
U-Net++
U-Net
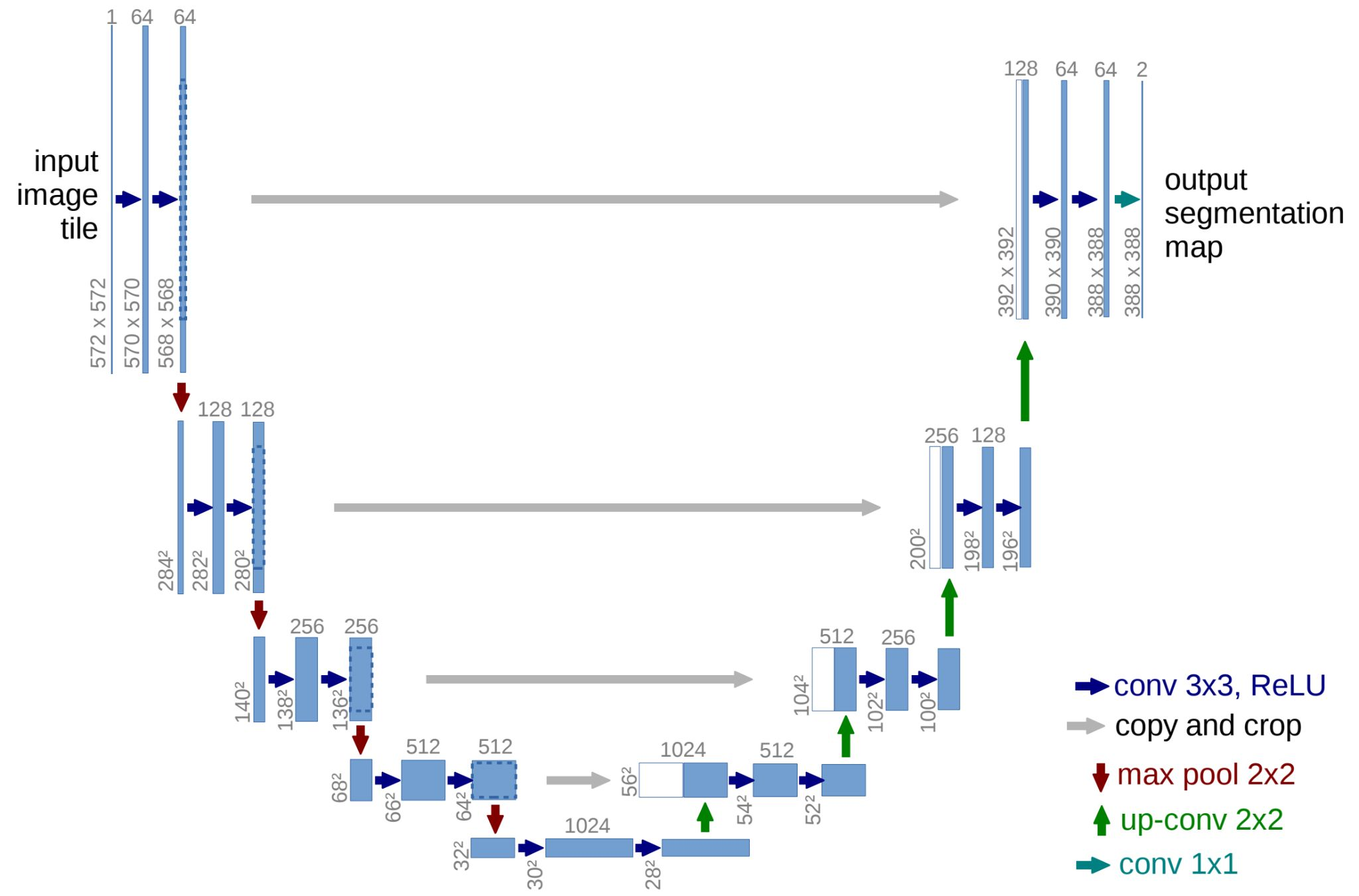
U-Net은 아키텍쳐 모양이 'U'자형으로 되어 있어 붙여진 이름이다.
기존 CNN은 input image의 레졸루션을 줄여가며 연산을 수행한 반면, U-Net은 레졸루션을 기존처럼 줄여가며 컨볼루션 연산을 수행하고 그 다음에는 2배씩 레졸루션을 키워가며 컨볼루션 연산을 수행한다.
