끝나지 않는 Ch3, 행복하다
Multiclass Classification에 대한 전체적인 구조, 내용, 그리고 지난번에 공부했던 confusion matrix와 관련하여 생긴 의문과 해결에 대해 다뤄보려고 한다.
Binary Classification은 두 개의 클래스를 분류하는 것, Multiclass Classification은 두 개 이상의 클래스를 분류하는 것이다.
Multiple한 클래스를 directly 분류하는 알고리즘(예: LogisticRegression, RandomForestClassifier, GaussianNB)이 있는 반면 나머지는 binary classifiers들이다(예: SGDClassifier, SVC). 그런데 binary classifier를 여러 개 이용하여 multiclass classification을 구현하는 방법이 존재한다고 한다!!
1) one-versus-all
*one-versus-all(OvA) 또는 one-versus-the-rest(OvR)
0부터 9까지의 이미지 데이터를 담고 있는 데이터셋을 분류한다고 하자. OvA는 10개의 binary classifier를 학습하도록 한다. 각 binary classifier는 0 detector(0: positive, 0이 아닌 수: negative), 1 detector(1: positive, 1이 아닌 수: negative), ..., 9 detector(9: positive, 9가 아닌 수: negative)로 구성되며, 어떤 이미지를 입력으로 넣고 10개의 classifier에 대해 학습한 결과로 나오는 decision score(decision_function에 넣으면 나오는 score) 중 가장 높은 score을 가진 클래스가 output class가 된다.
2) one-versus-one
one-versus-one(OvO)는 모든 클래스(숫자)의 조합에 대해 binary classifier를 학습하는 방법이다. N개의 class가 있는 경우 개의 classifier를 사용하게 된다.
총 10개의 class가 있는 MNIST 데이터셋은 0 -> 1~9, 1 -> 2~9, 2 -> 3~9, ..., 8 -> 9, 9 -> x로 개의 binary classifier를 사용한다.
output class는 "싸움에서 이긴 횟수"가 가장 많은 class가 된다.
3) OvA or OvO?
Some algorithms(such as Support Vector Machine Classifiers) scale poorly with the size of the training set, so for these algorithms OvO is preferred since it is faster to train many classifiers on small training sets than training few classifiers on large training sets. For most binary classification algorithms, however, OvA is preferred.
-> SVM과 같은 일부 알고리즘은 훈련 세트의 크기가 커질수록 학습 속도가 느려진다. OvO 방식은 각 클래스 쌍에 대해 이진 분류기를 학습시키므로, 많은 수의 작은 훈련 세트를 사용한다. 이는 소수의 큰 훈련 세트를 사용하는 것보다 학습 속도가 빠르기 때문에, 전체 훈련 시간을 줄일 수 있다.
반면 OvA는 구현이 간단하고, 관리해야 할 분류기의 수가 적기 때문에 대부분의 이진 분류 알고리즘에서 사용된다.
scikit learn은 binary classification algorithm을 multiclass classification으로 사용할 때를 알아서 감지하고 OvO를 사용하는 SVM을 제외한 나머지 알고리즘에서는 OvA 방식을 사용하도록 한다.
4) code
SGDClassifier를 multiclass classification에 사용했다. 책에서는 안 그랬는데 직접 코드를 치니까 5를 나타내야 할 some_digit이 3으로 예측되었다. sklearn은 자동으로 OvA 방식으로 10개의 binary classifier를 이용하여 분류하였고, 이는 decision score가 총 10개 나온 것을 통해서도 확인 가능하다.
