
문제 정의
회사들은 한정된 자원으로 효율적인 배분을 통한 운영을 해나간다.
적은 자원으로 최대의 효율을 낼수록 이익 증대와 더불어 다른 부분에 자원을 할당할 수 있는 기회를 얻을 수도 있다.
코로나 19로 보복소비 성향이 두드러지고 MZ세대가 소비층으로 부상하며 명품 플렛폼 시장이 커짐과 동시에 경쟁도 심화되고 있다.
고객의 소리라 할 수 있는 리뷰를 사람이 하나하나 들여다보는 것이 아닌,
리뷰를 분석하여 긍/부정과 카테고리별 분류 모델을 생성한다면 적은 자원으로 고객의 니즈를 파악할 수 있지 않을까?
데이터 확인
소스코드 및 데이터 : GitHub

각 앱스토어별/브랜드별로 데이터를 긍/부정과 카테고리를 부여하여 데이터를 병합하였다.
- 카테고리 10가지
CATE_TO_NUM = {
'배송':0,
'UX/UI 편의성':1,
'고객센터':2,
'상품 구색':3,
'앱 오류':4,
'가격&프로모션':5,
'상품 품질':6,
'정품 안전성':7,
'만족도&기타':8,
'상품 설명':9
}EDA & 시각화
별점
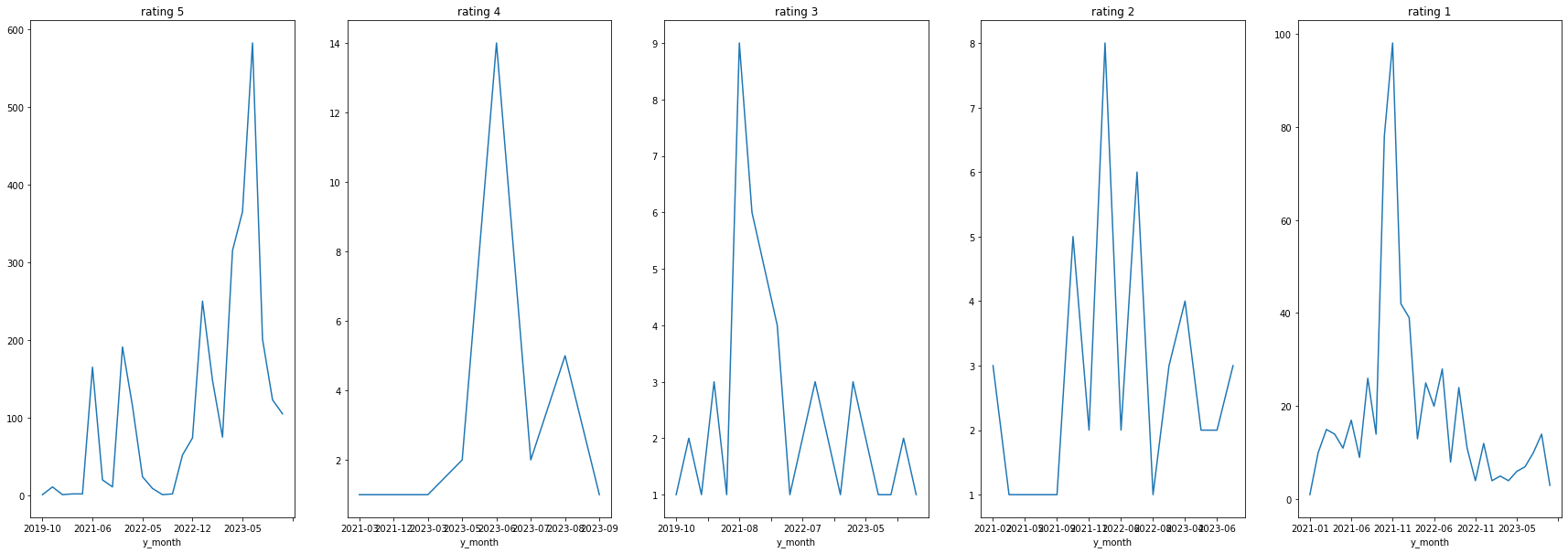
브렌드별 별점은 1점과 5점에 쏠려있는 것을 볼 수 있다.
발란
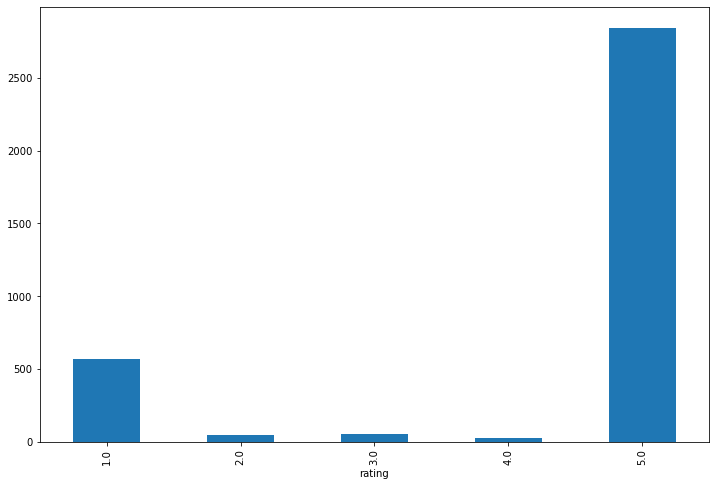
머스트잇
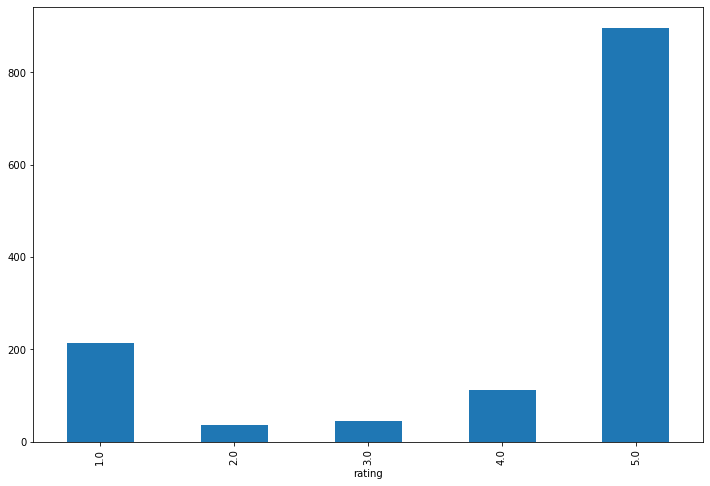
트랜비
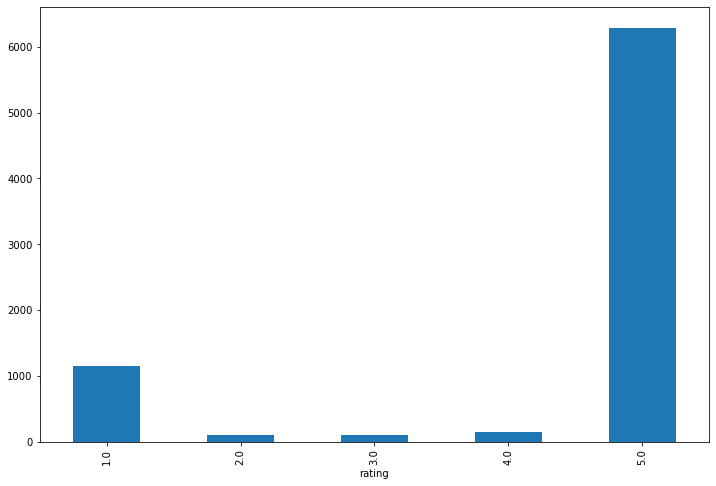
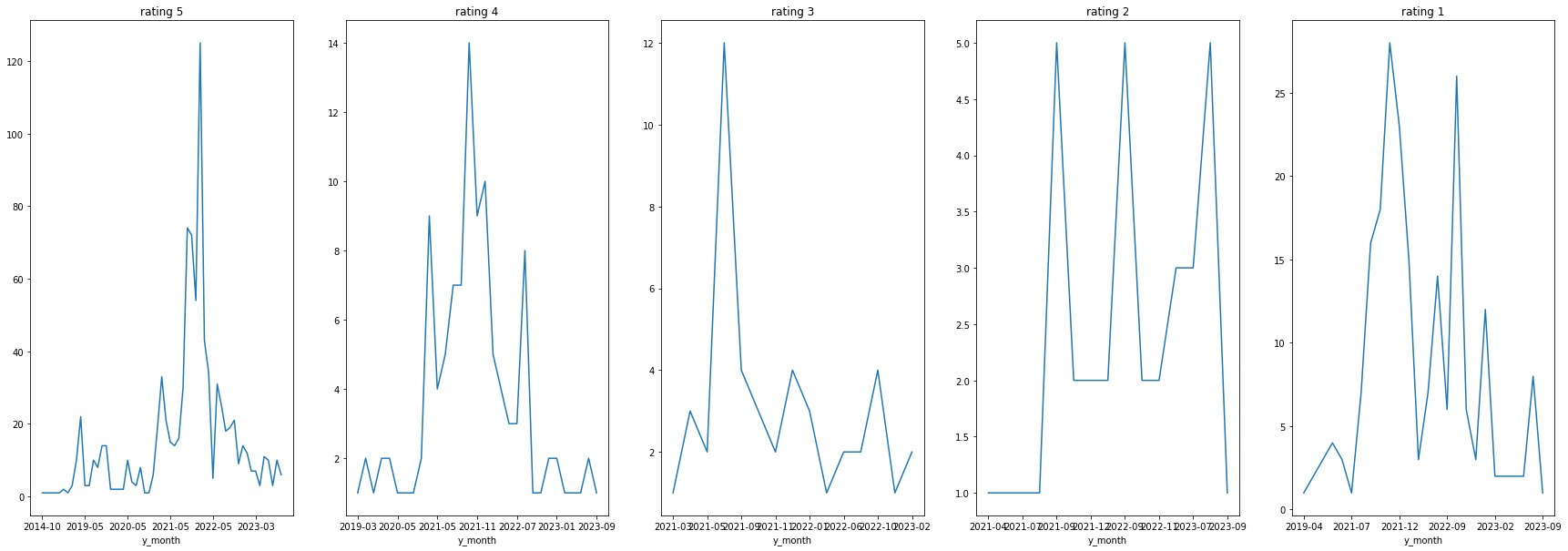
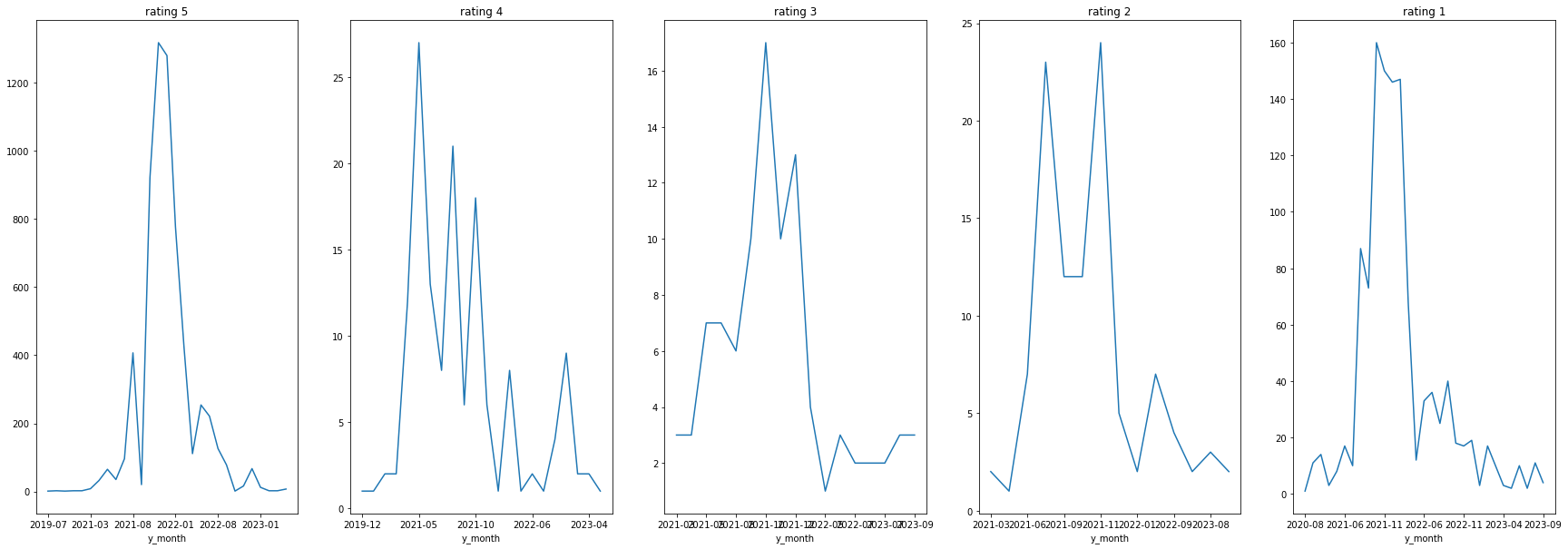
날짜별 브랜드 별점 추이
발란
머스트잇
트렌비
긍/부정
별점은 1점과 5점에 몰려있어서 별점1~2는 부정, 3점은 중간, 4~5점은 긍정으로 분류하였으나,
한 리뷰안에 긍/부정이 같이 섞여있는 부분이 있다. 그리고 별점은 5점인데 부정적인 내용이거나 별점은 3점인데 긍정적인 부분도 있어서 별점으로는 긍/부정을 나누기가 애매한 부분이 있다.
