시작하기 전에 import 하기
import numpy as np import pandas as pd import numba
레이블기반_스칼라 (at)
행/열 한쌍에 대한 단일 값에 엑세스합니다.
사용법
값 가져오기 : result = df.at['행', '열']
값 설정하기 : df.at['행', '열'] = value
예시
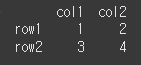
먼저 아래와 같이 기본적인 2x2 행렬을 만듭니다.
df = pd.DataFrame([[1,2], [3,4]], index=['row1', 'row2'], columns=['col1', 'col2']) print(df)
값 가져오기
행, 열 값을 인수로 입력하여 변수에 할당함으로써 값을 가져올 수 있습니다.result = df.at['row1', 'col2'] print(result)

값 설정하기
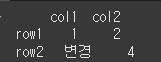
행, 열 값을 인수로 지정 후 값을 할당하여 값을 설정할 수 있습니다.df.at['row2', 'col1'] = '변경' print(df)
기타
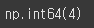
loc 메서드를 이용해 Series로 추출한 뒤 at메서드를 이용해 스칼라값을 얻는 방식으로 활용이 가능합니다.df.loc['row2'].at['col2']
레이블기반_데이터 (loc)
DataFrame.loc
loc 함수는 at 함수와 같이 레이블 기반으로 인덱싱을 합니다. DataFrame이나 Series형식으로의 반환이 필요하면 loc를 사용합니다.
행/열 설정에 따라 자유로운 인덱싱이 가능합니다.
loc는 bool 배열과 함께 사용이 가능합니다.
사용법
기본 사용법
값 가져오기 : result = df.loc['행', '열']
값 설정하기 : df.loc['행', '열'] = value
입력 가능한 Input
1. 레이블 (만약 3을 입력할 경우 정수위치가 아닌 index의 레이블로 해석
2. list 객체 (예 : ['a', 'b', 'c'])
3. 레이블의 슬라이스 객체 (예 : 'b' : 'f')
4. 슬라이싱되는 축과 길이가 같은 bool 배열 (예 : [True, True, False, True])
예시
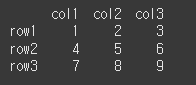
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
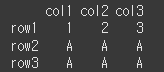
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3']) print(df)
값 가져오기
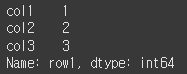
단일 레이블을 지정할경우 Series 형태로 반환됩니다.result = df.loc['row1'] print(result)
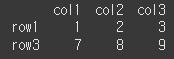
레이블로 구성된 리스트. [ [ ] ]를 사용하면 DataFrame형태로 반환됩니다.
result = df.loc[ ['row1','row3'] ] print(result)
행과 열을 설정하여 단일 레이블의 값을 입력가능합니다.
result = df.loc['row2', 'col2'] print(result)

