Lecture 13
Diagnostics for debugging learning algorithm
프로젝트를 진행하거나 프로그램을 돌리다 보면 여러가지 오류가 발생하는 경우가 많다. 프로젝트를 진행할 때 종종 ‘많은 양의 데이터를 사용하는 것이 시간을 잘 활용한다는 확신이 없다면 시간낭비를 하지 말아라’ 라는 조언을 듣기도 한다. 즉, 우리가 원하는 알고리즘을 만들기 위해서는 여러 조정 과정을 거쳐야지만 가능하다. 이번 강의는 어떤 조정방법을 써야 효율적으로 알고리즘을 최적화 할 수 있는지 알아보는 시간을 가져보고자 한다.
Debugging learning algorithms
한가지 예시를 통해 Debugging learning algorithms을 알아보도록 하자.
💡 **스팸방지 분류기 예제**스팸방지와 관련이 있는 100개의 단어 features를 사용한다.(instead of using all 50000+ words in English)
정규화된 로지스틱 회귀(Bayesian Logistc regression)를 사용한다.
이때, 허용할 수 없는 20%의 오차가 발생했다.
Fixing the learning algoritms
다음은 정규화된 로지스틱 회귀의 비용함수이다.
우리는 이러한 알고리즘을 개선하기 위해서 많은 방법을 사용한다.
- 더 많은 훈련세트를 사용한다.
- feature의 개수를 줄인다.
- feature의 개수를 늘린다.
- feature를 변경한다 Ex) Email header vs Email body
- 경사하강법을 더 많은 반복횟수로 실행한다.
- Newton’s method를 사용한다.
- 를 변경한다.
- SVM을 사용한다.
이렇게 다양한 방법이 있지만, 우리가 이중 한가지 방법을 선택하고 알고리즘을 고쳐가며 작업을 하게 된다. 정확한 방법을 알기 위해서는 위의 방법을 모두 사용해봐야 알 수 있다. 하지만 이렇게 무작위로 한가지 방법을 사용하는 것이 과연 효율적인 방법일까?? 그 답을 우리는 이번 강의에서 배워보고자 한다.
1. Diagnostics for bias vs variance
학습 알고리즘을 개발할 때 사용되는 가장 일반적인 진단이 편향과 분산 진단이다. bias가 높다면 데이터에 과소 적합하는 경향이 있고, variance가 높다면 과대 적합하는 경향이 있다. 즉 bias 와 variance를 조정하여 최적의 알고리즘을 만들어 가는 과정이 필요하다. 위의 예제를 통해 우리는 overfitting(high variance) 또는 적은 feature(high bias)로 인한 문제가 발생하였다고 충분히 의심할 수 있다.
High variance
High variance 상태에 대해 더 자세히 살표보도록 하자.
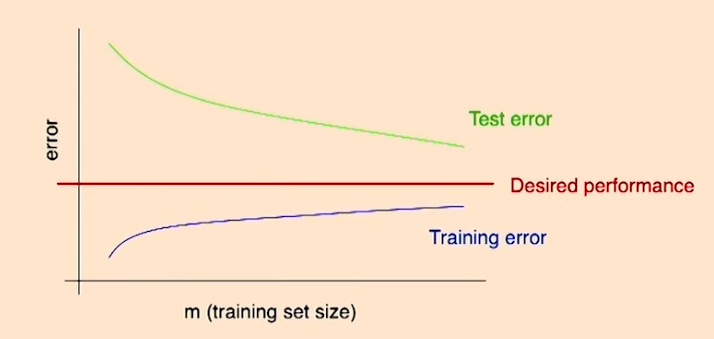
특징1
Training 단계에서는 예제가 1개가 있다면 어떠한 알고리즘 이던지 training error는 0이 될 것 이다. 하지만 training set의 크기가 매우 커지게 된다면, training error는 점점 커지게 된다. 하지만 이와 반대로 test error는 training set의 크기가 커질수록, 줄어들게 된다.
특징2
training set의 크기를 무한대로 늘릴수록, test error와 training error는 각각 감소하거나, 증가한다. 만약 training set를 무수히 많이 늘린다면, test error 와 training error가 어디로 향할지는 아무도 모른다. 따라서, 예제 수를 늘린다고 하여도 우리가 원하는 퍼포먼스를 기대할 수 없을 가능성이 있다.
