시작하기 전에 import 하기
import numpy as np import pandas as pd import numba from pandas import DataFrame
인덱스 (Index)
DataFrame.index
개요
index메서드는 pandas객체의 index(행)를 출력합니다.
사용법
기본 사용법
df.index
예시
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3']) print(df)
실행 결과
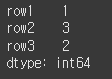
실행결과는 아래와 같이 Index명과 type이 차례로 출력되는것을 볼 수 있습니다.
반환 타입은 pandas의 Index타입임을 사용에 참고 바랍니다.result = df.index print(result) print(type(result))

열 (Columns)
DataFrame.columns
개요
columns메서드는 pandas객체의 columns(열)을 출력합니다.
사용법
기본 사용법
df.columns
예시
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3']) print(df)
실행 결과
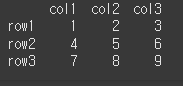
실행결과는 아래와 같이 columns명과 type이 차례로 출력되는것을 볼 수 있습니다. 반환 타입은 index함수에서와 같이 pandas의 Index타입임을 사용에 참고 바랍니다.result = df.columns print(result) print(type(result))

데이터 타입 (dtype)
DataFrame.dtypes
개요
dtypes 메서드는 열에 포함된 데이터들의 type을 Series형태로 반환합니다.
반환된 Series의 index는 원래 DataFrame 객체의 columns(열)에 해당됩니다.
사용법
기본 사용법
df.dtypes
예시
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,'A',3.1], [4,'B',6.2], [7,'C',9.3]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3']) print(df)
실행 결과
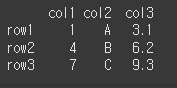
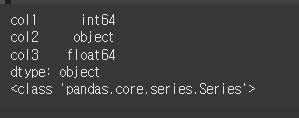
아래와 같이 실행 시 각 columns에 대해 dtypes를 반환합니다. 만약 type이 혼합되어있는경우
object 타입으로 반환합니다.result = df.dtypes print(result) print(type(result))
축 (axes)
DataFrame.axes
개요
axes메서드는 DataFrame 객체의 축(axes) 레이블 정보를 list형태로 반환합니다.
list의 첫 번째 요소는 행(row), 두 번째 요소는 열(columns)로 반환되며, 각각의 type은 index입니다.
추가로 요소의 type이 함께 출력됩니다.
사용법
기본 사용법
df.axes
예시
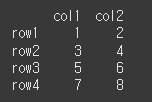
먼저, 아래와 같이 기본적인 4x2 행렬을 만듭니다.
df = pd.DataFrame(data=[[1,2],[3,4],[5,6],[7,8]],index=['row1','row2','row3','row4'],columns=['col1','col2']) print(df)
실행 결과
df.axes실행시 아래와 같이 list형태로 축의 정보가 출력되는것을 확인할 수 있습니다.
(실행 결과1)result = df.axes print(result)
(실행 결과2)print(result[0])
(실행 결과3)print(result[1])



차원 (ndim)
DataFrame.ndim
개요
ndim메서드는 데이터의 차원(축의 수)를 반환합니다. Series일경우 1차원, DataFrame이면 2차원이므로
데이터의 종류 파악에 사용할 수 있습니다.
사용법
기본 사용법
df.ndim
예시
간단히 Series객체와 DataFrame객체를 만들어 보겠습니다.
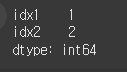
(실행 결과1)df1 = pd.Series({'idx1':1,'idx2':2,'idx2':2}) print(df1)
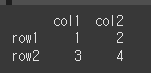
(실행 결과2)df2 = pd.DataFrame(data=[[1,2],[3,4]],index=['row1','row2'],columns=['col1','col2']) print(df2)
ndim 함수 사용시, Series의 경우 1을 반환하고 DataFrame의 경우 2를 반환하는것을 확인할 수 있습니다.
print(df1.ndim) print(df2.ndim)