그래서 리뷰를 하나하나 살펴서 직접 긍/부정을 달아주고 카테고리도 직접 라벨을 달아주었다.
리뷰 안에 카테고리별 내용이 여러가지 섞여있으면 분리도 진행하였다.(ex. 배송이 너무 느려서 화가 났지만, 고객센터에서 대응 잘 해줘서 화가 풀렸네요 -> 배송이 너무 느려서 화가 났지만-배송/부정, 고객센터에서 대응 잘 해줘서 화가 풀렸네요-고객센터/긍정)
3사 전체의 리뷰 중 긍/부정 리뷰 차이를 보면 클래스 불균형이 보인다.
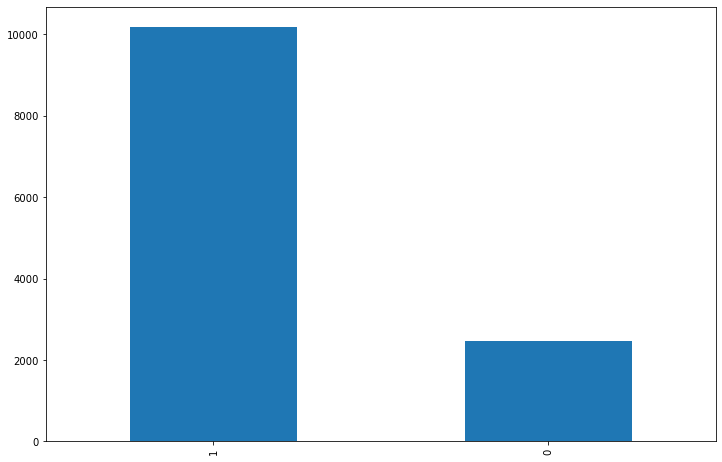
각 플렛폼별 리뷰 비율도 비슷할 것이라 예상은 된다.
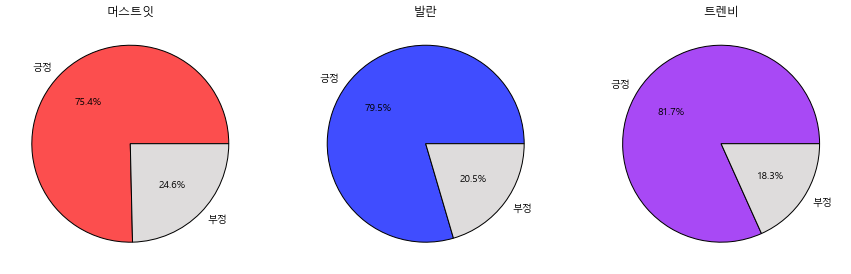
발란
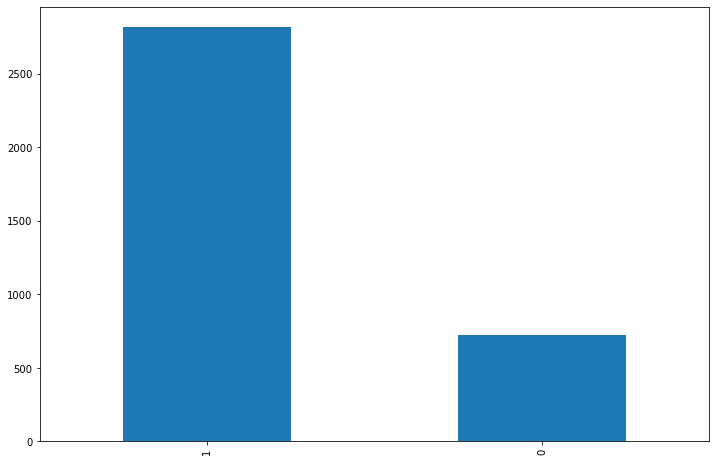
머스트잇
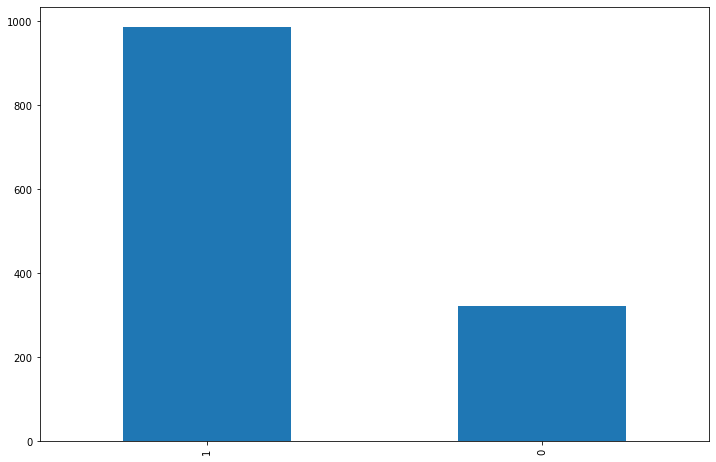
트렌비
