앞서 머신러닝의 목적은 데이터를 통해 모델을 만들어 문제를 해결하는 것이라고 했다. 즉, 학습 데이터로 모델을 구축하고 모델에 새로운 데이터를 적용하면 다양한 문제를 예측할 수 있다. 이때 학습 데이터에 정답이 포함되어 있을 경우 지도 학습, 그렇지 않은 경우 비지도 학습이라고 한다. 그리고 해결하고자 하는 문제에 따라 학습 알고리즘을 다르게 선택해야 한다고 했다. 이번 시리즈에서는 간단한 머신러닝 프로젝트 과정을 통해 머신러닝의 주요 단계를 이해하고 실제로 머신러닝 모델로 어떤 문제를 어떻게 해결할 수 있는 지를 소개하겠다. 그리고 직접 만든 모델로 예측한 결과를 온라인 경진대회 플랫폼인 캐글(kaggle) 사이트에 제출하는 것까지 소개할 예정이다.
참고로 이 포스트는 캐글 사이트에서 좋은 스코어를 내기 위한 방법을 소개하는 글이 아니며 1)간단한 예측 모델로 머신러닝 프로젝트 과정을 최대한 쉽게 소개 하고 2)캐글을 처음 접하는 사람들에게 그 프로세스를 친절하게 알려주는 것 이 목적이다. 만약 캐글 사이트에 결과를 제출하는 과정에 대해 바로 알고 싶다면 목차에서 5. 결과 를 확인하기 바란다.
- 이번 프로젝트에서는 날짜에 따른 자전거 대여수를 예측하고자 한다.
- 데이터는 캐글 사이트(데이터 사이언티스트와 머신러닝 전문가들을 위한 온라인 경진대회 플랫폼)에서 Bike Sharing Demand - Forecast use of a city bikeshare system 데이터를 다운받아 사용했다. 이 대회는 이미 오래 전에 끝났지만 여전히 머신러닝을 학습하는 사람들에게 연습 자료로 많이 활용되고 있다.

1. 데이터 소개
- 날짜 및 시간, 기온, 습도, 풍속 등의 정보를 기반으로 1시간 간격의 자전거 대여 횟수를 기록한 데이터이다.
- 기록 날짜는 2011년 1월 ~ 2012년 12월까지이다.
- 데이터에 대한 자세한 정보는 위에 소개된 캐글 사이트에서 확인 가능하다.
2. 탐색적 데이터 분석
- EDA(Exploratory Data Analysis)라고 자주 불리는 말 그대로 데이터를 탐색하면서 분석하는 과정이다.
- 시각화 자료를 만들거나 기술 통계값 조회, 결측치나 이상치 등을 확인하고 데이터에 대해 알아가는 단계이다.
앞으로 진행할 프로젝트의 최종 목표는 학습 데이터로 모델을 학습시킨 후 공공자전거의 수요량을 예측하는 것이다. 즉, 테스트 데이터 정보(features, 종속변수)를 바탕으로 제출용 데이터의 'count'(target, 독립변수)를 예측하는 것이다.
2-1. 데이터셋(dataset) 확인
모델링 과정 그리고 kaggle 대회에 참가하기 위해서는 먼저 데이터의 형태(shape)를 잘 파악하는 것이 중요하다.
- 모델 학습용 데이터(
train.csv) -> (10886, 12)

-
테스트용 데이터(
test.csv) -> (6493, 9)

-
제출용 데이터(
submission.csv) -> (6493, 2)

학습 데이터로 학습 시킨 모델을 예측하는 데 사용하기 위해서는 모델 학습에 필요한 데이터와 테스트용 데이터의 모양(shape)이 같아야 한다. 더 정확하게는 target을 예측하기 위해 필요한 features(특성)이 같아야 한다.
2-2. 데이터 타입(type) 확인
train_raw.info() # 데이터프레임에 대한 기본적인 정보 출력
데이터의 타입을 확인하니 날짜 데이터가 object 타입이다. 날짜 데이터를 보다 쉽게 조회하기 위해 아래와 같이 datetime 타입으로 변경했다.
train = train_raw.copy()
train['datetime'] = pd.to_datetime(train['datetime'])
train.dtypesdatetime 컬럼 데이터의 타입이 object 에서 datetime 으로 변경된 것을 확인할 수 있다.

