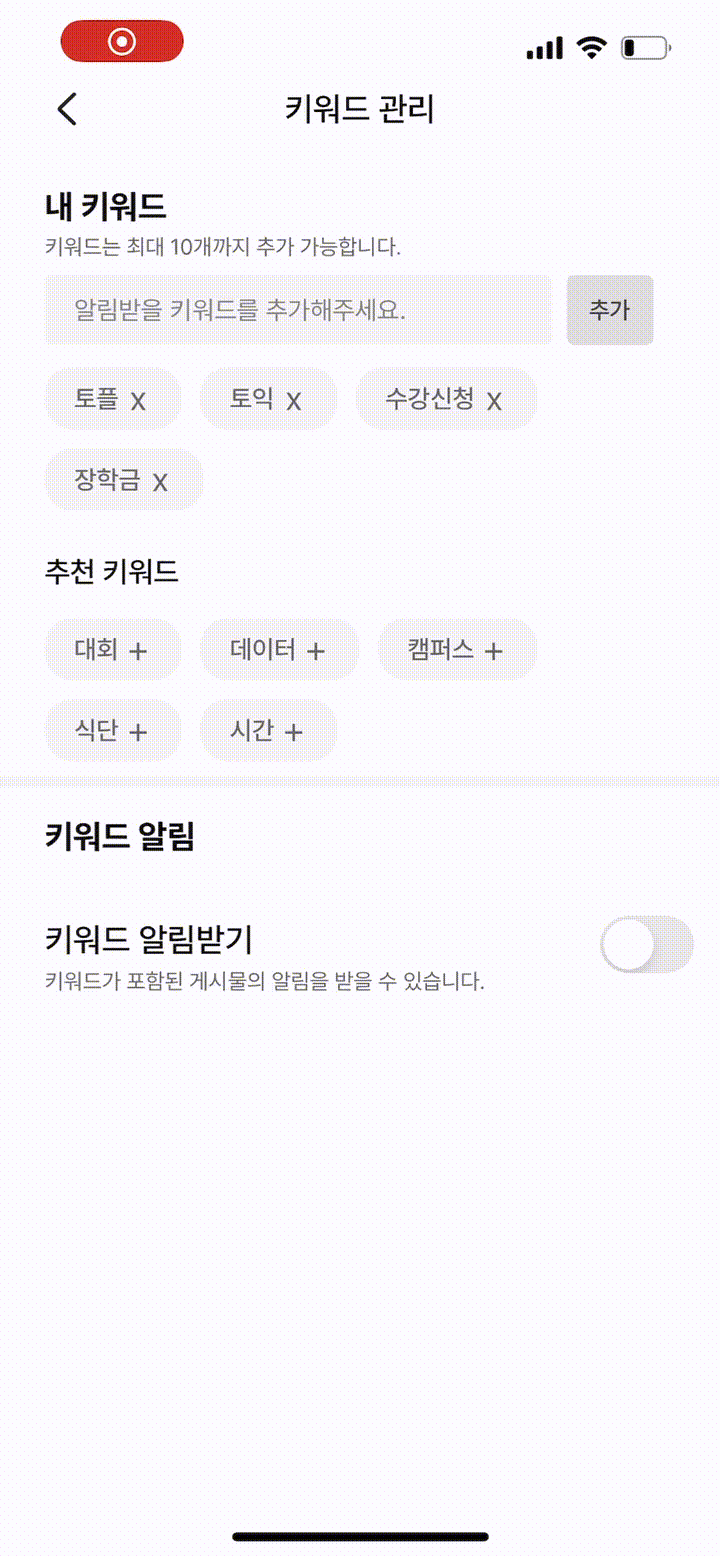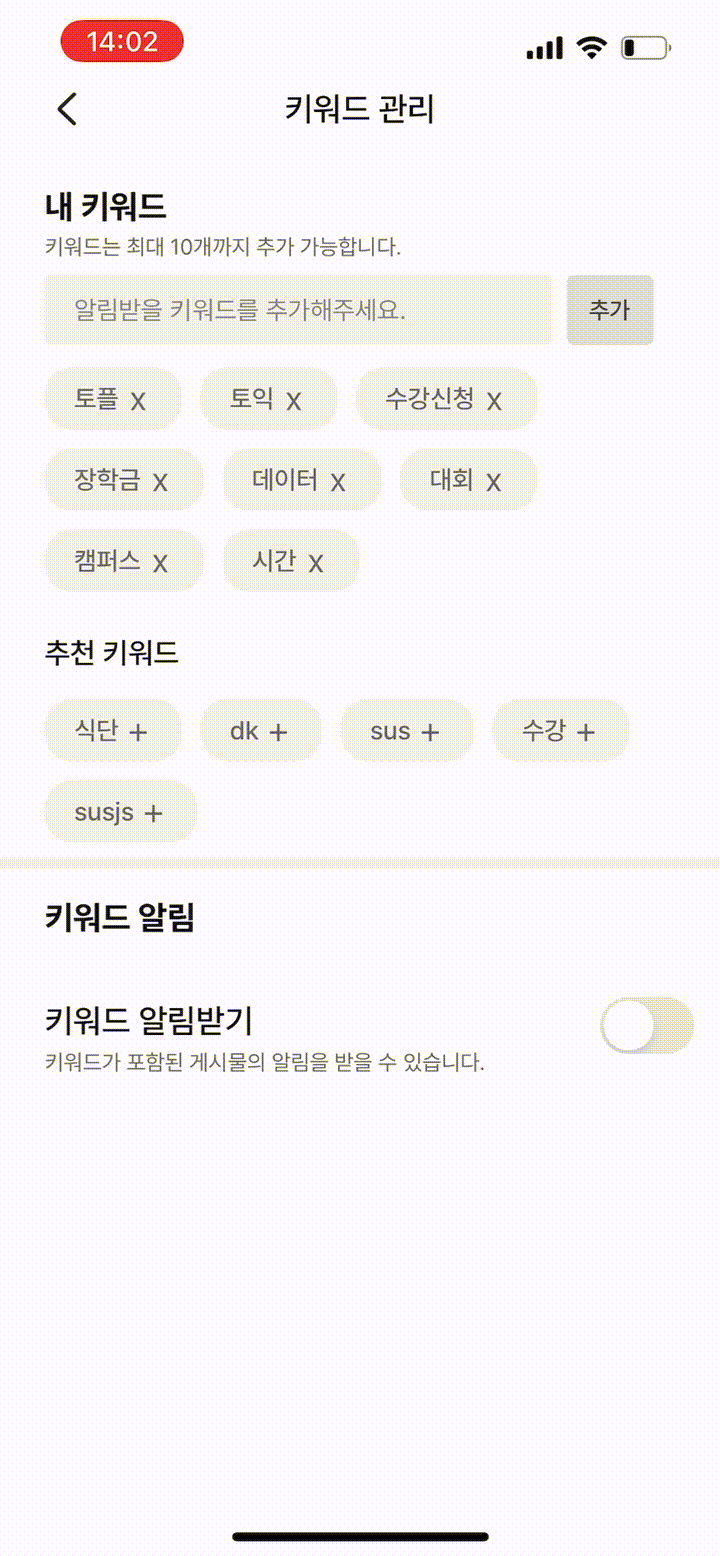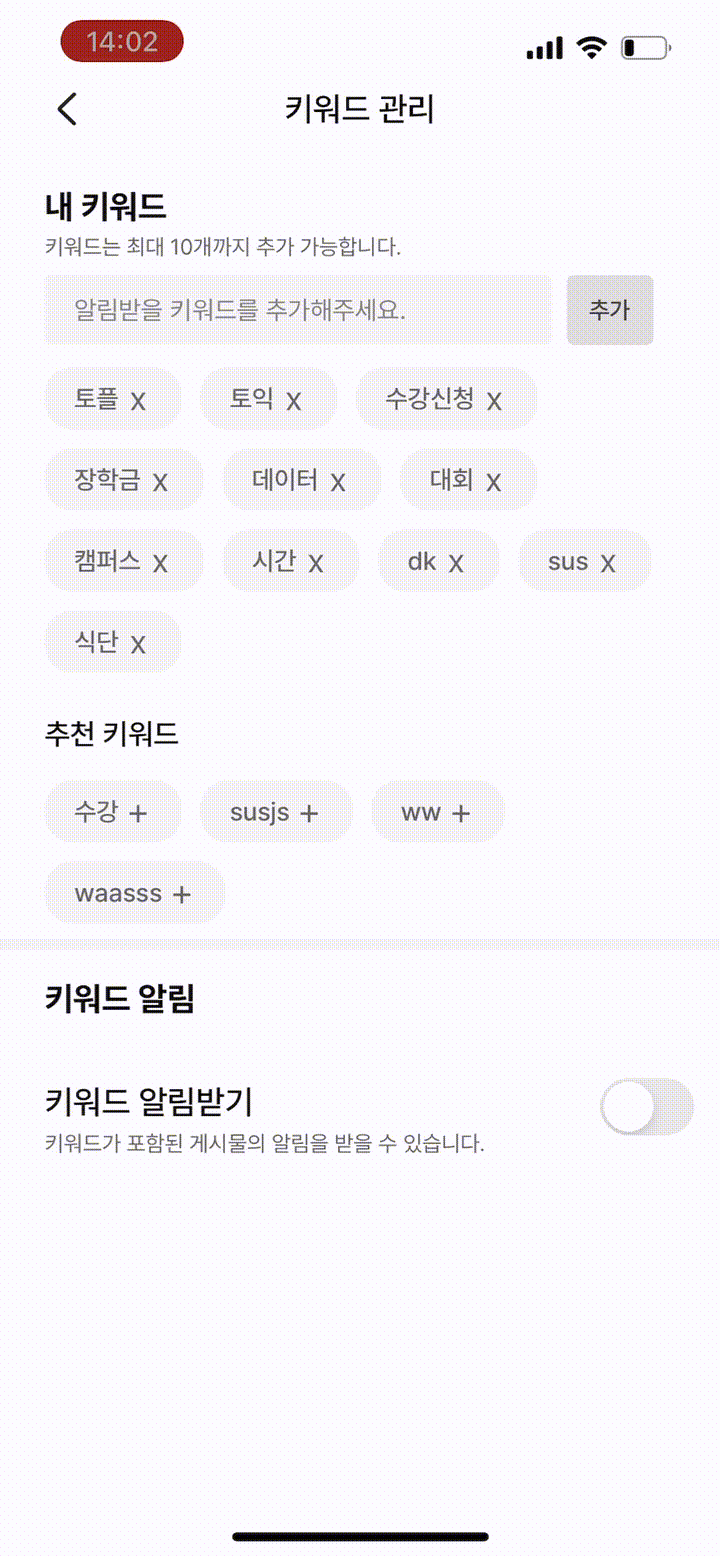
클라이언트에서 따닥 막으면 되는거 아니야?
클라이언트 쪽을 경험 해본 적이 많이 없어 잘 모르지만, 클라이언트 단에서 동시에 여러번 클릭 하는 것을 막는 여러 기법이 있다고 합니다. debouncing이나 throttling 같은 기법으로 클라이언트로부터 일정 주기안에 들어오는 동시 요청 중 단 하나만 수행하도록 할 수 있습니다. 그런데 이 방식은 여전히 허점이 존재합니다.
-
만약 클라이언트가 여러 개의 브라우저로 동시 요청을 보내면?
-
하나의 자원에 대해 여러 클라이언트가 동시에 처리 요청을 보내면?
이처럼 클라이언트 측에서만 문제를 해결하려고 한다면 허점이 생길 수 있습니다. 따라서 클라이언트 측 처리는 보조적인 수단일 뿐이며, 근본적으로 동시성 문제를 해결할 수 없다고 판단했습니다.
