Abstract
기본의 자율주행 시스템의 경우 도로의 상황, 라인 마킹 등 여러가지의 단계로 구분되어 학습되어야 했습니다. 하지만 해당 논문에서는 운전자의 Steering angle 정보만을 활용하여 End-to-End 자율주행 시스템을 개발했다고 주장하고 있습니다. 또한 특징을 명시적으로 훈련하지 않고, 학습에 유요한 특징을 모델이 직접 감지하도록 하여 다양한 환경에서 보다 안정적으로 작동한다고 주장하고 있습니다.
1. Introduction
CNN나오면서 2차원 이미지를 인식하는데 다양한 연구가 진행되었습니다. 또한 ILSVRC 대회 활성화, GPU의 발전으로 더 다양한 분야에서 CNN이 활용되고 있습니다. 해당 연구에서는 단순히 전체 이미지를 인식하는 CNN이 아니라 자동차 조향에 필요한 전체 처리 파이프라인 자체를 학습하는 CNN을 제시합니다. 이러한 실험은 이전에 DAVE 프로젝트와 유사하게 설계되었습니다. 또한 ALVINN 시스템의 경우 CNN을 사용함으로 써 이미지의 2차원 구조를 효과적으로 포착할 수 있으며, 실제로 도로에서 자율주행 수행이 가능함을 입증하였습니다. 하지만 이러한 방법들의 경우 Off-Road 환경에서는 좋지 못한 성능을 보였습니다. 이에 해당 논문에서는 이전 프로젝트에서 진행했던 If, Then, Else와 같이 규칙을 학습하는 방식이 아닌 모든 과정을 모델이 직접 학습하는 end-to-end 방식을 제안하고 있습니다.
2. Overview of the DAVE-2 system
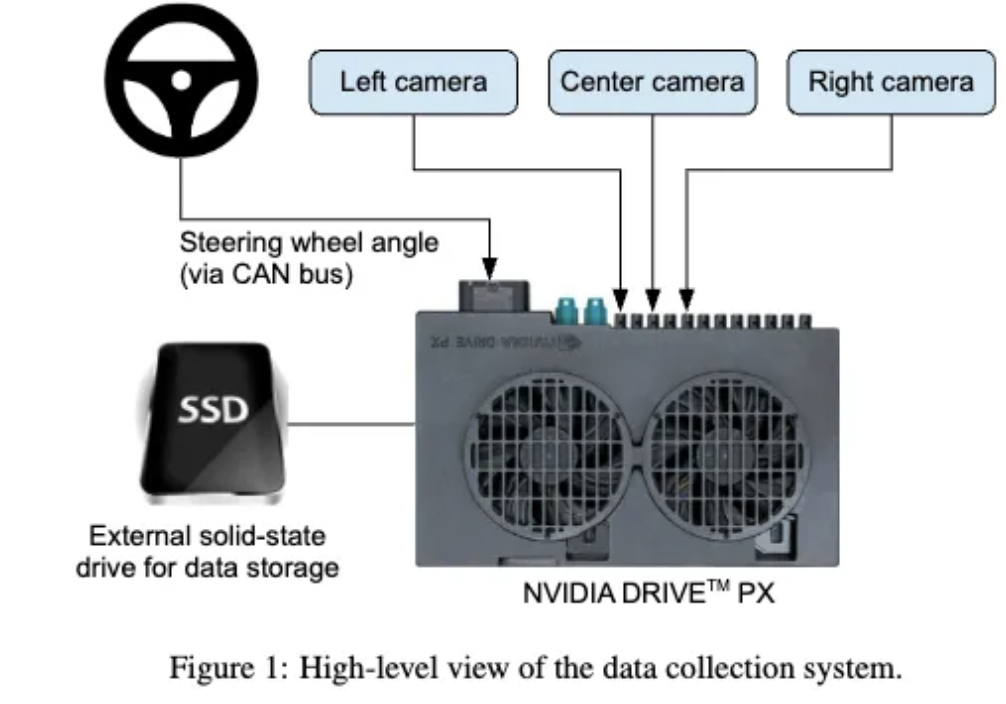
차량 앞 유리 뒤에 3대의 카메라가 설치되어 영상을 촬영합니다. 그리고 동시에 운전자의 핸들 정보 또한 함께 저장되도록 설계되어있습니다. 그리고 핸들 각도의 경우 로 표현하며, 우회전의 경우 양수, 좌회전의 경우 음수로 표현되도록 하였습니다. 그리고 사람의 운전 정보만을 가지고 학습하게 된다면, 차량이 길에서 벗어난 경우 다시 되돌아오는 데이터를 가지고 있지 않기때문에, 추가로 길을 벗안 경우 다시 돌아오도록 유도하는 추가 데이터를 학습에 사용하였습니다.
