내 첫 머신러닝 프로젝트는 작년 여름에 했던 LG Aimers였다. 이때는 데이터 분석이 뭔지도 몰랐고, 머신러닝이 뭔지는 더더욱 몰랐다. 그래서 같은 팀의 언니들과 친구 덕분에 결과물을 만들 수 있었다. 이 이후에 데이터 분석 스터디, 딥러닝 스터디 등 많은 스터디와 프로젝트를 해봤지만, 머신러닝 프로젝트가 어떻게 진행되는지에 대해 감을 잡은 건 불과 한두 달 전이다. 그동안 했던 게 쌓인 결과라고 할까? 올해 LG Aimers에서는 간단한 전처리, 모델링, 예측까지 스스로 코드를 작성해낼 수 있었다. (물론 지피티 도움도 많이 받았음ㅎ)
이런 감을 가지기까지 많은 시행착오를 거쳤지만, 사실 아직까지도 머신러닝 프로젝트를 어떤 순서대로 진행해야 되고, 각각의 스탭에서 어떤 작업을 해야 하는지에 대한 나만의 지침? 방법론?은 없어서 늘 이 공부에 대한 필요성을 느끼고 있었다.
그럼 이제 시작해 보도록 하자...
핸즈온 머신러닝에서 제시하는 주요 단계는 이와 같다. 이 중 이번 글에서 다룰 부분은 1~4번이다.
1. 문제를 정의하고 큰 그림을 그립니다.
2. 데이터를 수집합니다.
3. 인사이트를 얻기 위해 데이터를 탐색합니다.
4. 데이터에 내재된 패턴이 머신러닝 알고리즘에 잘 드러나도록 데이터를 준비합니다.
