Abstract
논문에서는 Segmentation 분야에서의 기초 모델(foundation model)을 목표로 하는 SA 프로젝트를 제안합니다. 이 프로젝트의 핵심 요소는 다음과 같습니다:
- Zero-shot Task: 추가 학습 없이 새로운 데이터와 과제에 적용할 수 있는 작업을 제안합니다.
- 효과적인 Model: 사용자가 입력한 프롬프트(prompt)를 기반으로 실시간으로 zero-shot 일반화가 가능한 모델을 설계하였습니다.
- 방대한 Dataset: 대규모 데이터셋을 활용하여 모델의 성능과 범용성을 극대화합니다.
이러한 접근을 통해, 다양한 하위 작업에서도 우수한 성능을 발휘하는 모델을 개발하는 것을 목표로 합니다.
Introduction
NLP 분야에서는 웹상의 방대한 텍스트 데이터를 기반으로 기초 모델(foundation model)을 구축하여, 적은 계산량으로도 zero-shot과 few-shot 학습을 가능하게 했습니다. 이와 유사하게, Vision 분야에서는 CLIP과 같이 이미지와 텍스트 쌍을 활용한 모델이 prompt를 통해 다양한 zero-shot 및 few-shot 학습을 수행하고 있습니다. 이러한 배경을 바탕으로, 해당 논문은 segmentation 분야에 특화된 기초 모델을 만들기 위한 SA 프로젝트를 제안합니다. 이를 위해 논문은 세 가지 핵심 질문에 대해 답을 제시하는데,
첫째, 어떤 문제를 zero-shot으로 일반화할 수 있는가에 대해서는 promptable segmentation task를,
둘째, 알맞은 모델 구조에 대해서는 flexible prompting과 real-time 대응이 가능한 모델을,
셋째, 효과적인 데이터에 대해서는 data engine을 통한 대규모 데이터 수집 방식을 제안합니다.
이와 같이 SA 프로젝트는 기존의 NLP와 Vision 분야에서의 성공 사례를 바탕으로, segmentation 분야에서도 효과적으로 적용될 수 있는 기초 모델 개발을 목표로 하고 있습니다.
Task (§2):
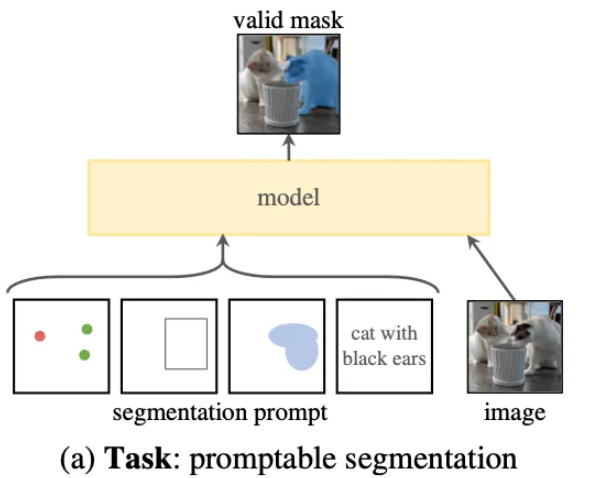
NLP 분야에서는 웹상의 방대한 텍스트 데이터를 활용해 구축한 기초 모델이 prompting 기술을 통해 새로운 데이터 분포와 작업을 zero-shot, few-shot 방식으로 처리해왔습니다. 최근 컴퓨터 비전 분야에서도 이러한 접근법이 적용되어, 예를 들어 CLIP과 같은 모델이 이미지와 텍스트 쌍을 정렬하고 prompt를 이용해 다양한 작업을 수행하고 있습니다.
