시작하기 전에 import 하기
import numpy as np import pandas as pd import numba from pandas import DataFrame
데이터프레임 인덱싱과 슬라이싱
data = [ ["037730", "3R", 1510, 7.36], ["036360", "3SOFT", 1790, 1.65], ["005760", "ACTS", 1185, 1.28], ] columns = ["종목코드", "종목명", "현재가", "등락률"] df = pd.DataFrame(data=data, columns=columns) df.set_index('종목코드', inplace=True)
문제
데이터프레임 컬럼 접근
데이터프레임에서 현재가 컬럼만 출력해보세요.정답
컬럼 인덱싱
데이터프레임에서 현재가 컬럼을 인덱싱하는데 이를 데이터프레임 타입이 되도록 하세요.print(df[['현재가']])
문제
특정 값 가져오기 (loc)
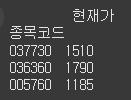
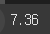
다음 데이터프레임에서 037730 종목의 등락률을 출력하세요.data = [ ["037730", "3R", 1510, 7.36], ["036360", "3SOFT", 1790, 1.65], ["005760", "ACTS", 1185, 1.28], ] columns = ["종목코드", "종목명", "현재가", "등락률"] df = pd.DataFrame(data=data, columns=columns) df.set_index('종목코드', inplace=True)정답
df.loc["037730", "등락률"]
####문제
iloc 슬라이싱
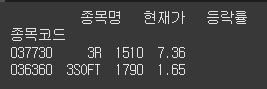
위 데이터프레임에서 iloc 속성을 사용하여 첫번째, 두번째 행을 슬라이싱하세요.정답
print(df.iloc[0:2])
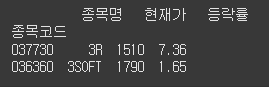
문제
loc 슬라이싱
위 데이터프레임에서 loc 속성을 사용하여 첫번째, 두번째 행을 슬라이싱하세요.정답
print(df.loc["037730":"036360"])
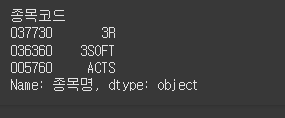
문제
컬럼 인덱싱 (iloc)
위 데이터프레임에서 iloc 속성을 사용하여 첫 번째 컬럼을 인덱싱하세요.정답
df.iloc[:, 0]
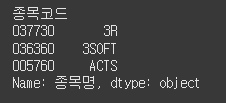
문제
컬럼 인덱싱 (loc 속성)
위 데이터프레임에서 loc 속성을 사용하여 첫 번째 컬럼을 인덱싱하세요.정답
print(df.loc[:, "종목명"])
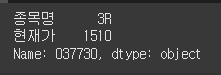
문제
loc
위 데이터프레임에서 loc 속성을 사용하여 '037730' 종목의 '종목명', '현재가' 컬럼을 선택하세요.정답
print(df.loc["037730", ["종목명", "현재가"]])
문제
iloc
위 데이터프레임에서 iloc 속성을 사용하여 '037730' 종목의 '종목명', '현재가' 컬럼을 선택하세요.정답
print(df.iloc[0, [0, 1]])
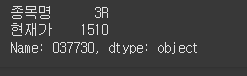
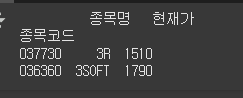
문제
loc
위 데이터프레임에서 loc를 속성을 사용하여 다음 범위를 가져오세요.
(예시자료)
정답
print(df.loc[["037730", "036360"], ["종목명", "현재가"]])
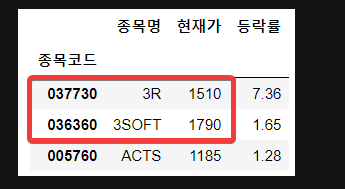
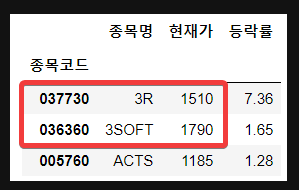
문제
iloc 속성
위 데이터프레임에서 iloc를 속성을 사용하여 다음 범위를 가져오세요.
