
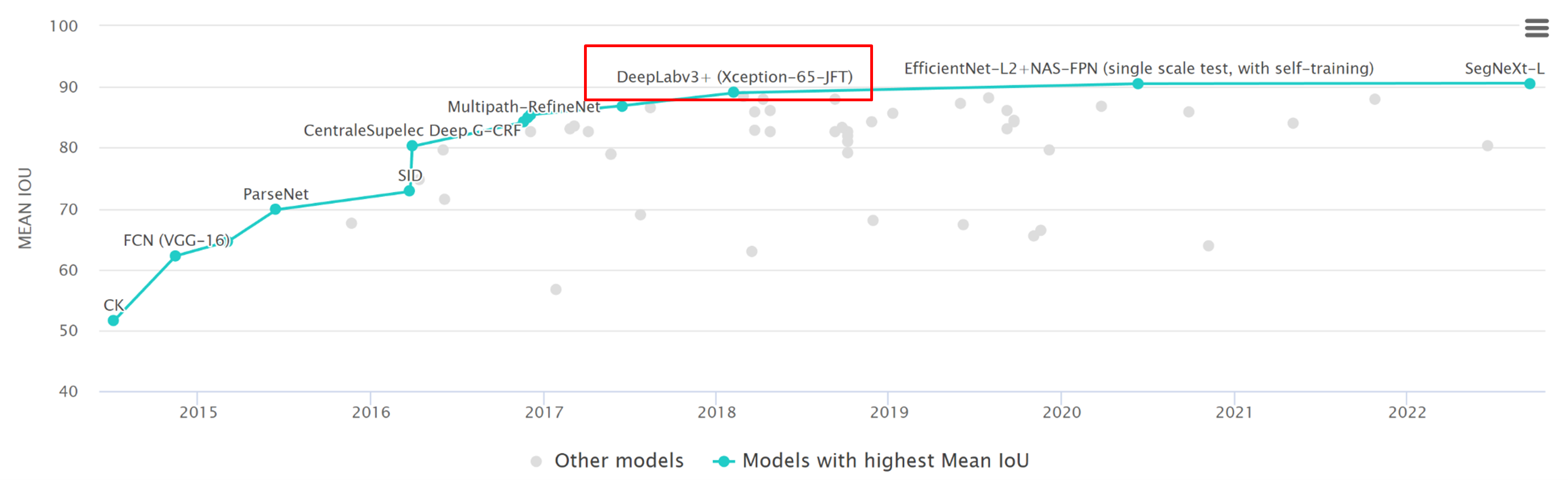
DeepLabV3Plus(ECCV 2018)
아래의 그림과 같이 사람과 background를 구분하는 것처럼, 입력 이미지에서 의미를 갖는 영역을 필셀별로 구분해내는 작업을 Semantic Segmentation이라고 한다.

DeepLab versions
- DeepLab V1 : ICLR 2105
- DeepLab V2 : TPAMI 2017
- DeepLab v3 : ECCV 2018
DeepLabV3Plus는 현재까지 준수한 성능을 가지고 있다. 그리고 모바일 버전의 디바이스에서도 real time으로 작동을 한다.
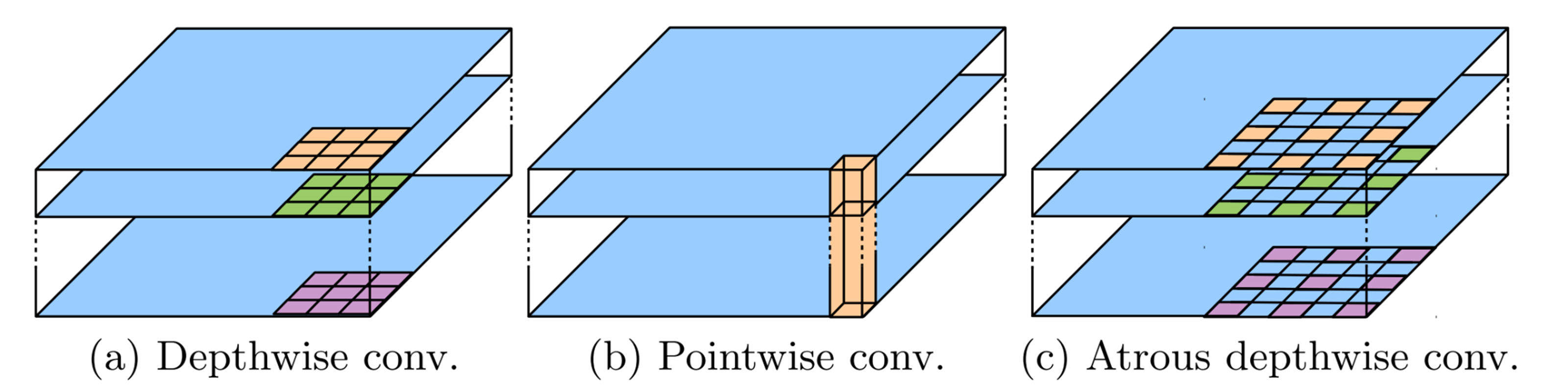
DeepLabV3Plus는 3가지 architecture improments를 가지고 있다.
