1. 서론
지난 포스팅 이후로 실험은 모두 끝내놨지만 조금의 휴식 기간을 보낸다고 늦어진 기록
혐오 표현 탐지 프로젝트에서 해보고자 했던 실험은 모두 끝내놔서 이번 포스팅 이후로 새로운 아이디어가 떠오를 때까지는 잠깐 홀드할 것 같다.
이번 시간에는 기존의 데이터 증강 방식을 통해서 오버 샘플링을 적용해보는 실험과 Unlabeled 데이터를 활용한 모델의 성능 비교에 대한 내용을 정리해보았다. 또한, 데이터 증강을 적용할 때 마스킹할 토큰을 랜덤이 아닌 어텐션을 이용하여 선택하는 방식을 고민해보았다.
2. 오버 샘플링
실험 환경
- 이전 실험에서는 labeled data 전체에 데이터 증강을 적용했기 때문에 증강 전과 후 모두 레이블 비율이 불균형했다.
- 이 실험에서는 현재 더 적은 양만이 존재하는 clean 데이터에만 증강을 적용하여 clean과 bad 레이블의 비율이 유사하도록 데이터를 변경하여 실험을 진행해보았다. 오버 샘플링을 적용한 데이터의 비율은 아래와 같다.
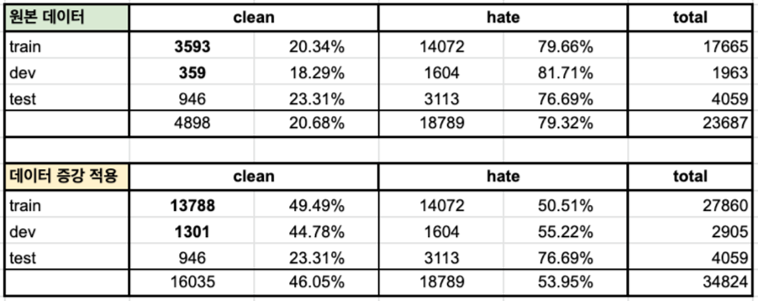
- 각 모델의 loss function은 모두 cross entropy로 설정하였다.
실험 결과
