이전 글과 내용이 비슷한 것 같지만 다름ㅎㅎ 둘 다 봐야 함!
https://velog.io/@shihyunlim/ML-SGD
1) Gradient Descent
최적화 알고리즘. 비용 함수를 최소화하기 위해 반복해서 파라미터를 조정
가장 가파른 길을 따라 내려가는 것
2차원 공간에서 경사 하강법의 이동(사진, 영상 ㅊㅊ)
출처: https://en.wikipedia.org/wiki/Gradient_descent
랜덤 초기화(random initialization): 를 임의의 값에서 시작
-> 비용 함수가 감소하는 방향으로 조금씩 조정, 반복
-> 최솟값에 수렴할 때까지
학습 스텝의 크기는 비용 함수의 기울기에 비례. 학습률 파라미터로 결정
학습률 크기에 따른 이동
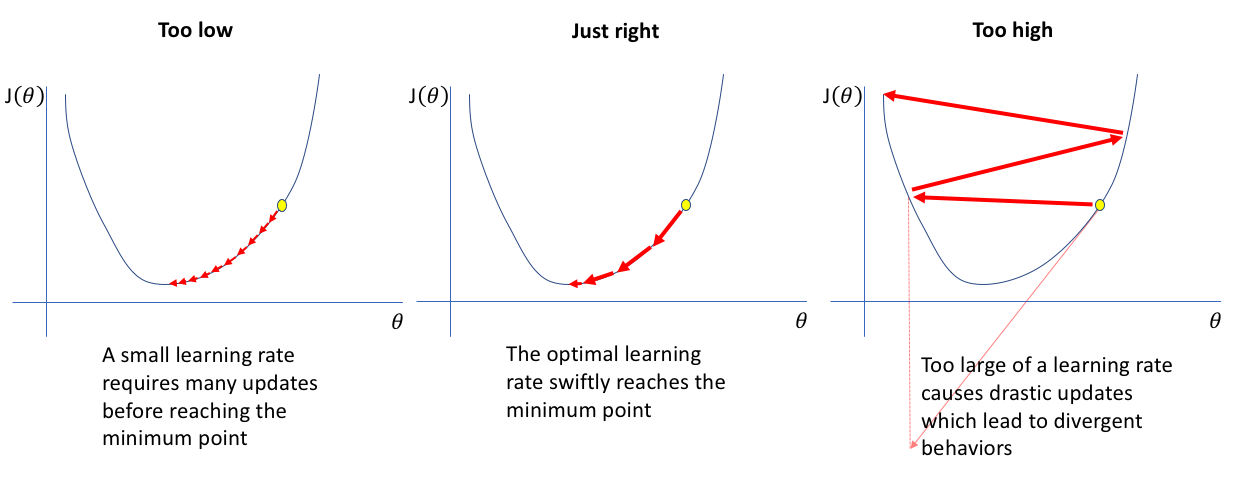
출처: https://www.jeremyjordan.me/nn-learning-rate/
경사하강법의 한계(+SGD, Mini-batch GD)
이전 블로그 참고
선형 회귀를 위한 비용 함수인 MSE는 볼록 함수(convex function)기 때문에 local minima가 없고 global minima만 존재. 또한 연속된 함수이며 기울기가 갑자기 변하지 않음
-> GD는 global minima에 근접하게 됨
*convex: 어떤 두 점을 선택해 선을 그어도 곡선을 가로지르지 않음
비용 함수는 그릇 모양을 하고 있지만, 특성들의 스케일이 다르면 길쭉한 모양일 수 있음. 스케일이 된 경우 알고리즘은 최솟값으로 곧장 진행하지만, 다른 경우 골짜기를 길게 돌아가서 가므로 오래 걸림
-> GD 전에 StandardScaler()로 스케일을 먼저 하자
파라미터 공간(parmeter space): 모델 파라미터 조합(비용 함수를 찾는 건 최상의 파라미터 조합을 찾는 것. 모델의 파라미터 공간에서 찾는 것)
파라미터가 많을수록 공간의 차원이 커지고 minima 찾기 어려움. but 선형 회귀의 비용 함수는 convex하므로 그릇의 맨아래로 가면 돼서 ㄱㅊ
2) Batch Gradient Descent
배치 경사 하강법 -> 매 스텝마다 전체 훈련 세트 X에 대해 계산 -> epoch마다 전체 훈련 세트 이용. 여기서 batch size=훈련 세트 전체
epoch: 훈련 세트를 한 번 반복하는 것
batch: 모델의 가중치를 한 번 업데이트할 때 사용하는 데이터 집합
*iteration: 1 epoch에 필요한 batch 수
경사 하강법 -> 각 모델 파라미터 에 대한 비용 함수의 그래디언트 = 가 조금 변할 때 비용 함수가 바뀌는 정도 -> partial derivative(편도 함수) 이용
-
파라미터 에 대한 비용 함수의 편도 함수
-
비용 함수의 그래디언트 벡터(편도 함수 모두 포함)
-
경사 하강법의 스텝 업데이트. 여기서 학습률로 내려가는 정도 조정
학습률 지정 how? GridSearchCV()로 최상의 학습률 찾기. 그리드 서치가 수렴하는 데 오래걸리는 걸 방지하기 위해 모델 반복 횟수 제한 필요
반복 횟수 지정 how? 아주 크게 지정하고 그래디언트 벡터가 허용 오차(tolerance)보다 작아지면 중지. tolerance 범위 안에 도달하기 위해서는 O(1/tolerance)의 반복 필요 -> "convergence rate(수렴률)"
예) tolerance=일 때 tolerance 오차 범위 내에 도달하기까지 필요한 시행 횟수는 임
3) Stochastic Gradient Descent
훈련 세트의 크기가 매우 커지면 시간 오래걸림. 확률적 경사 하강법은 매 스텝에서 샘플 한 개만 랜덤으로 선택하여 그래디언트 계산. 알고리즘 속도 훨씬 빠르지만 불안정함. 지역 최솟값을 건너뛰도록 도울 수는 있지만 전역 최솟값에 도달하지 못할 수도 있음 -> 학습률을 점진적으로 감소시키면 됨. 매 반복에서 학습률을 결정하는 함수인 learning schedule 이용
