
시작하기 전에 import 하기
import numpy as np import pandas as pd
덧셈 (add, radd)
add함수는 DataFrame에 다른 데이터프레임이나, Series, 스칼라 등 데이터를 더하는 메서드입니다.
단순 df + 다른df 등의 계산과 차별화되는 것은 fill_value 인수를 통해 계산 불가한 값을 채워 넣는다는 것입니다.
radd의 경우 add의 경우에서 순서만 바꾼것입니다. 즉 add가 'df+df2'라면 radd는 'df2+df'입니다.
add와 사용법이 동일하므로 예시는 생략합니다
사용법
기본 사용법
df.add(other, axis='columns', level=None, fill_value=None)
other : 데이터프레임이나, Series, 스칼라 등 데이터가 올 수 있습니다. 더할 값입니다.
axis : 더할 레이블을 설정합니다. 0은 행(index), 1은 열 입니다. ※Series일 경우 Index와 일치시킬 축
level : multiIndex에서 계산할 Index의 레벨입니다.
fill_value : NaN 값등의 누락 요소를 계산 전에 이 값으로 대체합니다.
예시
먼저, 간단한 3x3 짜리 DataFrame을 만들어 보겠습니다.
data = [[1,10,100],[2,20,200],[3,30,300]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) print(df)
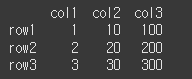
스칼라 값 더하기
(예시 1)
df.add(스칼라 값)의 경우 df+스칼라값 과 같은 결과를 가집니다.
data = [[1,10,100],[2,20,200],[3,30,300]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) result = df.add(1) print(result)(예시 2)
result = df+1 print(result)실행 결과는 똑같다
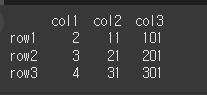
다른 DataFrame객체를 더하기
df에 더할 df2를 아래와 같이 만들어보겠습니다. 3x1 짜리 객체로 col1을 가집니다.
(예시 1)data2 = [[3],[4],[5]] df2 = pd.DataFrame(data=data2,index=['row1','row2','row3'],columns=['col1']) print(df2)
(예시 2)
이제 df에 df2를 add메서드를 통해 더해보겠습니다.
df2에는 col2과 col3열이 없기 때문에 해당 열의 계산결과는 NaN으로 반환됩니다.data2 = [[3],[4],[5]] df2 = pd.DataFrame(data=data2,index=['row1','row2','row3'],columns=['col1']) result = df.add(df2) print(result)
(예시 3)
fill_value 인수를 통해 해당 오류를 출력 가능하도록 바꿔보도록 하겠습니다.data2 = [[3],[4],[5]] df2 = pd.DataFrame(data=data2,index=['row1','row2','row3'],columns=['col1']) result = df.add(df2,fill_value=0) print(result)df2에는 존재하지 않던 col2, col3의 요소들에 대해 fill_value값인 0으로 채워 넣은 뒤 계산을 진행하여
계산한 것을 확인할 수 있습니다.
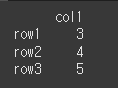
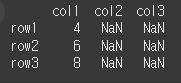
뺄셈 (sub, rsub)
sub함수는 DataFrame에 다른 데이터프레임이나, Series, 스칼라 등 데이터를 빼는 메서드입니다.
단순 df - 다른df 등의 계산과 차별화되는 것은fill_value 인수를 통해 계산 불가한 값을 채워 넣는다는 것입니다.
rsub의 경우 sub의 경우에서 순서만 바꾼것입니다. 즉 sub가 'df-df2'라면 rsub는 'df2-df'입니다.
sub와 사용법이 동일하므로 예시는 생략합니다.
사용법
기본 사용법
df.sub(other, axis='columns', level=None, fill_value=None)
other : 데이터프레임이나, Series, 스칼라 등 데이터가 올 수 있습니다. 뺄 값입니다.
axis : 뺄 레이블을 설정합니다. 0은 행(index), 1은 열 입니다. ※Series일 경우 Index와 일치시킬 축
level : multiIndex에서 계산할 Index의 레벨입니다.
fill_value : NaN 값등의 누락 요소를 계산 전에 이 값으로 대체합니다.
예시
먼저, 간단한 3x3 짜리 DataFrame을 만들어 보겠습니다.
data = [[1,10,100],[2,20,200],[3,30,300]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) print(df)
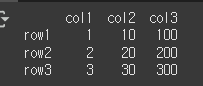
스칼라 값 빼기
df.sub(스칼라 값)의 경우 df-스칼라값 과 같은 결과를 가집니다.
result = df.sub(1) print(result)
곱셈 (mul, rmul)
mul함수는 DataFrame에 다른 데이터프레임이나, Series, 스칼라 등 데이터를 곱하는 메서드입니다.