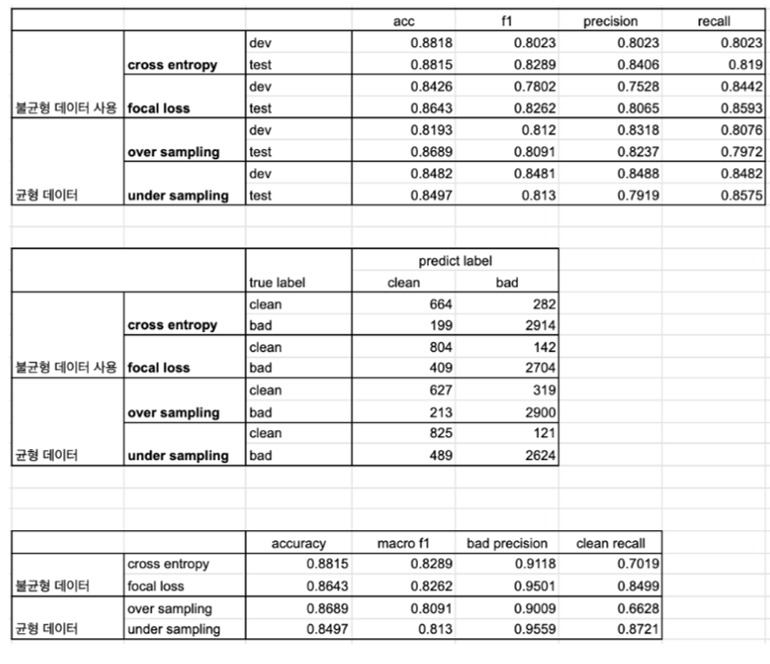
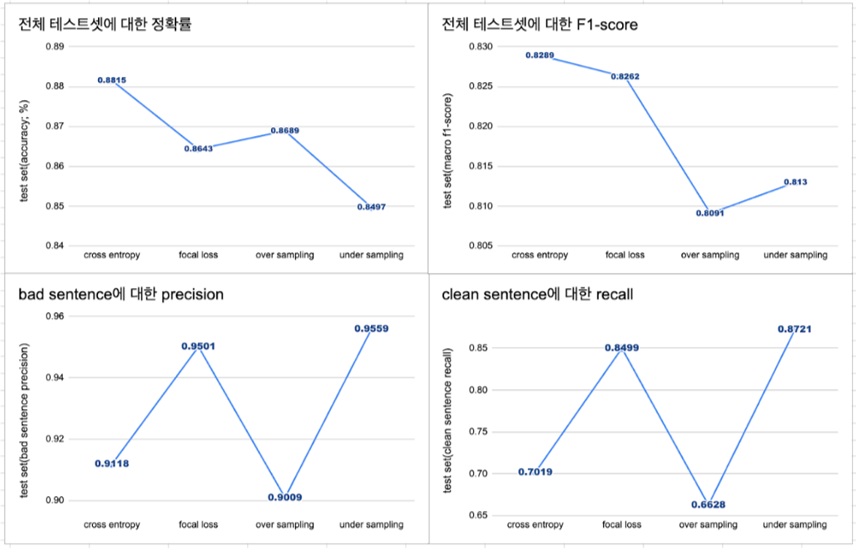
- 성능 비교 결과 focal loss도 사용하지 않고, 불균형 데이터에 그대로 cross entropy를 적용하여 학습한 모델보다도 조건(bad에 대한 precision, clean에 대한 recall이 높아야한다.)에 적합하지 않았다.
- 이러한 결과를 통해 한 가지 가설을 세워보았다.
가설 : 균형 데이터를 사용하는 것보다 데이터의 퀄리티가 더 중요하다(정확한 레이블링)
→ 가설 검증을 위해서는 퀄리티 좋은 데이터를 생성할 방법이 필요
3. Unlabeled data 활용
지난 실험 포스팅인 7. 증강 데이터 활용하기에서 가장 조건에 잘 맞았던 1:2 모델을 mixtext의 사전 모델(step1-model)로 활용하여 semi-supervised learning 방법론을 적용해보았다.
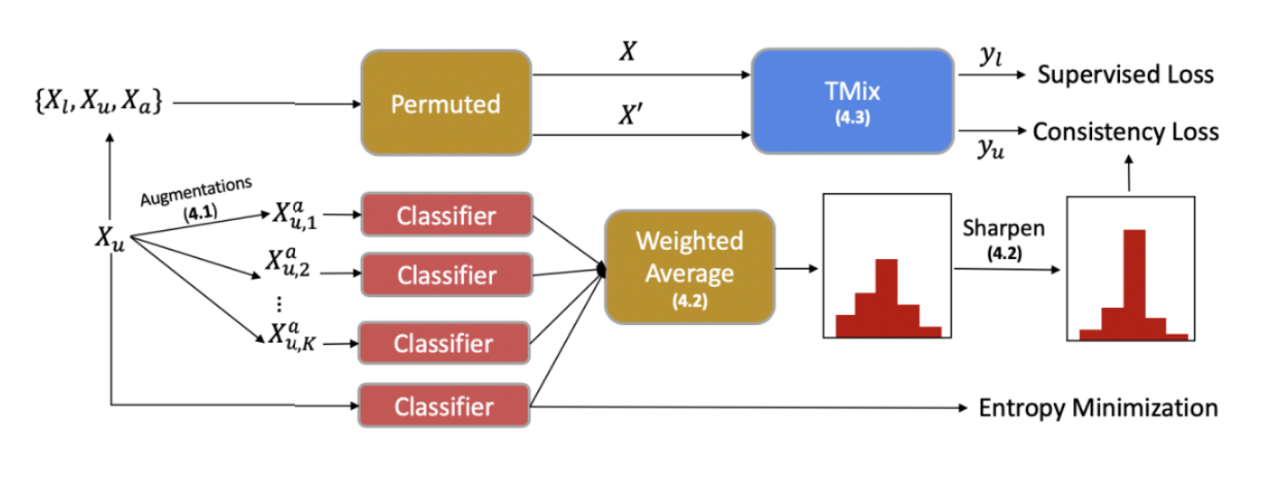
- 논문에서의 Augmentation 부분에서 역번역(back translation)을 활용하는데 이를 대신하여 MLM을 활용한 데이터 증강 방식을 적용했다.