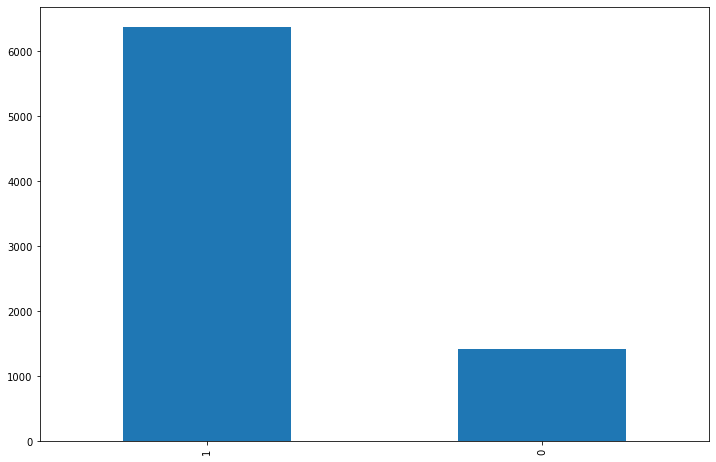
카테고리
리뷰의 카테고리별로 리뷰수를 나눠보면 아래와 같다.
리뷰의 카테고리를 보면 '굿, 좋아요, 싫어요' 등 짧은 리뷰 같은 '만족도&기타'가 제일 많고, 그 다음으로 '가격&프로모션', '편의성', '상품 구색', '정품 안전성', '배송' 순으로 되어 있다.
날짜별로나 긍/부정 그리고 카테고리별로 3사의 뚜렷한 특징의 차이점은 보이지 않는다.
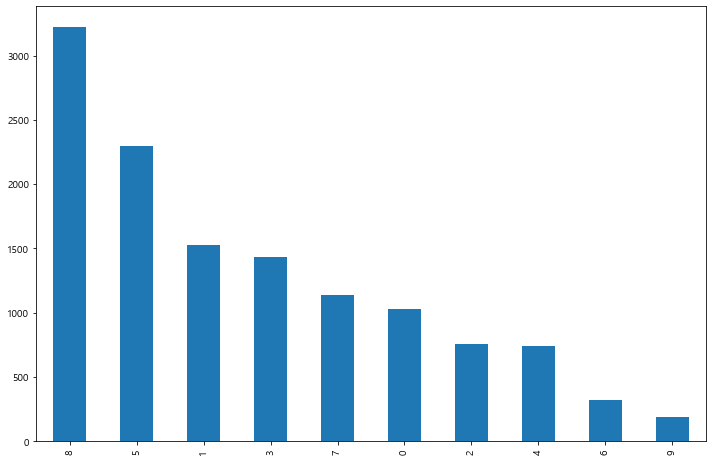
머스트잇이 다른 플렛폼에 비해서 '만족도&기타'부분에 쏠려있고 나머지는 비슷한 양상을 보인다.
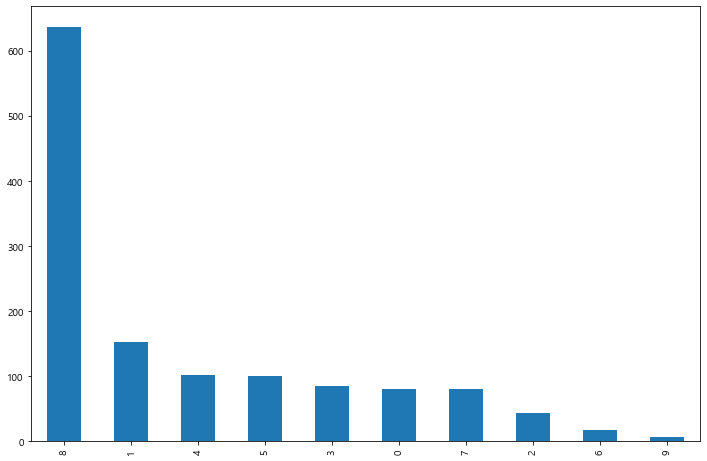
발란
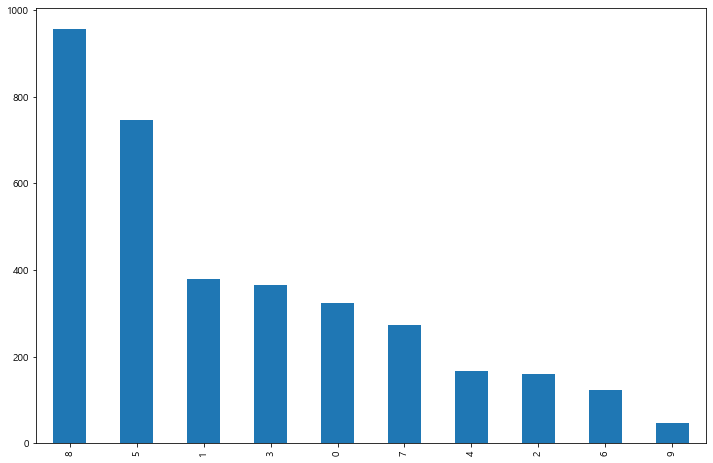
머스트잇
트렌비
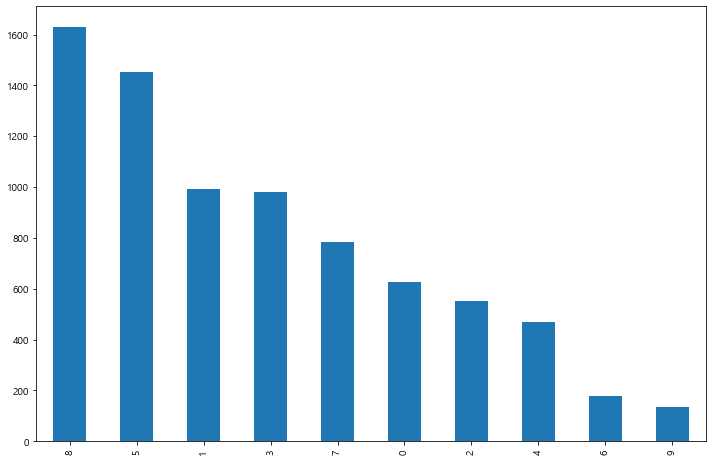
플렛폼별 긍/부정이나 카테고리로는 별 차이점이 보이지 않는다.