5. 여러 다른 모델을 시험해보고 가능성 있는 몇 개를 고릅니다.
6. 모델을 미세 튜닝하고 이들을 연결해 최선의 솔루션을 만듭니다.
7. 솔루션을 제시합니다.
8. 시스템을 론칭하고, 모니터링하고, 유지 보수합니다.1) 큰 그림을 그리자
(여태까지 내가 경험한 바(해커톤)로 문제와 데이터는 주어졌지만, 나중에 하게 될 프로젝트에서 내가 직접 문제를 정의해야 하는 경우를 대비해서...)
문제를 정의하는 것/목적을 아는 것은 내가 이후에 어떤 알고리즘을 택할지, 모델 평가에 어떤 성능 지표를 사용할지, 모델 튜닝을 위해 얼마 만큼의 노력을 투여할지를 결정하기 때문에, 이를 데이터 처리 component와 component들을 연결한 pipeline으로 설정해두는 게 매우 중요하다.
pipeline 설정이 끝나면 문제를 어떤 식으로 해결할지 아래의 3가지에 대해 하나씩 답을 내어 결정해야 한다.
-> 1) 훈련 지도 방식, 2) 점직적 학습 vs 배치 학습, 3) 사례 기반 학습 vs 모델 기반 학습
다음 단계는 모델을 평가하는 데 어떤 성능 지표를 사용할지 선택하는 건데, 이와 관련된 내용은 따로 정리해두겠다.
참고 글 -> https://bigdaheta.tistory.com/53