요소의 갯수(size)
DataFrame.size
개요
size메서드는 데이터의 총 수의 갯수를 구합니다. 즉, Series일 경우 행의 수를 반환하고
DataFrame의 경우 행의수 x 열의수 를 반환합니다.
사용법
기본 사용법
df.size
예시
간단히 Series객체와 DataFrame객체를 만들어 보겠습니다.
(실행 결과1)df1 = pd.Series({'idx1':1,'idx2':2,'idx2':2}) print(df1)
(실행 결과2)df2 = pd.DataFrame(data=[[1,2],[3,4]],index=['row1','row2'],columns=['col1','col2']) print(df2)
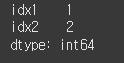
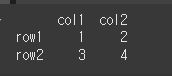
size 함수 사용시, 요소의 수를 반환 한 것을 확인 할 수 있습니다.
print(df1.size) print(df2.size)
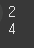
차원의 형태 (shape)
DataFrame.shape
개요
shape 메서드는 DataFrame 객체의 차원의 형태를(레이블 정보)를 튜플의 형식으로 반환합니다.
즉, 3행 2열의 객체의 경우 (3,2)를 반환합니다.
사용법
기본 사용법
df.shape
예시
간단히 1x4 객체와, 3x3 객체를 만들어서 확인해보겠습니다.
(실행 결과1)data1= [[1,2,3],[4,5,6],[7,8,9]] df1 = pd.DataFrame(data = data1, index = ['row1', 'row2', 'row3'], columns=['col1','col2','col3']) print(df1)
(실행 결과2)data2 = [[1,2,3,4]] df2 = pd.DataFrame(data =data2, index = ['row1'], columns=['col1','col2','col3','col4']) print(df2)
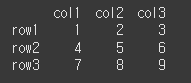
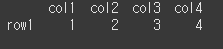
shape 함수 사용 시, 아래와 같이 3행3열, 1행4열의 정보가 튜플 형태로 반환된 것을 확인할 수 있습니다.
print(df1.shape) print(df2.shape)

정보축 (keys)
nfo axis를 사용하지 않는다면, columns함수를 사용하는것을 추천합니다.
DataFrame.keys()
개요
keys 메서드는 'info axis(정보축)' 값을 가져옵니다.
여기서 정보축이란 Series에서는 index, DataFrame에서는 열을 말합니다.
사용법
기본 사용법
df.keys( )
예시
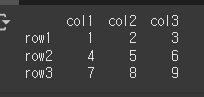
먼저 3x3 의 기본적인 DataFrame객체를 하나 만들어보겠습니다.
data = [[1,2,3],[4,5,6],[7,8,9]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) print(df)
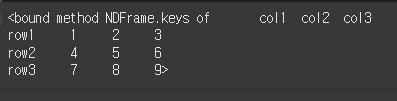
DataFrame 객체이기 때문에 key 메서드를 사용할 경우 열의 값을 가져옵니다.
print(df.keys)
키값(열의 요소) 반환 (get)
DataFrame.get(key, default=None)
개요
get 메서드는 pandas객체에서 key값(예: DataFrame에서 열)을 검색해서 요소를 가져옵니다.
찾는게 없을경우 default 값을 반환합니다.
사용법
기본 사용법
df.get(key, default=None)
예시
먼저 3x3 의 기본적인 DataFrame객체를 하나 만들어보겠습니다.
data = [[1,2,3],[4,5,6],[7,8,9]] col = ['col1','col2','col3'] row = ['row1','row2','row3'] df = pd.DataFrame(data=data,index=row,columns=col) print(df)
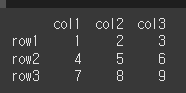
key='col1'로 해서 col1의 요소를 반환해보겠습니다.
result = df.get('col1') print(result)
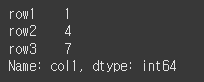
key='col4'로 해서 존재하지 않는 col4를 반환하면 default 값인 None을 반환하게 됩니다.
result = df.get('col4') print(result)