많이 등장하는 단어
from konlpy.tag import Okt
konlpy : 형태소 분석 라이브러리
okt = Okt()
- okt.nouns(리뷰) : 명사만 추출하여 가장 많이 등장한 단어 분석
플렛폼별로 긍/부정을 나누고, 긍정에서 많이 등장하는 단어와 부정에서 많이 등장하는 단어의 횟수를 살펴보도록 하자.
머스트잇
pos_reviews= data_mustit[data_mustit['label'] == 1]
neg_reviews= data_mustit[data_mustit['label'] == 0]
#-- 긍정 리뷰
pos_reviews['review'] = pos_reviews['review'].apply(lambda x: re.sub(r'[^ㄱ-ㅣ가-힝+]', ' ', x))
#-- 부정 리뷰
neg_reviews['review'] = neg_reviews['review'].apply(lambda x: re.sub(r'[^ㄱ-ㅣ가-힝+]', ' ', x))
pos_comment_nouns = []
for cmt in pos_reviews['review']:
pos_comment_nouns.extend(okt.nouns(cmt)) #-- 명사만 추출
#-- 추출된 명사 중에서 길이가 1보다 큰 단어만 추출
pos_comment_nouns2 = []
word = [w for w in pos_comment_nouns if len(w) > 1]
pos_comment_nouns2.extend(word)긍정 리뷰
#-- 긍정 리뷰 명사 추출
pos_comment_nouns = []
for cmt in pos_reviews['review']:
pos_comment_nouns.extend(okt.nouns(cmt))
pos_comment_nouns2 = []
word = [w for w in pos_comment_nouns if len(w) > 1]
pos_comment_nouns2.extend(word)
#-- 단어 빈도 계산
pos_word_count = Counter(pos_comment_nouns2)
# 제외할 단어 리스트
exclude_words = ['머스트잇', '머스트', '발란', '트렌비', '명품', '상품', '제품', '구매', '굿굿', '판매', '백화점', '진짜', '정말', '고민', '걱정', '최고', '사용', '다른', '자주', '마음', '플랫폼', '여기', '살수', '굿굿굿', '항상', '구입', '이용', '아주', '쇼핑', '물건', '만족', '어플', '사이트']
# Counter 객체 생성
pos_word_count = Counter(pos_comment_nouns2)
# 제외할 단어들을 반복문으로 확인하고 제거
for word in exclude_words:
if word in pos_word_count:
del pos_word_count[word]
#-- 빈도수가 많은 상위 50개 단어 추출
pos_top_50 = {}
max = 10
for word, counts in pos_word_count.most_common(max):
pos_top_50[word] = counts
print(f'{word} : {counts}')
#-- 그래프 작성
plt.figure(figsize=(10, 5))
plt.title('긍정 리뷰의 단어 상위 (%d개)' % max, fontsize=17)
plt.ylabel('단어의 빈도수')
plt.xticks(rotation=70)
for key, value in pos_top_50.items():
plt.bar(key, value, color='lightgrey')
plt.show()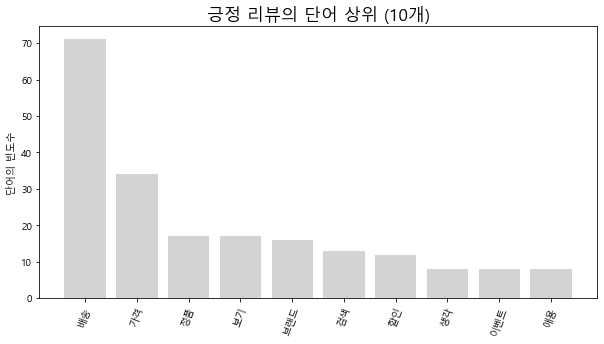
부정 리뷰
#-- 부정 리뷰 명사 추출
neg_comment_nouns = []
for cmt in neg_reviews['review']:
neg_comment_nouns.extend(okt.nouns(cmt))
neg_comment_nouns2 = []
word = [w for w in neg_comment_nouns if len(w) > 1]
neg_comment_nouns2.extend(word)
#-- 단어 빈도 계산
neg_word_count = Counter(neg_comment_nouns2)
# 제외할 단어 리스트
exclude_words = ['머스트잇', '머스트', '발란', '트렌비', '명품', '상품', '제품', '구매', '굿굿', '판매', '백화점', '진짜', '정말', '고민', '걱정', '최고', '사용', '이용', '아주', '쇼핑', '물건', '만족']
# Counter 객체 생성
neg_word_count = Counter(neg_comment_nouns2)
# 제외할 단어들을 반복문으로 확인하고 제거
for word in exclude_words:
if word in neg_word_count:
del neg_word_count[word]
#-- 빈도수가 많은 상위 50개 단어 추출
neg_top_50 = {}
for word, counts in neg_word_count.most_common(max):
neg_top_50[word] = counts
print(f'{word} : {counts}')
#-- 그래프 작성
plt.figure(figsize=(10, 5))
plt.title('부정 리뷰의 단어 상위 (%d개)' % max, fontsize=17)
plt.ylabel('단어의 빈도수')
plt.xticks(rotation=70)
for key, value in neg_top_50.items():
plt.bar(key, value, color='lightgrey')
plt.show()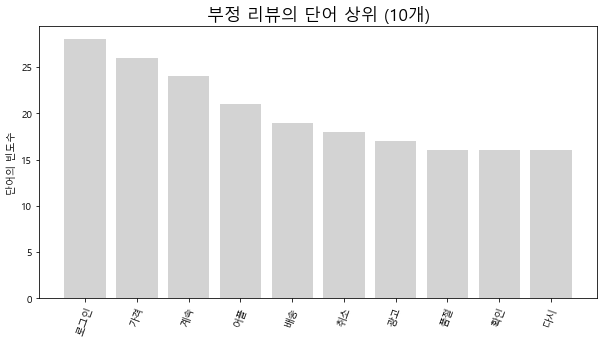
그리고 워드 클라우드로도 진행해보았다.