이에 영감을 받아, 본 논문에서는 promptable segmentation task를 제안합니다. 이 작업의 목표는 어떤 segmentation prompt가 주어지더라도 유효한 segmentation 마스크를 반환하는 것입니다. 여기서 prompt는 이미지 내에서 분할할 대상을 지정하는 역할을 하며, 이는 특정 객체를 나타내는 공간 정보나 텍스트 정보를 포함할 수 있습니다. 만약 prompt가 모호하여 여러 객체에 해당할 수 있는 경우에도, 출력되는 segmentation 마스크는 이러한 객체들 중 적어도 하나에 대해 합리적인 결과를 제공해야 합니다.
이와 같이, promptable segmentation task는 사전 학습 목표로 활용될 뿐 아니라, prompt engineering을 통해 다양한 다운스트림 segmentation 작업을 해결할 수 있도록 설계되었습니다.
Model (§3):
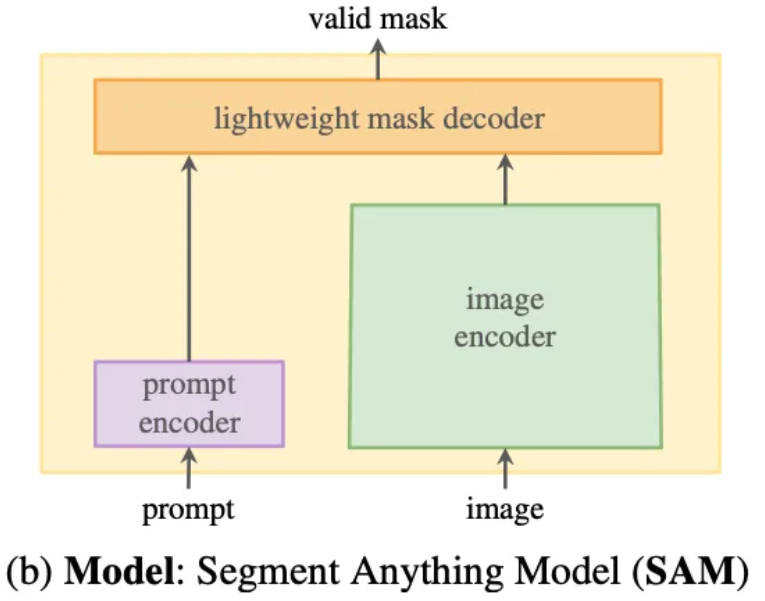
프롬포트 분할 작업과 실제 사용 목표는
1️⃣ 유연한 프롬포트 지원 ( 점, 박스, 마스크, 텍스 등등 다양한 프롬포트 ) 2️⃣ 실시간 분할 마스크 계산 ( prompt가 주어지면 바로 분할 )
3️⃣ 모호성 인지 ( 사람인지 , 셔츠 인지 등등 모호성 존재 )
본 논문에서는 SAM 이라는 모델로 위의 3가지 문제점을 간단하게 해결한다고 합니다. 강력한 이미지 인코더로 입력 이미지로 부터 임베딩을 생성하고, 프롬포트 인코더로 프롬포트를 인코딩 한다고 합니다. 그리고 이미지 임베딩과 프롬포트 임베딩을 결합하여 최종 분할 마스크를 예측한다고 합니다. 그리고 이미지 인코더와, 프롬포트 인코더, 마스크 디코더를 분리함으로써 재사용성을 극대화 하였다고 합니다.
모호성을 해결하기 위해서는 하나의 프름포트 예측에 대해서 여러개의 마스크를 예측하도록 설계하여 이를 해결하였다고 합니다.
Data engine (§4):
Foundation 모델을 만들기 위해서 대량의 고품질 데이터가 필요하고, 원래는 웹상에서 데이터를 받아오는 것이 일반적입니다. 하지만 Mask의 경우 자연스럽게 습득할 수 있는 데이터가 아니기 때문에 Data-engine이라는 과정을 통해서 데이터를 얻습니다.
- 사람이 직접 라벨링을 진행합니다.
- SAM을 활용하여 라벨링 후 부족한 부분을 사람이 직접 수행합니다.
- 모델이 자동으로 라벨링을 진행하도록 합니다.