2-3. 결측치(NaN) 확인
train.isnull().sum() # 결측치인 값을 조회(True)해 그 갯수를 셈
데이터에 결측치가 없는 것을 확인했다.
2-4. 특성 공학(Feature Engineering)
Feature Engineering을 하는 과정은 생각보다 복잡하며 데이터에 대한 도메인 지식이 충분하지 않다면 어떤 특성(feature)들이 더 중요한 지 혹은 덜 중요한 지 판단하고 결정하기 어렵다.
실제로 데이터 사이언티스트들이 가장 많은 시간을 쏟는 과정이다.
이 단계에서 여러 가지를 시도해 볼 수 있는데, 먼저 날짜 데이터부터 살펴보자.
결론부터 말하면
datetime형태의 데이터는 선형 회귀에 사용할 수 없다(참고로 선형 회귀는 정수형 혹은 실수형 데이터를 다룬다).날짜 데이터는 시계열 데이터에 속한다. 시계열 데이터는 관측 데이터가 시간적 순서를 가진 데이터이며 이 데이터는 변수 간 상관 관계가 있는 데이터를 다루며, 과거의 데이터를 통해 현재 혹은 미래를 예측하는 데 사용한다. 일반적인 예측 문제에서는 feature와 target간의 상관 관계를 본다면, 시계열 데이터는 시간에 따른 어떤 움직임 혹은 변화를 바탕으로 문제를 예측한다.
따라서 시계열 데이터를 다룰 때는 특별한 주의가 필요하다(기회가 된다면 나중에 시계열 데이터를 다루는 법에 대해 따로 소개하겠다).
날짜 데이터를 정수 형태로 변환한 데이터를 새로운 feature로 추가한다(년, 월, 일, 시, 분, 초, 요일).
train['year'] = train['datetime'].dt.year
train['month'] = train['datetime'].dt.month
train['day'] = train['datetime'].dt.day
train['hour'] = train['datetime'].dt.hour
train['minute'] = train['datetime'].dt.minute
train['second'] = train['datetime'].dt.second
# 요일 데이터 - 일요일은 0
train['dayofweek'] = train['datetime'].dt.dayofweek
describe() 함수를 통해 아래와 같이 데이터의 기초 통계값을 쉽게 조회할 수 있다.

먼저 일별 데이터(day)의 범위(최소값~최대값)가 1 ~ 19이다. 따라서 19일 이후의 데이터는 없는 것으로 예상된다. 그리고 분(minute)과 초(second) 데이터는 모든 값이 0임을 확인할 수 있다. 따라서 day와 minute, second 컬럼을 삭제한다.
2-5. 데이터 시각화
데이터를 시각화하여 분석하면 데이터를 직접 조회했을 때 미처 확인하지 못한 사실을 보다 쉽고 빠르게 파악할 수 있다.
연도별 자전거 대여수를 비교하니 2011년도 보다 2012년도에 대여수가 늘었다.

다음은 전체 대여수와 계절별, 시간대별, 근무일 여부에 따른 대여수를 비교한 그래프이다.

계절별로 보면 봄에 대여량이 가장 적고 시간별로는 출퇴근 시간대(8시, 17시)에 다른 시간대보다 대여량이 늘어나는 것을 확인할 수 있다. 근무일 여부에 따른 대여량은 큰 차이가 없다. 전체적으로 대여수(count) 데이터에 이상치(outliers)가 많이 발견된다. 이상치는 전체 데이터를 왜곡할 수 있기 때문에 이 부분은 필요에 따라 처리하는 것이 좋다.