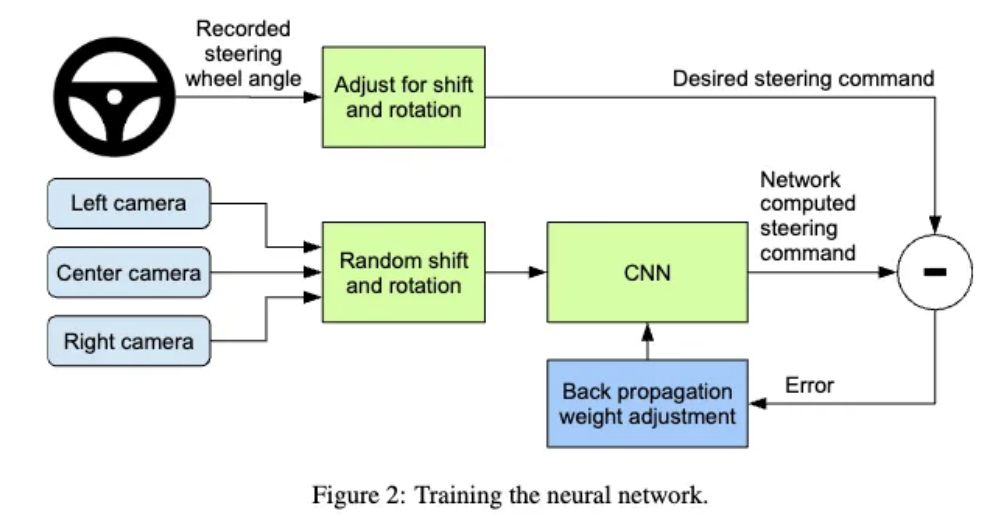
차량이 중앙선에서 벗어나는 경우는 왼쪽 카메라와 오른쪽 카메라를 통해서 확인할 수 있으며, 다양한 각도의 상황을 가정하기 위해서 가까운 카메라에서의 이미지를 변형시켜 마치 차량이 이동한것 과 같은 효과를 내어 데이터를 증강하였습니다. 그리고 3D 이미지를 활용해야 정확한 변형을 할 수 있지만, 해당 프로젝트에서 3D 데이터를 얻지 못하기 때문에, 단순히 모든 점들이 수평선 아래 존재한다고 가정을 하더라도 큰 문제가 없었다고 합니다. 그래서 최종적으로 학습을 하는 프로세스는 위의 그림과 같습니다. 카메라로 부터 얻은 이미지로 부터 핸들의 각도를 모델이 예측하도록 하고, 실제 핸들 각도와 비교하여 파라미터를 업데이트 하는 식으로 학습하게 됩니다. 즉, 각 이미지에 맞는 핸들 각도를 학습하게 하여 각 상황에 맞는 판다을 하도록 유도하게 됩니다.

그리고 최종적으로 자율주행을 수행하는 경우에는 하나의 카메라만 활용하여 수행하게 됩니다.
3. Data Collection
학습데이터의 경우 다양한 도로와 조명, 날씨 조건에서 주행하며 수집되었습니다. 대부분의 데이터는 미국에서 수집 되었으며, 다양한 유형의 도로가 존재합니다. 그리고 다양한 날씨에서 수집된 데이터 이기에 눈에 선이 가린 데이터들도 포함되어있습니다. 밤,낮 데이터도 모두 포함되어 있으며, 햇빛으로 인한 카메라의 왜곡 현상까지 포함되어 있습니다. 다양한 차종과 다양한 사용자가 모은 72시간 분량의 주행 데이터로 구성되어 있습니다.