정답
print(df.iloc[[0,1], [0,1]])
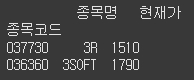
문제
loc 속성과 슬라이싱
위 데이터프레임에서 다음 코드로 선택되는 영역을 말해보세요.df.loc[:"036360", "현재가":"등락률"]정답
df.loc[:"036360", "현재가":"등락률"]
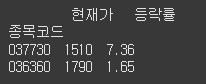
데이터프레임 필터링과 변경
data = [ ["037730", "3R", 1510, 7.36], ["036360", "3SOFT", 1790, 1.65], ["005760", "ACTS", 1185, 1.28], ] columns = ["종목코드", "종목명", "현재가", "등락률"] df = pd.DataFrame(data=data, columns=columns) df.set_index('종목코드', inplace=True)
문제
필터링
다음 데이터프레임에서 현재가가 1500 이상인 값만 가져와보세요.정답
df[ df['현재가'] >= 1500 ]
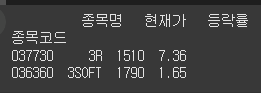
문제
필터링
위 데이터프레임에서 현재가가 1,500원 이상이면서 1,700원 미만인 값만 필터링 해보세요.정답
cond = (df['현재가']>=1500) & (df['현재가']<1700) print(df[cond])
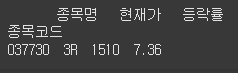
문제
컬럼 추가
다음 데이터프레임에 목표가 컬럼을 추가하세요. 목표가는 현재가에서 10% 상승한 가격입니다.정답
df['목표가'] = df['현재가'] * 1.1 print(df)
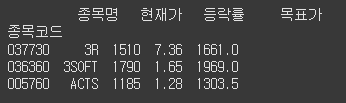
문제
로우추가
데이터프레임에 LG전자의 데이터를 추가하세요.
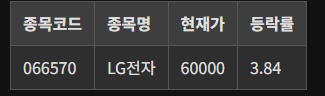
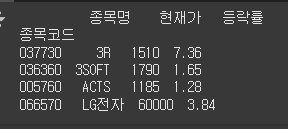
정답
df.loc["066570"] = ["LG전자", 60000, 3.84] print(df)
문제
데이터 프레임 컬럼명 변경 (columns 속성)
다음 코드를 통해 데이터프레임을 생성합니다.df = pd.DataFrame(data = [[1, 2, 3], [4, 5, 6]], columns=["A", "B", "C"])생성된 데이터프레임에서 columns 속성을 사용하여 컬럼명을 'a', 'b', 'c'로 변경하세요.
정답
df = pd.DataFrame(data = [[1, 2, 3], [4, 5, 6]], columns=["A", "B", "C"]) print(df)

문제
데이터 프레임 컬럼명 변경 (rename 메소드)
다음 코드를 통해 데이터프레임을 생성합니다.df = pd.DataFrame(data = [[1, 2, 3], [4, 5, 6]], columns=["A", "B", "C"])생성된 데이터프레임에서 rename 메소드를 사용해서 컬럼 'A'를 'a'로 변경해보세요.
정답
df.rename(columns={"A": "a"}, inplace=True) print(df)
name 속성
문제
다음 데이터프레임의 index의 name 속성을 'year'로 columns의 name 속성을 'company'로 변경하세요.