날씨에 따른 시간대별 대여수를 확인하니 날씨에 따라 대여량에 차이가 조금씩 있는 것 같다. 그리고 자전거를 타기에 적합하지 않은 심한 비나 눈이 오는 날(4)은 그래프에 나타나지 않아 직접 조회해보니 실제로 관측된 날이 단 하루 있었다.

train['weather'].value_counts()
다음은 날씨의 특성별 대여량의 차이를 그래프로 나타낸 시각화 자료이다.
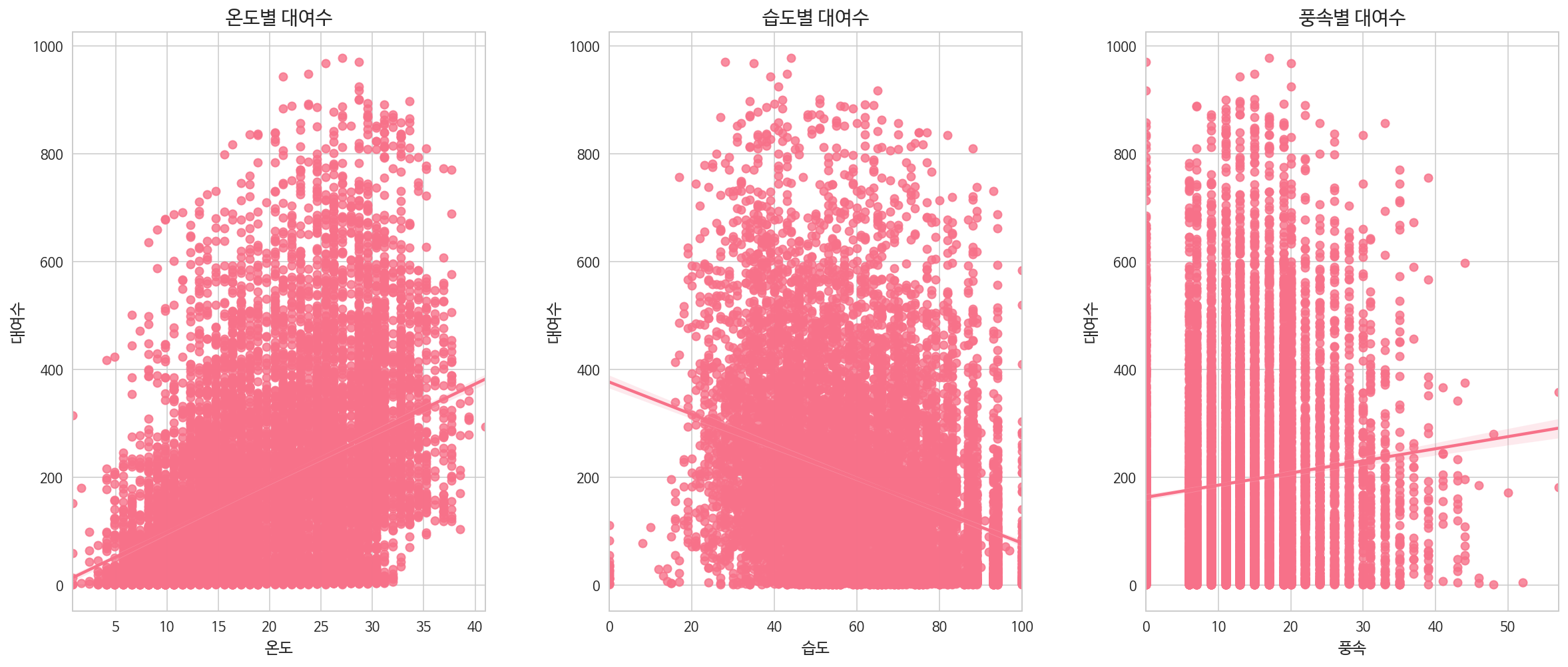
풍속별 자전거 대여수를 보면 값이 0인 데이터가 많아 실제로 계산해보니 전체 데이터의 약 12% 이상을 차지하고 있는 것을 확인했고, 그 결과 관측되지 않은 경우에 (결측치로써) 0을 대신 기록한 것이 아닐까라는 추측을 했다.
2-6. 상관 분석
데이터 간의 상관 관계를 분석하기 위해 상관계수를 구하고 시각화로 표현하였다.