단순 df 다른df 등의 계산과 차별화되는 것은 fill_value 인수를 통해 계산 불가한 값을 채워 넣는다는 것입니다.
rmul의 경우 mul의 경우에서 순서만 바꾼것입니다. 즉 mul이 'df df2'라면 rmul는 'df2 * df'입니다.
mul과 사용법이 동일하므로 예시는 생략합니다.
사용법
기본 사용법
df.mul(other, axis='columns', level=None, fill_value=None)
other : 데이터프레임이나, Series, 스칼라 등 데이터가 올 수 있습니다. 곱할 값입니다.
axis : 곱할 레이블을 설정합니다. 0은 행(index), 1은 열 입니다. ※Series일 경우 Index와 일치시킬 축
level : multiIndex에서 계산할 Index의 레벨입니다.
fill_value : NaN 값등의 누락 요소를 계산 전에 이 값으로 대체합니다.
예시
먼저, 간단한 3x3 짜리 DataFrame을 만들어 보겠습니다.
data = [[1,10,100],[2,20,200],[3,30,300]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) print(df)
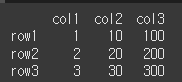
스칼라 값 곱하기
df.mul(스칼라 값)의 경우 df * 스칼라값 과 같은 결과를 가집니다.
result = df.mul(2) print(result)
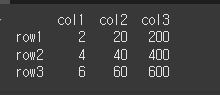
다른 DataFrame객체를 곱하기
df에 곱할 df2를 아래와 같이 만들어보겠습니다. 3x1 짜리 객체로 col1을 가집니다.
data2 = [[3],[4],[5]] df2 = pd.DataFrame(data=data2,index=['row1','row2','row3'],columns=['col1']) print(df2)
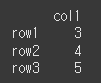
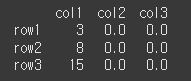
fill_value 인수를 통해 해당 오류를 출력 가능하도록 바꿔보도록 하겠습니다.
data2 = [[3],[4],[5]] df2 = pd.DataFrame(data=data2,index=['row1','row2','row3'],columns=['col1']) result = df.mul(df2,fill_value=0) print(result)
나눗셈 (div, rdiv)
div함수는 DataFrame에 다른 데이터프레임이나, Series, 스칼라 등 데이터를 나누는 메서드입니다.
단순 df÷다른df 등의 계산과 차별화되는 것은 fill_value 인수를 통해 계산 불가한 값을 채워 넣는다는 것입니다.
rdiv의 경우 div의 경우에서 순서만 바꾼것입니다. 즉 div가 'df ÷ df2'라면 rdiv는 'df2 ÷ df'입니다.
div와 사용법이 동일하므로 예시는 생략합니다.
사용법
기본 사용법
df.div(other, axis='columns', level=None, fill_value=None)
other : 데이터프레임이나, Series, 스칼라 등 데이터가 올 수 있습니다. 나눌값입니다.
axis : 나눌 레이블을 설정합니다. 0은 행(index), 1은 열 입니다. ※Series일 경우 Index와 일치시킬 축
level : multiIndex에서 계산할 Index의 레벨입니다.
fill_value : NaN 값등의 누락 요소를 계산 전에 이 값으로 대체합니다.
예시
먼저, 간단한 3x3 짜리 DataFrame을 만들어 보겠습니다.
data = [[1,10,100],[2,20,200],[3,30,300]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) print(df)
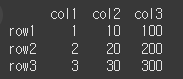
스칼라 값 나누기
result = df.div(2)
print(result)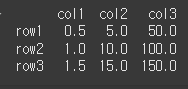
다른 DataFrame객체를 나누기
df에 나눌 df2를 아래와 같이 만들어보겠습니다. 3x1 짜리 객체로 col1을 가집니다.
data2 = [[0],[2],[3]] df2 = pd.DataFrame(data=data2,index=['row1','row2','row3'],columns=['col1']) print(df2)
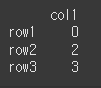
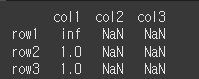
이제 df에 df2를 div메서드를 통해 나눠보겠습니다.
df2에는 col2과 col3열이 없기 때문에 해당 열의 계산결과는 NaN으로 반환됩니다.
0으로 나눈 경우는 div/0 에러 대신 inf를 반환합니다.result = df.div(df2) print(result)
나머지 (mod, rmod)
mod함수는 DataFrame에 다른 데이터프레임이나, Series, 스칼라 등 데이터를 나눴을때의 나머지를 반환하는 메서드입니다.
% 연산과 동일합니다.