분산락을 도입한 이유
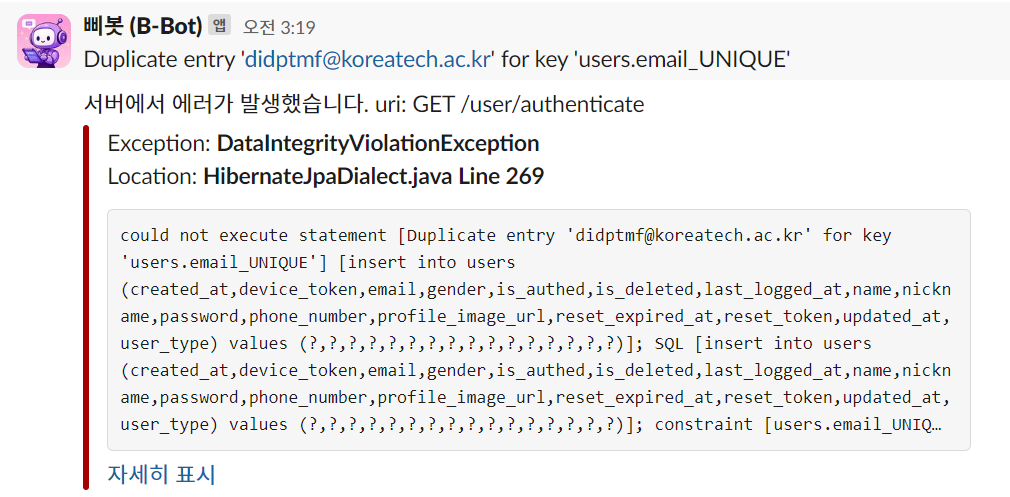
또한 서비스를 운영하면서 곳곳에서 동시성 문제가 발생하곤 했습니다. 기존에는 애플리케이션 레벨의 락이나 try-catch를 통해 단순하게 동시성을 제어했지만, 이러한 방식만으로는 한계가 있다고 판단했습니다. try-catch로는 에러가 발생한 후에야 처리할 수 있으며, 동시성 문제의 근본적인 해결책이 되지 못하기 때문입니다. 이에 따라 Redisson을 도입하게 된 이유는 다음과 같습니다.
애플리케이션 레벨 락의 한계
애플리케이션 레벨 락은 웹 서버가 단 한 대일 때는 정상적으로 동작할 수 있습니다. 하지만 일반적으로 서버는 확장성을 고려해야 하므로 여러 대의 서버에서 락을 제어해야 하는 상황이 빈번합니다. 이러한 환경에서는 애플리케이션 레벨 락이 적합하지 않아 근본적인 해결책을 찾았습니다.
DB Named Lock의 속도 및 관리 부담
데이터베이스에서 제공하는 Named Lock을 사용할 수도 있지만, 이는 Redis보다 속도가 느리고 관리해야 할 부분이 많습니다. 물론 트래픽 규모가 크지 않거나 Redis 도입이 부담스러운 경우에는 적절한 선택이 될 수 있습니다. 하지만 저희 서비스의 경우 Redis를 이미 사용하고 있었기 때문에 더욱 빠르고 효율적인 Redisson을 선택했습니다.
낙관적 락/비관적 락의 한계
먼저 각 락을 간단하게 설명하면
-
비관적 락: 트랜잭션 시작 시 데이터 충돌이 발생할 것이라고 가정하고 데이터베이스 레벨에서 락을 설정하는 방식입니다. 데이터 정합성을 확실하게 보장하지만, 다른 트랜잭션의 접근을 차단해 성능 저하를 일으킬 수 있습니다. 특히 충돌 가능성이 낮은 상황에서 사용하면 불필요한 락 비용이 발생할 수 있습니다.
-
낙관적 락: 반대로, 낙관적 락은 충돌이 드물 것이라 가정하고, 트랜잭션 종료 시점에만 충돌 여부를 확인합니다. 트랜잭션 시작 시점에 버전 정보를 가져와 종료 시 충돌이 발생하면 롤백하는 방식으로 동작합니다. 충돌이 적게 발생한다면 성능 면에서 유리하지만, 충돌 시 트랜잭션이 롤백되어야 하므로 데이터 정합성을 유지하는 데 한계가 있습니다.
