Abstract
해당 논문에서는 계층적 Transformer를 제안하며 컴퓨터 비전에서 사용되는 Backbone을 구축하고자 합니다.
Swin-Transformer의 경우 계층정 구조를 통해서 다양한 크기의 객체를 탐지하느데 유리하며, shifted-window 방식을 사용하여 서로 겹치지 않은 윈도우를 통해서 제한된 self-attention 연산량을 가지고 높은 정확도를 달성합니다. 각 윈도우 끼리 상호작용 또한 가능합니다.
이렇듯 다양한 컴퓨터 비전 분야에서 사용이 가능하며 실제로 다양한 분야에서 높은 정확도를 보여주며 컴퓨터 비전 분야의 Backbone 모델로 제안되었습니다.
Introduction
지금까지 컴퓨터 비전 분야에서는 CNN 기반의 모델들이 압도적인 성능을 발휘하며 모든 분야에서 Backbone으로 구성되었습니다. 한편 NLP 분야에서는 transformer가 급부상 하면서 컴퓨터 비전에서도 transformer를 적용하여 높은 성능을 발휘하는 모델들이 나오기 시작했습니다.
하지만 해당 논문에서는 단순히 transformer를 이미지에 적용하면 다음과 같은 2가지 문제가 발생한다고 지적하고 있습니다.
- 기존의 Transformer는 입력 토큰의 크기를 일정하게 고정하여 처리합니다. 예를 들어 텍스트에서는 모든 토큰이 보통 512차원과 같이 동일한 임베딩 차원으로 표현되므로 문제가 없지만, 이미지의 경우 작은 객체와 큰 객체 등 크기와 세부 정보가 크게 다르기 때문에 고정된 스케일로 처리하는 방식은 적합하지 않습니다.
- 텍스트에 비해 이미지는 훨씬 많은 수의 픽셀을 포함하므로, self-attention 연산 시 입력 크기의 제곱에 비례하여 계산량이 증가합니다. 이로 인해 이미지 크기가 커질수록 연산량이 급격히 늘어나며, 픽셀 단위의 밀집 예측 작업에서는 특히 부담이 됩니다.
위와 같은 두 가지 문제를 해결하기 위해 나온 것이 바로 “Swin Transformer”입니다. Swin Transformer는 처음에 작은 사이즈의 패치로 입력을 처리한 후, 계층적 구조를 통해 점진적으로 정보를 통합하며 더 큰 영역의 패치(혹은 특징 맵)를 생성합니다. 이러한 구조 덕분에 FPN, U-Net 등 최신 기술과 쉽게 결합할 수 있으며, 윈도우 단위의 self-attention을 사용해 연산량이 이미지 크기에 따라 선형적으로 증가하도록 설계되어 효율성을 크게 향상시켰습니다.
self-attention들의 연이은 게층적 구조는 swin-transformer의 핵심 아이디어 입니다. shifted window는 이전의 window와의 다리 역할을 할 뿐 아니라 모델이 다양한 패턴을 학습할 수 있도록 도와줍니다.
Method
3.1 Overall Architecture
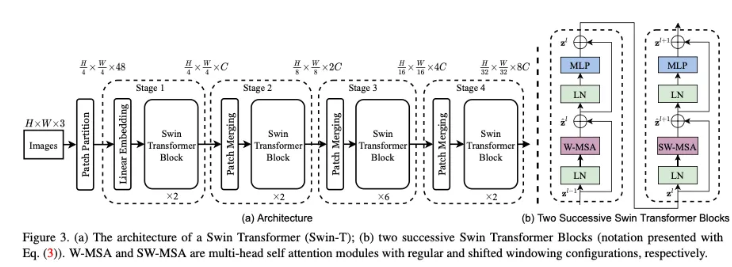
Swin Transformer는 ViT와 유사하게 입력 이미지를 겹치지 않는 패치 단위로 분할하여 각 패치를 토큰으로 사용하는데, 초기에는 4×4 픽셀 크기의 패치를 RGB 값을 이어 붙여 4×4×3의 벡터로 표현하고, 이후 선형 변환을 통해 C 차원의 표현으로 매핑합니다. 이 과정을 거치면 전체 이미지에서 H/4×W/4 개의 토큰이 생성되고, 각 토큰은 이후 로컬 self-attention을 수행하는데, 여기서는 먼저 고정된 윈도우(W-MSA) 내에서 어텐션을 계산한 후, 윈도우를 일정 픽셀만큼 이동시킨 shifted 윈도우(SW-MSA)를 적용하여 경계에 위치한 토큰들이 다른 윈도우와 상호작용할 수 있도록 하고, 이때 상대적 위치 바이어스를 추가하여 토큰 간 공간적 관계를 효과적으로 반영합니다. 마지막으로, Patch merging 모듈을 통해 인접한 패치들을 결합하면서 해상도를 점진적으로 줄이고 채널 수를 증가시켜 계층적 특징 표현을 구축하며, 이 전체 과정이 반복되어 효율적인 비전 태스크 수행이 가능하게 됩니다.