대여량(count)과 가입자(registered)와의 상관관계가 아주 높게 나온 것을 확인할 수 있다. 하지만 registered는 예측해야 할 target이기 때문에 feature에서 제외된다.
또, 온도와 체감온도 간의 상관관계가 높아 둘을 같이 feature로 사용하기에 적합하지 않고 둘 중 하나만 사용해야 한다.
2-7. 이상치(outliers) 확인
앞서(위에서) 대여수에 이상치가 존재하는 것을 확인했다.

이상치를 판별할 때의 기준은 통계적으로 크게 2가지로 나뉜다. 필자는 여기서 2가지 방법을 다 적용해보았다.
방법1) Box-plot, IQR = Q3 - Q1
- IQR(Interquartile Range)은 사분위수의 상위 75% 지점의 값과 하위 25% 지점의 값 차이
- Q1에서 1.5 * IQR을 뺀 값(지점)을 최소 제한선, Q3에서 1.5 * IQR을 더한 값(지점) 이 최대 제한선으로 두고 최소 제한선 이하 혹은 최대 제한선 이상이 되는 값들을 이상치로 간주한다.
# 'count' 데이터에서 전체의 25%에 해당하는 데이터 조회
count_q1 = np.percentile(train['count'], 25)
count_q1
# 'count' 데이터에서 전체의 75%에 해당하는 데이터 조회
count_q3 = np.percentile(train['count'], 75)
count_q3
# IQR = Q3 - Q1
count_IQR = count_q3 - count_q1
count_IQR
# 이상치를 제외한(이상치가 아닌 구간에 있는) 데이터만 조회
train_clean = train[(train['count'] >= (count_q1 - (1.5 * count_IQR))) & (train['count'] <= (count_q3 + (1.5 * count_IQR)))]방법2) 3-sigma, 평균 ± 3 * 표준편차
- 평균 ± 3 * 표준편차 를 벗어나는 데이터는 이상치로 간주한다(정규분포 기반).
train_wo_outliers = train_clean[np.abs(train_clean["count"] - train_clean["count"].mean()) <= (3*train_clean["count"].std())]
이상치가 눈에 띄게 줄었다.
2-8. 데이터 정규화
위에서 언급했듯이 선형 회귀에서 datetime 타입의 데이터를 사용할 수 없다. 따라서 날짜 데이터를 숫자형 데이터 타입으로 변환한다.
# datetime -> integer 타입으로 변환하는 사용자 정의 함수
def to_integer(datetime):
return 10000 * datetime.year + 100 * datetime.month + datetime.day
# 데이터 타입 변경
datetime_int = train_wo_outliers['datetime'].apply(lambda x: to_integer(x))
train_wo_outliers['datetime'] = pd.Series(datetime_int)
datetime 데이터의 타입이 변경된 것을 확인할 수 있다.
다음으로 확인해야 할 데이터는 '자전거 대여수'이다. 이 데이터의 분포를 그래프로 나타내면 다음과 같다.

count 데이터의 분산 정도를 확인하니 long-tail 그래프 형태이다. 정규 분포 형태로 만들어 주기 위해 데이터에 로그를 씌워 데이터 값을 변형했지만 완벽한 정규 분포 형태를 따르지는 않지만 이전보다 약간의 정규 분포 형태에 가까워졌다.

3. 모델링
- 머신러닝 모델을 만들기 위해 다양한 라이브러리를 활용할 수 있다.
- 회귀(regression)는 통계에서 수치형 자료라 불리는 연속형/이산형 데이터를 예측할 때 주로 사용한다.
자전거 수요량을 예측하는 것은 이산형 데이터(교통 사고 건수 등 셀 수 있는 자료형)를 예측하는 문제이기 때문에 여기서는 회귀를 활용할 것이다. 그 중에서도 가장 기본인 선형 회귀(Linear Regression) 모델 을 scikit-learn 라이브러리를 활용해 간단하게 만들고 문제를 해결하는 법을 알아볼 것이다.
머신러닝에서 선형 회귀를 통해 문제를 해결한다는 말은 훈련 데이터에 가장 적합한(fit)한 선형 방정식(linear model)을 구하여 새로운 데이터(features)를 입력했을 때 값(target)을 예측하는 것이다.
모델을 만들기 전에 데이터셋의 모양(shape)을 확인한다.
- 훈련 데이터