이처럼 두 방법 모두 데이터베이스 행(row)에 대한 잠금 방식이므로, 성능 저하나 확장성의 이슈가 생길 수 있습니다. 또한 요청 쓰레드에 대한 잠금을 수행할 수 없어서 선택하지 않았습니다.
이러한 이유로, 분산 락을 도입하게 되었습니다. Redis를 활용하여 락을 관리함으로써 여러 서버 인스턴스에서 데이터를 공유하더라도 동시성을 제어할 수 있으며, 이미 인프라에 Redis가 구축되어 있었기 때문입니다.
왜 Redisson?
분산 락은 보통 Redis 기반으로 구현하고 Redis와 통신하는 Java 라이브러리에는
Lettuce와 Redisson이 있는데 대부분은 Redisson을 사용합니다. 이유가 뭘까요?
먼저 각각의 동작 방식을 볼 필요성이 있습니다.
Lettuce
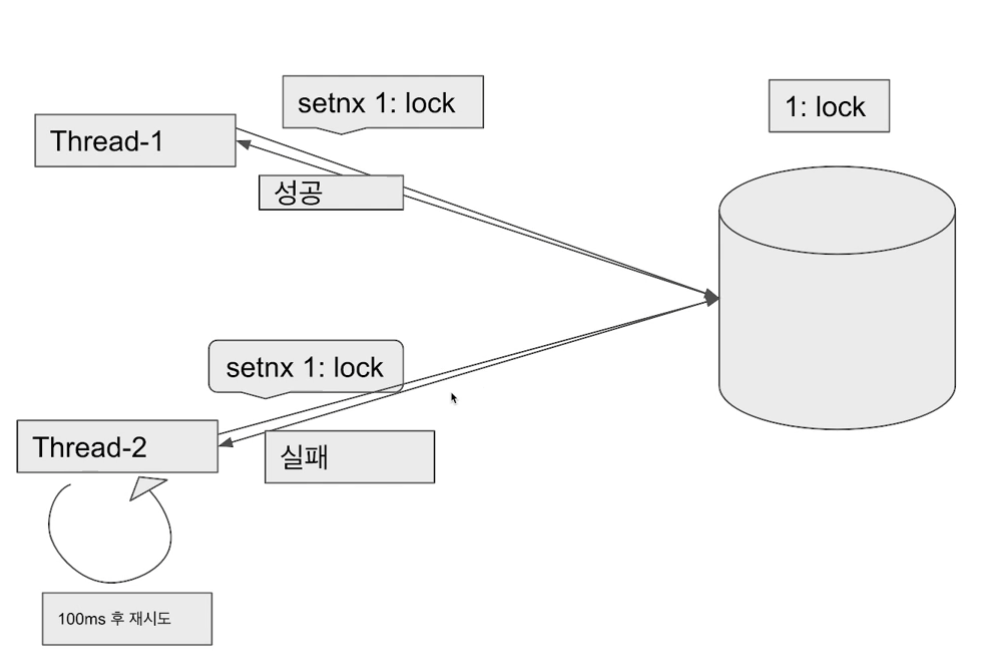
Lettuce는 Redis의 setnx() 명령어를 사용하여 락을 구현하며, Spin Lock 방식을 사용합니다. 즉, 락을 획득하려는 스레드가 다른 스레드에 의해 락이 점유되어 있으면, 락이 해제될 때까지 계속 확인하는 방식으로 동작하며, 이 Retry 로직은 개발자가 직접 작성해야 합니다.
-
장점
락 획득에 경쟁이 거의 발생하지 않아 빠른 응답을 제공합니다.
락 획득에 필요한 시간이 짧습니다. -
단점
락을 획득하지 못하면 무한 루프에 빠질 위험이 있습니다.
락이 해제되지 않은 상태로 장시간 유지되면 문제가 발생할 수 있습니다.