https://white-joy.tistory.com/9
https://velog.io/@jjw9599/machinelearningevaluation
2) 데이터를 가져오자

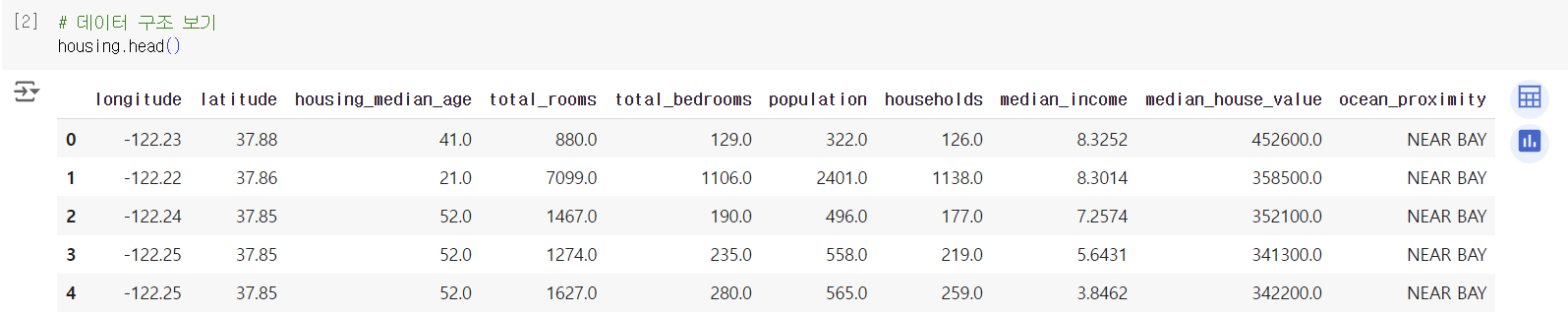




-> 데이터를 train과 test set으로 나눌 때 일반적으로 사용함. 얘를 random sampling이라고 함

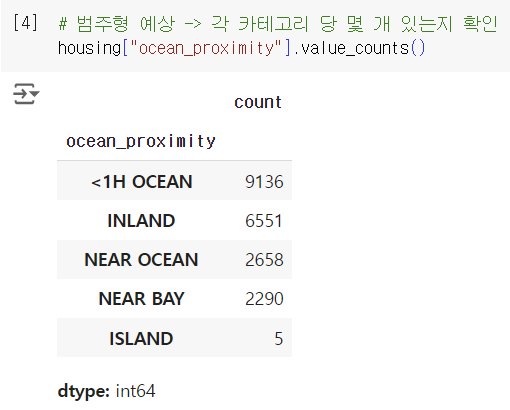
-> 데이터셋이 불균형한 경우 샘플링 편향으로 예측이 잘못될 수 있음. 그래서 여기서는 stratified sampling(계층적 샘플링) 방식을 택함
-> stratified sampling 예) 미국 인구의 51.1%가 여성이고, 48.9%가 남성이라면, 잘 구성된 설문 조사는 sample에서도 이 비율을 유지해야 한다. sample로 총 1000명을 선택한다면, 여성이 511명, 남성이 489명이어야 한다. -> 전체 인구는 strata(계층)이라는 동질의 그룹으로 나뉘고, sample이 모집단을 대표하도록 각 strata에서 올바른 수의 샘플을 추출해야 함
