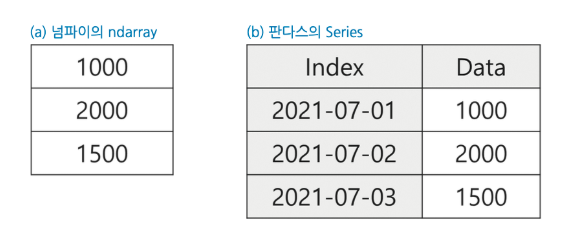
판다스 시리즈
판다스(Pandas)는 데이터 수집 및 데이터 전처리를 위한 다양한 편의 기능을 지원하며, 그 편의성으로 인해 데이터 분석 분야에서 널리 사용됩니다. 넘파이를 확장해서 만든 판다스는 일차원 데이터를 위한 시리즈(Series)와 이차원 데이터를 위한 데이터프레임(DataFrame)의 핵심 자료 구조로 구성돼 있습니다.
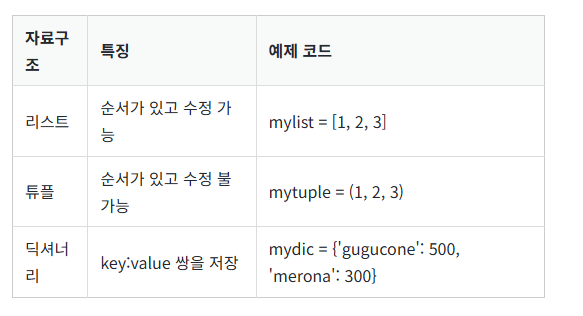
넘파이와 시리즈의 차이
시리즈를 사용하기 위해서는 먼저 Series 클래스를 import 해야 합니다. 참고로 판다스 라이브러리에서 시리즈를 임포트하는 방식은 표 3.1.2과 같이 크게 네 가지가 있습니다. 많은 사람이 두 번째와 네 번째 방식을 사용하기 때문에 본 도서에서도 두 가지를 혼용하겠습니다. Series의 'S'가 대문자임을 주의하세요. 일반적으로 파이썬에서 클래스는 파스칼 표기법(Pascal case)을 사용해서 단어의 시작을 대문자로 표기합니다. 두 개의 단어가 조합되면 각 단어의 시작을 대문자로 구분하는 겁니다. ThisIsClass 이런 식으로요.
임포트 방식
웬만하면 4번째꺼를 많이 사용

시리즈 생성
리스트와 튜플의 장점을 섞어 놓은 것과 같이 동작하는 시리즈에 대해 본격적으로 배워 보겠습니다. 시리즈 객체를 생성하려면 데이터를 파이썬 리스트로 표현한 후 리스트 객체를 초기화자 의 인자로 넘겨줘야 합니다
모듈 import하기
from pandas import Series(사용 예시1)
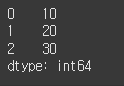
from pandas import Series # Series를 사용하기 위해 모듈을 import합니다. data = [10, 20, 30] s = Series(data) # 데이터를 파이썬 리스트로 저장합니다. print(s) # 시리즈 객체를 생성합니다. # 이때 data라는 변수가 바인딩하는 파이썬 리스트가 초기화자의 인자로 전달됩니다.
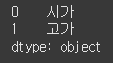
(사용 예시2)data = ["시가", "고가"] s = Series(data) print(s)
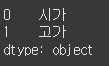
시리즈 인덱스
파이썬의 딕셔너리를 사용하면 데이터에 레이블을 붙여서 저장할 수 있는 것처럼 시리즈도 각 데이터에 인덱스를 설정할 수 있습니다. 인덱스의 설정을 하지 않으면, 0부터 시작하는 숫자 값을 RangeIndex 타입으로 생성합니다.
시리즈를 만들고 인덱스를 얻어와 보겠습니다.data = [1000, 2000, 3000] s = Series(data) print(s.index) print(s.index.to_list())

시리즈 객체를 생성한 후에 인덱스를 수정할 수 있습니다.