✔️ unlabeled data 비율에 따른 모델 성능
실험 조건
- 모델의 학습 코드 구조 상 labeled data와 unlabeled data의 배치의 개수를 동일하게 유지해야함.
- 현재의 실험 환경에서는 labeled data에 대한 배치 사이즈를 줄이지 않고, 최대 10만개의 unlabeled data만을 활용할 수 있다.
- labeled data의 batch_size = 32
- DataParallel로 Multi-GPU 학습 중(Distributed과 deepspeed 사용하지 않음)
실험 결과
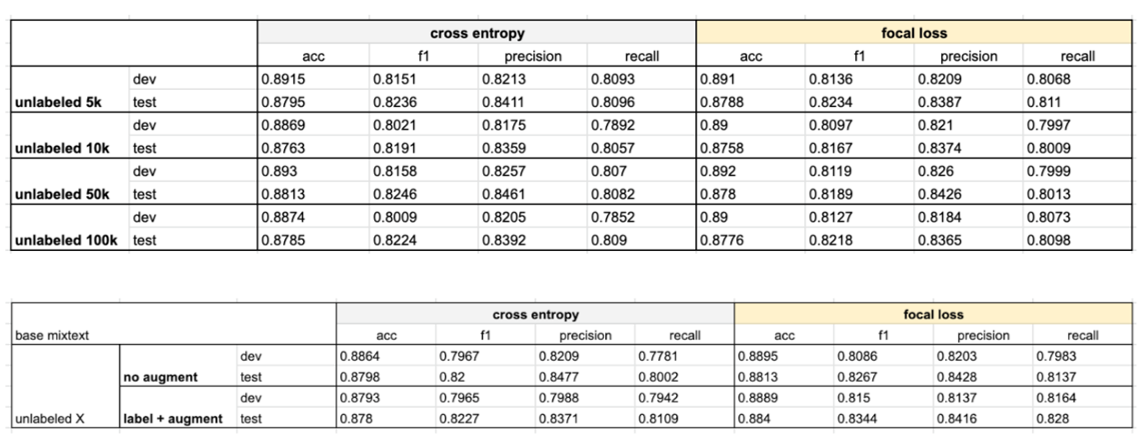
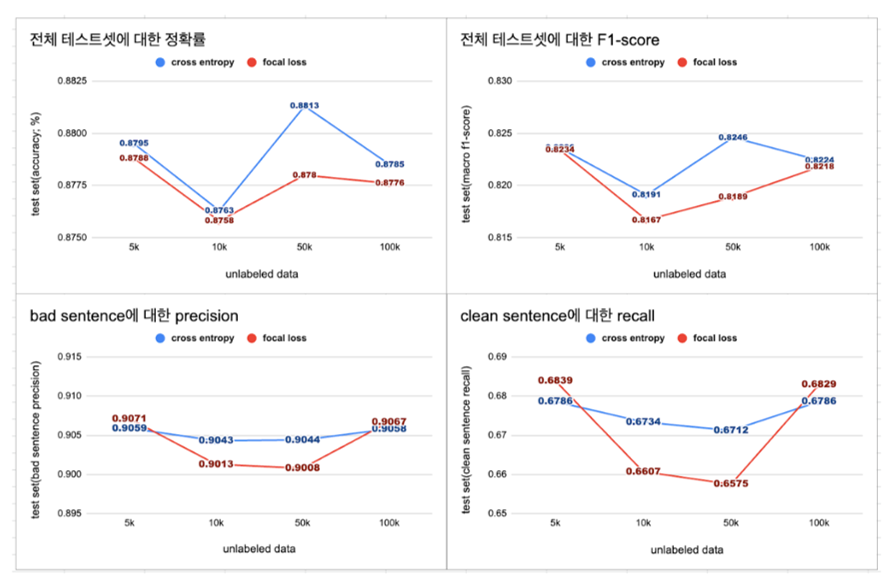
- 최대 100k개의 unlabeled data를 추가했을 때, f1-score가 0.8246으로 가장 높음. 하지만 이는 labeled data와 labeled data의 증강 버전을 학습한 모델에 비하면 떨어지는 수치(0.8344)
실험 결과에 대한 생각
- 데이터의 양을 늘린다면 모델의 성능이 좋아질 것이라고 생각하여 unlabeled data를 활용해보았지만, 오히려 성능이 떨어지는 모습을 보였다.