Dataset (§5):
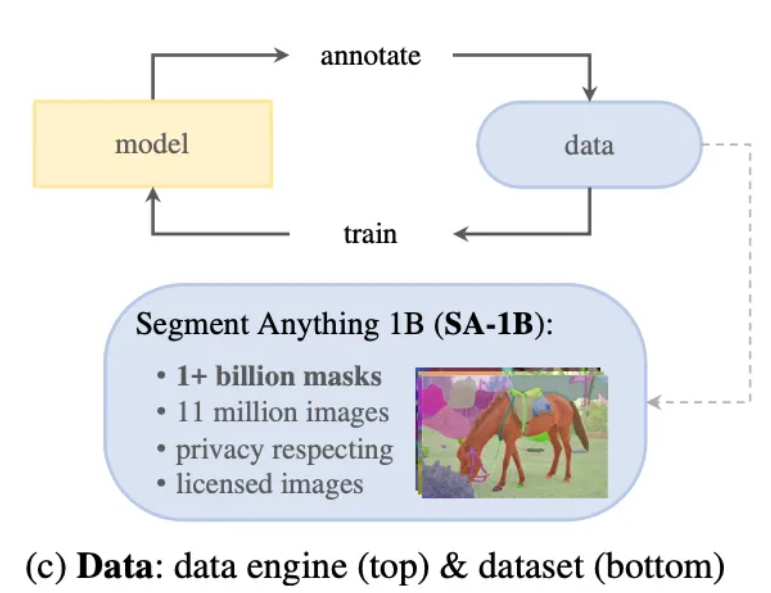
최종적으로 구축된 데이터셋인 SA-1B는 11백만 개의 라이선스가 부여되고 개인정보 보호를 준수하는 이미지에서 10억 개 이상의 마스크를 포함하고 있습니다. SA-1B는 데이터 엔진의 마지막 단계를 통해 완전히 자동으로 수집되었으며, 기존의 어떤 분할 데이터셋보다 400배 많은 마스크를 보유하고 있습니다.
2. Segment Anything Task
본 논문의 task는 NLP에서 다음 토큰을 예측하는 task에서 영감을 받았습니다.
Task
이에 promptable segmentation task를 푸는것을 목표로 하고 있습니다. prompt 로 텍스트, 점, 선, 박스, 마스크 와 같이 어떠한 prompt가 들어와도 segmentation을 진행하는 것을 목표로 하고 있습니다. 그래서 모호한 prompt가 들어오더라도 유효한 결과를 제출하는 것이 과제입니다.
Pre-training
어떠한 prompt가 들어오더라도 유효한 결과를 도출하기 위해서 프롬포트 분할 작업을 사전 학습 알고리즘으로 사용합니다. 각 학습 샘플에 대해 여러 형태의 프롬포트를 시뮬레이션하고, 모델이 예측한 마스크와 정답을 비교하며 학습하게 됩니다.
기존의 분할 문제 : 사용자가 정답이 포함된 방대한 양의 데이터를 입력으로 넣게 되면 모델이 이를 학습하여 입력에 대해서 모든 객체를 분할하여 결과를 도출해준다.
SAM 사전 학습 문제 : 다양한 양의 정답 마스크가 존재하고, 각각의 정답 마스크에서 생성할 수 있는 다양한 프롬포트를 자동으로 생성합니다. 그리고 이러한 프롬포트가 주어진 경우 우리의 정답을 잘 예측할 수 있는 모델을 만드는 것이 목표입니다.
Zero-shot transfer
이러한 프롬포트 학습 방식을 통해서 모델은 down stream task들에 대해서 prompt 접근 방식을 통해서 문제를 해결할 수 있게 됩니다.