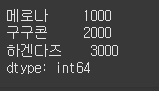
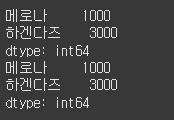
data = [1000, 2000, 3000] s = Series(data) s.index = ["메로나", "구구콘", "하겐다즈"] print(s)
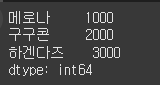
이번에는 시리즈를 생성할 때 인덱스를 같이 지정해 보겠습니다.
data = [1000, 2000, 3000] # 시리즈에 저장될 데이터를 리스트로 정의합니다. index = ["메로나", "구구콘", "하겐다즈"] # 시리즈에 저장될 인덱스를 리스트로 정의합니다. s = Series(data, index) print(s) # 시리즈를 생성할 때 데이터와 인덱스를 차례로 전달합니다.
keyword argument
s = Series(data, index) s = Series(data, index=index) s = Series(data=data, index=index) s = Series(index=index, data=data)
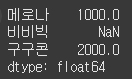
reindex 메서드를 사용하면 인자로 전달한 새로운 값으로 맞춰 인덱스를 변경합니다. 이때 기존에 있던 인덱스는 기존 값을 그대로 사용하고, 새로운 인덱스에는 NaN 값을 채웁니다.
(사용 예시)data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) s2 = s.reindex(["메로나", "비비빅", "구구콘"]) print(s2)
이제 실전 데이터를 사용해보기
(실행 예시)
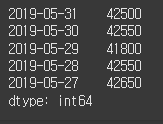
price = [42500, 42550, 41800, 42550, 42650] # 종가를 파이썬 리스트로 저장합니다. data = ["2019-05-31", "2019-05-30", "2019-05-29", "2019-05-28", "2019-05-27"] # 각 거래일의 날짜를 문자열로 표현한 후 이를 리스트에 저장합니다. s = Series(price, data) # 시리즈 객체를 생성합니다. 이때 데이터와 인덱스를 지정합니다. print(s)
딕셔너리를 사용해서 시리즈를 한 번에 만들 수도 있습니다.
(실행 예시)data = { "2019-05-31" : 42500, "2019-05-30" : 42550, "2019-05-29" : 41800, "2019-05-28" : 42550, "2019-05-27" : 42650 } s = Series(data) print(s)
시리즈 인덱싱
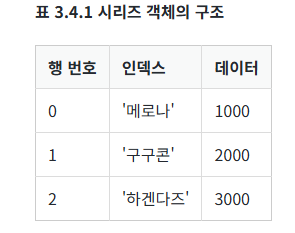
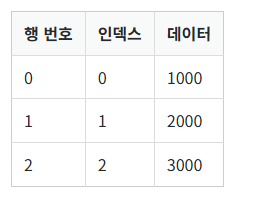
자료구조에서 하나의 값에 접근하는 것을 인덱싱이라고 합니다. 리스트는 인덱스로만 인덱싱을 했다면 시리즈는 행 번호와 인덱스를 사용해서 인덱싱을 할 수 있습니다. 시리즈 객체는 생성될 때 인덱스 이외에도 표 3.4.1과 같이 행 번호(row number)가 자동으로 부여됩니다. 눈에 보이지 않지만 내부적으로 부여되는 번호라고 생각하면 쉽습니다. 시리즈 객체는 행 번호와 인덱스가 존재하기 때문에 두 가지 방법으로 인덱싱할 수 있습니다. 시리즈 객체의 행 번호를 사용해서 인덱싱할 때 iloc 연산(속성)을, 인덱스를 사용할 때 loc 연산을 사용합니다.
(예제 1)
우선 iloc 연산을 사용해서 행 번호로 인덱싱해 봅시다.data = [1000, 2000, 3000] s = Series(data=data) print(s.iloc[0]) # 행 번호 0의 데이터를 출력합니다. print(s.iloc[1]) # 행 번호 1의 데이터를 출력합니다. print(s.iloc[2]) # 행 번호 2의 데이터를 출력합니다. print(s.iloc[-1]) # 행 번호 -1의 위치의 데이터인 3000을 출력합니다.앞서 시리즈 객체는 인덱스를 지정하지 않으면 자동으로 생성된 정수 인덱스(RangeIndex 타입)가 지정됨을 배웠습니다. 위 코드에서 시리즈 객체 s는 표 3.4.2과 같은 구조를 갖습니다. 행 번호와 인덱스가 모두 정수 값입니다.