그리고 down sampling때의 같은 레졸루션 크기를 갖는 feature map를 up sampling때의 feature map과 합치는 연산을 수행한다.
하이 레벨의 정보와 로우 레벨 정보를 함께 보존하면서 출력을 학습할 수 있도록 구성이 되어 있다.
U-Net++
U-Net ++의 원문은 A Nested U-Net Architecture for Medical Image Segmentation이다.
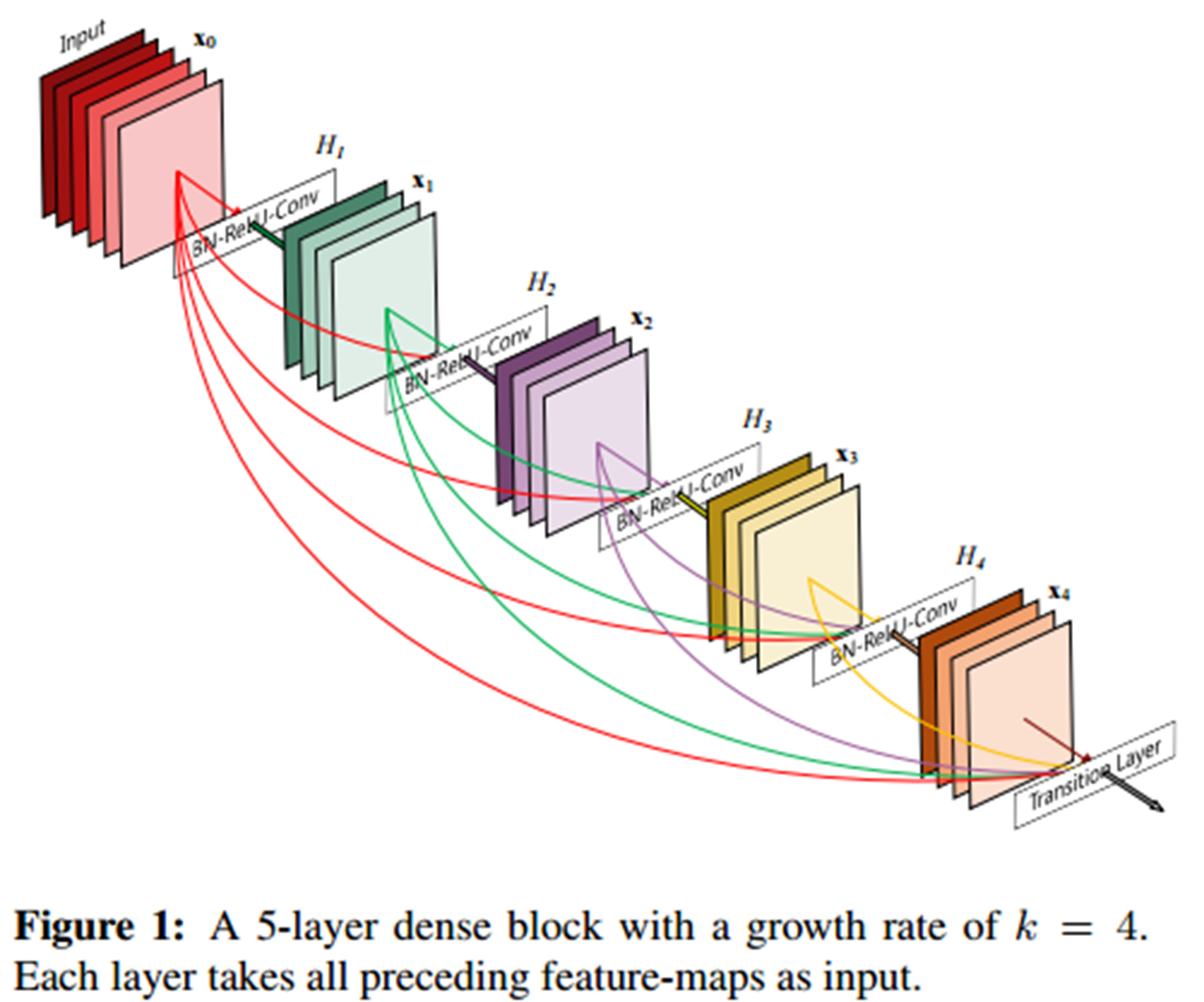
잠시 DenseNet(CVPR 2017)을 잠시 보면 아래의 그림과 같이, Input부터 다음 블럭'들'로 skip connection을 각각 넘겨준다. 그 다음 블럭에서 다음 블럭'들'로 다시 skip connection을 각각 넘겨주고 이 전체를 댄스 블럭 하나로, 이런 식으로 댄스 블럭 몇 개를 쌓는 구조로 만들어진다.