High bias
다음은 high bias일때의 상황이다.
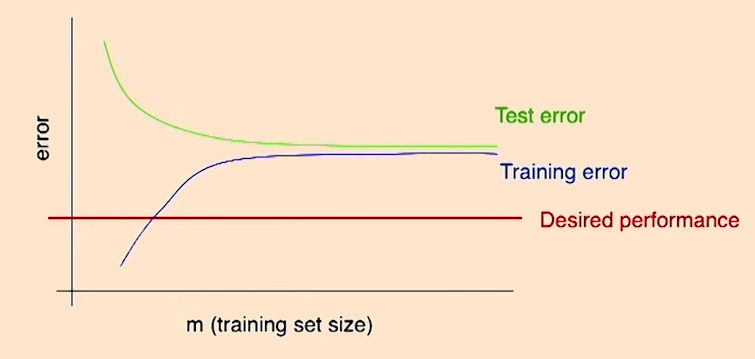
특징
high bias의 경우에는 아무리 training set의 사이즈를 늘려도, training error는 결코 줄어들지 않음을 알기 때문에, 우리가 원하는 error를 얻을 수 없게 된다.
이렇듯 training error 와 test error curve를 알게되다면, 훈련 데이터를 얻는 과정에서 많은 도움이 될 수 있다는 것을 알 수 있다.
2. Optimization algorithm diagnostics
위에서처럼 bias와 variance를 통한 진단과는 또다른 진단이 있다. 예시를 통해 자세히 알아보자.
💡 **스팸 방지 분류기 예제 2**로지스틱 회귀를 사용하면 스팸인 메일에서 2%의 오차가, 스팸이 아닌 메일에서 2%의 오차가 발생한다.(non-spam에서 2%의 오차는 허용될 수 없다.)
SVM을 사용하면 스팸인 메일에서 10%의 오차가, 스팸이 아닌 메일에서 0.01%의 오차가 발생한다.
이때, 우리는 계산하기 편리한 로지스틱 회귀를 사용하고 싶다면 어떻게 해야할까???
우리가 신경쓰고 관심있어 하는 부분은 가중치이다.
- 로지스틱 회귀에서의 비용함수
비용함수를 변경하기 위해서는 의 값을 변경하여 비용함수를 조정할 수 있다.
- SVM 에서의 비용함수
또한 비용함수 를 완전히 변경하여 C의 값으로 조정할 수도 있다.
Diagnostic
최적화 알고리즘이 문제인지 어떻게 알 수 있을까??
2가지 가능한 경우가 있다.
- 학습 알고리즘이 를 최대화 하지 않는 경우, 즉 경사상승법이 제대로 수렴하지 않는 경우이다.
- 가 최적화 하기에 잘못된 함수인 경우, 즉 가 우리가 원하는 와 너무 달라 비용함수를 최대화 하더라도 알 수 없는 경우
을 SVM을 통해 학습된 매개변수 라고 하고, 을 정규화된 로지스틱 회귀에서 학습된 매개변수라고 하자. 우리가 최종적으로 관심있어 하는 부분은 가중치 이다.
스팸 방지 분류기 예제에서 가 를 능가하기 때문에 다음과 같은 식을 쓸 수 있다.
그리고 로지스틱 회귀 비용함수에 과 을 넣어 값을 비교한다.
그렇게 되면 두가지 경우의 수가 발생하게 된다.
- case 1
BLR 은 비용함수를 최대화 시키는 것이 목적이였기 때문에 실제로 SVM의 매개변수가 BLR보다 더 최적화된 값을 찾았다는 뜻이다. 즉 알고리즘을 최적화 하는 과정에서 문제가 발생했다고 알 수 있는 것이다. 이러한 경우에는 optimization algorithm을 수정하여야 한다.
알고리즘의 문제 o 비용함수의 문제 x
- case 2
이 BLR의 비용함수를 보다 최대화 시키지만, 실제로 가중치에 대한 정확도는 SVM보다 낮다. 즉, 잘못된 비용함수 를 사용하고 있다는 것을 알 수 있다. 이러한 경우에는 optimization objective를 수정해야 한다.