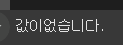
default값을 설정해줌으로써 원하는 반환을 설정할 수 있습니다.
result = df.get('col4',default='값이없습니다.') print(result)
비교 (compare)
DataFrame.compare(other, align_axis=1, keep_shape=False, keep_equal=False)
개요
compare 메서드는 두 객체의 요소의 차이를 반환합니다.
사용법
기본 사용법
self.compare(other, align_axis=1, keep_shape=False, keep_equal=False)
other : 원본과 비교할 데이터입니다. align_axis : {0 : index / 1 : columns} self와 other를 정렬할 축입니다.
keep_shape : 원본의 모양을 유지할지 여부입니다. False인 경우 차이가 있는 행만 출력합니다.
keep_equal : 값이 같은경우 값을 출력할지 여부입니다. 기본값은 False로 NaN을 출력합니다.
예시
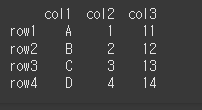
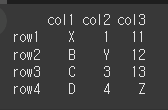
먼저 일부 값이 다른 4x3짜리 데이터프레임 두개를 생성하겠습니다.
(만들기)idx = ['row1','row2','row3','row4'] col = ['col1','col2','col3'] data1 = [['A',1,11],['B',2,12],['C',3,13],['D',4,14]] data2 = [['X',1,11],['B','Y',12],['C',3,13],['D',4,'Z']](실행 결과1)
df1 = pd.DataFrame(data1, idx, col) print(df1)
(실행 결과2)df2 = pd.DataFrame(data2, idx, col) print(df2)
기본적인 사용법
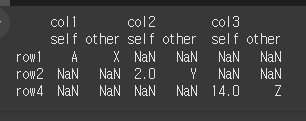
compare메서드를 이용해서 단순히 df1과 df2를 비교할 경우 아래와 같이 self와 other이 multi columns로 추가되며 차이가 있는 행만 출력하고, 동일한 값은 NaN을 출력하게 됩니다.print(df1.compare(df2))
align_axis인수의 사용
align_axis인수를 사용하여 self와 other 카테고리가 multi index로 반환될지 multi columns로 반환될지 지정할 수 있습니다.
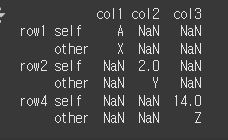
align_axis=0일 경우 multi index로 출력됩니다.print(df1.compare(other=df2, align_axis=0))
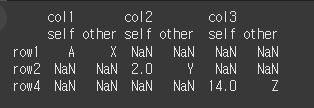
align_axis=1일 경우 multi columns으로 출력됩니다.(기본값)
print(df1.compare(other=df2, align_axis=1))
keep_shape인수의 사용
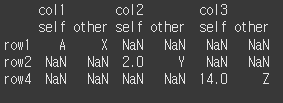
keep_shape=True로 사용할 경우 기존 열을 모두 출력하게되고, keep_shape=False일 경우(기본값) 차이가 있는 열만 출력하게 됩니다.
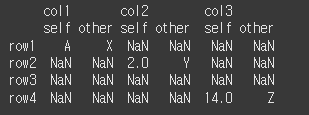
(실행 결과1)print(df1.compare(other=df2, keep_shape=True))
(실행 결과2)print(df1.compare(other=df2, keep_shape=False))
keep_equal인수의 사용
keep_equal인수를 사용할 경우 같은값을 출력할지 아니면 NaN으로 출력할지 지정할 수 있습니다.
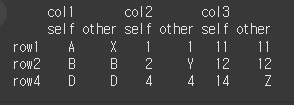
keep_eaual=True인 경우 같은값도 출력합니다.print(df1.compare(other=df2, keep_equal=True))
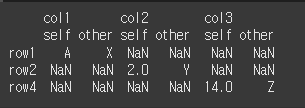
keep_eaual=False인 경우 같은값은 NaN을 출력합니다.(기본값)
print(df1.compare(other=df2, keep_equal=False))
고유한 행의 수 (value_counts)
DataFrame.value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)
개요
value_counts메서드는 고유한 행의 갯수를 반환합니다.
고유한 행이란 구성요소의 값이 완전히 동일한 경우를 말합니다.
사용법
기본 사용법
df.value_counts(subset=None, normalize=False, sort=True, ascending=False, dropna=True)
subset : 기준으로 삼을 열 입니다. list형태로도 입력이 가능합니다.
normalize : 갯수가 아니라 비율로 출력합니다.
sort : 빈도 순서로 정렬할지 여부입니다. 기본값은 True입니다.
ascending : 오름차순으로 정렬할지 여부입니다.
dropna : 결측치를 제외할지 여부입니다. 기본값은 True로 결측값은 제외됩니다.
예시
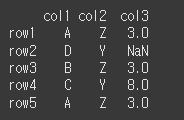
먼저 5x3짜리 데이터 객체를 하나 만들어보겠습니다.
n=np.nan idx = ['row1','row2','row3','row4','row5'] col = ['col1','col2','col3'] data = [['A','Z',3,],['D','Y',n],['B','Z',3],['C','Y',8],['A','Z',3]] df = pd.DataFrame(data, idx, col) print(df)
기본적인 사용법(+subset)
요소로 아무값도 입력하지 않는 경우 행의 모든 값을 대상으로 완전히 같은 행의 갯수를 우측에 출력하게됩니다.print(df.value_counts())
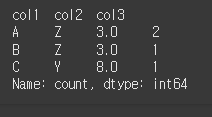
subset에 값을 입력해 줄경우 입력된 열의 값에 대해서만 동일성 검증을 진행하게 됩니다.
col2, col3에 대해서만 실행해보겠습니다.print(df.value_counts(subset=['col2','col3']))
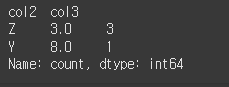
normalize인수의 사용
normalize인수를 사용할 경우 동일한 행의 갯수가 아닌 전체에서 차지하는 비율로 출력됩니다.
normalize=False인 경우(기본값)print(df.value_counts(subset='col2',normalize=False))
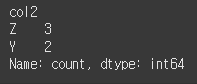
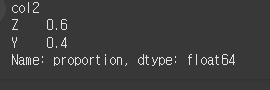
normalize=True인 경우
print(df.value_counts(subset='col2',normalize=True))
sort와 ascending인수의 사용
sort인수를 사용할 경우 최빈값부터 정렬하게되고, ascending을 사용할 경우 오름차순으로 정렬하게 됩니다.
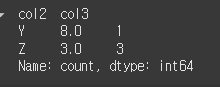
먼저 비교를 위해 sort=False이고 ascending=False으로 출력해보겠습니다.print(df.value_counts(subset=['col2','col3'],sort=False,ascending=False))
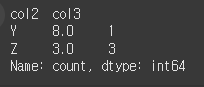
sort=True인 경우(기본값) 제일 고유값의 갯수가 많은 행부터 정렬됩니다.
print(df.value_counts(subset=['col2','col3'],sort=True,ascending=False))
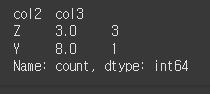
ascending=True인 경우 오름차순으로 정렬됩니다.
print(df.value_counts(subset=['col2','col3'],sort=True,ascending=True))
dropna의 사용(결측치 포함 여부)
dropna=True인 경우(기본값) 결측치가 포함된 행은 계산하지 않습니다. False인 경우 포함하게됩니다.print(df.value_counts(subset=['col2','col3'],dropna=False))

