인덱싱과 슬라이싱 개념
넘파이는 파이썬 리스트를 확장해서 만들었기 때문에 리스트가 제공하는 대부분의 기능을 사용할 수 있습니다. 하나의 데이터를 선택하는 인덱싱을 사용해 봅시다. arr[0]은 arr에 바인딩된 넘파이 객체의 0번째 데이터를 선택합니다. 인덱싱에 사용하는 인덱스는 리스트와 동일하게 데이터 하나에 하나씩 맵핑됩니다.
시작하기 전에 install 해주기!!
!pip install numpy import numpy as np(사용 예시)
arr = np.arange(4) print(arr[0])
2차원 ndarray의 경우 인덱싱은 기본적으로 행에 우선 적용됩니다. 다음 코드는 2차원 ndarray에서 0번째 행을 리턴합니다.
(사용 예시)arr = np.arange(4).reshape(2, 2) print(arr[0])

2차원 ndarray를 인덱싱하니 하나의 행이 ndarray로 선택됐습니다. 반환되는 결과가 ndarray라서 연쇄적으로 인덱싱을 적용하면 0번째 행의 0번째 열에 들어 있는 숫자 0이 출력됩니다.
(실행 예시)print(arr[0][0])

이차원 데이터에 대해 [행][열] 형태로 인덱싱하면 내부적으로 두 번에 인덱싱이 사용됩니다. ndarray에서는 이차원 데이터의 경우 [행, 열]과 같은 형태로 한 번에 특정 데이터를 인덱싱할 수 있습니다. 행과 열 사이에 콤마로 구분된 것에 주의하세요. 데이터의 양이 많아진다면 다음 두 개의 코드는 성능 차이가 생기기 시작합니다.
(실행 예시) (이렇게 똑같이 나오는 것을 확인할 수 있다.print(arr[0][0]) print(arr[0, 0])

주피터 노트북은 timeit이라는 특수 명령을 제공합니다. timeit 뒤에 나오는 코드를 1000만 번 반복 실행하고 걸린 시간의 평균을 반환합니다. 이차원 데이터의 [행, 열] 인덱싱의 실행 시간을 측정해보기
(실행 예시)a=np.arange(10000).reshape(100, 100) %timeit a[0,50]

두 번에 걸쳐 연쇄적으로 인덱싱하는 시간을 측정해보기
a=np.arange(10000).reshape(100, 100) %timeit a[0][50]

하나 이상의 데이터를 가져오는 슬라이싱을 사용해보기
arr = np.arange(4) print(arr[ :2])
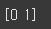
리스트의 기능에 추가해서 ndarray는 불연속적인 데이터를 슬라이싱할 수 있습니다.
target = [ 0, 2 ] print(arr[ target ])

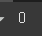
이차원 데이터의 슬라이싱도 사용해 봅시다. 여기까지는 리스트의 슬라이싱과 크게 다를 것이 없다
arr = np.arange(20).reshape(4, 5) print(arr[ :2])

ndarray는 한 번에 컬럼의 슬라이싱을 할 수 있습니다.
arr = np.arange(20).reshape(4, 5) print(arr[ : , :2 ])
4행 5열의 ndarray에서 그림 2.4.1과 같이 일부 영역을 슬라이싱해 해보기!print(arr[ 1:4, 2:5]) print(arr[ 1: , 2: ])