DETR overview
DETR 논문에서는 기존의 NMS와 같은 인간의 사전 지식을 배제한 모델을 제안했다고 주장한다. 하지만 단순히 앵커박스와 관련된 지식을 제거했을 뿐, 추가로 헝가리안 알고리즘을 도입하여 인간 개입이 아애없다고는 볼수 없어 보인다.
그래도 DETR의 핵심 아이디어는 [ 이분매칭 + Transformer ] 아키텍처이다. 싶지어 이분 매칭의 set들은 RNN과 다르게 순서가 중요하지 않다 보니깐 Non-Autoregressive하게 처리가 가능하여 모든 객체 후보에 대해서 병렬로 처리가 가능하다.
이분 매칭의 경우[[헝가리안 알고리즘]] 을 사용하였다. ( 1 대 1 매칭 최적화 알고리즘 )
기존 모델들의 문제점 :
(박스, 객체) 를 매칭하는 방법으로 우선 여러 후보를 만들고, 거기서 surrogoate regression과 classification problem을 도입해서 Detection 이라는 모델안에서 추가적인 2개의 task를 수행하는 모델을 사용하는 격이였다.
DETR 논문
Object detection set prediction loss
우선 DETR의 경우 모델이 예측하는 객체와 이미지에 존재하는 실제 객체들 사이에서 1 대 1로 매칭을 해줘야한다. 그러기 위해서는 모델이 몇개의 객체를 예측할지에 대해서 설정을 하는데, 주로 이미지 내 존재하는 객체의 수보다 많이 선택한다고 합니다. 아마도 Train 데이터나 Valid 데이터 중 가장 많은 객체의 수보다 많이 선택할것 이다.
그에 실제도 N개로 갯수를 맞춰줘야하기에, 예를 들어 K개의 실제 객체가 존재한다면 N - K 개의 을 할당해주게 된다.
그래서 일단 모델의 N개 예측과 N 개의 실제 값을 서로 헝가리안 알고리즘을 통해서 매칭해줍니다.
이떄 헝가리안 매칭에 사용되는 SCORE는 매칭된 예측과 실제값에 대해서 (클래스, (박스 좌표, 박스 크기)) 에 대한 손실을 계산하게 됩니다. 그래서 이를 수식으로 표현하면 아래와 같이 나타낼 수 있습니다.
그래서 위의 수식에 따라서 헝가리안 알고리즘에서 기회비용표가 만들어지게 됩니다.
Label의 경우 로 구성된다고 합니다. c의 경우 class에대한 라벨을 , 그리고 b는 로 ( 중심x, 중심y, 상대적 높이, 상대적 넓이 )로 구성되어 있다고 합니다.
그리고 의 경우 아래와 같이 표현이 가능합니다.
식에서 알수 있듯이 모두 실제값이 객체인 경우에 대해서만 손실을 계산해 주게 됩니다. 그리고 배경인 경우에는 모든 매칭 손실은 0 ( 상수 ) 취급하게 되어 객체를 매칭할때 아무런 영향을 주지 않습니다.
위의 식을 통해서 1 대 1 매칭을 할수 있고, 최종적으로 모델이 최적화 해야하는 Loss는 "헝가리안 Loss" 라고 불립니다. 다음과 같이 모든 매칭에 대해서 class 손실을 구해주고, 실제 정답이 객체인 경우에 대해서만 박스 손실을 더해주게 됩니다.
그리고 배경 클래스에 대해서는 만일 ( 클래스 = 배경 )인 경우에는 전경보다 압도적으로 많기 떄문에 가중치를 1/10을 주어 모두 배경으로만 학습하는 것을 막아주는 효과를 강제하게 됩니다. 그리고 박스 손실의 경우 GIOU를 사용하게 됩니다.
객체가 아닌 박스에 대해서는 박스손실을 계산하지 않게 됩니다.
정리
헝가리안을 사용하기 위해서 기회비용표를 만들어야하는데, 각 정답과 모델의 예측사이의 cost 함수는 아래와 같이 정의됩니다.
그리고 위 식을 통해서 매칭이 끝난 후 최종적으로 모델의 손실은 "헝가리안 손실"로 불리고 아래와 같은 식을 통해서 정의됩니다.
Bounding box loss
DETR에서 박스에 대해 손실을 구하는 경우 박스의 좌표와 크기를 직접 구하게 됩니다. 하지만 그렇게 되는 경우 박스 크기에 따라서 박스의 크기가 크면 에러 정도가 비슷해도 더큰 에러를 갖게 된다는 문제가 발생합니다.
이를 해결하기 위해서 해당 논문에서는 GIOU와 loss를 선형결합한 손실 함수를 사용한다고 합니다. GIOU의 경우 generaized IOU로 이미지의 크기 까지 고려한 평가 방법입니다.
그래서 최종적으로 Box에 대한 손실은 아래와 같이 정의됩니다.
위의 의 경우 박스가 최대한 겹치도록 유도하고, 의 경우 박스가 각 축 방향으로 얼마나 이동해야하는지를 의미합니다.
그래서 결국 최대한 많이 겹치면서 좌표값을 조정하도록 모델을 강제하는 손실입니다.
DETR ARCHITECTURE
DETR은 크기 3가지 component로 구성된다.