Redisson
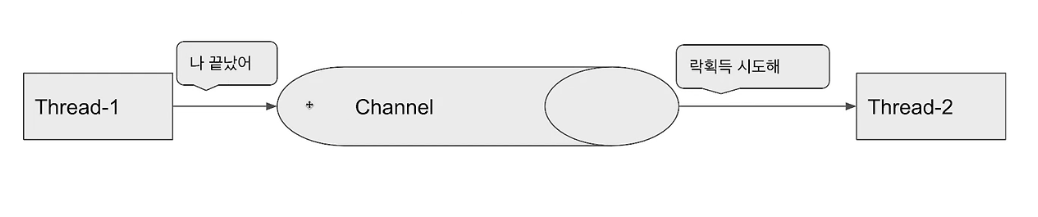
Redis의 pub/sub 메커니즘을 사용하여 락을 구현합니다.
pub/sub 메커니즘은 publisher가 메시지를 발행하면 subscriber가 해당 메시지를 수신하는 방식입니다.
락이 해제되면 락을 subscribe 하는 클라이언트는 락이 해제 되었다는 신호를 받고 락 획득을 시도하게 됩니다.
- 장점
락을 획득하기 위한 경쟁이 발생하지 않으므로 효율적입니다.
락이 장시간 해제되지 않는 문제가 없고, 안정적으로 해제 및 재획득이 가능합니다. - 단점
setnx() 명령어를 사용하는 Lettuce에 비해 성능이 다소 떨어질 수 있습니다.
정리
최종적으로 Redisson을 선택한 이유를 정리하면 다음과 같습니다.
-
Lettuce의 Spin Lock 방식은 무한 루프에 빠질 위험이 있어 개발자가 직접 재시도 로직을 구현해야 합니다. 반면, Redisson은 pub/sub 메커니즘을 사용하여 락이 해제되면 즉시 신호를 받아 안정적으로 락을 획득하고 해제할 수 있습니다.
-
Redisson은 락 획득, 해제, 타임아웃 등의 관리 로직을 자동으로 처리해주기 때문에 개발자가 별도로 관리할 필요가 없어 편리합니다. 이미 Redis 인프라를 사용하고 있다면, 성능과 안정성 측면에서 Redisson은 분산 락 라이브러리로 최적의 선택입니다.
이러한 이유로 안정성과 관리 편의성을 고려해 Redisson을 선택하게 되었습니다.
구현
동시성 문제가 여러 곳에서 발생했기 때문에, AOP를 적용하여 다양한 상황에서 사용할 수 있도록 커스텀 어노테이션으로 락을 구현했습니다. 저희 서비스의 모든 코드는 github에서 확인하실 수 있습니다.
build.gradle에 의존성 추가
먼저 본격적으로 구현하기 앞서 의존성을 추가해야 합니다.
implementation 'org.redisson:redisson-spring-boot-starter:3.35.0'의존성의 최신 버전은 여기에서 확인할 수 있고, 스프링 버전과의 호환 여부는 여기에서 확인하실 수 있습니다.
redisson config 추가
@Configuration
@Profile("!test")
public class RedissonConfig {
@Value("${spring.data.redis.host}")
private String redisHost;
@Value("${spring.data.redis.port}")
private int redisPort;
@Value("${spring.data.redis.password:}")
private String redisPassword;
private static final String REDISSION_HOST_PREFIX = "rediss://";
@Bean
public RedissonClient redissionClient() {
Config config = new Config();
config.useSingleServer()
.setAddress(REDISSION_HOST_PREFIX + redisHost + ":" + redisPort)
.setPassword(redisPassword.isEmpty() ? null : redisPassword);
return Redisson.create(config);
}
}인터넷에 있는 대부분의 자료는 로컬에서 진행하기 때문에
REDISSION_HOST_PREFIX = "redis://로 되어 있는데 실제 대부분의 서비스는 SSL 통신을 사용하므로 "redis://"가 아닌 "rediss://"로 설정해야 합니다.
