Ch3 p.92에서 cross_val_score로 데이터에서 5와 5가 아닌 데이터를 분류하는 코드를 작성한 뒤, 점수를 도출하였다. 5가 아닌 데이터를 뽑아내는 정확도가 각 fold마다 90% 이상이 나왔는데 그 이유는 단지 5가 전체 데이터의 10%에 해당하므로 5가 아닌 데이터가 나머지인 90% 이상으로 나올 수밖에 없기 때문이었다. 이는 accuracy가 왜 classifier 모델의 평가 지표가 될 수 없는지("especially when you are dealing with skewed datasets, when some classes are much more frequent than others") 보여준다.
그렇다면 classifier 모델을 제대로 평가할 수 있는 지표가 뭘까? 이 책에서는 Confusion Matrix, Precision, Recall, PR curve, ROC curve 등을 소개한다.
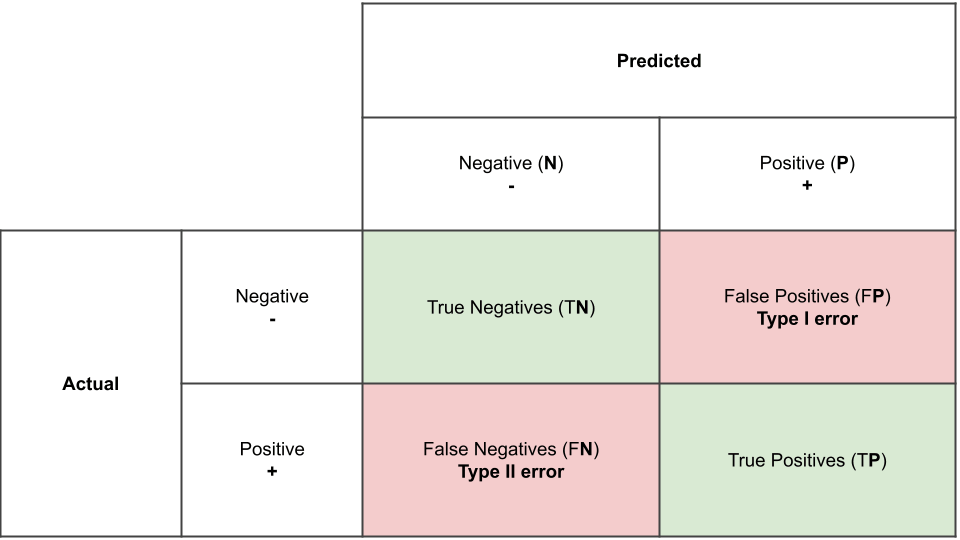
1) Confusion Matrix
a specific table layout that allows visualization of the performance of an algorithm, typically a supervised learning one
각 row는 actual class를, 각 column은 predicted class를 나타내며, (만약 5와 5가 아닌 수를 분류하는 문제라고 하면) Negative은 5가 아닌 수들, Positive는 5인 수들을 나타낸다. 그러므로 actual class로 5가 아닌 수(Negative)가 5가 아닌 수(Negative)로 예측이 된다면 이는 True Negative로 분류되고, 5(Positive)가 5(Positive)로 예측이 된다면 True Positive로 분류된다. 반면 5가 아닌 수지만 5로 예측이 된 경우에는 False Positive로, 5가 5가 아닌 수로 예측이 된 경우에는 False Negative로 분류되며 아래의 표와 같이 나타낼 수 있다.
[13]번 코드는 5와 5가 아닌 데이터를 confusion matrix로 나타낸 것이고, [14]번 코드는 FP와 FN은 각각 error에 해당하기 때문에 이를 제외한 이상적인 형태의, 잘 분류된 matrix를 나타낸 것이다.