- 성능 향상을 보이지 않았던 이유를 분석하기 위해서 다시 논문을 살펴본 결과, 논문에서는 labeled data를 매우 적은 양만을 활용하여 실험을 했다는 것을 발견.
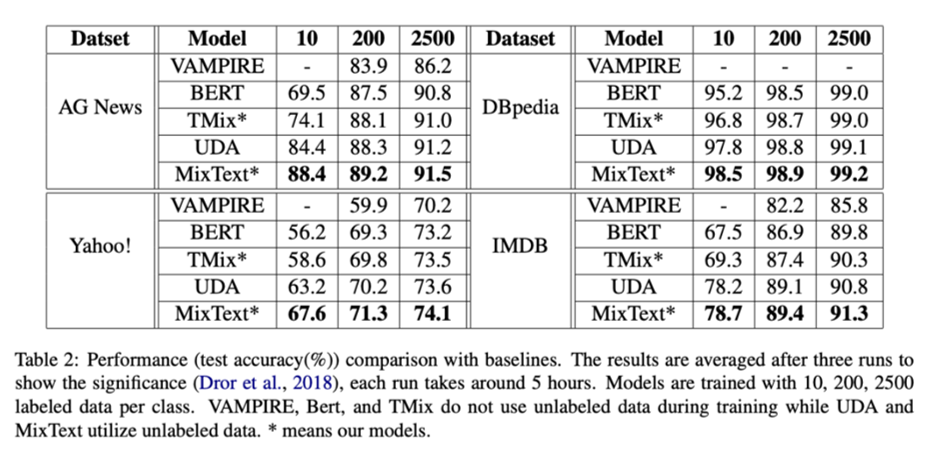
- 위 표에서는 labeled data를 각 레이블 별로 10, 200, 2500개만을 활용. 현재 hate speech detection에서는 문장에 대한 레이블을 2개(clean, bad)로만 나누고 있기 때문에 총 데이터를 20, 400, 5000개를 활용했다는 것과 같다.
- IMDB 데이터가 긍정/부정의 2개의 레이블만 가지고 있기 때문에 현재의 태스크와 가장 비슷한 성질을 가졌다고 생각되는데, 레이블 데이터를 추가할수록 기본 BERT의 성능과 MixText의 성능 차이가 크지 않았다.(아래의 가장 오른쪽 차트 참고)
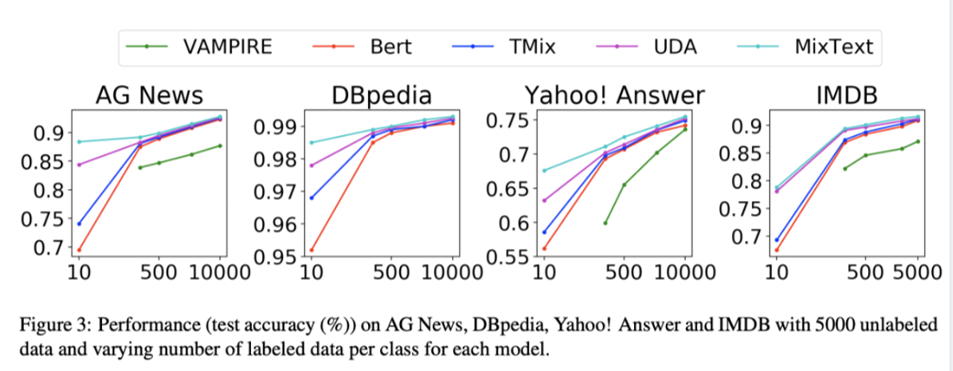 → 현 실험에서는 약 18,000개의 문장을 학습에 사용했기 때문에 unlabeled data 없이도 충분한 패턴 학습이 가능했던 것이 아닌가라고 추측.
→ 현 실험에서는 약 18,000개의 문장을 학습에 사용했기 때문에 unlabeled data 없이도 충분한 패턴 학습이 가능했던 것이 아닌가라고 추측.