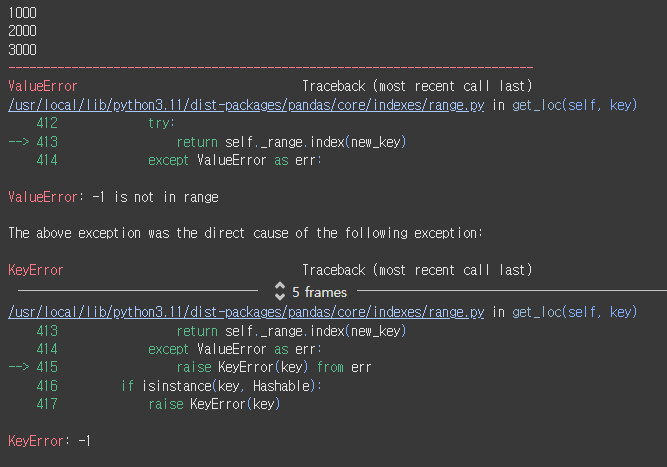
(실행 예시)data = [1000, 2000, 3000] s = Series(data=data) print(s.loc[0]) print(s.loc[1]) print(s.loc[2]) print(s.loc[-1]) # 에러
이렇게 에러가 발생한다
loc와 iloc라는 두 가지 연산이 왜 존재할까요?
그렇다면 왜 loc와 iloc라는 두 가지 연산이 존재할까요? 데이터를 인덱싱할 때 loc를 사용하는 경우가 더 편리한 경우도 있고 반대로 iloc를 사용하는 경우가 더 편리한 경우도 있기 때문입니다.
(예제 2)
(실행 예시)data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) print(s.iloc[0]) print(s.loc['메로나'])

시리즈 슬라이싱
파이썬 자료구조에서 연속적인 범위의 값을 가져오고자 할 때 슬라이싱을 사용했습니다. 예를 들어 data라는 파이썬 리스트에서 0번과 1번 위치의 연속된 값을 슬라이싱하려면 data[0:2]라고 표현했습니다. 시리즈 객체도 슬라이싱 할 수 있는데, 이때에도 iloc 나 loc 연산 또는 '[ ]' 기호를 사용합니다. 우선 iloc 연산을 사용해서 슬라이싱해 봅시다. iloc[시작 행 번호:끝 행 번호]와 같이 시작과 끝으로 사용할 두 개의 행 번호를 입력합니다.
(실행 예시 1)
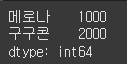
data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) s = Series(data=data, index=index) print(s.iloc[0:2])
이번에는 loc 연산을 사용해서 메로나에서 구구콘까지를 슬라이싱 해보겠습니다. loc 연산이므로 인덱스를 사용해서 loc[시작 인덱스:끝 인덱스]로 표현합니다.
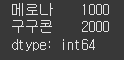
(실행 예시 2)data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) print(s.loc['메로나':'구구콘'])
시리즈 객체는 파이썬 리스트와 달리 연속적이지 않은 값들에 대해서도 슬라이싱 할 수 있습니다. 접근하고자 하는 데이터의 행 번호나 인덱스를 리스트로 표현한 후 iloc나 loc 연산에서 리스트를 사용한 슬라이싱을 적용하면 됩니다.
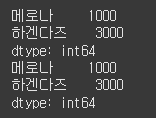
(실행 예시 3)data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) indice = [0, 2] # 행 번호를 의미하는 0번과 2번을 리스트로 저장합니다. print(s.iloc[indice]) # 리스트에는 인덱스가 저장돼 있으므로 iloc로 슬라이싱합니다. print(s.iloc[ [0,2] ]) # 라인5, 라인6의 코드는 간단하기 때문에 한 줄로 표현할 수 있습니다. 대괄호가 중첩해서 사용돼 이상해 보일 수 있지만, 이는 판다스 시리즈의 올바른 문법입니다. 바깥쪽의 대괄호는 인덱싱 기호로, 안쪽의 대괄호는 리스트 기호입니다.
iloc 뿐만 아니라 loc를 사용해서 불연속적인 데이터를 슬라이싱 할 수 있습니다. 리스트에 문자열 인덱스를 저장하고, loc 연산으로 슬라이싱합니다.data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) indice = ["메로나", "하겐다즈"] print(s.loc[ indice ]) print(s.loc[ ["메로나", "하겐다즈"]])
시리즈 수정/추가/삭제
이번에는 시리즈 객체의 값을 수정, 추가, 삭제해보겠습니다. 시리즈의 수정은 loc 혹은 iloc로 특정 위치에 접근한 뒤 변경할 값을 넣어주면 됩니다. 다음 코드는 메로나 인덱스에 저장된 1000이라는 값을 500으로 변경합니다. 킷값을 사용하는 딕셔너리와 유사한 형태입니다.