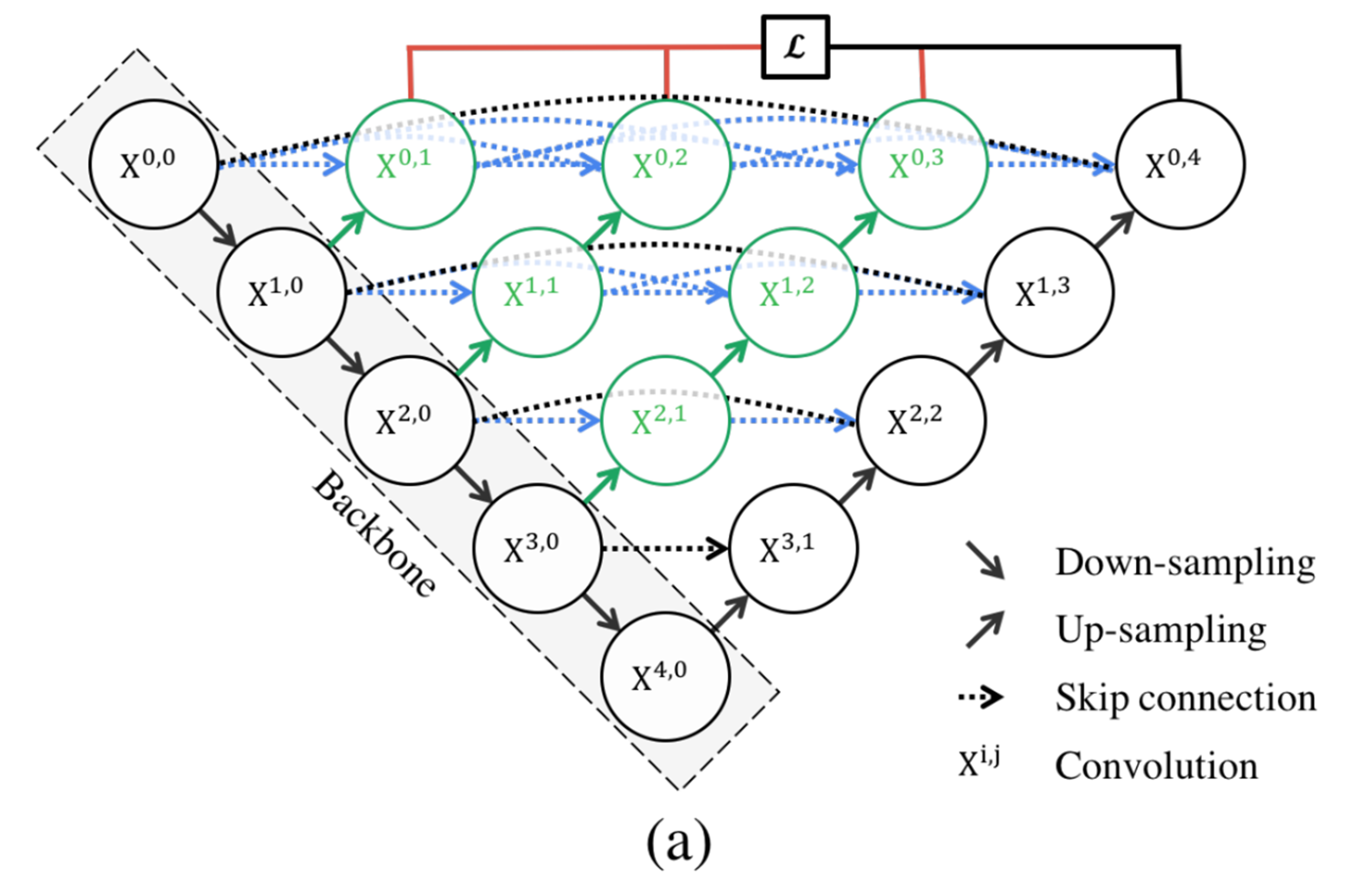
아래의 그림은 U-Net ++ 아키텍처다.