*의문점: upsampling이나 downsampling 말고 여기서 stratified sampling을 사용하는 이유가 뭘까? 그리고 이들의 차이는 뭘까?
-> 책에서 "전문가가 중간 소득이 중간 주택 가격을 예측하는 데 매우 중요하다고 이야기해주었다고" 가정하자고 했기 때문. 중간 소득의 1.5~6 사이에 대부분의 데이터가 있기도 하고 각 strata가 충분한 데이터를 가지고 있어야 해서 소득 카테고리 특성의 카테고리는 5개로 만듦. 그리고 sample이 모집단을 대표하도록 stratified sampling을 하여 샘플링 편향이 발생하지 않고, 중간 소득의 특성을 가격 예측에 효과적으로 이용할 수 있도록 함
-> stratified sampling이 이용된 이유를 알았으니, upsampling과 downsampling이 뭐하는 애들인지만 알고 넘어가자. upsampling은 minority class의 데이터 수를 증가시키는 것, downsampling은 majority class의 데이터 수를 감소시켜 모델이 데이터를 제대로 학습하고 예측할 수 있도록 하는 것.
-> (잡담?) 올해 LG Aimers에서 타깃이 Normal인 데이터와 Abnormal인 데이터의 수가 너무 크게 차이나서 베이스 코드에서부터 업샘플링 코드를 줬음. 