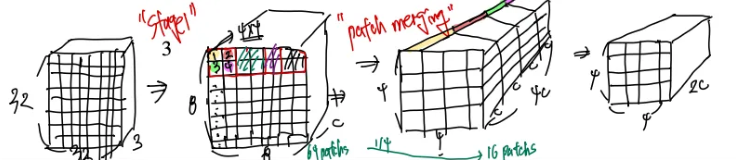
Swin transformer block
Swin Transformer Block은 전반적으로 기존 Transformer 블록(MLP, LayerNorm, Residual Connection 등)과 유사하나, self-attention을 윈도우(창) 단위로 계산한다는 점이 특징입니다.
- W-MSA(Window-based MSA): 고정된 윈도우 내에서만 self-attention을 수행하는 블록
- SW-MSA(Shifted Window-based MSA): 윈도우를 일정 픽셀만큼 이동(shift)하여, 이전에 다른 윈도우에 있던 경계 픽셀들이 새롭게 같은 윈도우에 포함되도록 하는 블록
이 두 블록이 번갈아 적용되며, 경계 픽셀도 인접 윈도우의 정보와 상호작용할 수 있도록 합니다.
MLP는 2층(2-layer) 구조이며, 활성화 함수로는 GELU를 사용합니다. LayerNorm은 각 Attention과 MLP 앞에 적용되고, 이후에는 Residual Connection이 더해져 학습 안정성과 표현력을 높여줍니다.
Self-attention in non-overlapped windows
Swin Transformer는 한 윈도우(예: 7×7) 내에서만 self-attention을 수행하므로, 전역적으로 모든 토큰과의 상호작용을 계산하는 기존 Transformer에 비해 연산량이 크게 감소합니다.
- 윈도우 내 패치 수가 일 때, self-attention의 복잡도는 에 비례합니다.
- M이 고정된 상수(주로 7)로 취급되면, 전체 이미지의 패치 수(hw)가 증가해도 연산량은 정도로 선형 증가하여, 고해상도 이미지나 밀집 예측 태스크에서도 효율적으로 적용할 수 있습니다.
3.2 Shifted window partitioning in successive blocks
윈도우가 겹치지 않도록 분할할 경우, 경계 픽셀끼리는 서로 다른 윈도우에 속해 정보 교환이 제한되는 문제가 생깁니다. 이를 해결하기 위해, Shifted Window(SW-MSA) 방식을 도입합니다.
- 윈도우 이동(Shift):
한 블록에서는 정규 윈도우(W-MSA)를 사용하고, 다음 블록에서는 윈도우를 가로·세로 방향으로 픽셀만큼 이동시킵니다.
이렇게 하면 이전에 다른 윈도우에 속했던 경계 픽셀들이 새롭게 같은 윈도우에 포함되어, 경계 간 정보도 상호 교환할 수 있게 됩니다.
- 효과: 1.계산 효율 유지: 여전히 윈도우 내부에서만 self-attention을 수행하므로, 전역 self-attention보다 훨씬 적은 연산량이 듭니다. 2.윈도우 간 정보 교류: 경계 픽셀들이 교대로 다른 윈도우에 편입되므로, 전체 이미지의 문맥을 더 풍부하게 학습할 수 있습니다.
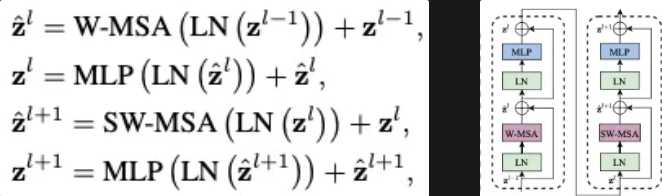
Efficient batch computation for shifted configuration
단순히 윈도우를 이동시키면, 일부 윈도우가 경계를 넘어가서 패치 수가 달라질 수 있습니다.