4. Network Architecture
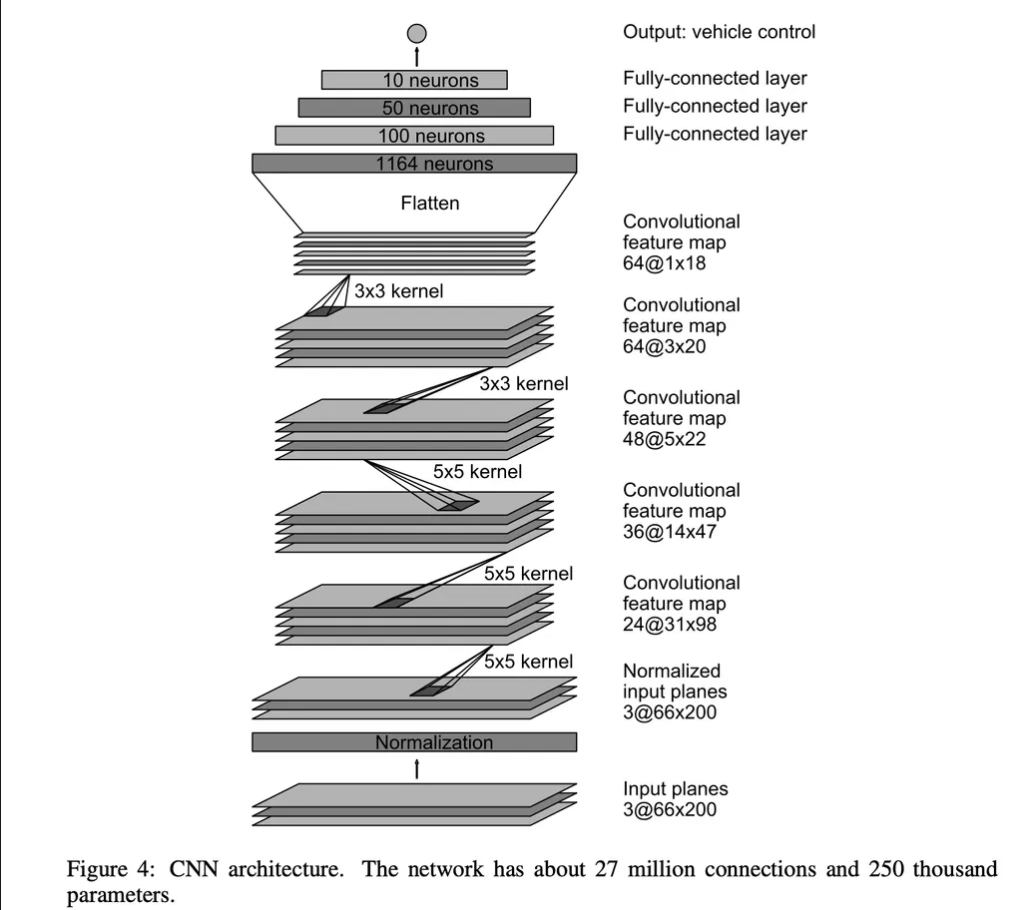
본 논문에서 사용하고 있는 아키텍처는 위의 그림과 같이 총 9개의 레이어로 구성됩니다. 정규화, 5개의 conv 레이어 그리고 3개의 FC 레이어로 구성됩니다. 이미지의 경우 YUV로 변환되어 아키텍처에 들어갑니다. ( 많은 카메라 센서, 영상 장치가 디지털 영상 신호를 YUV 형식으로 출력하기 떄문에 RGB 보다는 YUV 포멧을 활용합니다. 또한 밝기 및 색상 분리에 따른 인지 안정성이 높다고 합니다. )
Convolution 레이어의 경우 경험적으로 모델의 구조를 생성했고, 처음 3개의 레이어에 대해서는 stride = (2,2), kernel_size = (5,5)를 사용하여 전체적인 흐름을 파악하고, 뒤의 2개의 레이어의 경우 stride = (1,1), kernel_size = (3,3)을 사용하여 보다 세세하게 관찰할 수 있도록 설계하였습니다.
이후 FC 레이어를 통해서 Inverse turning radius ( 편의를 위해서 1/r 을 사용했기 떄문이다 ) 를 예측하게 됩니다. 여기서 End-to-End 학습을 하기 때문에 어느 네트워크가 이미지의 특징을 추출하고, 어느 네트워크가 최종적인 반경을 판단하는지를 명확하게 구별할 순 없습니다.
5. Training Details
5.1 Data selection
우선 CNN을 학습하기 위해서는, 이미지 내에서 차선을 따라가도록 학습해야 했습니다. 그래서 해당 논문에서는 다양한 조건의 이미지들 중에서 차량이 Lane (차선) 위에 존재하는 이미지만을 사용하여 학습을 하였습니다. 이미지의 경우 10FPS를 사용하였고, 더 높은 FPS를 사용하는 경우 이미지가 너무 비슷하여 효율적이지 못하기 때문에 10FPS를 선택하였다고 합니다. 추가로 직진 도로에 대한 편향을 줄이기 위해서 곡선 도로를 나타내는 프레임의 비율이 더 높도록 구성하였다고 합니다.
5.2 Augmentation
추가로 실제 환경의 다양한 상황을 학습 시키기 위해서 원본 이미지에 인위적으로 Shfit 시킨 이미지 + 차선에서 벗어난 이미지 등을 추가로 학습하였습니다. 해당 이미지 들은 표준 정규분포를 따르도록 랜덤으로 선택되었습니다. 데이터 증강시 인위적 이동이 일어나는 경우 실제로 일어날 수 없는 부자연스러운 이미지가 연출될 수 있기에 증강 범위를 잘 조절 할 필요가 있었습니다.