from wordcloud import WordCloud
from wordcloud import WordCloud
font_path = "C:/Windows/Fonts/malgun.ttf" # 폰트 저장 위치 : 윈도우라면 그대로 쓰면 된다.
#긍정에 대한
wc = WordCloud(font_path, background_color='white', colormap = 'OrRd', width=800, height=600)
cloud = wc.generate_from_frequencies(pos_word_count)
plt.figure(figsize=(12,12))
plt.title('긍정', fontsize=20)
plt.imshow(cloud)
plt.axis('off')
plt.show()
#부정에 대한
wc = WordCloud(font_path, background_color='ivory', width=800, height=600)
cloud = wc.generate_from_frequencies(neg_word_count)
plt.figure(figsize=(12,12))
plt.title('부정', fontsize=20)
plt.imshow(cloud)
plt.axis('off')
plt.show()
발란
위의 방법과 똑같이 진행하면 된다.
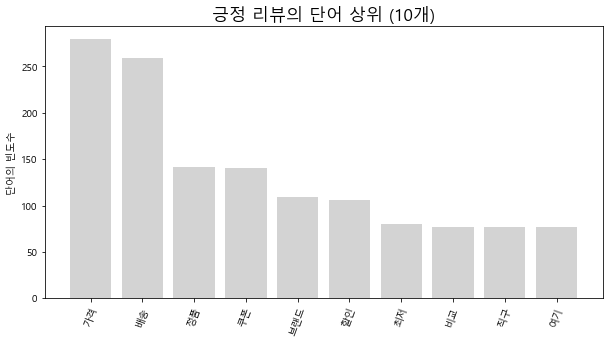
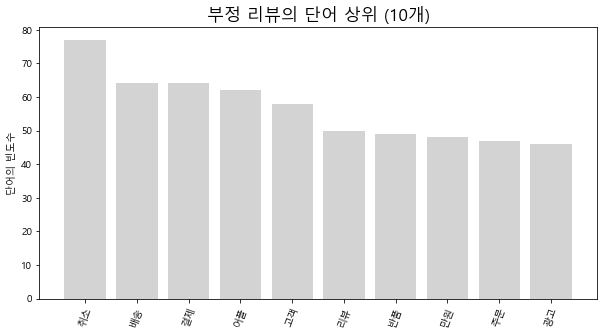
트렌비
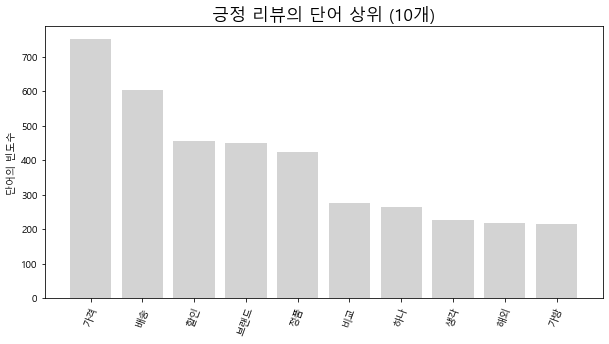
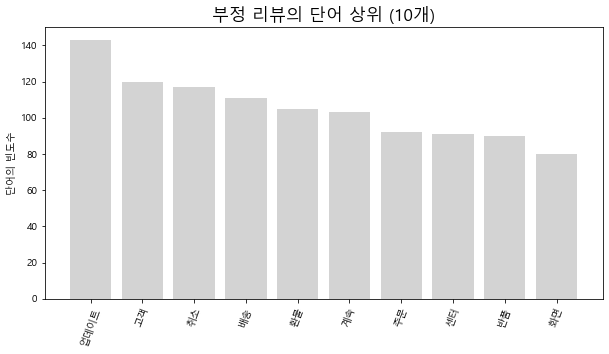
긍/부정의 각 플렛폼별 단어가 속하는 상위 5개 카테고리들은 다음과 같았다.

3사의 뚜렷한 차이점은 보이지 않는다.
리뷰의 양상이 비슷하다면 고객들의 니즈가 플렛폼별로 다른 것이 아닌, 같은 긍정과 부정의 감정을 느낀다는 것이라 볼 수 있다.
리뷰들을 긍/부정으로 카테고리별로 분류할 수 있는 모델을 만들어 보자.
하나하나 리뷰를 찾아 읽는 것이 아닌, 현재의 리뷰가 긍정이 많은지 부정이 많은지 그리고 부정이 많다면 어느 카테고리에서, 긍정이 많다면 어느 카테고리에서 발생하는지 확인할 수 있는 자동화까지 추가 한다면 적은 자원으로 고객의 니즈를 파악하는데 도움이 될 것이다.
또한 데이터가 쌓인다면 그 흐름과 변화에 민감하게 대응할 수 있을 것이다.
모델링
bert모델은 성능도 우수하다고 알려져있고 일반화가 잘 되어 있다고 한다.