- 위 표에서는 labeled data를 각 레이블 별로 10, 200, 2500개만을 활용. 현재 hate speech detection에서는 문장에 대한 레이블을 2개(clean, bad)로만 나누고 있기 때문에 총 데이터를 20, 400, 5000개를 활용했다는 것과 같다.
4. Attention 활용하기
 [출처 : 넥슨 인텔리전스랩 딥러닝으로 욕설 탐지하기]
[출처 : 넥슨 인텔리전스랩 딥러닝으로 욕설 탐지하기]
-
넥슨 인텔리전스랩에서는 욕설 필터링을 위해서 attention mechanism을 활용했다고 한다. attention이 높은 쪽이 혐오 표현 탐지에 더 많은 영향을 준 토큰이기 때문에 욕설/혐오 표현일 가능성이 높은 토큰이 된다.
→ 이 부분을 활용하여 문장 내의 혐오 표현을 뜻하는 토큰을 찾아서 이 부분을 중심으로 마스킹하여 생성한 문장과 이 부분을 제외하고 마스킹한 문장의 퀄리티 비교를 하고자 함.
실험 환경
KcELECTRA + self-attention layer
- 기존에는 넥슨 인텔리전스랩의 모델 구조를 따라서 VDCNN + attention 구조를 활용하고자 했었지만, 이 경우에는 word2vec 모델을 추가로 학습을 하거나 음절/자소 단위로 임베딩을 해야 하기 때문에 추후에 데이터 증강에 활용하게 된다면 추가적인 토큰 단위 매칭이 필요하여 사용하지 않았음.
- ex) 개소리
- 자소 단위 :
ㄱ, ㅐ, ㅅ, ㅗ, ㄹ, ㅣ- 음절 단위 :
개, 소, 리 - KcELECTRA 토크나이저 단위 :
개소리
- 음절 단위 :
- 자소 단위 :
- 위 넥슨 인텔리전스랩의 발표자료처럼 "개"가 attention이 높을 경우에 마스킹을
개소리전체에 적용을 할 것인지,개 + 소리로 나누어서[MASK] + 소리로 적용할 것인가 등의 추가적인 고민/연구가 필요
- ex) 개소리
모델 성능
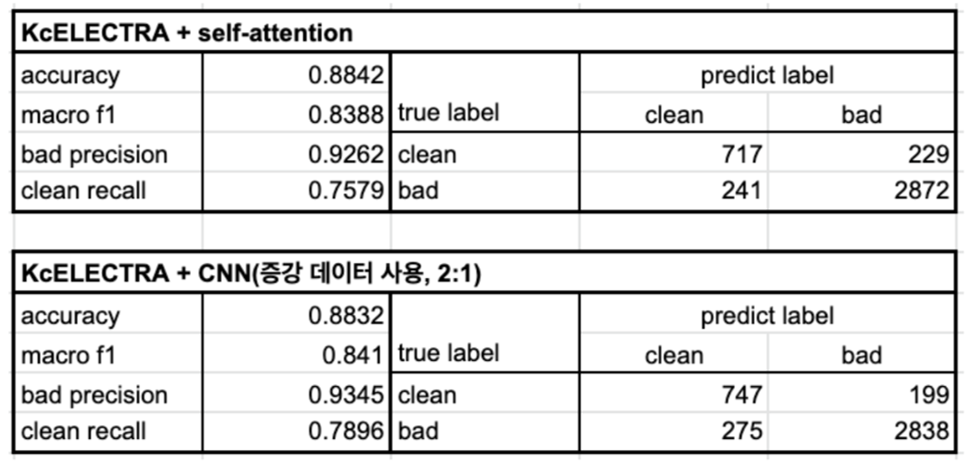
- 기존에 실험 내용 중 가장 적합하다고 생각한 모델에 비해서는 약간 성능이 떨어지지만, 유사한 수준의 성능을 보였음.