검정색으로 된 것이 기존의 U-Net 아키텍처이고, 녹색 Convolution과 다운 샘플링 과정 각각에서 업 샘플링하는 녹색과 파란색의 skip connection이 합쳐지는 Convolution이 추가 되었고 각각의 제일 윗 단에서 Loss가 계산되는 것이 추가가 된 형태로 아키텍처가 구성되어 있다.
그리고 DenseNet과 같이 같은 레졸루션을 가지는 Convolution'들'에 skip-connection을 넘겨준다.
Convolution X에서 앞자리는 다운 샘플링을 하면 순서이고 뒷자리는 업 샘플링의 순서를 말한다.
제일 윗단만 보면 Dense block과 똑같은 형태를 띄고 있는데, 추가적으로 각각의 Convolution에 업 셈플링된 Convolution이 Skip_connection이 추가로 합처진다.
그래서 제일 오른쪽 부분을 제외하더라도 나머지 부분들이 U-Net 아키텍처가 되는 것처럼 구성이 되어 있다.
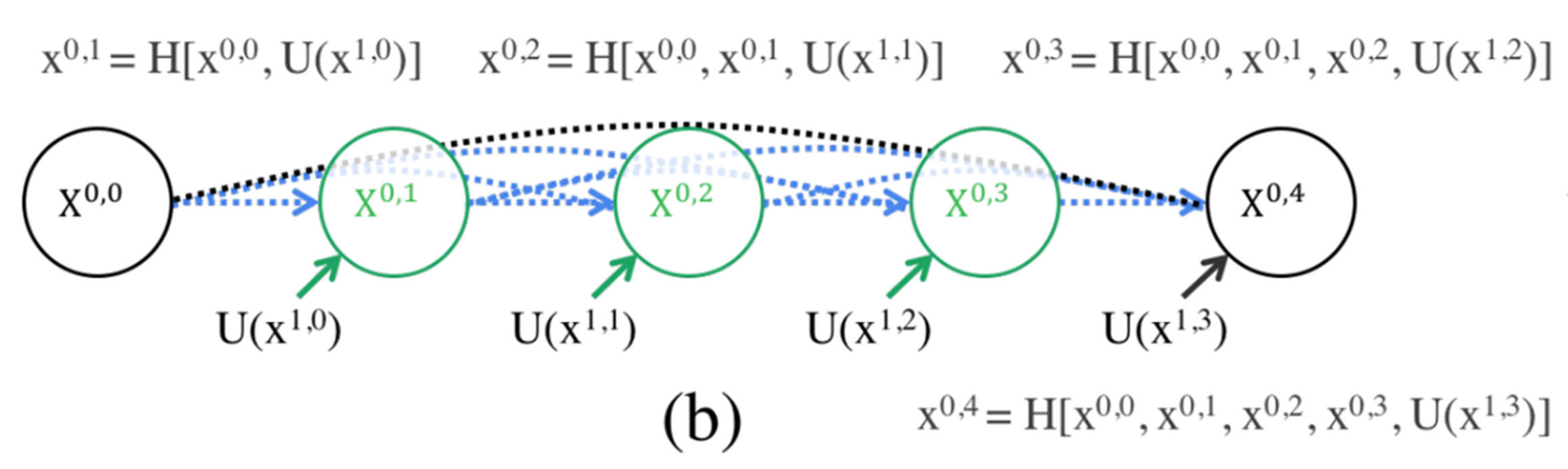
U-Net ++ 윗단을 다시 살펴보면, H가 Convolution이고 H(X0, 1)은 H(X0, 0)과 업 샘플링 된 U(X1, 0)이 합쳐지는 식으로 구성되어 있다.