추가하는 방법
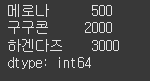
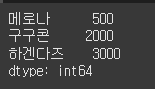
(실행 예시 1) (loc 사용)data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) s.loc['메로나'] = 500 print(s)
(실행 예시 2) (iloc 사용)data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) s.iloc[0] = 500 s['메로나'] = 500 print(s)
삭제하는 방법
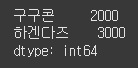
(실행 예시 1) (drop)data = [1000, 2000, 3000] index = ["메로나", "구구콘", "하겐다즈"] s = Series(data=data, index=index) print(s.drop('메로나'))
(실행 예시 2) (drop 오류 예시print(s.drop(0))이렇게 쓰면 오류가 난다.
drop 메서드는 시리즈의 원본 데이터를 제거하지 않고 새로운 시리즈 객체를 반환하는 것에 유의해야 합니다. 이는 실수로 원본 데이터를 수정해버리는 것을 방지하기 위한 일종의 안전장치입니다. 다음과 같이 drop 메서드를 호출한 결과를 다시 변수에 바인딩하기
(실행 예시 3)s = s.drop('메로나') print(s)
시리즈 연산
시리즈는 넘파이와 동일하게 브로드캐스팅이 적용되며, 같은 인덱스를 갖는 데이터끼리 연산을 수행합니다
(간단한 예시를 들어보겠습니다.)
철수가 NAVER 10주, SKT 30주, KT 30주를 보유하고 있고 영희가 SKT 10주, KT 20주, NAVER 20주를 보유하고 있을 때 철수와 영희 가족이 보유하고 있는 종목별 주식 수는 어떻게 될까요? 이를 판다스 시리즈로 계산해 봅시다.
실습 1
(실행 예시 1)
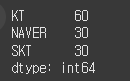
철수 = Series([10, 20, 30], index=['NAVER', 'SKT', 'KT']) # 철수의 주식 종목 보유 현황을 시리즈 객체로 표현합니다. 영희 = Series([10, 30, 20], index=['SKT', 'KT', 'NAVER']) # 영희의 주식 종목 보유 현황을 시리즈 객체로 표현합니다. # 두 시리즈 객체를 더합니다. 가족 = 철수 + 영희 print(가족)
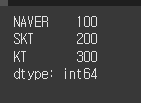
(실행 예시 2)print(철수 * 10)
실습 2
이번에는 삼성전자의 5일 일봉 데이터에서 고가와 저가 시리즈로 각 거래일의 변동폭을 계산해 봅시다. 여기서 변동폭이란 '고가와 저가의 차분값'입니다.
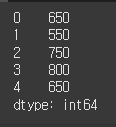
(실행 예시 1)high = Series([42800, 42700, 42050, 42950, 43000]) low = Series([42150, 42150, 41300, 42150, 42350]) diff = high - low print(diff)
이번에는 앞서 계산한 diff 변수에서 변동폭이 가장 큰 값을 찾아봅시다.
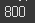
(실행 예시 2)print(diff.max())
가장 변동폭이 작은 값 찾기
(실행 예시 3)print(diff.min())

날짜를 인덱스로 갖는 시리즈에서 변동폭이 가장 큰 날짜를 찾아봅시다.
(실행 예시 4)date = ["6/1", "6/2", "6/3", "6/4", "6/5"] high = Series([42800, 42700, 42050, 42950, 43000], index=date) low = Series([42150, 42150, 41300, 42150, 42350], index=date) diff = high - low print(diff) print(diff.min())
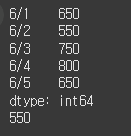
시리즈는 자료구조이므로 반복문을 사용할 수 있습니다. 반복문으로 값에 하나씩 접근하면서, 비교를 통해 최댓값과 인덱스를 저장해 놓습니다. 반복문이 끝나면 최댓값과 인덱스를 알 수 있으니 index를 하나 선택합니다.
(실행 예시 5)max_idx = 0 max_val = 0 for i in range(len(diff)): if diff[i] > max_val: max_val = diff[i] max_idx = i print(max_idx) print(diff.index[max_idx])
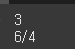
시리즈는 최댓값일 때의 인덱스를 반환하는 idxmax와 최솟값일 때의 인덱스를 반환하는 idxmin 메서드를 제공합니다. 반복문을 사용할 필요 없이 메서드를 호출하기만 하면 끝입니다.