단순 df % 다른df 등의 계산과 차별화되는 것은 fill_value 인수를 통해 계산 불가한 값을 채워 넣는다는 것입니다.
rmod의 경우 mod의 경우에서 순서만 바꾼것입니다. 즉 mod가 'df % df2'라면 rmod는 'df2 % df'입니다.
mod와 사용법이 동일하므로 예시는 생략합니다.
사용법
기본 사용법
df.mod(other, axis='columns', level=None, fill_value=None)
other : 데이터프레임이나, Series, 스칼라 등 데이터가 올 수 있습니다. 나눌값입니다.
axis : 나눌 레이블을 설정합니다. 0은 행(index), 1은 열 입니다. ※Series일 경우 Index와 일치시킬 축
level : multiIndex에서 계산할 Index의 레벨입니다.
fill_value : NaN 값등의 누락 요소를 계산 전에 이 값으로 대체합니다.
예시
먼저, 간단한 3x3 짜리 DataFrame을 만들어 보겠습니다.
data = [[1,2,3],[4,5,6],[7,8,9]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) print(df)
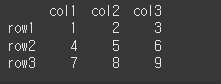
스칼라 값 나누기
df.div(스칼라 값)의 경우 df % 스칼라값 과 같은 결과를 가집니다.
result = df.mod(7) print(result)
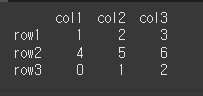
다른 DataFrame객체를 나누기
df에 나눌 df2를 아래와 같이 만들어보겠습니다. 3x1 짜리 객체로 col1을 가집니다.
data2 = [[2],[3],[5]] df2 = pd.DataFrame(data=data2,index=['row1','row2','row3'],columns=['col1']) print(df2)
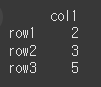
fill_value 인수를 통해 해당 오류를 출력 가능하도록 바꿔보도록 하겠습니다.
result = df.mod(df2,fill_value=1) print(result)
거듭제곱 (pow, rpow)
pow함수는 DataFrame에 다른 데이터프레임이나, Series, 스칼라 등 데이터를 거듭제곱 합니다.
연산과 동일합니다.
단순 df 다른 df 등의 계산과 차별화되는 것은 fill_value 인수를 통해 계산 불가한 값을 채워 넣는다는 것입니다.
rpow의 경우 pow의 경우에서 순서만 바꾼것입니다. 즉 pow가 'df df2'라면 rpow는 'df2 df'입니다.
pow와 사용법이 동일하므로 예시는 생략합니다.
사용법
기본 사용법
df.pow(other, axis='columns', level=None, fill_value=None)
other : 데이터프레임이나, Series, 스칼라 등 데이터가 올 수 있습니다. 제곱할 값입니다.
axis : 제곱할 레이블을 설정합니다. 0은 행(index), 1은 열 입니다. ※Series일 경우 Index와 일치시킬 축
level : multiIndex에서 계산할 Index의 레벨입니다.
fill_value : NaN 값등의 누락 요소를 계산 전에 이 값으로 대체합니다.
예시
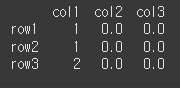
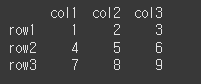
먼저, 간단한 3x3 짜리 DataFrame을 만들어 보겠습니다.
data = [[1,2,3],[4,5,6],[7,8,9]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) print(df)
스칼라 값 제곱하기
result = df.pow(3)
print(result)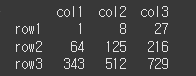
다른 DataFrame객체를 제곱하기
df에 제곱할 df2를 아래와 같이 만들어보겠습니다. 3x1 짜리 객체로 col1을 가집니다.
data2 = [[0],[3],[5]] df2 = pd.DataFrame(data=data2,index=['row1','row2','row3'],columns=['col1']) print(df2)
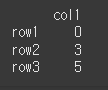
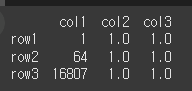
fill_value 인수를 통해 해당 오류를 출력 가능하도록 바꿔보도록 하겠습니다.
result = df.pow(df2,fill_value=0) print(result)
오칙연산은 다른게 add, sub 이런 것이기 떄문에 넘어감
행렬곱 (dot)
두 객체간의 행렬곱을 계산합니다.

사용법
기본 사용법
df.dot(other)
other : Series, DataFrame, 배열 등이 올 수 있습니다.
예시
먼저, 간단한 2x2 짜리 DataFrame을 두개 만들어 보겠습니다.
col = ['col1','col2'] row = ['row1','row2'] data1 = [[1,2],[3,4]] data2 = [[5,6],[7,8]] df1 = pd.DataFrame(data=data1) df2 = pd.DataFrame(data=data2) print(df1)