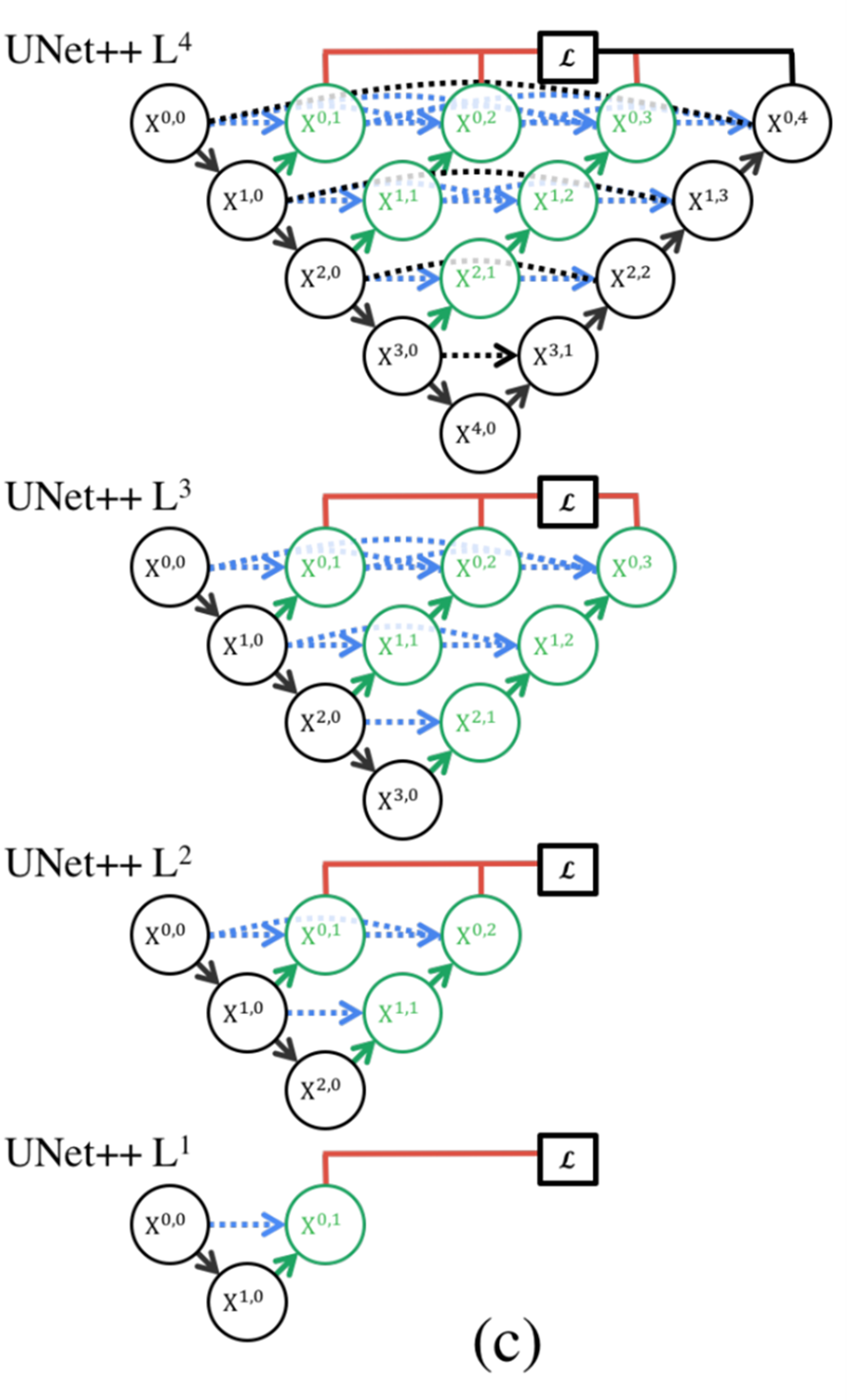
해당 논문에서는 이러한 아키텍처의 구성을 잘 살리기 위해서 Deep supervision이라고 하는 Loss를 추가를 한다. 래의 그림과 같이 제일 오른쪽 업 샘플링단을 없애더라도 결과가 도출이 될 수 있도록 각 끝단에 Loss를 추가를 했다.