업샘플링 코드 괜히 어려워보여서 처음에 이거 안하고 모델 만들었을 때 성능이 0.11인가 나왔던 것 같은데 업샘플링하고 똑같이 전처리+모델링했더니 0.142였나 나왔던 것 같음ㅋㅋ
-> 결론은 데이터 비율 최악이면 일반적으로 하는 random sampling 말고, 다른 sampling 방식 이용해보자
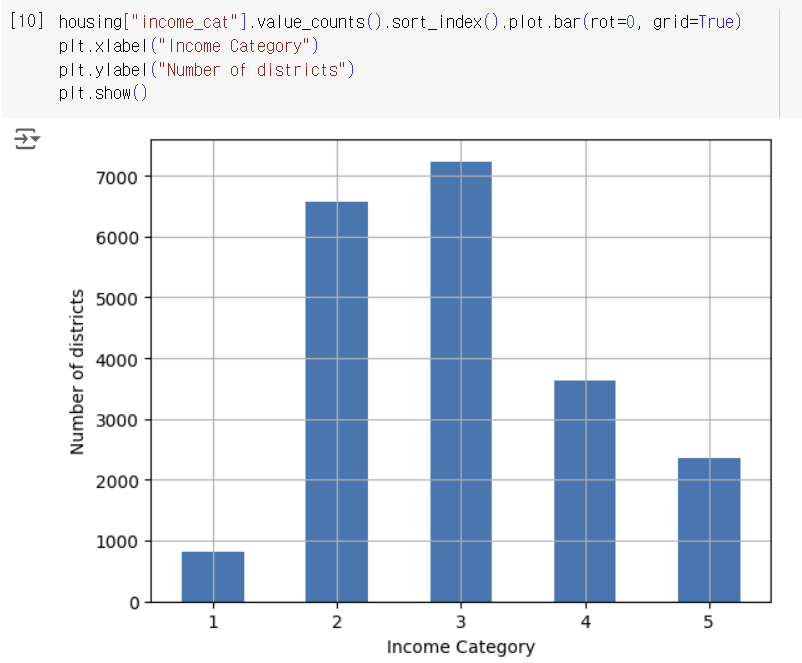
-> 소득 카테고리 특성에서 strat 비율


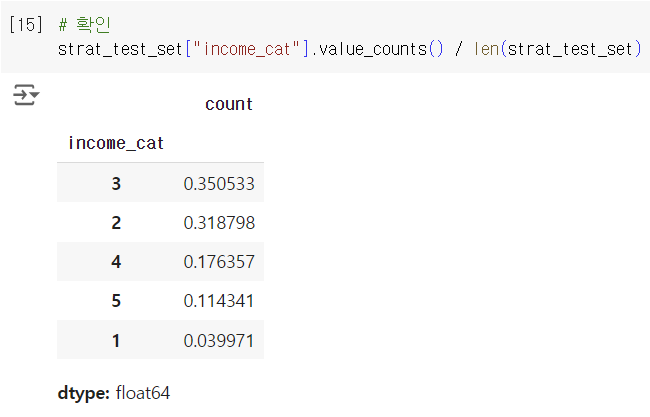
| 소득 카테고리 | 전체 % | 계층 샘플링 % | 랜덤 샘플링 % | 계층 샘플링 오차 % | 랜덤 샘플링 오차 % |
|---|---|---|---|---|---|
| 1 | 3.98 | 4.00 | 4.24 | 0.36 | 6.45 |
| 2 | 31.88 | 31.88 | 30.74 | -0.02 | -3.59 |
| 3 | 35.06 | 35.05 | 34.52 | -0.01 | -1.53 |
| 4 | 17.63 | 17.64 | 18.41 | 0.03 | 4.42 |
| 5 | 11.44 | 11.43 | 12.09 | -0.08 | 5.63 |
-> stratified sampling 오차가 작은 거 확인하면 됨