기존에 모든 입력 체널에 필터를 연산한 것과는 다르게, Depthwise conv는 하나의 채널당 다른 필터를 적용하여 연산을 한다. 그리고 구멍을 뚫는 식으로 격자 무늬를 넓혀가면서 conv 연산을 진행하는 것을 제안한다.
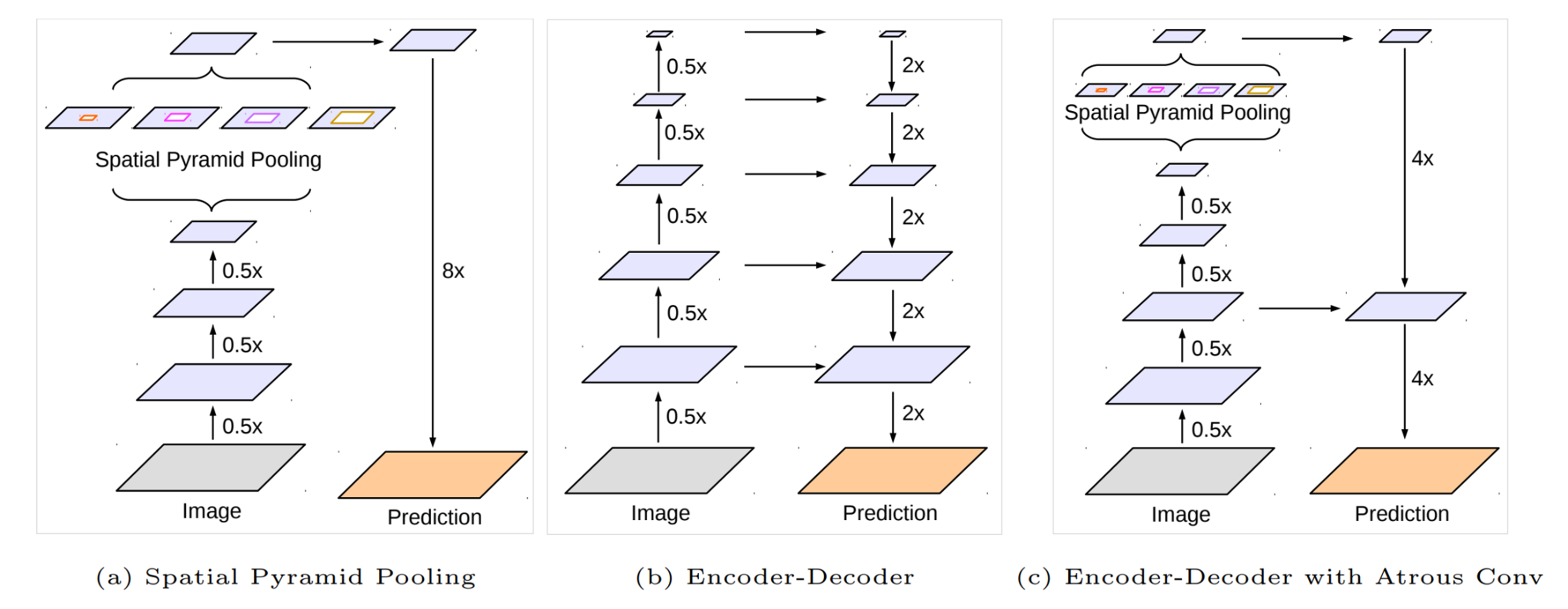
레졸루션을 줄여가며 컨볼루션 리셉티브 필드가 다른 풀링 레이어들(spatial pyramid pooling)을 거쳐서 가장 작은 레졸루션을 가진 feature map을 생성하고 업샘플리을 해서 에측을 진행한 것과 U-Net처럼 레졸루션을 줄이고 키우는 과정을 합치는 방법을 제안한다.