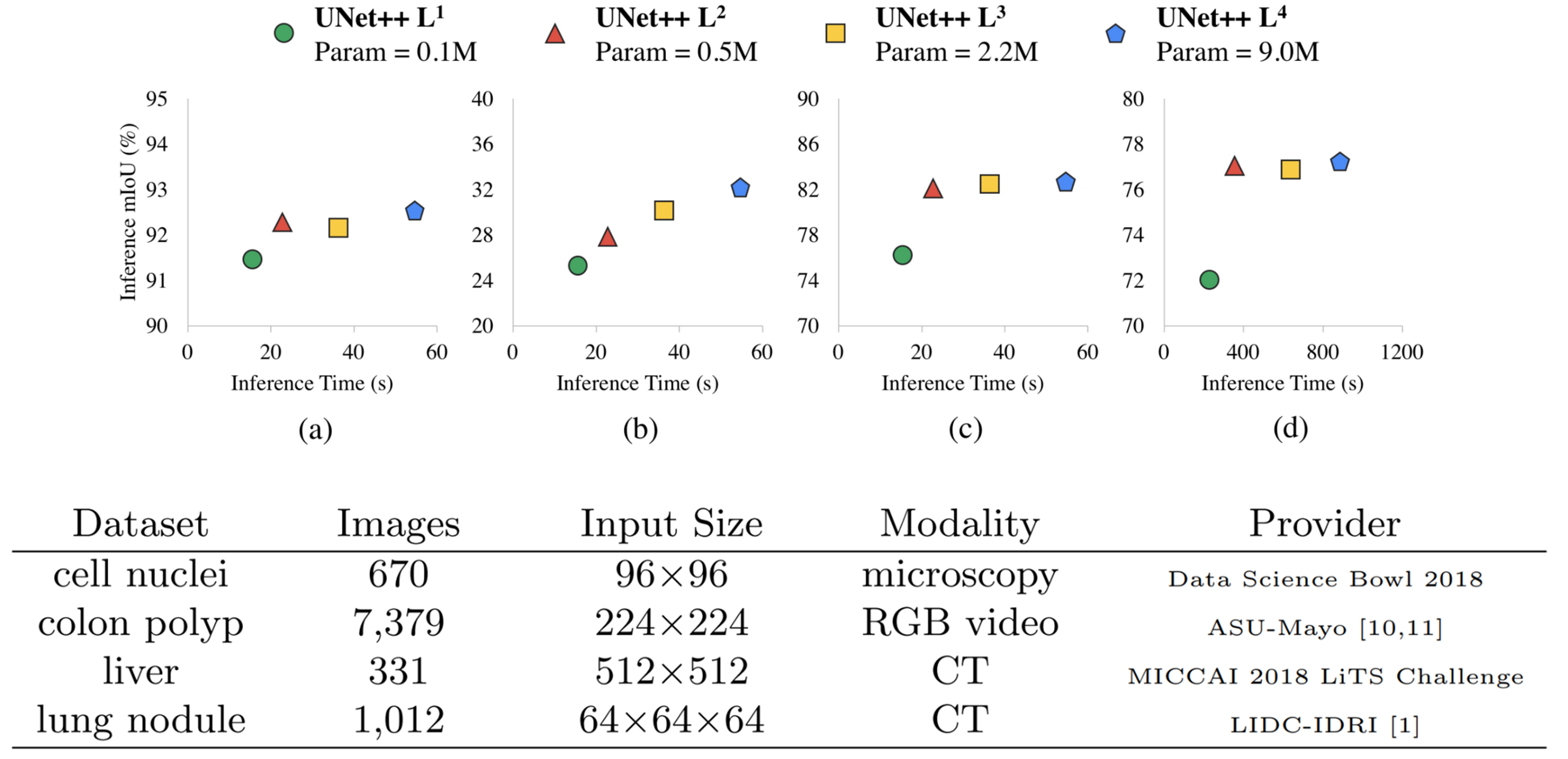
이렇게 Loss를 구현했을 때 장점이 Network pruning을 inference time에 할 수 있다는 것이다. 그래서 계산량이 많을 때나 적을 때, 즉 가용할 리소스가 많을 때나 적을 때나 예측을 수행할 수 있어야 한다는 것이다.
가용할 리소스가 적다면 일단 U-Net++L1에서 결과를 출력하고 그 다음으로 U-Net++L2에서 결과를 출력하는 식이다.
Loss Function은 binary classification을 수행한다. 메디컬 이미지의 대부분의 데이터셋은 대부분 Yes/No로 구분되어 있다.
Y는 label, Y hat은 모델 output을 말하고, 수식은 binary class에 대한 corss entropy식과 dice coefficient score(산술기하평균)의 합에 대한 N(이미지 수)를 가지고 Loss를 계산한다.