- 테스트 데이터

테스트 데이터에 없는 두 features(casual, registered)를 제거하고 훈련 데이터에서 했던 feature engineering 작업을 테스트 데이터에도 해준다(주로 날짜 데이터).
- 훈련 데이터 -> (10577, 14)

- 테스트 데이터 -> (6493, 13)

작업 후 두 데이터를 비교하면 훈련 데이터에서 count를 제외하고는 feature 수와 형태(type)가 일치한다.
3-1. 데이터셋 나누기
훈련 데이터에서 feature와 target을 구분하고, 검증을 위한 validation 데이터셋을 훈련 데이터에서 분리하여 새로 생성해준다.
# target과 features 구분
target = 'count'
features = train_sub.columns.drop(target)
X = train_sub[features].copy()
y = train_sub[target].copy()
X_test = test.copy()
# 데이터를 편리하게 분할해주는 라이브러리 활용
from sklearn.model_selection import train_test_split
# 훈련 데이터의 25%를 검증 데이터로 활용
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=.25, random_state=42)3-2. 모델 만들기
scikit-learn 라이브러리를 활용해 선형 회귀 모델을 만든다.
from sklearn.linear_model import LinearRegression
# 선형 회귀 모델 선언
linear_model = LinearRegression()
# 모델 학습
linear_model.fit(X_train, y_train)모델을 학습하는 과정에서 학습 데이터(X_train, y_train)로 회귀 모델(방정식)을 만들어 alpha, beta 값을 계산한다.
4. 예측
4-1. 모델 퍼포먼스 계산
검증 데이터를 사용해 위에서 만든 선형 회귀 모델로 예측을 해본다.
# 자전거 대여수 예측(검증용 데이터)
y_val_pred = linear_model.predict(X_val)
y_val_pred
# y_val 전체 데이터 수는 2645
np.equal(y_val_int, y_val_pred_int).sum() # 1005두 데이터는 실수형인데 수요량은 갯수이기 때문에 정수형으로 데이터를 변경한 후에 실제값과 비교해봤더니 예측한 것 중 약 38% 정도 맞았다.
4-2. 테스트 데이터 예측
테스트 데이터는 target(자전거 수요량)을 제외한 형태의 데이터셋이다(테스트 데이터에서 주어진 feature(종속 변수)로 target(독립 변수)를 예측).
y_pred = linear_model.predict(X_test)
y_pred # 예측 결과5. 결과
예측 결과를 캐글에 제출할 차례이다. 먼저 결과 제출을 위해서 다운받은 submission.csv 파일을 확인한다.

임의의 자전거 수요량(수) 데이터(count)가 들어있다. 이 데이터를 위에서 만든 모델로 예측한 결과(y_pred)로 변경한다.
submission['count'] = y_pred.astype(int)
submission.dtypes이 데이터를 파일(.csv)로 저장한다.
# kaggle 제출용 데이터 저장
submission.to_csv('./bike-demand-submission.csv', index=False)6. 캐글(kaggle)에 제출
로그인 후 Late Submission 으로 들어가서 업로드 모양의 아이콘을 클릭하면 파일을 선택할 수 있다. 앞에서 저장한 kaggle 제출용 파일을 제출하면 Leaderboard 에서 자신의 등수를 확인할 수 있다.

7. 맺음말
앞에서 확인했지만 이 포스트대로 진행할 경우 캐글에서 좋은 점수를 받기 힘들다. 서두에도 설명했듯이 이 포스트의 목적은 머신러닝 프로젝트 과정을 전체적으로 정리하고 이후에 모델의 성능을 높이는 방법에 대해서 차례대로 소개하기 위해 작성되었다. 앞으로 같은 데이터에 다른 모델을 적용했을 때 혹은 다른 데이터에 같은 모델 그렇지만 다른 방법으로 모델의 성능을 높이는 방법 등에 대해 더 알아보는 시간을 갖도록 하겠다.

weather 변수 시각화, 탐색 부분은 날씨에 따른 자전거 대여 수가 아닌, 날씨별 도수 같습니다.
groupby(by = 'weather').sum()를 하시면 날씨별 자전거 대여 총 수가 나옵니다!