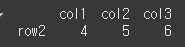
슬라이스를 이용하여 인덱싱을 할 수 있습니다.
result = df.loc['row1' : 'row3', 'col2'] print(result)
bool로 구성된 list를 이용하여 인덱싱을 할 수 있습니다.
bool = [False, True, False] # row2에 대응되는 값만 True result = df.loc[bool]
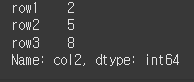
bool로 구성된 Series를 반환하는 조건문의 사용도 가능합니다. 아래의 경우 col3열에 대해서 5보다 큰 경우인 row2, row3행만 반환됩니다.
result = df.loc[ df['col3'] > 5 ] print(result)
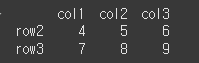
여기에 해당조건을 만족하는 특정 열을 반환할 수도 있습니다. 아래의 경우 col3에서 5보다 큰 값을 만족하는 행에 대해서 col2의 값만 반환합니다.
result = df.loc[ df['col3'] > 5, ['col2'] ] print(result)
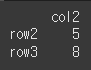
람다함수를 이용하여 인덱싱이 가능합니다. 아래의 경우 col2의 값중 5인 값을 만족하는 행을 반환합니다.
result = df.loc[lambda df : df['col2'] == 5] print(result)
값 설정하기
기본적으로 조건을 만족하는 모든 항목의 값이 변경됩니다.
레이블을 지정하여 값 설정하기.df.loc[ ['row1', 'row3'], ['col3'] ] = 'A' print(df)
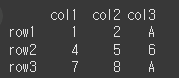
하나의 레이블만 지정할 경우 해당 행/열 전체의 값 설정이 가능합니다.
(실행 결과1)df.loc[ ['row1'] ] = 'A' # 행을 변경할 경우 print(df)
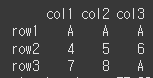
(실행 결과 2)df.loc[ : , ['col3'] ] = 'B' # 열을 변경할 경우 행을 전체선택 ( : ) 해줍니다. print(df)
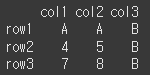
조건을 설정하여 만족하는 값의 변경이 가능합니다.
아래의 경우 col2에서 3보다 큰 열은 row2, row3이기 때문에 해당 열의 값이
전부 변경되었습니다.df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3']) df.loc[df['col2'] > 3] = 'A' print(df)
정수기반_스칼라 (iat)
DataFrame.iat
iat 함수는 iloc 함수와 같이 정수 기반으로 인덱싱을 합니다.
단일 스칼라값으로 반환하길 원한다면 iat함수를 사용합니다.
정수기반 조회 메서드입니다. 행/열 한쌍에 대한 단일 값에 엑세스합니다.
사용법
기본 사용법
값 가져오기 : result = df.iat['행', '열']
값 설정하기 : df.iat['행', '열'] = value
예시
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3']) print(df)
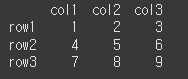
값 가져오기
정수기반 조회 메서드이기 때문에, 행/열 쌍을 정수로 입력해야합니다.
아래의 경우 [rows=1,columns=2] 를 출력하는 것으로, 0부터 시작하기 때문에 [row2, col3]의 값인 6을 출력하게 됩니다.result = df.iat[1,2] print(result)

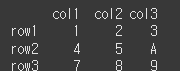
값 설정하기
마찬가지로 정수값을 지정하여 해당 행/열의 값을 바꿀 수 있습니다.df.iat[1,2] = 'A' print(df)
정수기반_데이터 (iloc)
DataFrame.iloc
iloc 함수는 iat 함수와 같이 정수 기반으로 인덱싱을 합니다.
DataFrame이나 Series형식으로의 반환이 필요하면 iloc를 사용합니다.
정수기반 조회 메서드입니다.
사용법
기본 사용법
값 가져오기 : result = df.iloc['행', '열']
값 설정하기 : df.iloc['행', '열'] = value
가능한 Input
1. 단일 정수값 (예 : 5)
2. 정수로 이루어진 list (예 : [3, 5, 1])
3. 정수 슬라이스 객체 (예 : 2:5 )
4. bool 배열
예시
먼저, 아래와 같이 기본적인 3x3 행렬을 만듭니다.
df = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2', 'col3']) print(df)
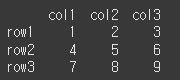
값 가져오기
단일 정수로 인덱싱 하는 경우 Series 형식으로 반환합니다.result= df.iloc[0] print(result)
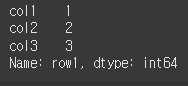
list형식으로 인덱싱하는 경우 DataFrame형식 으로 반환합니다.
result= df.iloc[[0,2]] print(result)
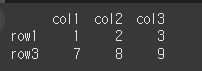
슬라이스의 사용이 가능합니다.
result= df.iloc[1:2] print(result)
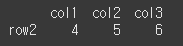
bool로 구성된 list를 이용하여 인덱싱을 할 수 있습니다.
bool_list = [True, False, True] result= df.iloc[bool_list] print(result)
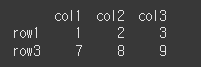
람다(lambda) 함수의 사용도 가능합니다. 아래의 경우 람다 함수를 이용하여 index가 row3인 경우에 대한 bool 배열을 이용한 예 입니다.
result= df.iloc[lambda x : x.index == 'row3'] print(result)
앞에서 n행 인덱싱 (head)
DataFrame.head(n=5)
head함수는 Dataframe 객체를 위에서부터 n열 반환하는 함수입니다.
기본값은 5입니다.
사용법
기본 사용법
df.head(n=5)
예시
먼저, head 함수의 사용을 위해 np.random함수로 10x10 난수 DataFrame를 만들어 보겠습니다.
data = np.random.randint(10,size=(10,10)) df = pd.DataFrame(data=data) print(df)