✔️ attention 시각화
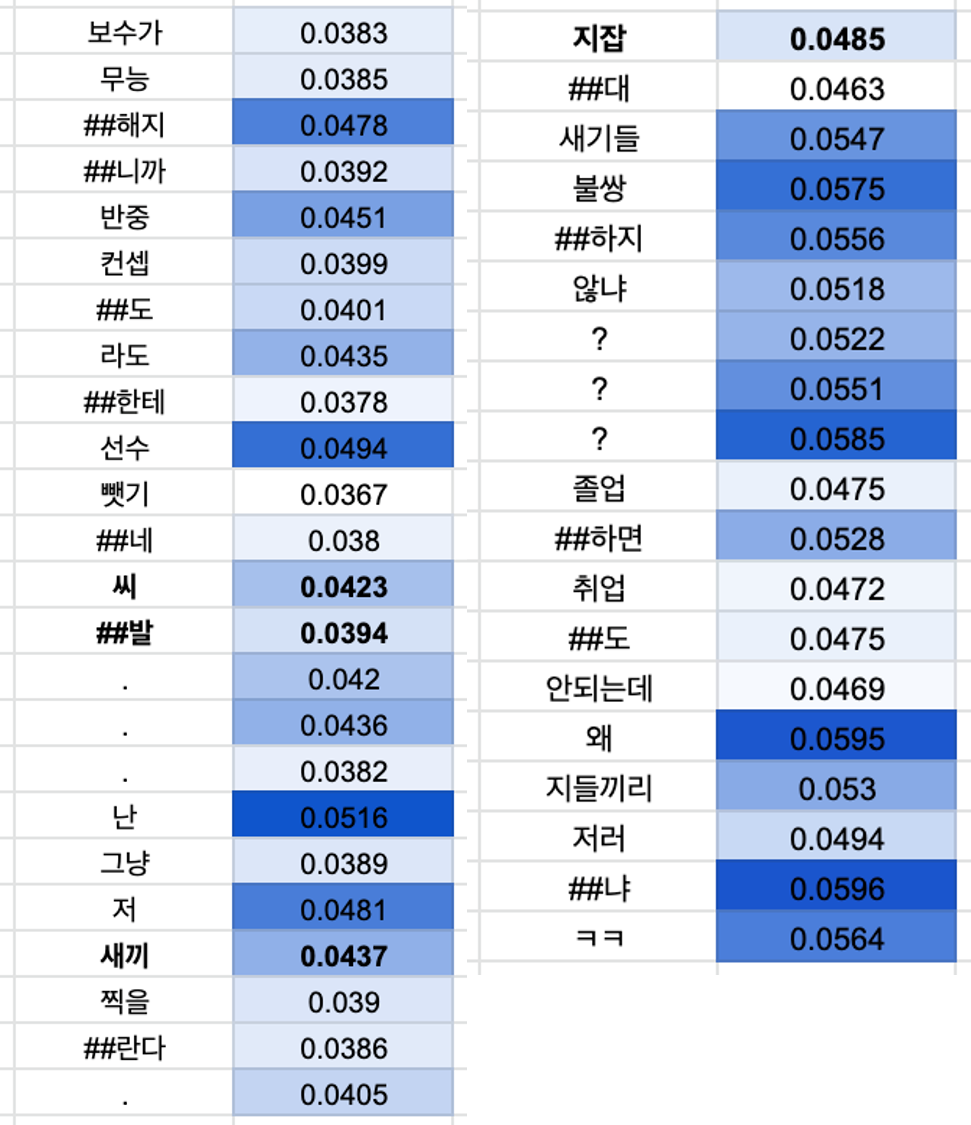
- 실질적인 욕설과 비하의 의미가 포함된 토큰에 대한 attention이 높지 않았음.
5. 마무리
- attention 시각화 이후에 수작업으로 욕설과 비하의 의미가 포함된 토큰에 마스킹을 적용하고 데이터 증강을 적용해보았지만, 랜덤으로 마스킹 했을 때와 큰 차이가 없었다.
→ 마스킹하는 위치보다는 MLM의 성능이나 후보에 대한 필터링이 더 중요한 것으로 예측된다.
- unlabeled data를 활용해보았지만 성능 향상에 도움이 되지 않았다. 이를 현실에서 활용하기 위해서는 unlabeled data를 태깅하는 작업을 효율화하는 것이 더 좋을 것으로 보인다.

ML Engineer @Wrtn Technologies Inc.