
시작하기 전에 import 하기
import numpy as np import pandas as pd import numba
값 기준 정렬 (sort_values)
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
개요
sort_values 메서드는 값을 기준으로 레이블을 정렬하는 메서드입니다.
사용법
기본 사용법
df.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
by : 정렬 기준이될 레이블입니다.
axis : {0 : index / 1: columns} 정렬할 레이블입니다. 0이면 행, 1이면 열을 기준으로 정렬합니다.
inplace : 원본을 대체할지 여부입니다. True일 경우 원본을 대체하게 됩니다.
kind : 알고리즘 모드 입니다. 모드는 총 4종으로 quicksort, mergesort, heapsort, stable이 있는데,
속도와 효율성의 차이를 갖습니다. 기본적으로 quicksort이며, 자세한건 numpy doc에서 확인 가능합니다.
na_position : {first / last} Na값의 위치입니다. 기본값은 last로 정렬시 맨 뒤에 위치합니다.
ignore_index : 인덱스의 무시 여부입니다. True일 경우 인덱스의 순서와 상관없이 0,1,2,... 로 정해집니다.
key : 이 인수를 통해 정렬방식으로 함수를 사용할 수 있습니다. lamba의 사용이 가능합니다.
예시
먼저 np.nan이 포함된 간단한 5x3짜리 데이터를 만들어보겠습니다.
na = np.nan data = [[-3,'A',17], [na,'D',31], [ 7,'D',-8], [15,'Z', 3], [ 0, na,-7]] col = ['col1','col2','col3'] row = ['row1','row2','row3','row4','row5'] df = pd.DataFrame(data = data, index = row, columns= col) print(df)
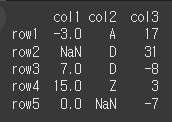
기본적인 사용법
정렬의 기준이 되는 by에는 레이블명이 되는 str이 올수도 있고, 레이블명들의 list가 올 수 있습니다.
list형태가 올 경우, 첫 값부터 정렬합니다.
(실행 예시1)print(df.sort_values(by='col3'))
(실행 예시2)print(df.sort_values(by=['col2','col3']))
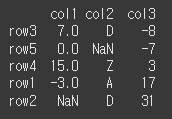
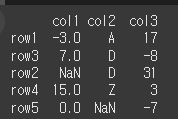
axis인수의 사용
axis인수를 사용하여 어떤축을 기준으로 정렬할지 설정이 가능합니다.
단, 문자와 숫자의 혼용시 오류가 발생합니다. ※ Na는 무시됩니다.
열 기준 col3으로 오름차순 정렬print(df.sort_values(by='col3',axis=0))

행 기준 row1의 오름차순 정렬. 문자와 숫자의 혼용으로 오류가 발생합니다.
print(df.sort_values(by='row1',axis=1))
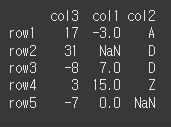
행 기준 row5의 오름차순 정렬. 문자와 NaN의 혼용이기 때문에 정상적으로 정렬됩니다.
print(df.sort_values(by='row5',axis=1))
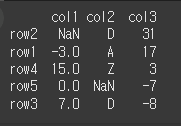
ascending인수의 사용
ascending인수를 이용하여 오름차순과 내림차순을 설정할 수 있습니다.
기본값은 True로 오름차순입니다. 내림차순의 경우 False로 아래와 같습니다.print(df.sort_values(by='col3',ascending=False))
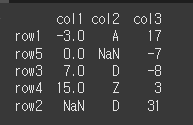
na_position인수의 사용
na_position인수를 이용하여 결측값의 위치를 지정할 수 있습니다.
결측값이 맨 뒤(기본값)print(df.sort_values(by='col1',na_position='last'))
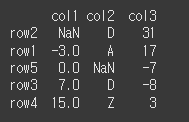
결측값이 맨 앞
print(df.sort_values(by='col1',na_position='first'))
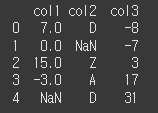
ignore_index인수의 사용
ignore_index인수를 사용하여 인덱스를 미사용 할 수 있습니다. 어떤식으로 정렬 되더라도
인덱스는 0, 1, 2, 3, ... 순서로 표시됩니다.print(df.sort_values(by='col3',ignore_index=True))
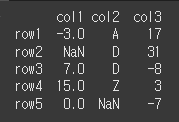
key인수의 사용
key인수를 사용하여 정렬에 함수를 이용할 수 있습니다print(df.sort_values(by='col2',key=lambda col: col.str.lower()))
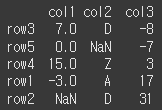
inplcae 인수의 사용
inplace 인수를 사용해서 원본을 대체할지의 여부를 설정 ㄱㄴdf.sort_values(by='col3',inplace=True) print(df) #그냥 df를 출력함해서 원본 확인 ㄱㄴ
인덱스 기준 정렬 (sort_index)
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None)
개요
sort_index 메서드는 인덱스를 기준으로 레이블을 정렬하는 메서드입니다.
사용법
기본 사용법
df.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None)
axis : {0 : index / 1: columns} 정렬할 레이블입니다. 0이면 행, 1이면 열을 기준으로 정렬합니다.
level : multi index의 경우 정렬을 진행할 level입니다.
ascending : 오름차순으로할지 여부 입니다. 기본은 True로 오름차순입니다.
inplace : 원본을 대체할지 여부입니다. True일 경우 원본을 대체하게 됩니다.
kind : 알고리즘 모드 입니다. 모드는 총 4종으로 quicksort, mergesort, heapsort, stable이 있는데,
속도와 효율성의 차이를 갖습니다. 기본적으로 quicksort이며, 자세한건 numpy doc에서 확인 가능합니다.
na_position : {first / last} Na값의 위치입니다. 기본값은 last로 정렬시 맨 뒤에 위치합니다.
sort_remaining : multi index의 경우 다른 레벨에 대해서도 정렬을할지 여부입니다. True로 할 경우
한 레벨에 대한 정렬이 완료되면, 다른 레벨도 정렬합니다.
ignore_index : 인덱스의 무시 여부입니다. True일 경우 인덱스의 순서와 상관없이 0,1,2,... 로 정해집니다.