Cyclic Shift: 경계를 넘어간 픽셀을 반대편에서 다시 가져오는 방식으로 “순환”시켜, 모든 윈도우가 동일한 크기와 패치 수를 유지하게 합니다.
Masked MSA: 그래도 윈도우 경계를 넘는 토큰끼리는 서로 주의를 주고받지 않도록 마스킹 처리하여, 윈도우 간 혼선이 없도록 합니다.
계산 후에는 다시 원래 위치로 되돌리는(reverse shift) 과정을 거쳐, 전체 공간적 정렬을 유지합니다. 이 과정을 통해, 모든 레이어에서 동일한 윈도우 크기,갯수로 배치 연산이 가능하며, 경계 정보도 효율적으로 교환할 수 있습니다.
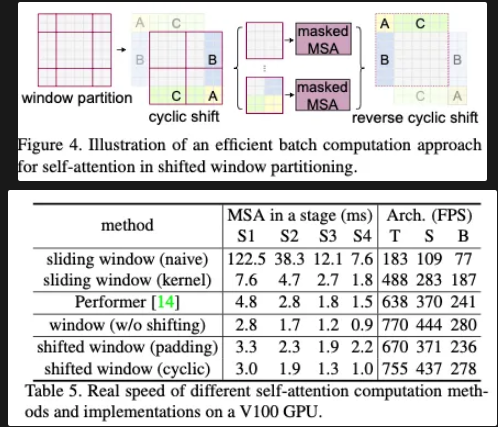
다음과 같이 cyclic-shifting을 적용하는 경우 다른 방식들 보다 더 높은 효율을 보여준다고 주장하고 있습니다.
Relative position bias
Swin Transformer는 윈도우 내부 토큰 간 self-attention을 계산할 때, 상대적 위치 바이어스(Relative Position Bias)를 추가해 이미지 상에서의 공간적 관계를 더 잘 반영합니다.
크기의 작은 행렬로 모든 가능한 상대적 위치를 파라미터화하고, 실제 self-attention에서 를 참조하여 형태의 B를 구성합니다.
이는 절대 위치 임베딩을 사용하는 것보다 성능이 우수하며, 해상도(윈도우 크기)가 달라져도 /수하 를 보간(bi-cubic interpolation)해 쉽게 재활용할 수 있습니다.
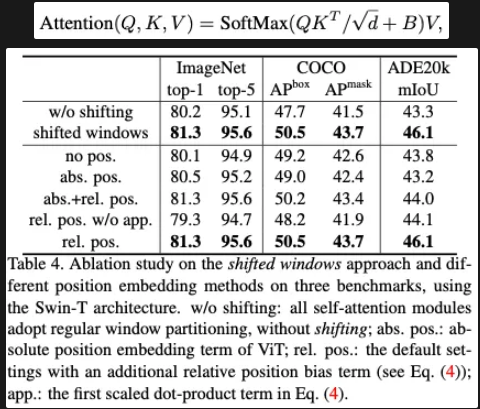
그리고 다음과 같이 다른 위치 정보를 추가하는 것 보다 더 효율적이라고 말하고 있습니다.
3.3 Architecture Variants
Swin Transformer는 모델 크기(파라미터 수)에 따라 Swin-T, Swin-S, Swin-B, Swin-L 등으로 구분됩니다. 각 모델은 채널 수(C)와 스테이지별 블록(레이어) 개수가 다릅니다. 예를 들어, Swin-T에서는 구조로 4개의 스테이지를 구성하고, Swin-B나 Swin-L로 갈수록 채널 수와 블록 수가 증가합니다. 이러한 계층적 설계를 통해 해상도를 점진적으로 줄이면서(패치 병합) 채널을 늘려, 고해상도 이미지 처리와 효율적 학습이 모두 가능해집니다

Summary
swin Transformer는 윈도우 기반의 로컬 어텐션과 Shifted Window 기법을 통해 계산 효율과 전역 문맥 파악 사이의 균형을 맞추고, Patch Merging을 통해 계층적 구조를 형성하여 다양한 비전 task 에서 우수한 성능을 보이는 모델입니다.