SGDRegressor 모델 파라미터(출처: 사이킷런 공식 문서)
max_iter: The maximum number of passes over the training data (aka epochs). It only impacts the behavior in the fit method, and not the partial_fit method.
tol: The stopping criterion. If it is not None, training will stop when (loss > best_loss - tol) for n_iter_no_change consecutive epochs. Convergence is checked against the training loss or the validation loss depending on the early_stopping parameter.
eta0: The initial learning rate for the ‘constant’, ‘invscaling’ or ‘adaptive’ schedules. The default value is 0.01.
early_stopping: Whether to use early stopping to terminate training when validation score is not improving. If set to True, it will automatically set aside a fraction of training data as validation and terminate training when validation score returned by the score method is not improving by at least tol for n_iter_no_change consecutive epochs.
n_iter_no_change: Number of iterations with no improvement to wait before stopping fitting. Convergence is checked against the training loss or the validation loss depending on the early_stopping parameter.
모든 사이킷런의 추정기는 fit()으로 훈련. 일부는 partial_fit()으로 하나 이상의 샘플에서 한 번의 반복 훈련을 할 수 있음. partial_fit()을 반복적으로 호출하면 모델이 점진적으로 훈련됨. 다른 모델에는 대신 warm_start 파라미터가 있음. True로 설정하면 fit()을 호출해도 모델이 재설정되지 않고 max_iter나 tol을 반영하여 중지된 지점부터 훈련 재개.
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-5, penalty=None, eta0=0.01, n_iter_no_change=100, random_state=42, verbose=1)
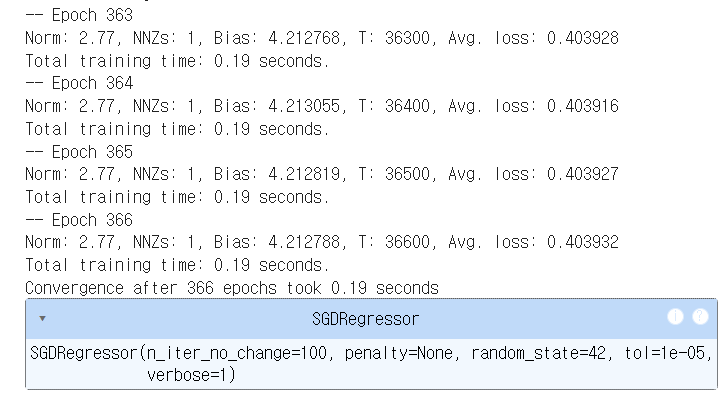
sgd_reg.fit(X, y.ravel()) #fit이 1D 타깃 기대위 코드와 sklearn 문서에서 모델 파라미터에 대한 설명을 비교했을 때, 코드에 early_stopping이 설정되지 않아도 tol과 n_iter_no_change에 따라 멈출까 의문이 들었음. 그런데 verbose=1로 설정해서 학습 과정과 멈춘 시점을 확인했더니 epoch가 366으로 수렴했음을 확인할 수 있었음
4) Mini-batch Gradient Descent
임의의 작은 샘플 세트, 즉 미니배치에 대해 그레디언트를 계산하는 것. 크기를 적당히 크게 하면 SGD보다 덜 불규칙하며 BGD보다 시간은 빠른 모델을 만들 수 있음. 하지만 local minima에서 나오기는 어려울 수 있음