예시
na_position, ignore_index, inplace, key인수의 경우 sort_value와 사용이 동일하므로 참고 바랍니다.
na_position, ignore_index는 multi index에서 작동하지 않습니다.
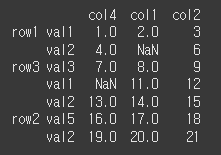
먼저 np.NaN이 포함된 간단한 multi index 데이터를 만들어보겠습니다.na = np.nan index_tuples = [('row1', 'val1'), ('row1', 'val2'), ('row3', 'val3'), ('row3', 'val1'), ('row3', 'val2'), ('row2', 'val5'),('row2', 'val2')] values = [ [1,2,3], [4,na,6], [7,8,9], [na,11,12], [13,14,15], [16,17,18], [19,20,21]] index = pd.MultiIndex.from_tuples(index_tuples) # 인덱스 설정 df = pd.DataFrame(values, columns=['col4', 'col1', 'col2'], index = index) print(df)
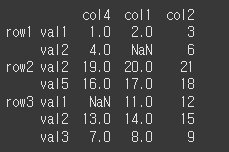
level의 지정
level을 지정하므로써 해당 level에서의 정렬이 가능합니다.
level이 0인 경우 row기준으로 정렬되는것을 확인 할 수 있습니다.print(df.sort_index(axis=0, level=0))
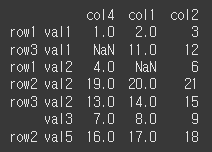
level이 1인 경우 val기준으로 정렬되는것을 확인 할 수 있습니다.
print(df.sort_index(axis=0, level=1))
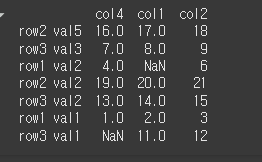
level별 ascending의 병용
level과 ascending의 값을 list형태로 입력하므로써, 각 level에 다른 정렬방식의 사용이 가능합니다.
level이 1인 val이 내림차순 정렬되고, level이 0인 row가 오름차순 정렬된것을 확인 할 수 있습니다.print(df.sort_index(axis=0, level=[1,0],ascending=[False,True]))
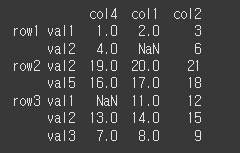
sort_remaining 인수의 사용
multi index에서 sort_remaining인수를 True로 할 경우 level별로 순차적으로 정렬이 진행됩니다.
만약 level을 따로 지정했다면, 해당 level부터 정렬한 후 나머지 level을 순차적으로 정렬합니다.
row정렬 후 val의 정렬까지 완료된 것을 확인할 수 있습니다.print(df.sort_index(axis=0, sort_remaining=True))
정렬후 추출 (nlargest, nsmallest)
DataFrame.nlargest(n, columns, keep='first')
DataFrame.nsmallest(n, columns, keep='first')
개요
nlargest메서드와 nsmallest메서드는 데이터를 오름차순/내림차순 정렬 후, 위에서 n개의 행을 출력하는 메서들입니다.
사실상 df.sort_values(columns, ascending=True/False).head(n)와 사용방식이 완전히 동일합니다.
사용법
기본 사용법
df.nlargest(n, columns, keep='first')
df.nsmallest(n, columns, keep='first')
n : 정렬 후 출력할 행의 수 입니다.
columns : 정렬의 기준이 될 열 입니다.
keep :{first, last, all} 동일한 값일경우 어느 행을 출력할지 정합니다. first면 위부터, last면 아래부터, all이면 모두 출력합니다.
예시
nlargest와 nsmallest는 사용방식이 완전히 동일하므로, nlargest 예시만 진행하겠습니다.
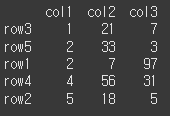
먼저 간단한 5x3짜리 DataFrame를 생성해보겠습니다.col = ['col1','col2','col3'] row = ['row3','row5','row1','row4','row2'] data = [[ 1, 21, 7], [ 2, 33, 3], [ 2, 7,97], [ 4, 56,31], [ 5, 18, 5]] df = pd.DataFrame(data=data, index=row, columns=col) print(df)
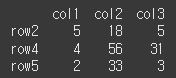
keep 인수의 사용
keep인수를 통해 중복일경우의 출력할 행을 지정할 수 있습니다.
처음 발생한 값부터 출력(위쪽값 출력)print(df.nlargest(n=3,columns='col1',keep='first'))
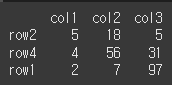
마지막에 발생한 값부터 출력(아래쪽 값 출력)
print(df.nlargest(n=3,columns='col1',keep='last'))
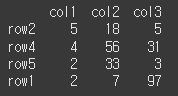
중복값 모두 출력
print(df.nlargest(n=3,columns='col1',keep='all'))
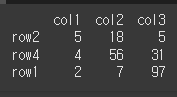
여러 열을 동시에 고려하여 정렬
여러 열을 동시에 고려하여 정렬하고자 한다면 list를 사용하면됩니다.
col1과 col3 모두에서 큰 값 기준 정렬할 경우 아래와 같습니다.print(df.nlargest(n=3,columns=['col1','col3']))