3. Segment Anything Model
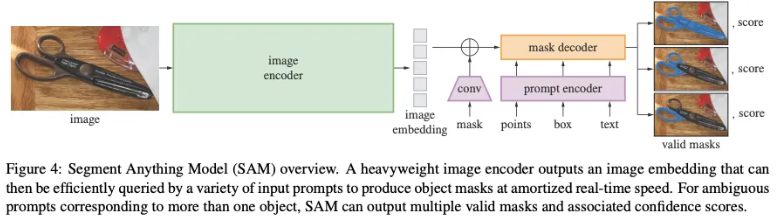
SAM 모델은 총 세 가지 주요 구성 요소로 이루어져 있습니다. 첫째, image encoder, 둘째, flexible prompt encoder, 셋째, fast mask decoder
Image encoder:
이미지 인코더는 MAE 방식을 통해 사전 학습된 ViT(Vision Transformer)를 기반으로 합니다. 또한, 높은 해상도의 이미지를 효과적으로 처리할 수 있도록 약간의 수정이 이루어졌습니다.
Prompt encoder:
‘flexible prompt encoder’라는 표현은 프롬프트의 유형에 따라 서로 다른 임베딩 방식을 적용하기 때문입니다. 본 논문에서는 프롬프트를 크게 두 가지로 분류합니다.
첫 번째는 Sparse Prompt로, 여기에는 점, 박스, 텍스트가 포함됩니다. 점과 박스의 경우, 각 프롬프트에 해당하는 학습된 임베딩과 positional encoding을 결합하여 표현하며, 텍스트는 CLIP의 텍스트 인코더를 사용하여 임베딩됩니다.
두 번째는 Dense Prompt로, 주로 마스크를 의미하며, 이는 합성곱 계층을 거쳐 임베딩된 후 이미지 인코딩 결과와 픽셀 단위로 결합됩니다.
Mask decoder
수정된 Transformer 디코더 블록에서는 프롬프트와 이미지 임베딩이 양방향 어텐션을 통해 서로 상호작용하며 업데이트됩니다. ( 각각의 임베딩이 서로 한번은 쿼리가 되고, 한번은 키,벨류 가되면서 서로의 정보를 반영하여 업데이트 되게 됩니다. )
이 과정에서 프롬프트는 이미지 임베딩 내에서 관심 영역에 대한 신호를 전달하고, 두 임베딩이 서로 보완되어 최종 분할 결과에 필요한 정보를 형성합니다.
이후, 업데이트된 이미지 임베딩은 업샘플링되어 더 높은 해상도의 특징 맵으로 변환되고, 출력 토큰 ( decoder 결과의 일종으로 객체에 대한 정보를 계속해서 저장하고 있습니다. )이 MLP를 통해 동적 선형 분류기로 매핑되어 각 픽셀마다 사용자가 지정한 객체를 나타내는 확률을 계산합니다.
결국, 높은 확률을 가진 픽셀들이 해당 객체의 영역으로 결정되어 최종 분할 마스크가 생성됩니다.
Resolving ambiguity
모호한 포롬포트에 의해서 모델이 여러가지 유효한 마스크를 출력으로 내놓지만, 하나의 결과만 가지게 할 경우 모든 마스크를 평균한 결과를 낼 수 있습니다 ( 유효한 마스크를 혼합한 이상한 마스크를 내놓을 수 도 있다 ). 이를 방지하기 위해서 모델의 결과로 나온 유효한 마스크들 중에서 Loss가 가장 적은 하나의 마스크에 대해서만 역전파를 수행하여 파라미터를 업데이트 하도록 합니다. 각 마스크에 대한 신뢰도 점수는 IOU를 사용하비다.
Losses and training
본 몬델의 경우 Focal Loss + Dice Score를 선형으로 결합한 손실 함수를 사용하고 있습니다. 하나의 마스크에 대해 다양한 형태의 프름포트를 입력으로 사용합니다. 또한 하나의 마스크에 대해서 랜덤으로 11개의 프롬포트를 시뮬레이션 하게 됩니다. ( 본 프로젝트의 data engine과 통합되며 )
4. Segment Anything Data Engine
마스크로 라벨링된 이미지가 웹 상에 많이 존재하지 않기 떄문에, 해당 프로젝트에서는 1.1B 개의 마스크된 이미지를 얻기 위해서 본 프로젝트만의 data engine을 구축하였습니다. data engine은 총 3단계로 구성됩니다.