또한 서버 redis에는 비밀번호가 걸려 있고 로컬에서는 걸려 있지 않기에 삼항 연산자를 이용해 setpassword를 해줬습니다.
aop를 위한 커스텀 어노테이션 선언
@Documented
@Target(METHOD)
@Retention(RUNTIME)
@Profile("!test")
public @interface ConcurrencyGuard {
String lockName();
long waitTime() default 5L;
long leaseTime() default 3L;
TimeUnit timeUnit() default TimeUnit.SECONDS;
}ConcurrencyGuardAspect 정의
@Slf4j
@Aspect
@Component
@Profile("!test")
@RequiredArgsConstructor
public class ConcurrencyGuardAspect {
private final RedissonClient redissonClient;
private final TransactionAspect transactionAspect;
@Around("@annotation(ConcurrencyGuard) && (args(..))")
public Object handleConcurrency(ProceedingJoinPoint joinPoint) throws Throwable {
ConcurrencyGuard annotation = getAnnotation(joinPoint);
Object[] args = joinPoint.getArgs();
String lockName = getLockName(args, annotation);
RLock lock = redissonClient.getLock(lockName);
try {
boolean available = lock.tryLock(annotation.waitTime(), annotation.leaseTime(), annotation.timeUnit());
if (!available) {
throw ConcurrencyLockException.withDetail("Redisson GetLock 타임 아웃 lockName: " + lockName);
}
return transactionAspect.proceed(joinPoint);
} finally {
try {
lock.unlock();
} catch (IllegalMonitorStateException e) {
log.warn("Redisson 락이 이미 해제되었습니다 lockName: " + lockName);
}
}
}
private ConcurrencyGuard getAnnotation(ProceedingJoinPoint joinPoint) {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
return method.getAnnotation(ConcurrencyGuard.class);
}
private String getLockName(Object[] args, ConcurrencyGuard annotation) {
String lockNameFormat = "lock:%s:%s";
String relevantParameter;
if (args.length > 0) {
relevantParameter = args[0].toString();
} else {
relevantParameter = "default";
}
return String.format(lockNameFormat, annotation.lockName(), relevantParameter);
}
}Redisson은 같은 이름의 락은 순차 처리하고, 다른 이름의 락은 병렬 처리하는 방식을 사용합니다.
- 같은 이름의 락 처리:
- 동일한 lockName을 가진 락은 한 번에 하나의 스레드만 처리할 수 있습니다.
- 락을 이미 소유한 스레드가 있는 경우 다른 스레드들은 대기 상태에 들어가고, 락이 해제되면 순차적으로 실행됩니다.
- 이를 통해 동일한 자원에 대한 동시성 문제를 방지합니다.
- 다른 이름의 락 처리:
- 서로 다른 lockName을 가진 락은 독립적으로 관리되므로 병렬 처리가 가능합니다.
- 즉, 각기 다른 자원에 대한 요청들은 동시에 처리될 수 있어, 효율적인 동시성 제어가 가능합니다.
락의 이름 생성 로직
동시성 문제를 더 효과적으로 관리하기 위해 메서드의 첫 번째 인자를 기준으로 락 이름을 생성하도록 설정했습니다. ConcurrencyGuard 어노테이션이 적용된 메서드의 첫 번째 파라미터 값을 고유한 lockName으로 사용하여 자원별로 락을 관리합니다.
예를 들어, 첫 번째 인자가 groupId라면 각 groupId별로 독립적인 락이 생성됩니다. 이때 동일한 groupId에 대한 요청은 순차적으로 처리되고, 서로 다른 groupId에 대한 요청은 병렬로 처리됩니다. 이를 통해 락의 범위를 세분화하여 불필요한 대기 시간을 줄이고 동시성 처리의 효율을 높였습니다.
Redisson의 이러한 구조는 자원 단위로 락을 생성해 필요할 때만 락을 점유하고, 다른 자원에 대해서는 병렬로 처리하는 동시성 제어를 가능하게 합니다.
트랜잭션 관리
@Profile("!test")
@Component
public class TransactionAspect {
// leaseTime보다 트랜잭션 타임아웃은 작아야 한다.
// leaseTimeOut 발생 전에 rollback 시키기 위함
@Transactional(propagation = Propagation.REQUIRES_NEW, timeout = 2)
public Object proceed(final ProceedingJoinPoint joinPoint) throws Throwable {
return joinPoint.proceed();
}
}@ConcurrencyControl이 선언된 메서드는 Propagation.REQUIRES_NEW 옵션을 지정해 부모 트랜잭션과 무관하게 별도의 트랜잭션으로 동작하도록 설정되어 있습니다. 이렇게 함으로써 트랜잭션이 독립적으로 처리되고, 트랜잭션이 커밋된 이후에 락이 해제되도록 제어합니다.