1) CNN Backbone
2) Transformer
3) FFN
+) Transformer가 나왔음에도 불구하고 지속적으로 모델의 Backbone이나 앞쪽에 CNN모델을 사용하는 이뉴는 우선 Transformer에 비해 CNN이 사용하는 파라미터의 수가 월등히 적기 떄문입니다. 그리고 지금까지 다양한 pre-trained 모델이 존재하여 추가 학습 없이도 충분히 이미지의 선,면 등과 같은 저수준의 특징을 잘 파악할수 있다는 장점이 있어서 꾸준히 사용되고있습니다.
CNN Backbone
CNN 모델의 경우 주로 3채널 이미지를 받고, 해상도를 32배로 줄이고, 채널은 2048을 사용한다고 합니다.
Transformer encoder
Transformer encoder의 입력으로 넣기 전에 CNN Backbone에서 나온 Feature map에 (1 X 1 ) convolution을 곱해서 차원을 C -> d 로 더 작은 차원으로 낮추준다고 합니다. 그리고 Transformer의 경우 입력에 대한 순서를 무시하고 모든 변수들과의 attention을 하기에 어느 패치에서 왔는지에 대한 정보를 넣어주기 위해서 positional encoding을 더해주게 됩니다.
그런 다음 Trnasformer의 입력으로 넣기 위해서 feature map을 flatten 하여 d * HW 크기의 입력을 만든다고 합니다.
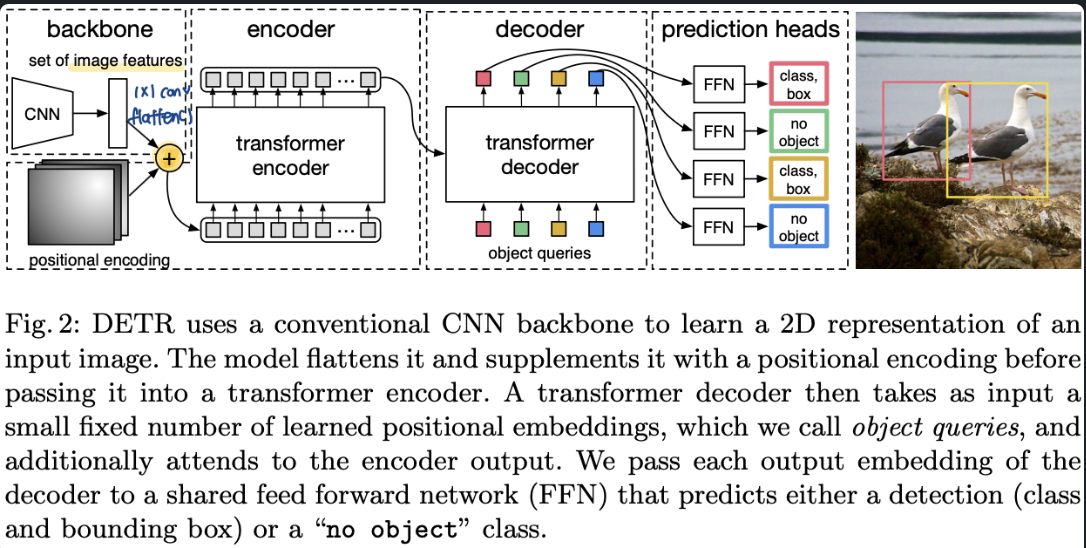
Transformer Decoder
deocder의 입력의 경우 N개의 "학습 가능한 positional embedding" 입니다. 그래서 각각이 다른 값을 가지고 있어 서로 다른 출력을 갖게 됩니다.
이후에는 일반적인 Transformer와는 동일하게 작동하며, self attention을 통해서 서로 중복을 최대한 피하면서 cross-attention을 통해서 전체적인 이미지르 보고 각각 어느 위치를 할당하지 정하게 됩니다.
그리고 최종적으로 N개의 출력을 내게 되는 구조를 가지고 있습니다.
Prediction Feed-Forward Networks (FFNs)
3개의 projection Layer와 Box Head와 class Head로 구성됩니다.
Proejction의 경우 nn.Linear(d,d)가 총 3번 반복되고, Box Head의 경우 모델의 출력은 [0,1] 사이의 값으로 정규화가 되어 나와 이미지 크기에 맞게 다시 크기를 재정규화해줘야합니다. 그리고 class head의 경우 최종적으로 C + 1 개의 클래스를 예측 후 softmax로 확률값을 전달하게 됩니다.
Auxiliary decoding losses
추가적으로 보조 손실을 사용하면 보다더 유용하다고합니다.
기본적인 방법은 유지하되, 각 디코더의 레이어별로 매칭 후 FFN와 각 HEAD를 통과해서 결과를 도출해서 손실을 구한다고 합니다.
예를들어서 K개의 레이어로 구성된 decoder의 경우 원래는 최종 K 번째에 대해서만 Loss를 구했다면, 보조 손실은 K 전의 ( K - 1 ) 개에 대해서 헝가리안 손실을 구하고 최종 손실에 이 보조 헝가리안 손실을 더해주어 각 레이어 과정에서도 손실이 흐르도록 해준다고 합니다.