(실행 예시 6)print(diff.idxmax()) print(diff.idxmin())
이번에는 매일 저가에 사서 고가에 팔았을 경우 수익률을 계산해 보겠습니다. 현재 단계에서는 수수료는 고려하지 않고 단순 계산합니다.
(실행 예시 7)date = ["6/1", "6/2", "6/3", "6/4", "6/5"] high = Series([42800, 42700, 42050, 42950, 43000], index=date) low = Series([42150, 42150, 41300, 42150, 42350], index=date) profit = high / low print(profit)
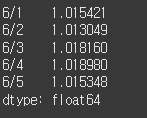
누적 수익률은 모든 수익률을 누적해서 곱함으로써 계산할 수 있습니다. 반복문을 사용할 수도 있지만 판다스가 제공하는 cumprod 메서드를 사용하면 한 번에 결과를 얻을 수 있습니다.
(실행 예시 8)print( profit.cumprod( ) )
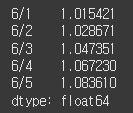
cumprod 메서드를 적용한 결과가 다시 시리즈이니 인덱싱으로 하나의 값을 가져올 수 있습니다.
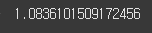
(실행 예시 9)print( profit.cumprod( ).iloc[ -1 ] )
실습 3
시리즈 객체에 저장된 데이터 중 유일한 값을 뽑아내고 각 데이터의 개수도 카운트(count)하는 방법을 배워보겠습니다. 먼저 예제로 사용할 시리즈 객체를 생성합니다. 딕셔너리 타입으로 데이터를 정의하고 시리즈 객체로 변환했습니다.
(실습 예시 1)data = { "삼성전자": "전기,전자", "LG전자": "전기,전자", "현대차": "운수장비", "NAVER": "서비스업", "카카오": "서비스업" } s = Series(data)
5개의 종목에 대한 업종 데이터를 시리즈 객체로 표현한 겁니다. 5개의 종목에서 중복을 제거하고 업종 리스트를 가져오고 싶을 때가 있습니다. 이 경우 unique 메서드를 사용합니다.
(실습 예시 2)print(s.unique())

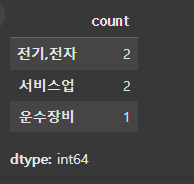
시리즈 안에 업종이 몇 번 존재하는지 횟수를 세어봅시다. value_counts 메서드를 사용하면 값의 출현 빈도를 계산해서 시리즈 객체로 반환합니다.
(실습 예시 3)s.value_counts()
시리즈와 Map
시리즈를 사용하다 보면 시리즈가 지원하는 기본 연산 (덧셈, 뺄셈, 곱셈, 나눗셈) 이외에도 복잡한 형태의 사용자 정의 코드를 적용하고 싶은 경우가 있습니다. 예를 들어 숫자가 문자열 타입으로 시리즈에 바인딩 돼 있을 때 이를 숫자로 변환하는 경우입니다. 형변환 함수를 바로 사용하면 콤마로 인해 형변환을 실패해서 에러가 출력됩니다.
(실행 예시 1) (오류 코드)s = Series(["1,234", "5,678", "9,876"]) print( int(s) )

이렇게 파이썬이 제공하지 않는 기능을 시리즈에 적용할 때는 map 메서드를 사용합니다. 우선 map 메서드가 동작하는 원리를 파악해 봅시다.
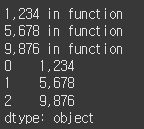
(실행 예시 2)def remove_comma(x) : # 라인 1~3: 파라미터를 한 개 입력받아 그 값을 그대로 리턴하는 print(x, 'in function') # 라인 1~3: 파라미터를 한 개 입력받아 그 값을 그대로 리턴하는 return x # 라인 1~3: 파라미터를 한 개 입력받아 그 값을 그대로 리턴하는 s = Series(["1,234", "5,678", "9,876"]) result = s.map(remove_comma) # map 메서드에 remove_comma 함수를 입력합니다. print(result)
콤마를 제거하고 숫자로 타입을 변경해 보겠습니다. remove_comma 함수를 수정하면 되겠죠? replace 메서드로 콤마를 제거하고 int 함수로 타입을 변경합니다.