왜 Propagation.REQUIRES_NEW를 사용하는가?
분산 락과 트랜잭션의 문제점은 락을 언제 해제하느냐와 관련이 있습니다. 만약 분산 락 트랜잭션이 부모 트랜잭션과 동일한 트랜잭션에서 수행된다면, 락은 부모 트랜잭션이 종료되는 시점에 해제됩니다.
이렇게 되면 락이 해제된 상태에서도 트랜잭션이 커밋되지 않았기 때문에, 다른 스레드에서는 락을 획득할 수 있지만 아직 커밋되지 않은 변경 전 데이터를 조회하게 되는 문제가 발생합니다. 이런 경우, 동시성 환경에서 데이터 정합성이 깨질 수 있습니다.
데이터 정합성 보장을 위해
데이터 정합성을 보장하려면 락이 트랜잭션의 커밋 이후에 해제되어야 합니다. 이를 위해서는 트랜잭션이 락의 유지 시간(leaseTime)보다 짧게 설정되어야 하며, Propagation.REQUIRES_NEW 옵션을 통해 새로운 트랜잭션에서 로직을 수행해야 합니다.
이러한 구조를 위해 TransactionAspect 클래스에서는 joinPoint를 넘겨받아 새로운 트랜잭션에서 로직을 처리하도록 했습니다. 이렇게 하면 락이 올바른 시점에 해제되고, 트랜잭션 커밋 이후에 다른 스레드가 올바른 데이터를 조회하게 되어 동시성 환경에서의 데이터 정합성을 유지할 수 있습니다.
마무리
음 어떻게 마무리를 지어야 할지 모르겠네요..ㅎㅎ
이렇게 길게 쓰려 안 하는데 호흡이 많이 길어졌네요. 많이 부족한 긴 글 읽어주셔서 감사합니다!
궁금한 점이나 피드백 있으면 언제든지 편하게 남겨주시면 감사하겠습니다😊
참고자료
- https://gengminy.tistory.com/59
- https://kiseoky.tistory.com/7
- https://ttl-blog.tistory.com/1568#%F0%9F%A4%94%20%EB%82%99%EA%B4%80%EC%A0%81%20%EB%9D%BD%EA%B3%BC%20%EB%B9%84%EA%B4%80%EC%A0%81%20%EB%9D%BD%20%EC%82%AC%EC%9A%A9%20%EC%8B%9C%20%EB%AC%B8%EC%A0%9C-1
- https://velog.io/@meong/SpringBoot-Redisson-AOP-%EC%A0%81%EC%9A%A9%EA%B8%B0-%EC%9E%AC%EA%B3%A0-%EB%8F%99%EC%8B%9C%EC%84%B1-%EC%A0%9C%EC%96%B4
- https://dkswnkk.tistory.com/711
- https://velog.io/@bagt/Database-%EB%82%99%EA%B4%80%EC%A0%81-%EB%9D%BD-%EB%B9%84%EA%B4%80%EC%A0%81-%EB%9D%BD
- https://velog.io/@haron/%EC%99%B8%EB%9E%98%ED%82%A4Foreign-Key%EC%99%80-%EB%8D%B0%EB%93%9C%EB%9D%BDDeadLock-%EA%B7%B8%EB%A6%AC%EA%B3%A0-%EC%BF%BC%EB%A6%AC-%EC%A7%80%EC%97%B0-%EC%8B%A4%ED%96%89-eruedsy4
- https://velog.io/@znftm97/%EB%8F%99%EC%8B%9C%EC%84%B1-%EB%AC%B8%EC%A0%9C-%ED%95%B4%EA%B2%B0%ED%95%98%EA%B8%B0-V3-%EB%B6%84%EC%82%B0-DB-%ED%99%98%EA%B2%BD%EC%97%90%EC%84%9C-%EB%B6%84%EC%82%B0-%EB%9D%BDDistributed-Lock-%ED%99%9C%EC%9A%A9