그래서 클래스 불균형을 어느 정도 해소할 것이라 생각했고, 전이 학습도 용이하기에 bert 모델을 선택하였고, 한국어의 불규칙한 언어 변화의 특성을 반영하기 위해 데이터 기반 토큰화 기법이 적용된 SKT에서 공개한 KoBert 모델을 가지고 진행한다.
Kobert 모델과 transformers를 다운받고 진행해야 한다.
!pip install transformers
!pip install transformers[sentencepiece]
!pip install datasets
!pip install gluonnlp
!pip install mxnet
!pip install 'git+https://github.com/SKTBrain/KoBERT.git#egg=kobert_tokenizer&subdirectory=kobert_hf'긍/부정을 반환하는 동시에 카테고리도 같이 반환하는 모델을 사용하려 했으나 용이하지 않아서,
긍/부정 분류 모델 하나와 카테고리 분류 모델을 따로 학습시키고 출력을 같이 하도록 모델링하였다.
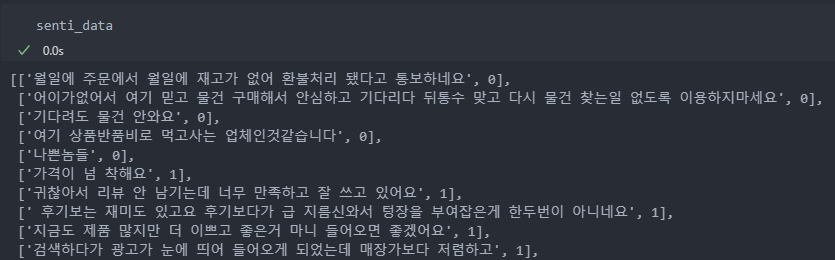
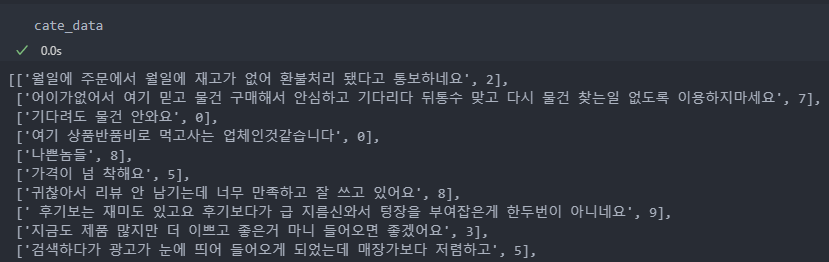
입력 데이터의 형식은 리뷰와 라벨을 리스트로 입력을 한다.
긍/부정 입력 데이터
카테고리 입력 데이터
from konlpy.tag import Mecab
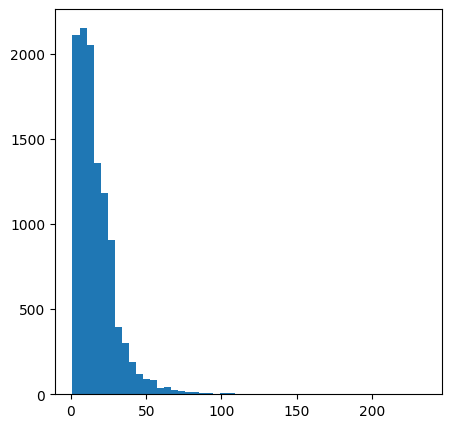
- max length 확인하기 위해 사용
리뷰의 길이가 대부분 30단어 안으로 이루어져 있다.
최대한 모든 리뷰를 삭제 없이 넣기 위해 128로 진행하였다.
128보다 긴 리뷰는 128까지만 사용되고 나머지는 버린다.
학습
먼저 필요한 tokenizer, bertmodel, vocab, tok를 정의한다.
tokenizer = KoBERTTokenizer.from_pretrained('skt/kobert-base-v1')
bertmodel = BertModel.from_pretrained('skt/kobert-base-v1', return_dict=False)
vocab = nlp.vocab.BERTVocab.from_sentencepiece(tokenizer.vocab_file, padding_token='[PAD]')
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower = False)1. 긍/부정
데이터를 학습/평가 데이터로 나누고,
# 긍/부정
num_classes = 2
senti_dataset_train, senti_dataset_test = train_test_split(senti_data, test_size = 0.2, shuffle = True, random_state = 29)하이퍼 파라미터 튜닝을 진행한다.
patience = 5
max_len = 128
batch_size = 100
warmup_ratio = 0.1
num_epochs = 30
max_grad_norm = 1
log_interval = 200
learning_rate = 0.0001
dr_rate = 0.5
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device그리고 튜닝한 옵션들을 모델에 적용시킨 후,
tok = tokenizer.tokenize
senti_data_train = BERTDataset(senti_dataset_train, 0, 1, tok, vocab, max_len, True, False)
senti_data_test = BERTDataset(senti_dataset_test, 0, 1, tok, vocab, max_len, True, False)설정한 batch_size 만큼 DataLoader로 데이터셋을 만든다.
senti_train_dataloader = torch.utils.data.DataLoader(senti_data_train, batch_size = batch_size, num_workers = 5)
senti_test_dataloader = torch.utils.data.DataLoader(senti_data_test, batch_size = batch_size, num_workers = 5)마지막으로 optimizer, loss_fn 등을 설정하고
model = BERTClassifier(bertmodel, num_classes=num_classes, dr_rate=dr_rate).to(device)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr = learning_rate)
loss_fn = nn.CrossEntropyLoss()
t_total = len(senti_train_dataloader) * num_epochs
warmup_step = int(t_total * warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps = warmup_step, num_training_steps = t_total)학습을 진행한다.