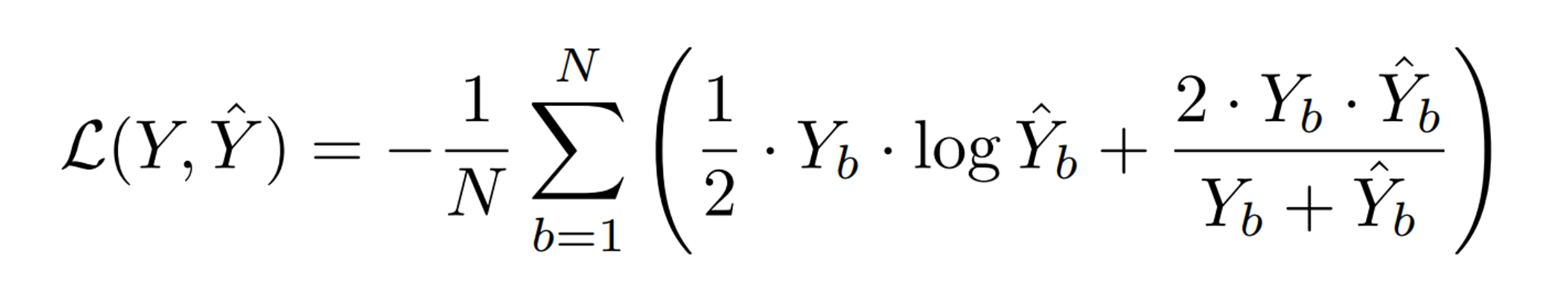
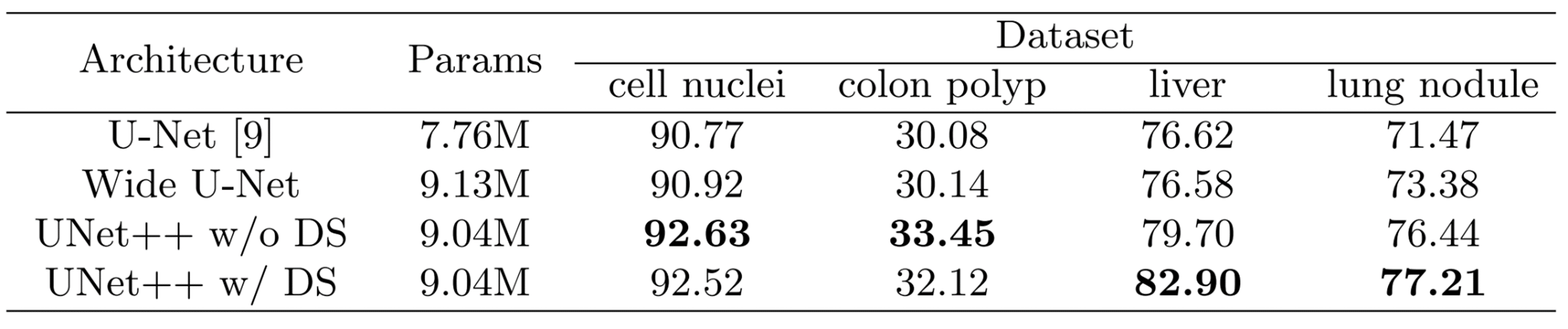
Results
Ground Truth에 대비하여 U-Net ++가 비교적 다른 비교군보다 성능적으로 좋아보이는 결과를 도출한다.

아래는 Segmentation 결과를 IoU로 것인데 좋은 성능을 이끌어낸다고 볼 수 있다.
하지만 DS(Deep Supervision)를 중간 단계에서 쓴 다는 것은, 최종 결과에서 뿐만 아니라 중간에서도 Loss를 계산한다는 것인데, 이것은 오히려 전체 Loss를 계산하는데 방해가 되는 부분임에도 불구하고 더 높은 결과가 도출 되는 것은 눈여겨 볼 만 하다.
아래는 Network pruning에 대한 결과다.
U-Net++ 아키텍처
참조 : GitHub
Model
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
class NestedUNet(nn.Module):
def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return outputLoss
class BCEDiceLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input, target):
bce = F.binary_cross_entropy_with_logits(input, target)
smooth = 1e-5
input = torch.sigmoid(input)
num = target.size(0)
input = input.view(num, -1)
target = target.view(num, -1)
intersection = (input * target)
dice = (2. * intersection.sum(1) + smooth) / (input.sum(1) + target.sum(1) + smooth)
dice = 1 - dice.sum() / num
return 0.5 * bce + dice