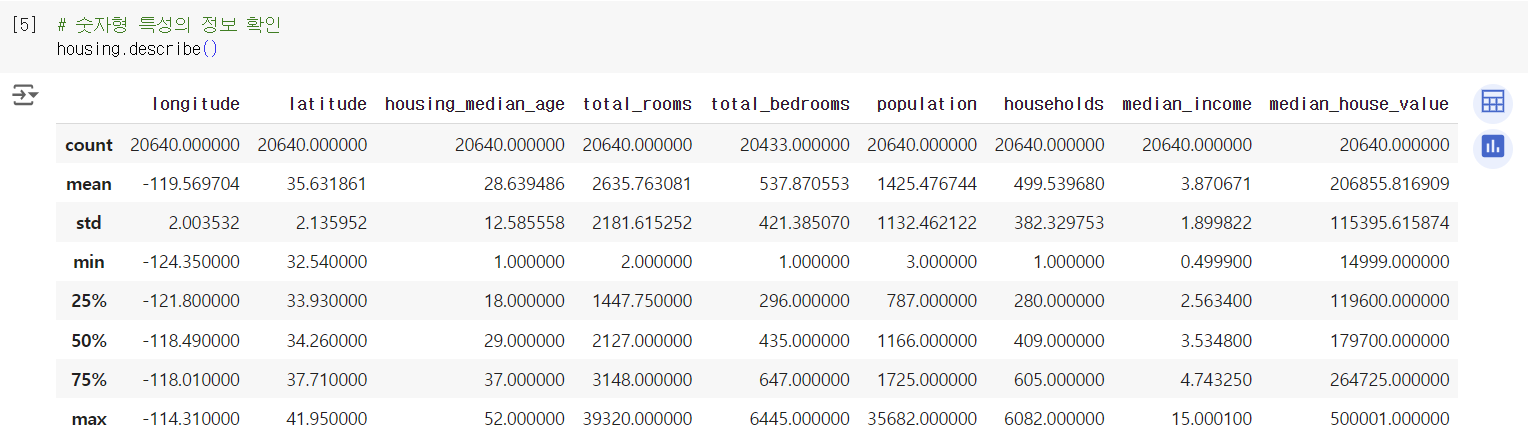
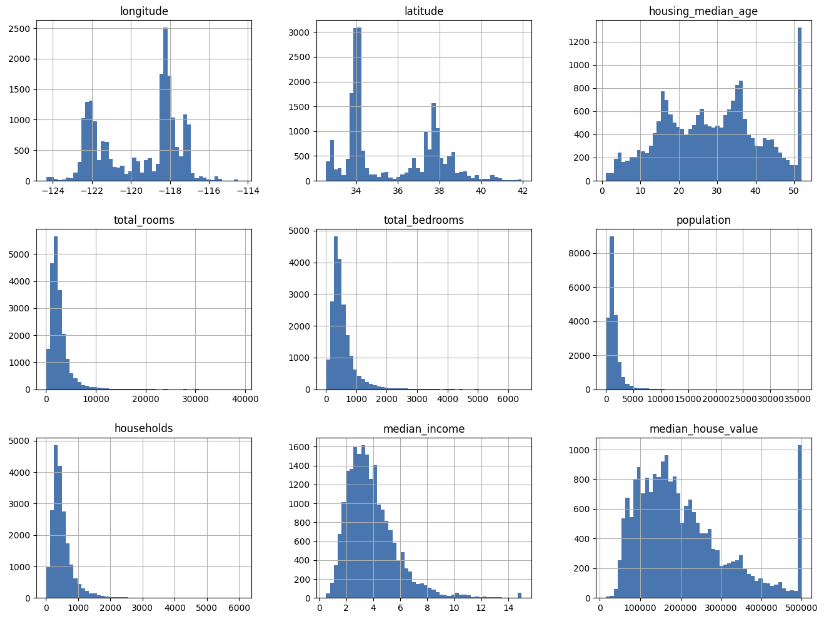
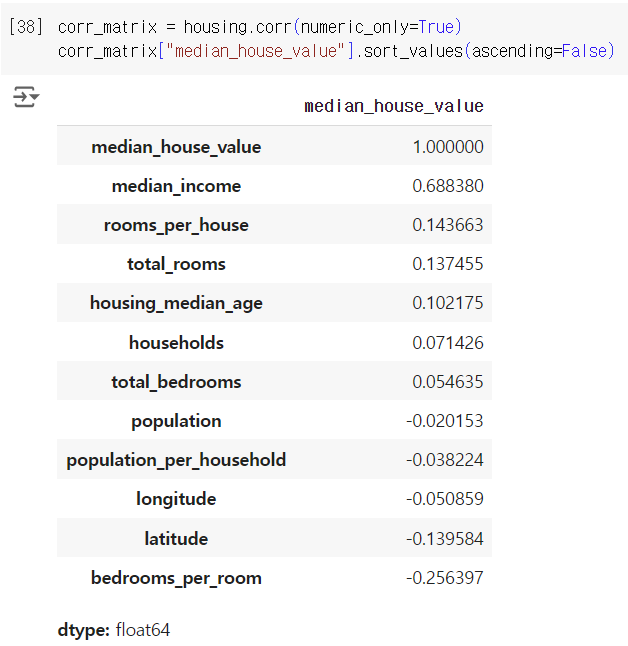
3) 데이터를 탐색하고 시각화하자
-> 데이터에 이것저것 할 거라서 복사본 이용
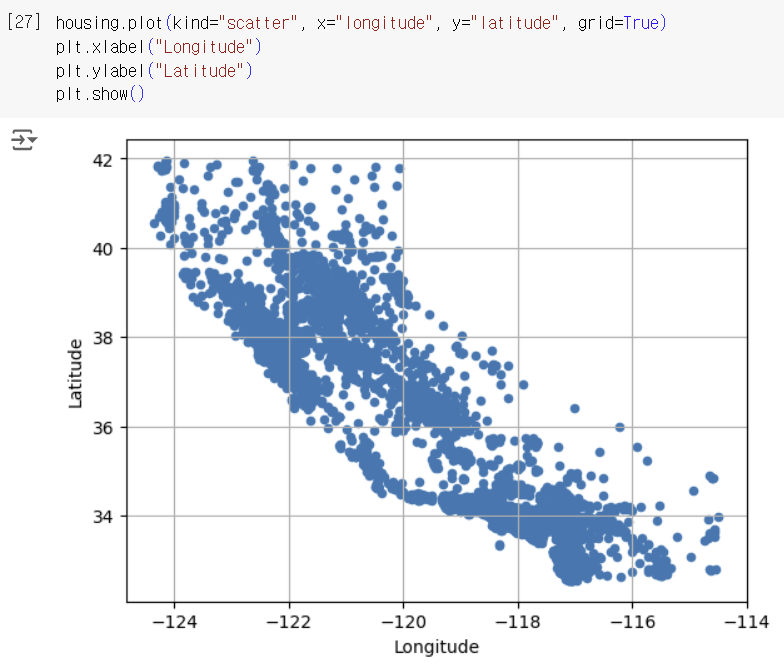
3-1) 지리적 데이터 시각화하기
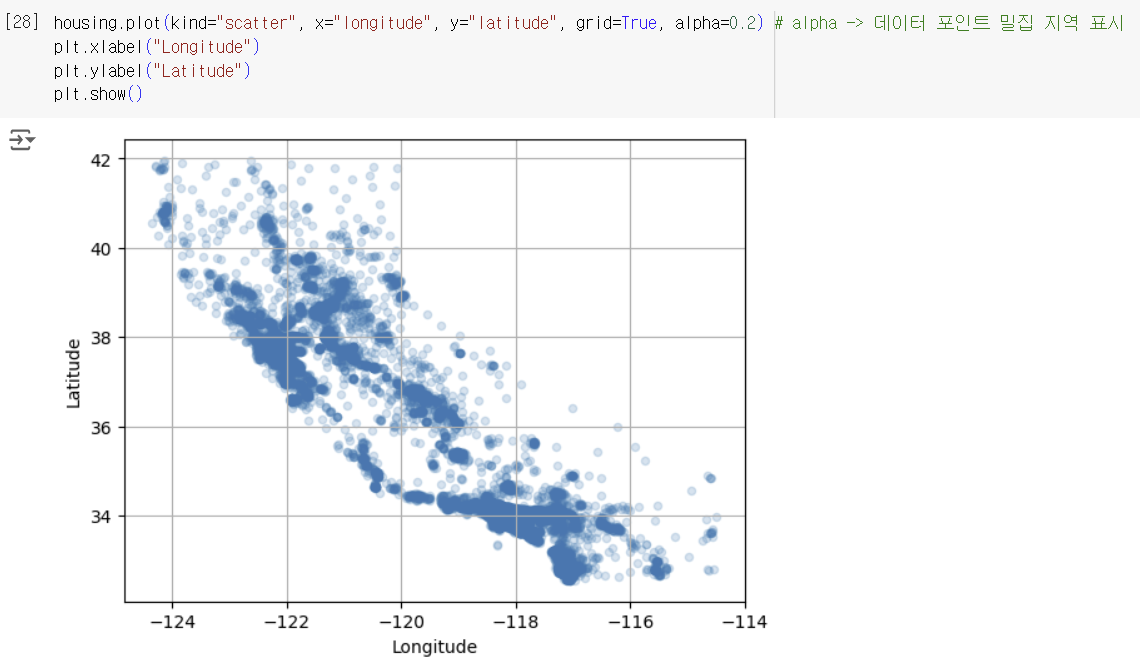

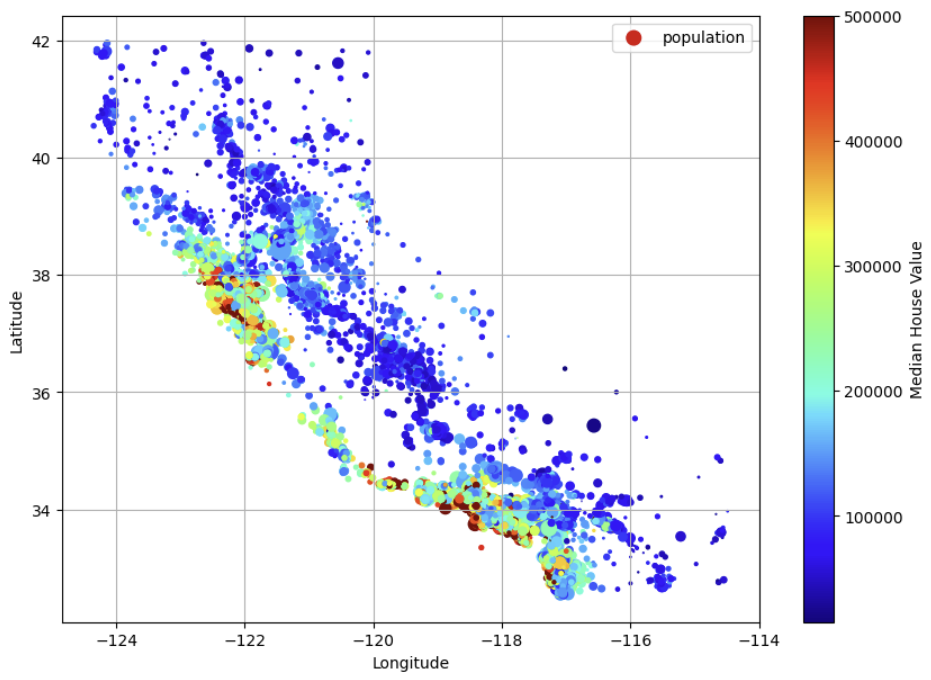
3-2) correlation 조사하기
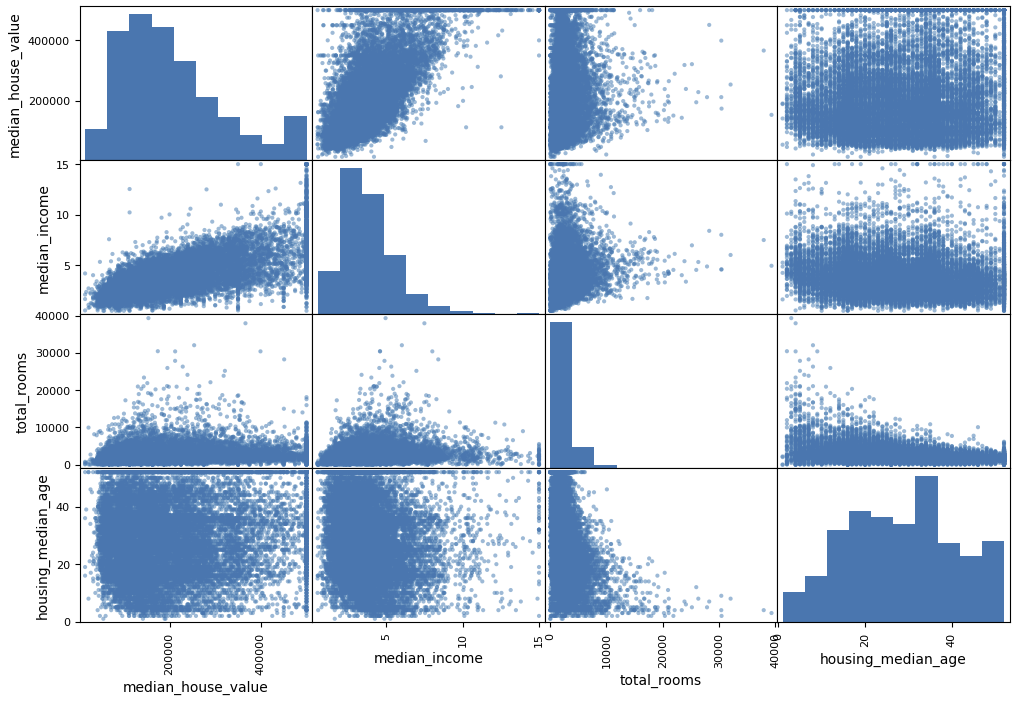
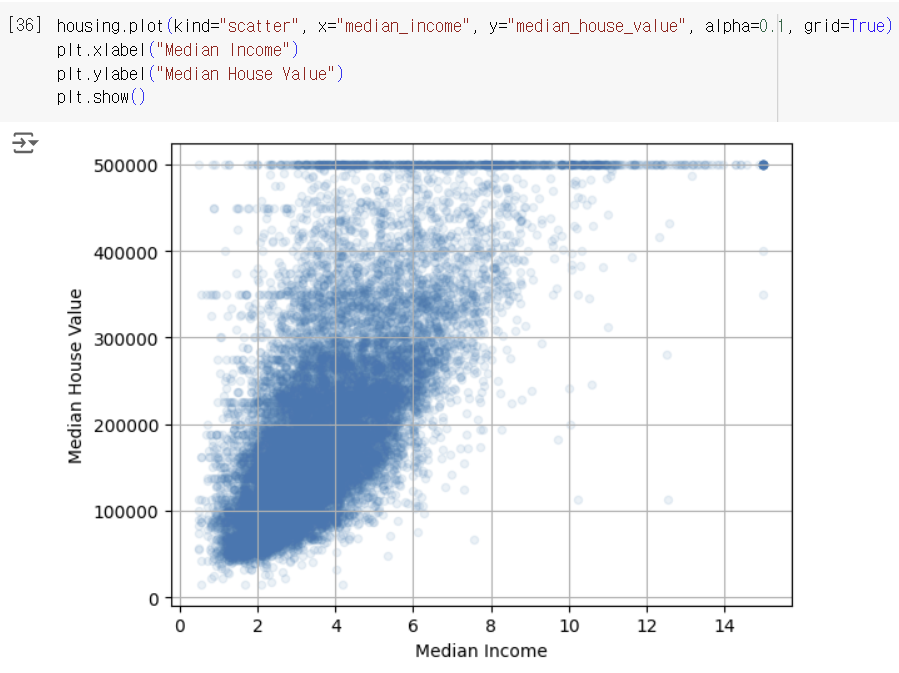
*standard correlation coefficient(표준 상관계수) or Pearson Correlation Coefficient(피어슨 상관계수)
-> 두 변수 x와 y 간의 선형 상관관계를 계량회한 수치. +1과 -1 사이의 값을 가지며, +1은 완벽한 양의 선형 상관관계, 0은 선형 상관관계 없음, -1은 완벽한 음의 선형 상관관계를 의미. 일반적으로 상관관계는 피어슨 상관관계를 의미하는 상관계수임