2) Precision and Recall
2-1) Precision
the accuracy of the positive predictions
완벽한 precision을 만들기 위해서는 잘못된 positive 예측 하나씩 제대로 분류하면 된다. 하지만 이는 그 수 외의 수들을 완전히 무시하게 되는 문제가 있다. 그러므로 Precision은 Recall과 일반적으로 함께 사용된다.
2-2) Recall
thr ratio of positive instances that are correctly detected by the classifier
2-3) score
precision과 recall을 combine한 metric
위 식에서 볼 수 있듯, score을 계산할 때에는 harmonic mean을 사용한다. -> rate으로 구성되어 있는 경우 평균을 계산하기 위해 더 적합 참고1 참고2
2-4) sklearn에서 제공하는 클래스
scikit learn에는 precision, recall, f1 score를 계산하는 클래스가 마련되어 있다.

3) Precision/Recall Tradeoff
SGDClassifier가 classification decision을 하는 방법 -> decision function을 기반으로 한 score를 계산한 뒤 이 점수가 threshold보다 크면 해당 instance를 positive로, 작으면 negative로 분류한다.
아래의 표는 lowest score에서 highest score을 가진 이미지를 순서대로 나열한 것이다. 표에 있는 세 개의 threshold를 기준으로 Precision과 Recall을 계산해보면, 둘 사이에는 하나가 증가하면 하나는 감소하는, trade-off 관계가 있음을 알 수 있다.

threshold를 임의로 바꾸면 그에 따라 분류 결과가 True->False로 바뀐다.

적절한 threshold를 찾기 위해 precision, recall versus threshold 그래프를 그리려고 한다. 그러기 위해선 모든 instances에 대한 scores를 계산해야 하는데, 이번에는 cross_val_predict 클래스에서 method를 decision_function으로 지정하여 scores를 얻으려고 한다.
precisions, recalls, thresholds 값은 precision_recall_curve를 통해 얻을 수 있으며, 이를 기반으로 그래프를 그린 결과는 다음과 같다.

Precision을 직접적으로 Recall에 대응해서 그리는 방법도 있다. -> PR curve
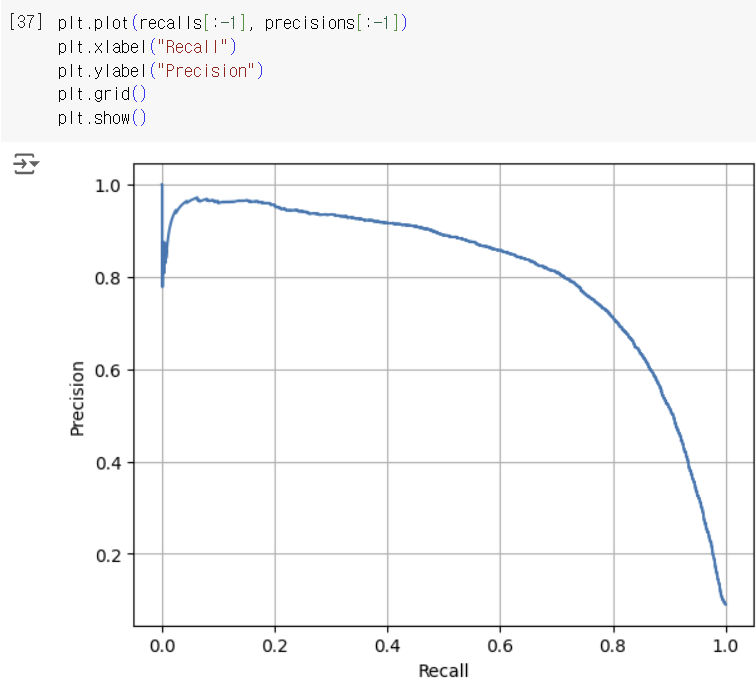
아래 코드는 precision이 0.90 이상인 값들 중 가장 작은 인덱스를 구하고, 이 인덱스 이상인 값들에 대해 1의 값을 갖는 y_train_pred_90을 만들어 예측 결과로 삼아, precision과 recall 점수를 구한 것이다. precision은 0.90 이상인 것을 볼 수 있지만, recall이 0.4x로 매우 낮음을 알 수 있다. precision이 높은 이 그래프는 recall이 너무 낮기에 그렇게 좋은 classifier라고 할 수 없다.

