✏️ 차원의 저주(The Curse of Dimensionality)란?
👉 데이터 학습을 위해 차원(변수)가 증가하면서 학습 데이터의 수가 차원의 수보다 적어져 성능이 저하되는 현상
👉 차원이 증가할 수록 개별 차원 내 학습할 데이터 수가 적어지면서 발생하는 현상
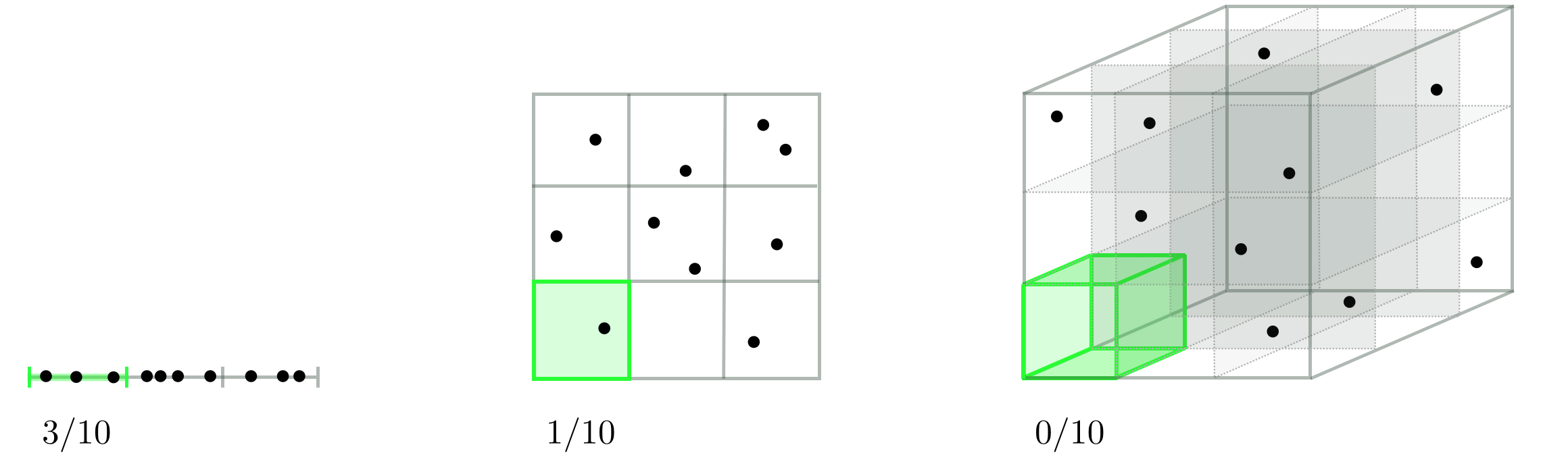
- 데이터 셋의 특성(feature)가 많아질수록, 각 feature인 하나의 차원(Dimension) 또한 증가
- 데이터의 차원이 증가할 수록 데이터 공간의 부피가 기하급수적으로 증가하기 떄문에, 데이터의 밀도가 급격히 감소
- 위 그림에서 알 수 있듯이, 차원이 증가할 수록 데이터의 밀도가 희소(sparse)해지는 것을 확인 가능
- 이는 다시 말하면, 모델이 학습을 제대로 진행하기 위해 필요한 데이터의 양이 많아진다는 것을 의미
연산비용 증가, 과적합(Overfitting) 위험 증가, 모델의 예측성능 저하
🔎 차원의 저주 해결 방법
✅ Feature Selection
👉 종속성이 강한 불필요한 특성(feature)는 제거하고, 데이터의 특징을 잘 나타내는 주요 특성(feature)만 선택
🧩 Filter, Wrapper, Embedded Method 등
❓ 더 자세한 내용은 Data_Reduction(2)_Feature Selection
✅ Feature Extraction
👉 기존 특성(feature)를 저차원의 중요 특성(feature)로 압축하여 추출하는 것
🧩 주성분분석(RCA), 선형판별분석(LDA) 등
❓ 더 자세한 내용은 Data Reduction(1)_Feature Extraction
🙏 Reference
https://lottegiantsv3.tistory.com/114
https://github.com/ExcelsiorCJH/Hands-On-ML/blob/master/Chap08-Dimensionality_Reduction/Chap08-Dimensionality_Reduction.ipynb
https://datapedia.tistory.com/15