train_accuracies = []
train_losses = []
val_accuracies = []
val_losses = []
for epoch in range(num_epochs):
train_acc = 0.0
val_acc = 0.0
model.train()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm(senti_train_dataloader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
t_acc = (train_acc / (batch_id+1))
print(f'Epoch: {epoch}/{num_epochs}\t| Train Acc: {t_acc:.4f}\t| Train Loss: {loss.item():.4f}')
model.eval()
with torch.no_grad():
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm(senti_test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
val_loss = loss_fn(out, label)
val_acc += calc_accuracy(out, label)
v_acc = (val_acc / (batch_id+1))
print(f'Epoch: {epoch}/{num_epochs}\t| Val Acc: {v_acc:.4f}\t| Val Loss: {val_loss.item():.4f}')
train_accuracies.append(t_acc)
train_losses.append(loss.item())
val_accuracies.append(v_acc)
val_losses.append(val_loss.item())
print(f'EPOCHS: {epoch+1}/{num_epochs}\t| train acc: {t_acc}\t| train loss: {loss.item()}\t| val acc: {v_acc}\t| val loss: {val_loss.item()}')
# epoch 당 save
if (epoch+1) % 5 == 0:
save_model(model.state_dict(), f'senti_model_{epoch+1}.pth')
save_model(model.state_dict(), f'e20_b50_d05_lr0001_senti_model_{epoch+1}.pth')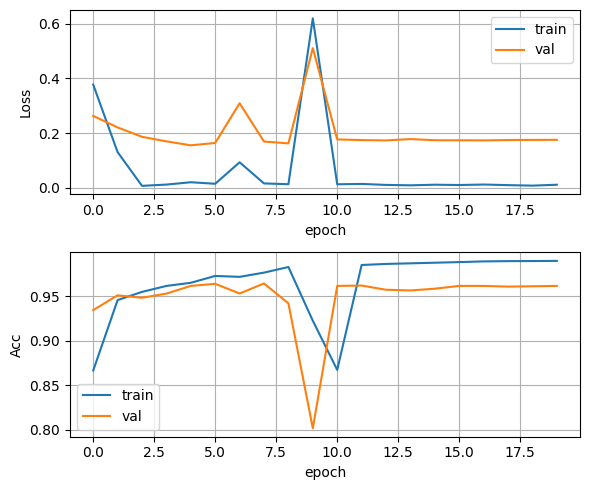
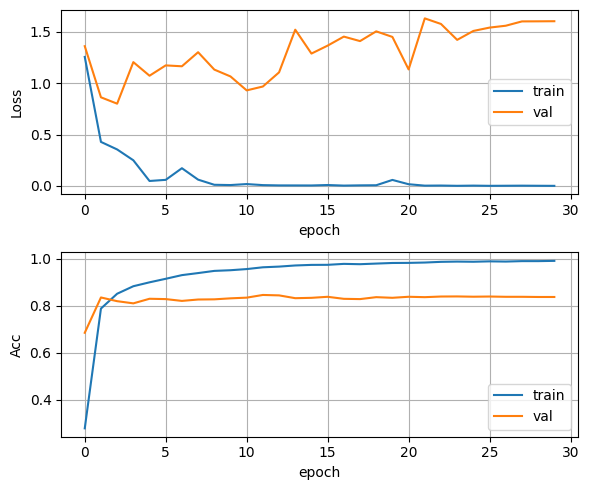
2. 카테고리
카테고리 학습도 긍/부정과 거의 똑같고 class만 10개로 늘어날 뿐이다.
3. 하이퍼 파라미터
파라미터는 크게 max length, batch size, learning rate, drop rate 정도다.
-
batch size
코렙으로 학습을 진행하였는데,
batch size가 130을 넘어가면 메모리 부족으로 코렙이 터져서 30~120 사이로 학습을 진행하였다. -
learning rate
0.0001보다 크면 학습 진행이 되지 않는다.
0.0001보다 작게하여 진행하였으나 유의미한 차이는 없다. -
drop rate
0.45 이하로 진행을 하면 valid에서 과적합 현상이 보인다.
4. 클래스 불균형
-
긍/부정
긍정의 비율이 많아서, '굿, 굳, 좋아, 좋아여, 별로'등 짧거나 반복적으로 나오는 리뷰들을 삭제를 시켰으나,
유의미한 변화를 보이지는 않았다. -
카테고리
카테고리를 통합하여 10 -> 8개로 축소시켜 다시 진행하였으나,
긍/부정과 같이 유의미한 변화를 보이지 않고 때로는 오히려 정확도는 떨어지고 Loss가 오르는 결과도 나왔다.
그래서 처음처럼 10개로 진행하였다.
클래스가 불균형하고 불균형한 데이터의 숫자가 적더라도 학습이 잘 진행이 되었다.
딥러닝으로 nlp는 처음 접하는 것이라, 결과가 생각보다 잘 나와서 놀랐다.
그리고 테스트로 직접 결과물을 확인했는데 실제적인 결과물도 잘 나왔다.
기대효과
분류한 것에서 끝나지 않고 매일의 리뷰를 분류해 놓는다면,
리뷰들의 흐름이 긍정이 많아지는지 부정이 많아지는지 빠르게 파악할 수 있을 것 같다.
카테고리들에 대한 리뷰들도 긍정에서 어느 카테고리에서 긍정이 달리는지 보고 추가적인 조치로 서비스를 강화할 수 있고
부정이 달린다면 빠르게 해소하여 불만을 제거하는데 초점을 둘 수도 있다.
또한 매일의 자료들이 데시보드화 하거나 쌓인다면 그 흐름들을 보고 추세를 짐작하여 빠른 대응에 나설 수도 있을 것이다.

https://velog.io/@hsty94/%EC%9D%B4%EC%BB%A4%EB%A8%B8%EC%8A%A4NLPDL-%EB%AA%85%ED%92%88-%EC%BB%A4%EB%A8%B8%EC%8A%A4%EC%9D%98-VoC-%EB%B6%84%EC%84%9D%EA%B3%BC-%EB%B6%84%EB%A5%98-%EB%AA%A8%EB%8D%B8-%EA%B0%9C%EB%B0%9C
해당 블로그와 내용이 너무 유사하여 혹시 몰라 확인해보셔야 할 것 같아 댓글 남깁니다!