넘파이란?
넘파이(Numpy)는 Numeric과 Python의 합성어로 수학 및 과학 연산을 위한 파이썬 패키지입니다. 넘파이의 ndarray 객체를 사용하면 다차원 배열과 행렬을 보다 쉽게 다룰 수 있습니다. 반복문을 사용하지 않고도 전체 데이터에 연산을 적용할 수도 있으며, 다양한 선형 대수학, 변환 (transform) 기능까지 지원합니다. 이 책에서 다룰 파이썬 판다스가 넘파이를 기반으로 만들어졌기 때문에 우선은 넘파이의 기본에 대해 공부해 보겠습니다.
넘파이 설치
!pip install numpy import numpy as np
넘파이 사용 예시
import numpy as np data = [1, 2, 3] arr = np.array(data) print(arr) print(type(arr))
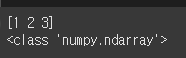
다음의 출력된 결과만 봤을 때는 파이썬 기본 자료구조인 리스트와 크게 다르지 않습니다. array 함수에 의해 생성된 객체의 타입이 ndarray임을 확인할 수 있습니다.
넘파이를 활용하면 왜 편할까?
넘파이는 반복문을 사용하지 않고 단순히 ndarray 객체에 10을 곱하면 ndarray 객체의 모든 원소에 동일한 연산이 반복적으로 적용됩니다. 반복문을 사용하지 않아 코드도 짧고 심지어 실행속도도 더 빠릅니다. 이렇기 떄문에 사용합니다.
사용 예시
넘파이(X)data = [1, 2, 3] result = [] for i in data: result.append(i*10) print(result)
넘파이(O)
import numpy as np arr = np.array([1, 2, 3]) result = arr * 10 print(result)
넘파이 인덱싱 arr[행 인덱스, 열 인덱스]
넘파이를 사용하면 arr[행 인덱스, 열 인덱스] 또는 arr[행 인덱스][열 인덱스]와 같은 표현을 통해 특정 위치의 원소에 접근할 수 있습니다. 위 코드에서 행 인덱스에 콜론(:)을 사용한 것은 모든 행을 선택하는 것을 의미합니다. 범용적인 프로그래밍에서 사용되는 파이썬 리스트와 달리 넘파이의 ndarray 객체를 사용하면 행렬과 다차원 배열을 보다 쉽게 다룰 수 있습니다.
사용 예시
넘파이(X)data2d = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] print(data2d[0])
넘파이 (O)
import numpy as np data2d = [1, 2, 3], [4, 5, 6], [7, 8, 9] arr = np.array(data2d) print(arr[ :, 0])

ndarray 개념
파이썬에 리스트, 튜플, 딕셔너리와 같은 기본 데이터 타입이 있는 것처럼 넘파이에는 다차원 배열을 위한 ndarray 클래스(타입)를 제공합니다. 1차원 리스트를 넘파이의 array 함수에 전달하면 쉽게 ndarray 객체로 변환할 수 있습니다. 범용적인 용도로 사용되는 파이썬 리스트 타입을 행렬과 다차원 배열에 최적화된 ndarray 타입으로 변환하는 겁니다.
ndarray 변수 사용해보기
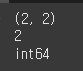
ndarray 객체의 인스턴스 변수를 사용해서 저장된 데이터의 정보를 조회할 수 있습니다. shape은 ndarray의 크기 정보를, ndim은 차원 정보, dtype은 데이터 타입을 표현합니다.
data2 = [ [1, 2], [3, 4] ] print(arr2.shape) print(arr2.ndim) print(arr2.dtype)
data2 = [ [1, 2], [3, 4] ] print(np.zeros(3)) print(np.ones(3))
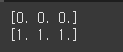
size = (3, 4) print(np.zeros(size))
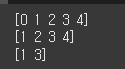
print(np.arange(5)) print(np.arange(1, 5)) print(np.arange(1, 5, 2))
넘파이 배열의 형상(shape)
넘파이는 배열의 형상(shape)을 변경할 수 있는 reshape 함수를 제공합니다. 다음 예제와 같이 6개의 원소로 구성된 1차원 배열 ndarr1을 2행 3열의 ndarray로 변환합니다.
ndarr1 = np.arange(6) ndarr2 = ndarr1.reshape(2, 3) print(ndarr2)참고로 reshape 메서드의 행과 열의 개수는 원본 데이터를 고려해서 입력해야 합니다. 6개의 데이터가 담긴 ndarr1을 reshape(4, 4)로 변환을 시도하면 원본 데이터가 부족해서 에러가 발생합니다.
데이터 타입
파이썬에는 정수(int), 실수(float), 문자열(str)과 같은 기본 데이터 타입이 존재합니다. 기본 데이터 타입은 사용하기 편리하지만, 항상 데이터를 넉넉한 공간에 저장하기 때문에 메모리 및 보조 저장 장치의 공간을 효율적으로 사용할 수 없습니다. 공간을 많이 차지하기 때문에 대용량의 데이터를 처리하는 시간이 오래 걸릴 수도 있습니다.
넘파이 주요 데이터 타입

데이터 타입 실습해보기
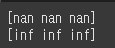
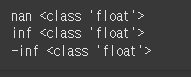
print(np.nan, type(np.nan)) print(np.inf, type(np.inf)) print(-np.inf, type(-np.inf))
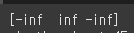
arr = np.array([-1, 2, -3]) print(arr/0)
arr = np.array([-1, 2, -3]) print(arr + np.nan) print(arr + np.inf)