data = {"카카오": [np.nan, 221, 35], "NAVER": [52, 47, 3]} index = [2019, 2020, 2021] df = pd.DataFrame(data=data, index=index)정답
df.index.name = "year" df.columns.name = "company"
문제
데이터프레임 reindex
다음 데이터프레임에서 컬럼의 순서를 ['NAVER', '카카오']로 재정렬해보세요.data = {"카카오": [np.nan, 221, 35], "NAVER": [52, 47, 3]} index = [2019, 2020, 2021] df = pd.DataFrame(data=data, index=index) print(df)정답
df = df.reindex(columns=['NAVER', '카카오'])
문제
데이터프레임 drop
데이터프레임에서 'NAVER' 컬럼을 삭제하세요.data = {"카카오": [np.nan, 221, 35], "NAVER": [52, 47, 3]} index = [2019, 2020, 2021] df = pd.DataFrame(data=data, index=index) df정답
df.drop("NAVER", axis=1)
문제
데이터프레임 drop
다음 데이터프레임에서 '카카오'와 'NAVER' 컬럼을 삭제하세요.data = {"카카오": [np.nan, 221, 35], "NAVER": [52, 47, 3], "삼성전자": [17, 21, 13]} index = [2019, 2020, 2021] df = pd.DataFrame(data=data, index=index) df정답
df.drop(['NAVER', '카카오'], axis=1)
문제
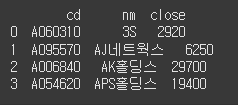
데이터프레임 컬럼 문자열 다루기
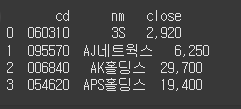
다음 데이터프레임의 'cd' 컬럼의 'A'를 제거하세요.data = [ {"cd":"A060310", "nm":"3S", "close":"2,920"}, {"cd":"A095570", "nm":"AJ네트웍스", "close":"6,250"}, {"cd":"A006840", "nm":"AK홀딩스", "close":"29,700"}, {"cd":"A054620", "nm":"APS홀딩스", "close":"19,400"} ] df = DataFrame(data=data) print(df)정답
df['cd'] = df['cd'].str[1:] print(df)
문제
데이터프레임 문자열 컬럼
위 데이터프레임에서 'close' 컬럼의 콤마를 제거한 후 np.int64 타입으로 변경하세요.정답
df['close'] = df['close'].str.replace(',','').astype(np.int64) print(df)
문제
DataFrame dropna
다음 데이터프레임에서 np.nan 값이 있는 모든 행을 제거하세요.data = [ [1, 2, 3], [np.nan, 5, 6], [7, np.nan, 9], [10, 11, np.nan] ] df = pd.DataFrame(data)정답
print(df.dropna())
문제
dataframe.dropna (subset)
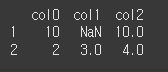
다음 데이터프레임에서 col2 컬럼의 값에 NaN이 포함된 행만 제거하세요.data = [ [1, 1, np.nan], [10, np.nan, 10], [2, 3, 4] ] columns = ['col0', 'col1', 'col2'] df = pd.DataFrame(data, columns=columns)정답
print(df.dropna(subset='col2'))
문제
dataframe.fillna
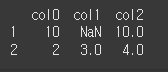
다음 데이터프레임의 NaN 값을 0으로 채우세요.data = [ [1, 1, np.nan], [10, np.nan, 10], [2, 3, 4] ] columns = ['col0', 'col1', 'col2'] df = pd.DataFrame(data, columns=columns)정답
print(df.fillna(0))
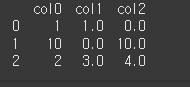
문제
fillna (method)
다음 데이터프레임에서 NaN 값을 동일 컬럼의 이전 값으로 채우세요.data = [ [1, 1, np.nan], [10, np.nan, 10], [2, 3, 4] ] columns = ['col0', 'col1', 'col2'] df = pd.DataFrame(data, columns=columns)정답
print(df.fillna(method='ffill'))
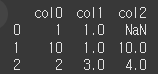
문제
dataframe.isna()
다음 데이터프레임에서 isna 메서드를 호출해보세요.data = [ [1, 1, np.nan], [10, np.nan, 10], [2, 3, 4] ] columns = ['col0', 'col1', 'col2'] df = pd.DataFrame(data, columns=columns)정답
print(df.isna())
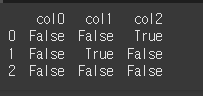
문제
dataframe.notna
위 데이터프레임에 대해서 notna 메서드를 호출해보세요.정답
print(df.notna())
문제
dataframe replace
다음 데이터프레임에서 0을 100으로 변경하세요.data = np.arange(9).reshape(3, 3) df = pd.DataFrame(data)정답
print(df.replace(0, 100))
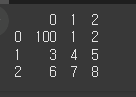
문제
astype
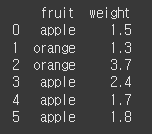
다음 데이터프레임의 'fruit' 컬럼의 타입을 object에서 category로 변경하세요.
data = { 'fruit': ['apple', 'orange', 'orange', 'apple', 'apple', 'apple'], 'weight': [1.5, 1.3, 3.7, 2.4, 1.7, 1.8] } df = pd.DataFrame(data)정답
df['fruit'] = df['fruit'].astype('category') print(df)