레졸루션을 4배로 키우고 다시 4배로 최종 16배로 키우는데, 중간 단계에서 연산을 더 하지 않는 이유는 성능 뿐만 아니라 효율도 좋게 만들기 위해서다.
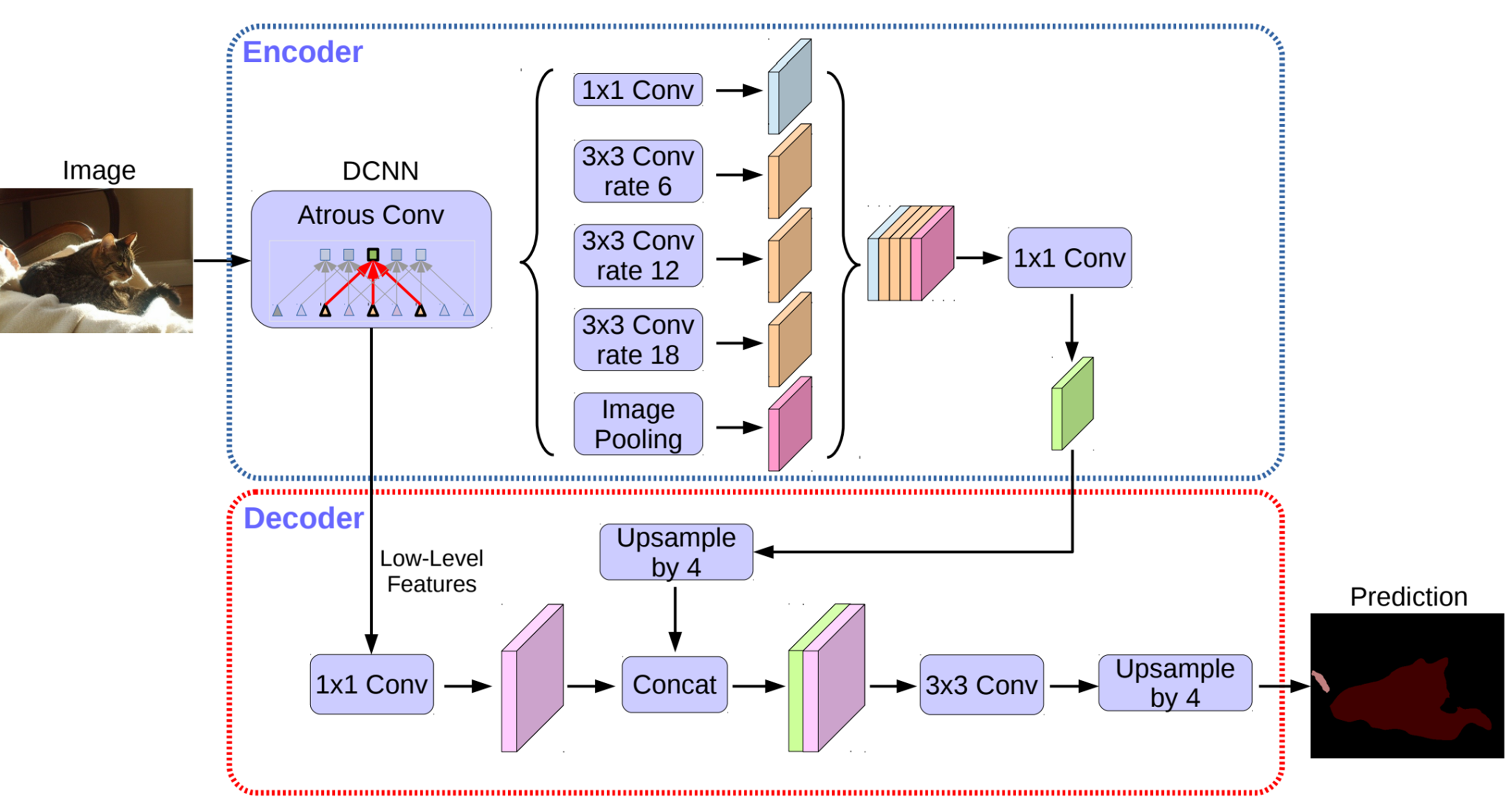

데이터 굽는 타자기