시작하기 전에 import 하기
import numpy as np import pandas as pd import numba
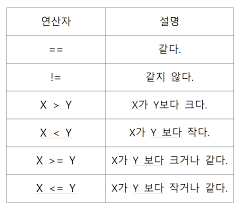
초과, 미만, 이상, 이하, 같음, 다름 (gt, lt, ge, le, eq, ne)
pandas.DataFrame.gt(other, axis='columns', level=None) > pandas.DataFrame.lt(other, axis='columns', level=None) < pandas.DataFrame.ge(other, axis='columns', level=None) >= pandas.DataFrame.le(other, axis='columns', level=None) <= pandas.DataFrame.eq(other, axis='columns', level=None) == pandas.DataFrame.ne(other, axis='columns', level=None) !=
개요
lt, gt, le, ge, eq, ne 메서드는 DataFrame의 크기 비교를 수행하는 메서드입니다.
각각 >, <, >=, <=, ==, !=와 용도가 같습니다. 그리고 각 메서드는 사용법이 동일합니다.
각각 less than, grater than, less equal, grater equal, equal, not equal을 뜻합니다.
사용법
기본 사용법
df.eq(other, axis='columns', level=None)
other : 스칼라, 시퀀스, Series, DataFrame, list등이 올 수 있습니다. 비교하고자 하는 값입니다.
axis : {0 : index / 1 : columns} 비교할 레이블 입니다.
level : 멀티인덱스 사용시 비교할 레이블의 레벨입니다.
예시
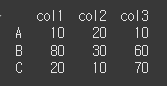
먼저, 간단한 3x3 객체를 하나 생성하겠습니다.
col = ['col1', 'col2', 'col3'] row = ['A', 'B', 'C'] df = pd.DataFrame(data=[[10, 20, 10], [80, 30, 60], [20, 10, 70]],index=row, columns=col) print(df)
스칼라값과의 비교
스칼라와의 비교시에는 단순히 other에 스칼라값을 입력하는것으로 실행할 수 있습니다.
비교 결과는 bool로 표시됩니다.
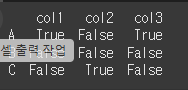
(실행 예시1)print(df.eq(10)) # 10과 같은 경우 True 표시
(실행 예시2)print(df.ne(20)) # 20과 같지 않는 경우 True 표시
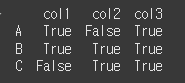
Series와의 비교
Series로 입력할 경우 Series의 index를 통해 비교할 레이블의 설정이 가능합니다.col = ['col1', 'col2', 'col3'] row = ['A', 'B', 'C'] df = pd.DataFrame(data=[[10, 20, 10], [80, 30, 60], [20, 10, 70]],index=row, columns=col) s1 = pd.Series([10,30],index=["col1","col3"]) print(df.gt(s1)) # col1에서 10이상, col3에서 30이상이면 True
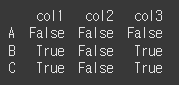
만약 존재하지 않는 레이블을 비교한다면, 해당 레이블이 생성(broadcast)됩니다.
s2 = pd.Series([10],index=["col4"]) print(df.lt(s2)) # df에는 col4가 없기 때문에 col4가 브로드캐스트 됩니다.
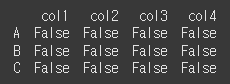
axis에 따른 비교의 차이
(실행 예시1)print(df.le([10,20,30], axis="columns")) # 열 기준으로 비교했을때 각각 10, 20, 30 이하면 True
(실행 예시2)print(df.le([10,20,30], axis="index")) # 행 기준으로 비교했을때 각각 10,20,30 이하면 True
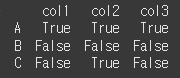
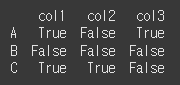
DataFrame과의 비교
Series와 마찬가지로 특정 레이블이 일치하는 DataFrame과의 비교가 가능합니다.
레이블이 일치하지 않을경우 해당 레이블이 생성(broadcast)됩니다.
먼저 간단한 3x1 짜리 DataFrame을 하나 만들어보겠습니다.df2 = pd.DataFrame([[50],[50],[50]],index=row,columns=['col1']) print(df2)
이제 df와 비교해보겠습니다.