-> PCC를 시각화한 것. 두 번째 줄에서 볼 수 있듯 상관계수는 기울기와 상관이 없고, 마지막 줄에서 볼 수 있듯 그래프의 두 축이 완전히 독립적이지 않음에도 0이 나오는 이유는 두 변수 간에 비선형적인 관계를 갖고 있기 때문
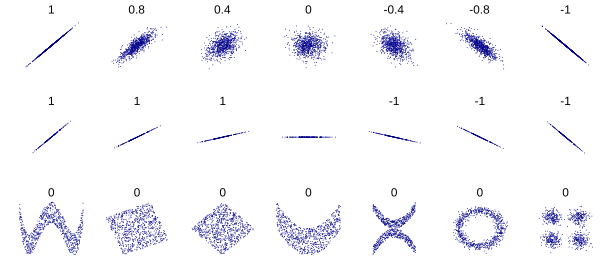
출처: https://ko.wikipedia.org/wiki/%ED%94%BC%EC%96%B4%EC%8A%A8_%EC%83%81%EA%B4%80_%EA%B3%84%EC%88%98
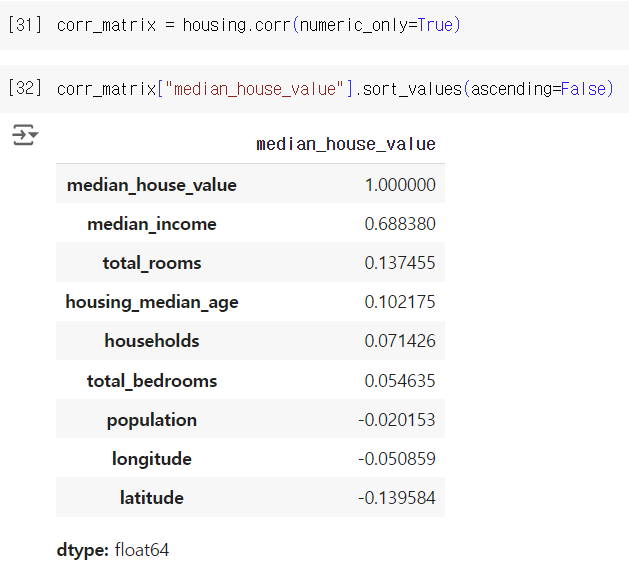

3-3) 특성 조합으로 실험하기

4) 머신러닝 알고리즘을 위한 데이터를 준비하자

4-1) Data Cleaning
결측치를 다루는 방법으로는 3가지가 있다.
- total_bedrooms 열에 결측치가 있는 행만 제거
- total_bedrooms 열 전체 제거
- 누락된 값을 다른 값으로 채움(0, 평균, 중간값 등) => Imputation(대체)
이 데이터셋에서는 total_bedrooms에만 결측치가 있으므로 코드는 아래와 같이 각각 작성할 수 있다.