6. Simulation
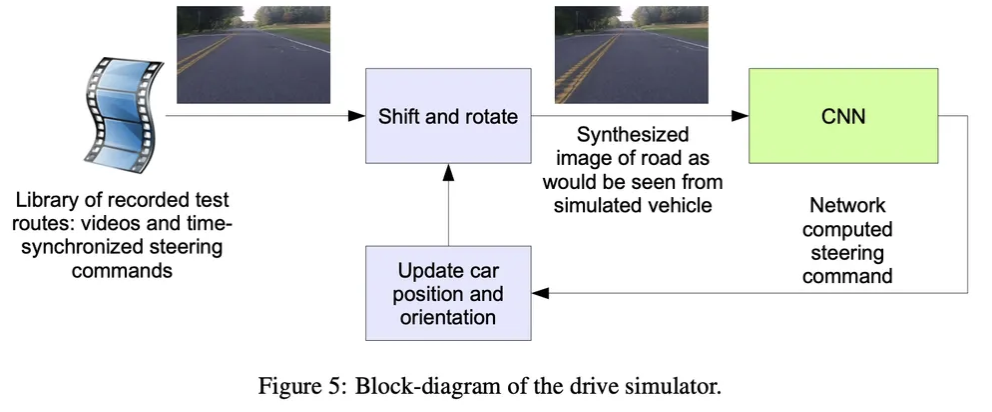
훈련된 CNN을 실제 도로에서 테스트하기 전에, 시뮬레이션을 통해서 성능을 테스트 했습니다. 우선 사람이 운전하는 데이터 수집 차량의 전면 카메라로 부터 영상을 얻고, 만약 자율주행을 하는 경우 해당 화면에 나타났을 화면을 생성하도록 하였습니다.
운전가가 항상 차선의 중앙에서 운전을 하는 것이 아니기 때문에 모든 이미지가 차선의 중앙으로 올 수 있도록 변환 과정을 거치게 됩니다. 이렇게 변형된 이미지가 CNN의 입력으로 들어가고, CNN은 결과를 내놓게 됩니다. 이렇게 내놓은 다음 상황의 이미지의 경우 다시 다음 CNN의 입력으로 들어가게 됩니다. 만일 CNN의 결과가 실제 정답과 1m 이상 멀어지게 된다면, 가상 인간의 개입이 발생하여 실제 정답 이미지를 다시 넣어주게 됩니다. 이를 반복하게 됩니다.
7. Evalutation

해당 네트워크는 시물레이션 → 실제 도로 테스트로 2단계에 걸쳐서 테스크가 진행되었습니다.

다음과 같은 평가지표를 사용해서 평가를 진행하였습니다.
Number of interventions : 사람이 개입한 경우 입니다. 즉, 차량이 실제 도로에서 1m를 벗어난 경우를 의미합니다.
6 seconds : 차량이 차선을 벗어난 후 다시 회복하는 데 걸리는 시간
elapsed time : 전체 차량이 운전한 시간.
즉, 이를 통해서 최종적으로 차량이 스스로 운전한 시간을 백분위로 나타내어 평가할 수 있게 됩니다. 만일 600초의 시간 동안 운전을 하는 도중 총 10번의 사람의 개입이 있었다고 가정 하게 된다면 다음과 같이 자율주행 90% 를 얻을 수 있게 됩니다.
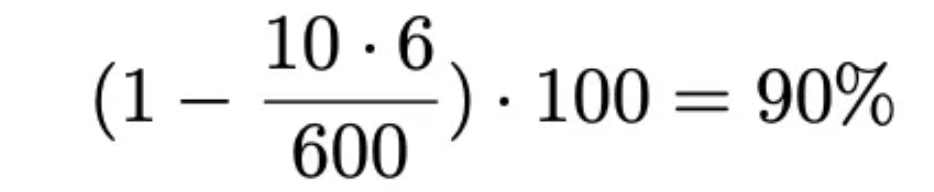
7.2 on_road test
뉴저지내에서 특정 거리에서 실험한 결과 98% 자율주행 능력을 보여줬다고 합니다. 또한 다차선 분리 고속도로에서는 10마일 주행하는 동안 한번의 인간개입도 없었다고 합니다.
7.3 Visualization of Internal CNN State


또한 도로의 이미지와 숲의 이미지를 비교한 결과, 우리가 명시적으로 도로의 특징을 알려주지 않아도 모델이 스스로 도로의 특징을 학습한 것을 확인할 수 있습니다. 도로 사진의 경우 스스로 윤곽선 픽셀들이 확성화 되는 한편, 숲의 이미지에서는 노이즈가 발생하는 것을 통해 확인할 수 있습니다.
8. Conclusion
본 논문은 CNN이 도로 차선 마킹 감지, 경로 계획 등 별도의 수동적·명시적 기능 분해 없이도 차선 및 도로 주행이라는 전체 작업을 End-to-End 방식으로 학습할 수 있음을 실험적으로 증명하였으며, 100시간 미만의 데이터만으로도 다양한 도로, 날씨, 주간 및 야간 조건에서도 효과적인 학습이 가능함을 입증하였습니다.