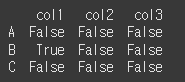
print(df.ge(df2)) # col1에 대해서 각각50, 50, 50 이상이면 True
멀티 인덱스의 사용 (level인수)
먼저 간단한 멀티인덱스 데이터프레임을 하나 만들어보겠습니다.row_mul = [['U','U','U','D','D','D'],['A','B','C','A','B','C']] df_mul = pd.DataFrame(data=[[10,20,10], [80,30,60], [20,10,70], [30,70,60], [10,90,40], [50,30,80]],index=row_mul,columns=col) print(df_mul)
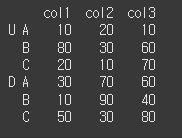
이제 여기서 레벨을 선택하여 df와의 비교에 사용해 보겠습니다.
print(df.ge(df_mul,level=1)) # level=1이기 때문에 A, B, C를 index로하는 두 DataFrame과의 비교처럼
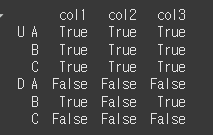
dtype기반 열 선택 (select_dtyps)
DataFrame.select_dtypes(include=None, exclude=None)
개요
select_dtypes 함수는 열에 포함된 데이터들을 type 기준으로 인덱싱 할 수 있도록 합니다.
select_dtypes(include=None, exclude=None) 형태를 가지며, include에 넣은값을 포함하고
exclude에 넣은 값을 제외한 columns(열)을 DaraFrame 형태로 반환합니다.
사용법
기본 사용법
df.dtypes
- include 및 exclude는 비어있거나 겹치면 안되며(에러발생), 스칼라나 list형태의 입력값이 가능합니다.
자료형
- 숫자형(numeric)은 np.number 또는 'number'
- 문자형(str)은 'object'
- 날짜,시간(datetimes)을 선택하려면 np.datetime64, 'datetime' 또는 'datetime64'
- timedeltas는 np.timedelta64, 'timedelta' or 'timedelta64'
- Pandas의 categorical 타입은 'category'
예시
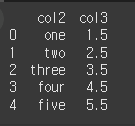
먼저, 아래와 같이 기본적인 4x5 행렬을 만듭니다. col1은 숫자, col2는 문자, col3은 float, col4는 bool의 dtype을 가집니다.
col1 = [1, 2, 3, 4, 5] col2 = ['one', 'two', 'three', 'four', 'five'] col3 = [1.5, 2.5, 3.5, 4.5, 5.5] col4 = [True, False, False, True, True] df = pd.DataFrame({"col1": col1, "col2": col2, "col3": col3, "col4": col4}) print(df)
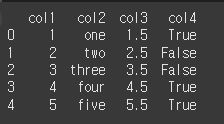
print(df.dtypes)
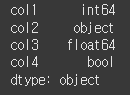
include사용
include에 포함될 type을 입력함으로써, 해당 type인 열만 반환하는것이 가능합니다.result = df.select_dtypes(include=[float,bool]) print(result)
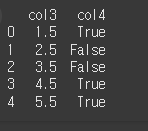
exclude사용
exclude에 제외할 type을 입력함으로써, 해당 type인 열만 제외하여 반환하는것이 가능합니다.result = df.select_dtypes(exclude=['int64']) print(result)
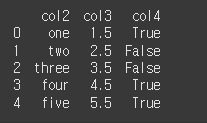
include & exclude 혼합 사용
include에 포함될 type을, exclude에 제외할 type을 입력하여 혼용 인덱싱이 가능합니다.result = df.select_dtypes(include =[float,object], exclude=['int64']) print(result)
임계값 적용 (clip)
DataFrame.clip(lower=None, upper=None, axis=None, inplace=False, args, kwargs)
개요
clip 메서드는 Series나 DataFrame에 대해서 요소들의 범위를 제한하는 메서드입니다
즉, 상한선과 하한선을 임계값으로 정해서 임계값 밖의 값을 임계값으로 변경합니다.
NA의 경우 변경하지 않습니다.
사용법
기본 사용법
df.clip(lower=None, upper=None, axis=None, inplace=False, args, kwargs)
lower : 하한값입니다. 이 이하의 값은 이 값으로 변경됩니다.
upper : 상한값입니다. 이 이상의 값은 이 값으로 변경됩니다.
axis : 계산할 기준이되는 레이블입니다.
inplace : 제자리에서 계산할지 여부 입니다.
inplace의 개념은 간단합니다. 우리가 만약 print(df.dropna())로 df에서 NA를 제거한다고 가정해봅니다.