알고리즘의 문제 x 비용함수의 문제 o
위에서 살펴보았던 알고리즘 개선 방법들이 어떤 범주에 있는지 확인해보자.
- 더 많은 훈련세트를 사용한다. →Fixes high variance
- feature의 개수를 줄인다. →Fixes high variance
- feature의 개수를 늘린다. →Fixes high bias
- feature를 변경한다 Ex) Email header vs Email body →Fixes high bias
- 경사하강법을 더 많은 반복횟수로 실행한다. →Fixes optimzation algorithm
- Newton’s method를 사용한다. →Fixes optimzation algorithm
- 를 변경한다. →Fixes optimzation objective
- SVM을 사용한다. →Fixes optimzation objective
Debigging an RL algorithm
또다른 예제를 통해 어떤 과정으로 debugging 하는지 알아보도록 하자.

-
헬리콥터 시뮬레이터를 만든다.
-
비용함수를 선택한다.
이때 비용함수 -
강화학습을 헬리콥터 시뮬레이터를 통해 진행하여 비용함수를 최소화 시킨다.
-
이렇게 얻은 매개변수 은 인간의 조종보다 훨씬 떨어지는 성능을 가지고 있다.
우리가 원하고자 하는것은 이 실제 상황에서 잘 작동하는 것이다. 그러기 위해서는 위에서 사용했던 workflow를 사용하면 된다.
- 만약 가 시뮬레이터에서 잘 작동하지만, 현실에서는 작동하지 않는다면, 문데는 시뮬레이터에 있다.
- 만약 이라면, 비용함수는 최소화 시키는게 목적이기 때문에, 비용함수는 적상적으로 작동한 것이기 때문에, 문제는 강화학습 알고리즘의 문제이다.
- 만약 이라면, 비용함수가 제대로 작동하지 않다는 뜻이다. 즉 비용함수를 대체해야 한다.
이렇게 다음과 같은 workflow를 사용하게 된다면, 시간을 절역하며 효율적으로 알고리즘을 debugging 할 수 있게 된다.
Error analysis
앞서 살펴보았던 진단들 외에도 학습 알고리즘을 디버깅하는 유용한 방법중 하나가 error analysis 이다. error analysis는 학습 알고리즘에서 무엇이 작동하는지, 무엇이 작동하지 않는지 파악할 수 있는 방법이다. 예제를 통해 알아보도록 하자.
💡 **보안 시스템 예제**얼굴인식 알고리즘을 구현하여 보안 시스템을 구축하려고 한다.
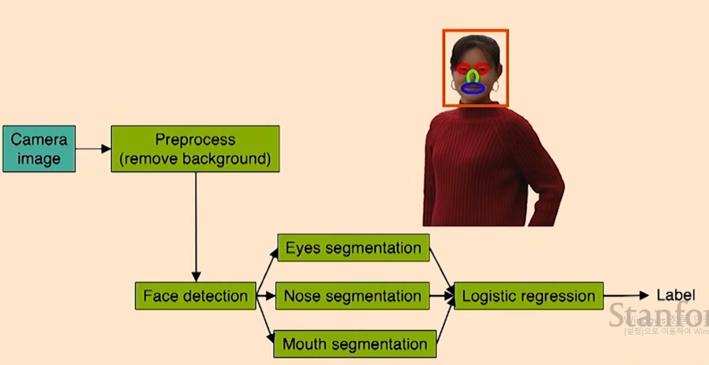
다음과 같이 파이프라인이 형성되고 나면, 각 과정에서의 정확도를 측정한다.
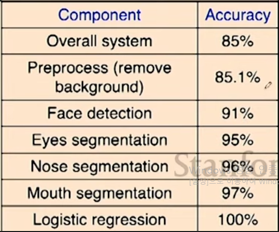
이렇게 정확도를 측정하면, 어떤 과정이 가장 중요한지 알 수 있다. 이번 예제의 경우에는 face detection과 eyes segment가 중요하다는 것을 알 수 있다.