4) ROC curve
PR curve와 더불어 Receiver Operating Characteristic (ROC) curve도 binary classification의 유용한 도구가 될 수 있다. ROC curve는 true positive rate(Recall)을 false positive rate에 대해 나타낸다. FPR는 1 - true negative rate로 나타낼 수 있다. TNR는 specificity라고도 불리고 TPR은 sensitivity라고도 불리기 때문에 이 그래프는 sensitivity를 1 - specificity에 대해 나타냈다고 말할 수 있다.
앞의 precision_recall_curve와 비슷하게 roc_curve라는 함수를 통해 fpr, tpr, threshold 값을 구할 수 있으며 이를 이용하여 그래프를 그릴 수 있다. 아래 그래프에서 대각선은 "the ROC curve of a purely random classifier"라고 볼 수 있고, 좋은 분류기 일수록 이 대각선에서 최대한 멀어져야 한다.

ROC curve로 binary classifier들의 성능을 비교할 수 있는데, 정확하게 비교하는 방법으로는 그래프 아래의 넓이를 측정하는 방법을 택할 수 있다. -> area under the curve (AUC)
1에 가까울수록 완벽한 분류기라고 할 수 있고, 0.5에 가까울수록 purely random하다고 볼 수 있다.
위 그래프의 AUC를 구한 결과 0.96이 나왔다.

이번에는 SGDClassifier(기존에 쓰던 분류기)와 RandomForestClassifier의 분류기 성능을 비교해보려고 한다. SGD와 다르게 RandomForest에는 score를 계산하기 위한 decision_function method가 없어서 대신에 predict_proba method를 이용해야 한다. (scikit learn의 classifier에는 위 두 개의 메서드 중 하나는 꼭 있다고 함)
difference between prediction functions
그런데 predict_proba는 score를 반환하는 게 아니라 probability를 반환하므로 score로 positive class의 probability를 이용할 수 있다고 한다. -> row는 instance들을, column은 class들을 의미하며 instance가 class에 속할 가능성에 대한 값들을 포함한다.
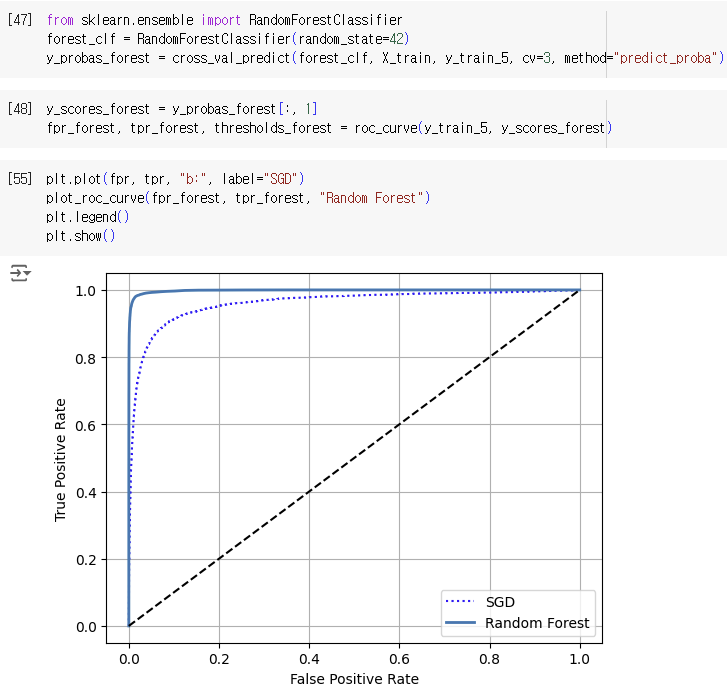
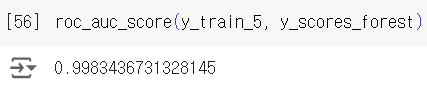
RandomForestClassifier가 SGDClassifier보다 분류 성능이 좋음을 위 그래프를 통해서도 확인할 수 있고, 아래 계산을 통해서도 확인할 수 있다.
5) When to use PR or ROC curve?
PR curve
- imbalanced datasets: positive class가 적은 경우
- costly false positives: FP가 FN보다 중요한 경우
ROC curve
- more balanced datasets
출처: Hands-On Machine Learning by Aurelien Geron