그럼 NA가 사라진 데이터가 출력되겠지만, 다시 print(df)할 경우 df는 변경되어있지 않을 것입니다.
이때 print(df.dropna(inplace=True))를 수행한다면 print(df) 실행 시 df에도 NA가 삭제되어있는것을
확인할 수 있습니다. 물론 dropna뿐만 아니라 clip처럼 inplace 인수를 가진 모든 함수에서 동일합니다.
즉, df.dropna(inplace=True)는 df = df.dropna( )와 같은 효과를 가집니다.
예시
먼저 간단한 3x3짜리 데이터를 만들어보겠습니다.
col = ['col1','col2','col3'] row = ['row1','row2','row3'] data = [[-7,3,9], [6,-8,1], [-3,0,-7]] df = pd.DataFrame(data,row,col) print(df)
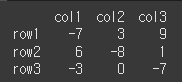
일반적인 사용법
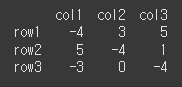
하한선을 -4로 상한선을 5로 clip메서드를 적용시켜보겠습니다.
즉, -4보다 작은수는 -4로. 5보다 큰 수 는 5로 변경되며 그 안의 수는 변경되지 않습니다.print(df.clip(-4,5))
임계값을 Series로 설정
임계값을 Series형태로 설정하여 각행이나 열마다 원하는 임계값의 지정이 가능합니다.
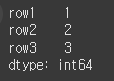
row1에는 -1~1, row2에는 -2~2, row3에는 -3~3으로 임계값을 지정해보겠습니다.
먼저 Series인 s를 설정해보겠습니다.s = pd.Series(data=[1,2,3],index=row) print(s)
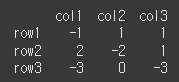
이제 임계값을 -s 와 s로 설정하여 clip메서드를 적용해보겠습니다.
print(df.clip(-s,s,axis=0))
레이블 필터링 (filter)
DataFrame.filter(items=None, like=None, regex=None, axis=None)
개요
filter 메서드는 레이블에 대해서 조건에 맞는 레이블만 필터링하는 메서드입니다.
내용물이 아니라 레이블에 대해서만 필터링하는것을 유의하세요.
특정 레이블을 이름으로 필터링하거나, 포함된 문자열을 통해 필터링하거나, 정규표현식으로 필터링이 가능합니다.
정규표현식(regular expression)의 경우 regex라고도 하며 파이썬에서는 re 메서드가 지원하는 내용과 동일합니다.
※ 정규표현식의경우 웹상에 자료가 방대하므로 이 페이지에서는 설명하지 않겠습니다. 추후 별도 페이지로 생성 예정입니다.
사용법
기본 사용법
df.filter(items=None, like=None, regex=None, axis=None)
items : 이름으로 필터링하는 경우입니다. 리스트형태로 입력합니다.
like : str로 필터링합니다. 해당 문자열이 포함된 경우를 반환합니다.
regex : 정규표현식을 이용해 필터링합니다. re.search(regex, label) == True에서 사용되는 경우와 동일합니다.
axis : {0 : index / 1 : columns} 필터링할 레이블입니다. 0은 행, 1은 열 입니다.
예시
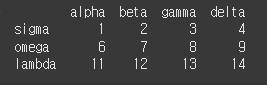
먼저 간단한 3x5짜리 데이터를 만들어보겠습니다.
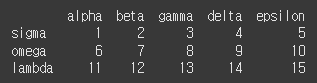
col = ['alpha','beta','gamma','delta','epsilon'] row = ['sigma','omega','lambda'] data = [[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]] df = pd.DataFrame(data,row,col) print(df)
items 인수를 사용하는 경우
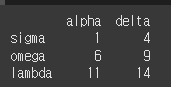
items인수를 통해 alpha, beta 열을 필터링 해보겠습니다.print(df.filter(items=['alpha','delta']))
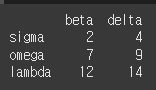
omega행을 필터링해보겠습니다.
print(df.filter(items=['omega'],axis=0))

like 인수를 사용하는 경우
like인수를 이용해 'ta'가 포함된 열을 필터링해보겠습니다.print(df.filter(like='ta'))
regex 인수를 사용하는 경우
regex인수를 사용해서 m과 n이 포함된 열을 필터링 해보겠습니다.
정규표현식 [ ] 는 [ ] 안의 모든 문자가 포함된 경우를 말합니다.