Model assisted manual annotation → semi-automatic stage with a mix of automaticaaly predicted masks and model-assisted annotation → fully automatic stage in which our model generates masks without annotator input. 간단하게 정리하면 기존의 모델의 도움을 받은 후 사람이 라벨링 진행 → 어느 정도 학습된 모델에 사람이 수정만 진행 → 모든 라벨링을 모델이 직접 진행.
Assisted-manual stage
첫 단계에는 사람이 직접 Annotation을 진행하였습니다. 공공 데이터셋을 활용하여 학습된 ViT 모델을 활용하여 이미지의 특징을 추출하고, 이어서 사람이 중요한 부분을 라벨링 하도록 진행하였습니다. 그리고 이를 통해서 다시 모델을 학습하였습니다. 이렇게 6번의 ( 학습 → 라벨링 ) 을 거치면서 라벨링 속도가 빨라졌고, 쵲오적으로 120k개의 이미지에서 4.3M 개의 마스크를 추출할 수 있었다고 합니다.
Semi-automatic stage
자동으로 신뢰할 수 있는(Confident) 마스크를 먼저 생성합니다. 그런 다음 주석자들은 자동으로 채워지지 않은, 덜 두드러진 객체들에 대해서만 추가 어노테이션을 진행합니다.
이 단계에서는 전체 이미지에서 자동으로 감지된 마스크 외에도, 부족한 부분만 보완하여 데이터의 다양성과 완성도를 높이는 것이 목표입니다.
Fully automatic stage
충분한 데이터와 모호성을 처리할 수 있는 모델 개선 덕분에, 32×32 격자 포인트를 이용해 각 포인트마다 여러 마스크를 예측하고, 신뢰도와 안정성을 기준으로 올바른 마스크만 자동으로 선택 및 후처리합니다. 이로써, 인간의 개입 없이 전체 데이터셋에서 대규모의 고품질 마스크를 생성할 수 있게 됩니다.
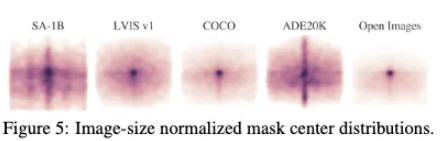
객체의 중앙이 다양한 곳에 분포되어 있어, 다양한 위치를 갖는 객체들이 존재함을 암시한다.
5. Segment Anything Dataset
본 프로젝트의 데이터셋의 경우 다른 데이터셋에 비해서 높은 해상도를 가지고 있으며, 다양한 라이센스를 포함하고 있습니다. 그리고 웹상에서 데이터를 제공하기에 작은 픽셀의 길이가 1500이 되도록 다운 샘플링된 이미지를 제공하고 있다고 합니다. 그리고 마스크의 경우 99.1%가 자동으로 설정되었고, 추가로 마스크 퀄리티 또한 IOU를 비교했을떄 94% 의 마스크가 IOU 90을 넘김을 통해 마스크 또한 신뢰성이 높다고 주장하고 있습니다.



기초 모델(foundation models)의 개념과 SAM 모델의 의의를 설명합니다. SAM은 대규모 감독 학습과 프롬프트 분할 작업을 통해, 다양한 다운스트림 분할 작업에 적용할 수 있는 범용 모델로 설계되었습니다. 특히, SAM은 프롬프트를 활용해 이미지 내의 객체를 효과적으로 분할하고, 다른 시스템과 쉽게 조합될 수 있도록 하는 점에서 혁신적입니다. 다만, 세밀한 구조나 복잡한 경계를 완벽하게 처리하지 못하는 한계와, 일부 도메인에서는 전용 도구에 비해 성능이 떨어질 수 있는 문제도 언급됩니다. 결국, 이 프로젝트는 1B 이상의 마스크와 SA-1B 데이터셋을 공개함으로써, 이미지 분할 분야를 새로운 기초 모델 시대로 이끌어가는 데 기여하는 것을 목표로 합니다.
