SVM을 공부하던 중 모델을 학습하기 전에 feature scaling을 해야한다는 이야기가 있었음. 내가 아는 바로는 feature scaling 방법으로 normalization과 standardization이 있는데, 왜 여기서 후자의 방법을 택하는지 궁금했음. 그리고 여기서 뿐만 아니라 데이터를 스케일링할 때 두 방법 중 어떤 걸 택해야할지 늘 고민되었음. 그래서 이번 기회에 두 개념에 대해 정리하고 각 쓰임에 대해서 알아보려고 함
참고한 내용은 다음과 같다.
https://sebastianraschka.com/Articles/2014_about_feature_scaling.html#about-standardization
https://www.baeldung.com/cs/normalization-vs-standardization
여러 블로그를 살펴봤는데, normalization, min-max scaling, standardization의 범위 구분이 다 달랐다. 그 중 그나마 가장 그럴듯한 구분으로 설명을 하려고 한다. 근데 이게 맞는듯! -> 참고
피처들을 정규화하는 것은 크기가 다른 데이터들을 측정할 때 뿐만 아니라 gradient descent에서도 중요하다. 아래의 식에서 볼 수 있듯 feature value x는 w의 업데이트에서 영향을 미치는데, 그 크기가 클 경우 weight의 업데이트가 더 빠르게 일어날 수 있기 때문이다. 함수 J는 일반적으로 손실함수를 나타내며, 여기서 t와 o는 각각 target class label과 actual output이다. (참고로, 데이터 스케일링에 영향을 받지 않는 알고리즘으로는 tree 기반의 알고리즘들이 있다.)
그러므로 모든 데이터가 같은 정도의 중요도를 반영해주도록 normalization(정규화)를 해주어야 한다.
normalization의 종류에는 여러 가지가 있는데, 그 중에서도 standardization과 min-max scaling에 대해서 다루어보려고 한다.
Standardization(표준화) or Z-score normalization을 진행하면 평균()이 0, 표준편차()가 1이 되므로, 데이터를 스케일링할뿐 아니라 centralizing도 한다. 이는 population parameter(모수: 모집단 분포 특성을 규정 짓는 척도)를 알고 있을 때 사용되며, normal distribution(정규분포)를 가지는 경우 잘 작동한다고 한다.
Min-Max scaling에서는 표준화와 달리 데이터가 고정된 범위(주로 0 to 1이지만 feature_range 매개변수를 사용해 다른 범위로 변경할 수 있음!)로 스케일링된다. 어디서 읽은 건데 대부분의 경우에는 standardization을 선호?하지만 이미지(0~255) 스케일링의 경우 min-max scaling을 사용한다고 했음
위 스케일링을 적용한 예시를 보자.
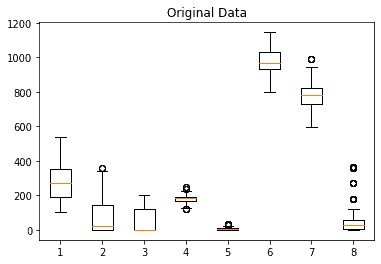
MinMaxScaler를 진행한 결과, 마지막 피처에 극단적인 이상치가 대부분의 데이터들을 더 작은 범위로 만든 것을 알 수 있다.
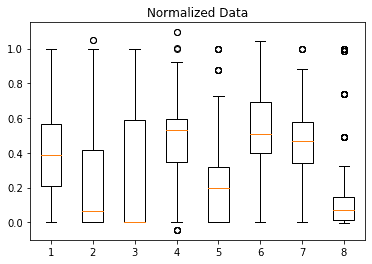
마지막 피처를 비교하면, 여기서는 이상치가 대부분의 데이터들의 변환에 영향을 미치지는 않는다.
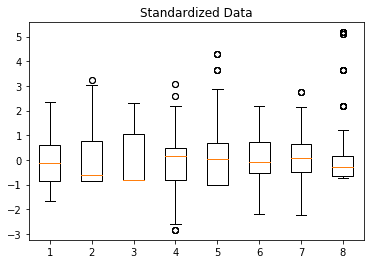
아래의 파란점들은 input feature들의 actual value들이고, 빨간점들은 standardized value들, 초록점들은 min-max scaling한 value들이다. min-max scaling에서 데이터포인트들 사이의 간격이 매우 작으며, standardization과 비교했을 때 전체 범위가 작은 것을 확인할 수 있다.

Feature Scaling과 관련된 내용은 이 블로그의 4-3)에서 더 다루고 있으니 읽어보시길 ㅊㅊ! ➡️모델 훈련 전에는 뭘 해야 하나요?