n=양수 n이 0보다 크면 위에서부터 n까지 열을 반환합니다.
print(df.head(3))
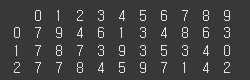
n=음수 n이 0보다 작으면 DataFrame의 끝에서부터 n개열을 제외하고 반환합니다.
print(df.head(-3))

주의사항 print로 출력시에 보이는 출력물만 n열까지 보여주는것이 아니라 실제 값이 바뀌는 것임을 염두해야 합니다.
아래를 확인해보세요check = df.head(3) print(check.index)
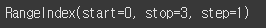
뒤에서 n행 인덱싱 (tail)
DataFrame.head(n=5)
tail함수는 Dataframe 객체를 아래에서부터 n열 반환하는 함수이다.
기본값은 5이다.
사용법
df.tail(n=5)
예시
먼저, tail 함수의 사용을 위해 np.random함수로 10x10 난수 DataFrame를 만들어 보겠습니다.
data = np.random.randint(10,size=(10,10))
df = pd.DataFrame(data=data)
print(df)
n=양수 n이 0보다 크면 아래에서부터 n까지 열을 반환한다.
print(df.tail(3))
n=음수 n이 0보다 작으면 DataFrame의 위에서부터 n개열을 제외하고 반환합니다.
print(df.tail(-3))

주의사항 print로 출력시에 보이는 출력물만 n열까지 보여주는것이 아니라 실제 값이 바뀌는 것임을 염두해야 합니다.
아래를 확인해보세요check = df.tail(3) print(check.index)
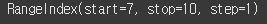
Multi Index의 경우
Multi Index의 경우에 사용하는 Indexing 기법을 알아보겠습니다.
예시
먼저, 아래와 같이 Multi Index를 가지는 DataFrame 객체를 만듭니다.
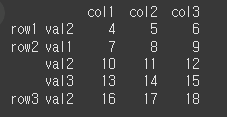
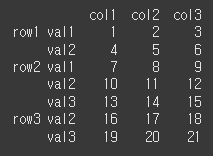
index_tuples = [('row1', 'val1'), ('row1', 'val2'), ('row2', 'val1'), ('row2', 'val2'), ('row2', 'val3'), ('row3', 'val2'),('row3', 'val3')] values = [ [1,2,3], [4,5,6], [7,8,9], [10,11,12], [13,14,15], [16,17,18], [19,20,21]] index = pd.MultiIndex.from_tuples(index_tuples) # 인덱스 설정 df = pd.DataFrame(values, columns=['col1', 'col2', 'col3'], index = index) print(df)
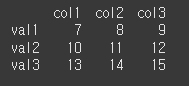
하나의 행을 지정할 경우 단일 index로 반환된다.
result = df.loc['row2'] print(result)
multi index에서 특정 index를 튜플로 지정할 경우 Series로 반환됩니다.
또한, 아래의 경우에서 튜플이 아니라 단일 행/열 레이블 형태로 입력하여도
같은 결과가 도출됩니다. (예 : result = df.loc[ ' row2', 'val2' ] )result = df.loc[('row2','val2')] print(result)
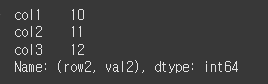
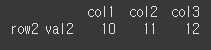
만약 DataFrame 형태로 반환하고 싶다면 [ [ ] ] 형태로 인덱싱하면됩니다.
result = df.loc[[('row2','val2')]] print(result)
여기에 열 값까지 설정해줄 경우 해당 값을 반환할 수 있습니다.
result = df.loc[('row2','val2'), 'col3'] print(result)

Multi Index의 튜플을 통해 슬라이스하여 인덱싱이 가능합니다.
result = df.loc[('row1','val2') : ('row3','val2')] # row1의 val2부터 row3의 val2까지 print(result)