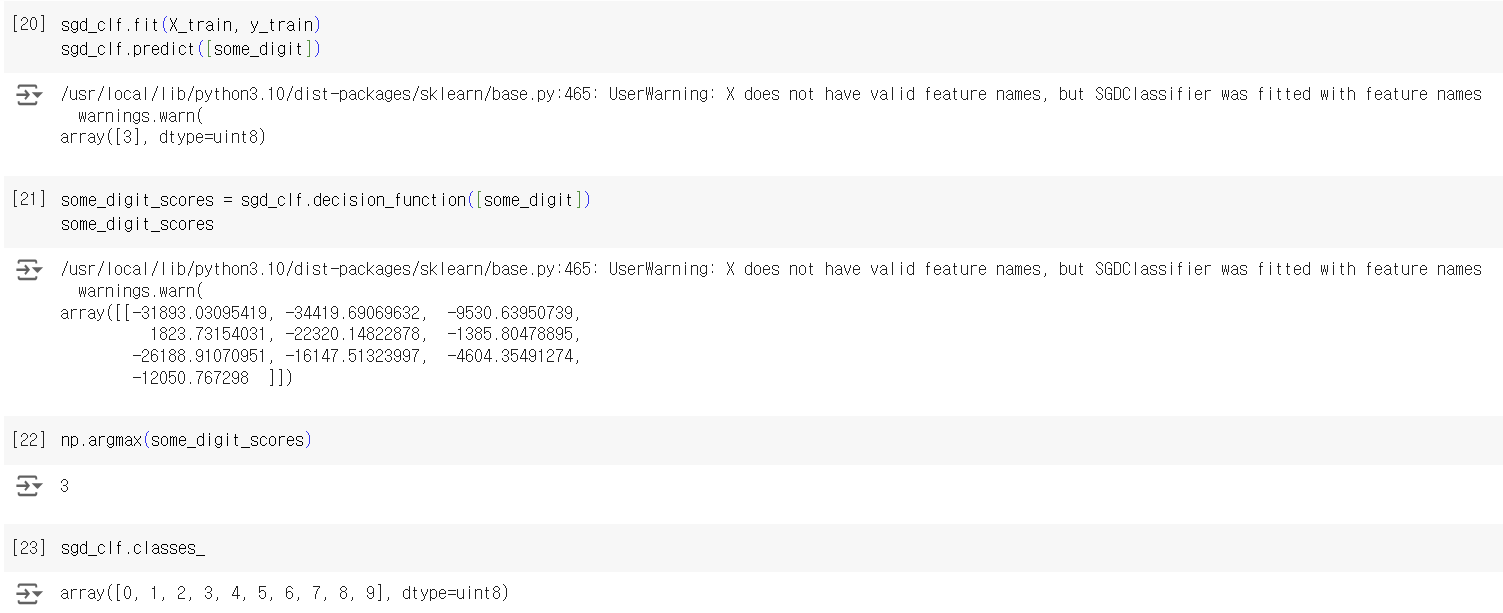
만약에 sklearn이 "강제로" one-versus-one 혹은 one-versus-all 방식을 사용하도록 만들고 싶다면? -> OneVsOneClassifier, OneVsRestClassifier 클래스를 각각의 경우 사용하면 된다.
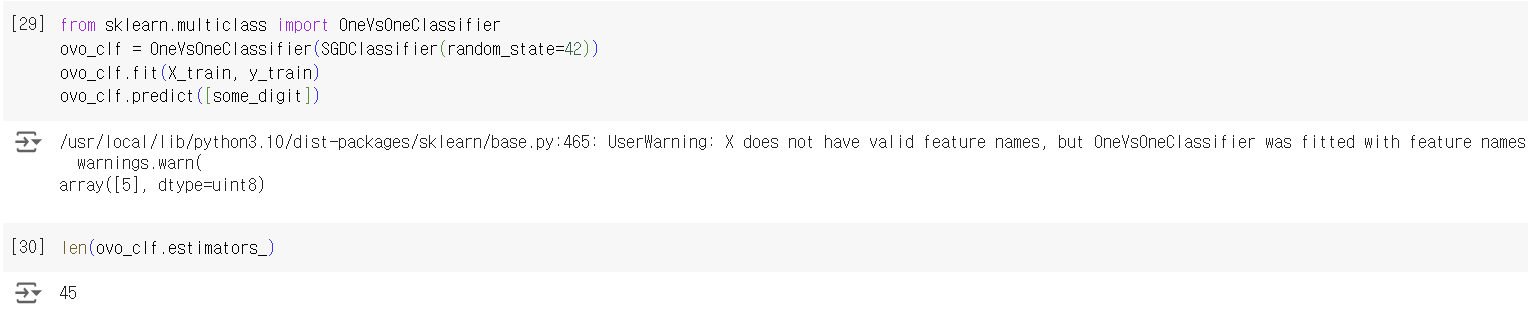
자동으로 OvA가 적용되는 SGDClassifier에 OvO가 적용되도록 만든 코드이다. 웃기게도 5로 잘 예측한 것을 확인할 수 있고, estimators_를 통해 총 45개의 binary classifier가 사용된 것을 볼 수 있다.
아래의 경우에는 OvA 또는 OvO 방식이 사용되지 않았다. Random Forest Classifier는 binary classifier들을 여러 개 이용하여 multiclass classification을 하는 방식이 아니라 multiclass classification을 directly 하는 경우기 때문!! 또한, 앞에서 여러 개의 분류기가 구한 decision_function에 의한 decision score를 보여주는 대신, predict_proba를 통해 각 클래스로 예측될 확률을 directly 확인할 수 있다.

참고로, 모델을 그냥 사용했을 때보다 scaling을 하고 난 뒤에 성능이 더 높게 나온 것을 볼 수 있다.

의문 & 해결
왜 앞에서는 classifier를 평가하는 방법으로 accuracy가 그닥 좋지 않은 방법이라고 했으면서 여기서는 cross_val_score로 성능을 평가했지?
-> 앞 코드와 비교하니까 앞에서는 5와 none 5를 분류함. 이는 classification을 요구하는 문제 중에서도 skewed dataset, when same classes are much more frequent에 해당되기 때문에 accuracy가 정확하지 않다고 판단한듯
-> 그런데 여기서는 0부터 9까지의 class의 prob를 판단한 것이므로 skewed가 아니라서 cross_val_score를 쓴 듯
출처: Hands-On Machine Learning by Aurelien Geron