고유한 요소의 수 (nunique)
DataFrame.nunique(axis=0, dropna=True)
개요
nunique메서드는 선택된 축에 대해서 고유한 요소의 수를 구하는 메서드입니다.
사용법
기본 사용법
df.nunique(axis=0, dropna=True)
axis : 기준이 되는 축 입니다.
dropna : 결측치를 무시할지 여부 입니다. False일경우 하나의 요소로 간주합니다.
예시
먼저 3x3짜리 데이터 객체를 하나 만들어보겠습니다.
idx = ['row1','row2','row3'] col = ['col1','col2','col3'] data = [[1,1,n],[1,2,6],[1,3,n]] df = pd.DataFrame(data, idx, col) print(df)
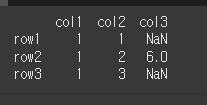
기본적인 사용법
기본값인 axis=0으로 실행할 경우 각 축에 대해서 고유값의 갯수를 출력합니다.
즉, 각 열에 대해서 값의 종류의 수를 반환합니다.print(df.nunique(axis=0))
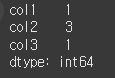
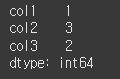
만약 dropna=False로 할 경우 NaN도 하나의 요소로 간주합니다.
print(df.nunique(axis=0,dropna=False))
axis=1로 하면 행 기준으로 메서드가 실행됩니다.
print(df.nunique(axis=1))