즉, [mn]은m과 n이 포함된 경우입니다.print(df.filter(regex='[mn]'))
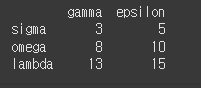
g로 시작하는 경우에 대해 필터링 해보겠습니다.
정규표현식 ^는 ^뒤에있는 문자로 시작하는 문자열을 말합니다.
즉, ^g는 g로 시작하는 경우를 말합니다.print(df.filter(regex='^g'))
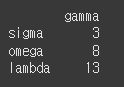
a로 끝나는 경우에 대해 필터링 해보겠습니다.
정규표현식 $ 는 $ 앞에있는 문자로 끝나는 문자열을 말합니다.
즉, a$는 a로 끝나는 경우를 말합니다.print(df.filter(regex='a$'))
샘플 추출 (sample)
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None, ignore_index=False)
개요
sample 메서드는 DataFrame이나 Series에서 무작위로 몇개의 값(레이블)을 출력하는 메서드입니다.
사용법
기본 사용법
df.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None, ignore_index=False)
n : 추출할 갯수 입니다. replace가 False면 n의 최댓값은 레이블의 갯수를 넘을수 없습니다.
frac : 추출할 비율입니다. 1보다 작은값으로 설정하며(예 : 0.3 이면 30%), n과 동시에 사용할 수 없습니다.
replace : 중복추출의 허용 여부 입니다. True로 하면 중복추출이 가능하며 n의 최댓값이 레이블의 갯수보다 커도 됩니다.
weight : 가중치입니다. 즉 레이블마다 추출될 확률을 지정할 수 있습니다. 합계가 1(100%)이 아닐경우 자동으로 1로 연산합니다.
random_state : 랜덤 추출한 값에 시드를 설정할 수 있습니다. 원하는 값을 설정하면, 항상 같은 결과를 출력합니다.
axis : {0 : index / 1 : columns} 추출할 레이블입니다.
ignore_index : index의 무시 여부입니다. True일경우 출력시 index를 무시하고 숫자로 출력합니다.
예시
먼저 간단한 5x3짜리 데이터를 만들어보겠습니다.
col = ['col1','col2','col3'] row = ['row1','row2','row3','row4','row5'] data = [[1,2,3],[4,5,6],[7,8,9],[10,11,12],[13,14,15]] df = pd.DataFrame(data,row,col) print(df)

n의 사용과 replcae의 사용
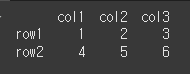
n을 설정함으로써 원하는 갯수의 추출이 가능합니다. n을 2로 설정함으로써 2개의 행이 추출된것을 볼 수 있습니다.print(df.sample(2))
행이 5이지만 replace=True로 설정하여 중복 추출을 허용한다면, n이 5보다 커도 됩니다.
print(df.sample(10,replace=True))
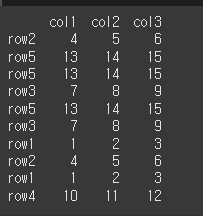
frac를 사용하는경우
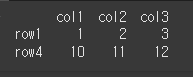
frac을 통해 전체에대한 추출 비율을 정할 수 있습니다. frac을 0.4로 설정하므로써, 전체에서 40%인 2개를 추출해보겠습니다.print(df.sample(frac=0.4))
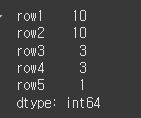
weights를 통한 가중치의 사용
먼저 가중치를 적용하기위해 5짜리 Series를 하나 만들어보겠습니다.s = pd.Series(data=[10,10,3,3,1], index = row) print(s)
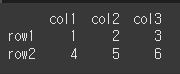
이제 이 Series s를 weights에 적용시켜보겠습니다. 가장 가중치가 높은 row1, row2가 추출된 것을 확인할 수 있습니다.
물론 가중치가 적더라도 확률적으로 추출될 가능성이 존재합니다.print(df.sample(2,weights=s))
random_state를 통한 동일값 재출력 허용
random_state에 원하는 값을 설정하므로써 출력 결과를 동일하게 다시 출력하는것이 가능합니다.print(df.sample(5,random_state=7))
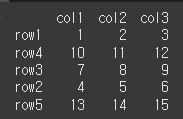
ignore_index의 사용
ignore_index를 True로 하면 index는 사라지고 순서대로 번호가 부여됩니다.print(df.sample(3,ignore_index=True))