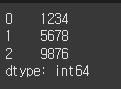
(실행 예시 3)def remove_comma(x) : return int(x.replace(",", "")) s = Series(["1,234", "5,678", "9,876"]) result = s.map(remove_comma) print(result)
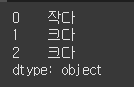
map 메서드를 사용해서 수치형 데이터를 범주형 데이터로 구분해 보겠습니다. 바인딩된 값이 5000보다 크면 '크다', 그렇지 않으면 '작다'라는 카테고리로 분류해 봅시다. 시리즈에는 정수 데이터가 저장돼 있습니다.
(실행 예시 4)def is_greater_than_5000(x): if x > 5000: return "크다" else: return "작다" s = Series([1234, 5678, 9876]) s = s.map(is_greater_than_5000) print(s)
시리즈 필터링
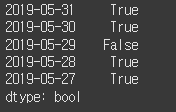
이번에는 시리즈 객체에 비교 연산을 적용해 보겠습니다. 비교 연산의 종류로는 크다, 작다, 같다, 다르다 등이 있습니다. 간단한 예를 통해서 비교 연산을 익혀 봅시다. 삼성전자의 5일 종가가 시리즈 객체로 표현되어 있을 때 이를 42,000원과 비교해 봅시다.
(실행 예시 1)data = [42500, 42550, 41800, 42550, 42650] index = ['2019-05-31', '2019-05-30', '2019-05-29', '2019-05-28', '2019-05-27'] s = Series(data=data, index=index) cond = s > 42000 # 시리즈 객체의 각 데이터가 42000보다 큰지 비교합니다. print(cond) # 비교 연산의 결과가 저장된 시리즈를 출력합니다.
cond라는 변수에는 True 또는 False가 시리즈로 저장되어 있는데 이를 사용해서 색인하는 것을 '불리언 인덱싱(색인)'이라고 부르며 시리즈 객체에서 매우 유용한 기능 중 하나입니다. 예를 들어 삼성전자의 종가가 42,000원 이상인 거래일만 출력해야 하는 경우를 생각해봅시다. 이 경우 시리즈 객체의 대괄호([ ]) 연산자에 True 또는 False가 저장된 시리즈 객체를 넘겨주기만 하면 됩니다.
(실행 예시 2)print(s[cond])
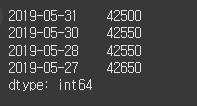
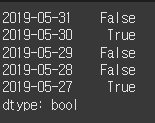
이번에는 시가와 종가를 시리즈 객체로 표현한 후 종가가 시가보다 큰지를 비교해 보겠습니다.
close = [42500, 42550, 41800, 42550, 42650] open = [42600, 42200, 41850, 42550, 42500] index = ['2019-05-31', '2019-05-30', '2019-05-29', '2019-05-28', '2019-05-27'] open = Series(data=open, index=index) close = Series(data=close, index=index) cond = close > open print(cond)
만약 종가가 시가보다 높았던 상승 마감한 날의 종가를 출력하려면 어떻게 해야 할까요? 앞에서 배운 불리언 색인 기능을 사용하면 되겠지요?
(실행 예시 3)cond = close > open print(close[cond])
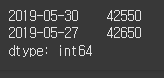
코드가 간략하니 변수를 사용하지 않고 한 줄로 짧게 표현할 수도 있습니다.
(실행 예시 4)print(close[close > open])
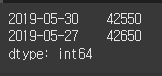
상승 마감한 날짜만을 출력할 수도 있습니다. index에 조건을 연결하면 조건이 참인 날짜만 선택됩니다. 혹은 조건으로 시리즈를 필터링한 다음 인덱스를 가져올 수도 있습니다. 두 가지 모두 출력되는 결과는 같습니다.
(실행 예시 5)print(close.index[close > open]) print(close[close > open].index)

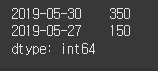
이번에는 종가가 시가보다 높은 날의 거래일과 변동폭을 출력해 보겠습니다. 여기서 변동폭은 '종가-시가'로 정의합니다. 먼저 변동폭을 시리즈 객체로 표현한 후 조건으로 데이터를 슬라이싱합니다. (close와 open 시리즈 객체는 인덱스가 같기 때문에 조건 비교 및 필터링을 할 수 있습니다.)
(실행 예시 6)close = [42500, 42550, 41800, 42550, 42650] open = [42600, 42200, 41850, 42550, 42500] index = ['2019-05-31', '2019-05-30', '2019-05-29', '2019-05-28', '2019-05-27'] open = Series(data=open, index=index) close = Series(data=close, index=index) diff = close - open # 각 거래일의 변동폭을 시리즈 객체로 생성합니다. print(diff[close > open]) # 각 거래일의 종가와 시가를 비교하고 시리즈 객체에 대해서 불리언 색인을 적용합니다. # 코드가 간단하기 때문에 변수에 값을 바인딩하지 않고 한 줄에 표현했습니다.
정렬 및 순위
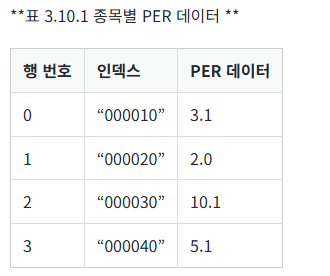
이번 절에서는 시리즈 객체의 정렬에 대해 알아봅시다. 표 3.10.1과 같이 4개 종목의 PER 데이터가 시리즈 객체로 구성돼 있다고 가정합니다.
시리즈 객체는 sort_values라는 자체 정렬 메서드를 가집니다. 따라서 정렬하고 싶은 시리즈 객체에서 sort_values 메서드를 호출하기만 하면 데이터를 기준으로 오름차순으로 정렬됩니다. 만약 큰 값에서 작은 값으로 내림차순 정렬하고 싶다면 ascending=False라고 함수 기본 인자를 설정하면 됩니다.
(실행 예시 1)data = [3.1, 2.0, 10.1, 5.1] index = ['000010', '000020', '000030', '000040'] s = Series(data=data, index=index) # 시리즈 객체를 생성합니다. 6자리의 종목코드가 인덱스이고 PER 값이 데이터인 시리즈 객체를 생성합니다. print(s) # 정렬 (오름차순) s1 = s.sort_values() # 시리즈 객체를 오름차순으로 정렬한 새로운 시리즈 객체를 생성하고 이를 s1이라는 변수가 바인딩합니다. print(s1) # 정령 (내림차순) s2 = s.sort_values(ascending=False) # 시리즈 객체를 내림차순으로 정렬한 새로운 시리즈 객체를 생성하고 이를 s2라는 변수가 바인딩합니다. print(s2)
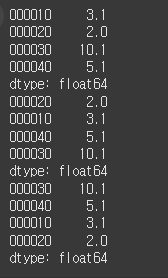
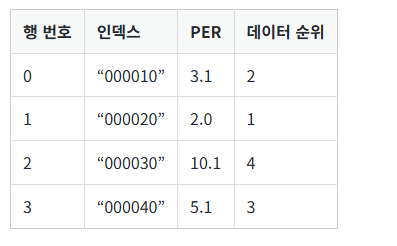
이번에는 시리즈 객체의 데이터 값을 기준으로 순위를 매겨보겠습니다. 예를 들어 표 3.10.2와 같이 4개의 주식 종목에 대한 PER 데이터가 있을 때 PER 값이 낮은 순으로 순위를 매겨 보고 싶은 겁니다. 앞서 배운 정렬과 달리 데이터의 위치는 그대로 유지한 채 순위만 추가한다는 점이 다릅니다.
시리즈 객체는 순위를 매기기 위한 rank 메서드를 제공합니다. 시리즈 객체의 rank 메서드는 기본적으로 값이 작은 데이터를 1순위로 지정합니다.
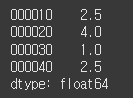
(실행 예시 2)data = [3.1, 2.0, 10.1, 3.1] index = ['000010', '000020', '000030', '000040'] s = Series(data=data, index=index) print(s.rank())
rank 메서드의 출력 결과를 살펴보면 PER 값이 가장 작은 '000020' 인덱스 항목의 순위가 1임을 확인할 수 있습니다. 동일한 값을 갖는 데이터의 순위를 표현하기 위해 rank 값이 float64로 표현됩니다.
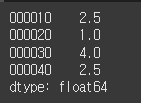
만약 값이 큰 데이터를 1등으로 순위로 매기려면 rank 메서드를 호출할 때 ascending=False 옵션을 넣어주면 됩니다.
(실행 예시 3)print(s.rank(ascending=False))