housing.dropna(subset=["total_bedrooms"], inplace=True) # 1)
housing.drop("total_bedrooms", axis=1, inplace=True) # 2)
median = housing["total_bedrooms"].median() # 3)
housing["total_bedrooms"].fillna(median, inplace=True)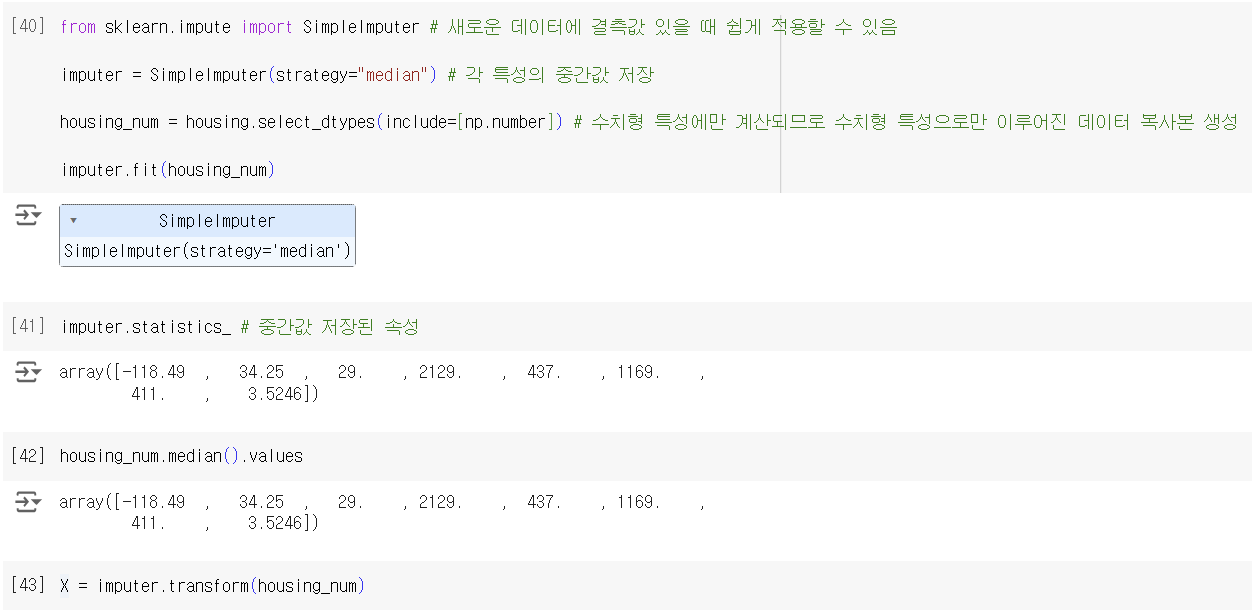
-> 새로운 데이터에 결측값 있는 경우 더 쉽게 해결할 수 있어서 SimpleImputer를 이용함. 누락된 값을 다른 값으로 채우는 위의 코드와 비슷하지만 얘는 다른 값들을 모든 특성에 대해 구해서 SimpleImputer 객체에 저장해 둔다는 점에서 차이가 있음
*의문점: imputer.fit(housing_num)과 imputer.transform(housing_num)의 차이가 뭘까
-> fit(): (규칙을)학습하는 단계. 계산해두고 기억해두지만 데이터를 실제로 변환하거나 대체하지는 않음
-> transform(): 변환 단계, 실제로 값을 대체함
estimator(추정기): 데이터셋을 기반으로 일련의 모델 파라미터들을 추정하는 객체. 추정 자체는 fit()에 의해 수행되고, 하나의 매개변수로 하나의 데이터셋만 전달함.(지도 학습에서만 매개변수로 레이블도 담기에 두개임)
transformer(변환기): 데이터셋을 변환하는 추정기. 변환은 학습된 모델 파라미터에 의해 결정되며 모든 변환기는 fit()과 transform()을 연달아 호출하는 것과 동일한 fit_transform() 메서드도 가지고 있음
predictor(예측기): 일부 추정기는 주어진 데이터셋에 대해 예측을 만들 수 있음. 새로운 데이터셋을 받아 이에 상응하는 예측값을 반환. 또한 test set을 사용해 예측의 품질을 측정하는 score() 메서드를 가짐*strategy를 "mean", "most_frequent", "constant" 등으로 바꿀 수 있음
*sklearn.impute 패키지에 KNNImputer(누락된 값을 이 특성에 대한 k-최근접 이웃의 평균으로 대체. 거리는 모든 특성을 바탕으로 계산됨)와 IterativeImputer(특성마다 회귀 모델을 훈련하여 다른 모든 특성을 기반으로 누락된 값을 예측함. 그다음 업데이트된 데이터로 모델을 다시 훈련하고 이 과정을 반복하여 모델과 대체 값을 향상시킴) 있음

4-2) 텍스트와 범주형 특성 다루기

*의문점: OrdinalEncoder와 LabelEncoder 모두 카테고리를 숫자로 바꾸는 거면, 둘의 차이는 뭐지?
-> OrdinalEncoder는 input data X에서, LabelEncoder는 target data y에서 카테고리를 숫자로 바꾼다는 점에서 차이가 있다!
참고: https://www.kaggle.com/discussions/questions-and-answers/170936
카테고리를 숫자로 변환하는 것의 문제는 가까이 있는 두 값을 떨어져 있는 두 값보다 더 비슷하다고 생각한다는 점이다. 정도를 나타내는 표현을 인코딩한 경우에는 괜찮지만, 현재 보고 있는 데이터셋과 같은 경우에는 알고리즘이 이상하게 학습될 수도 있다.
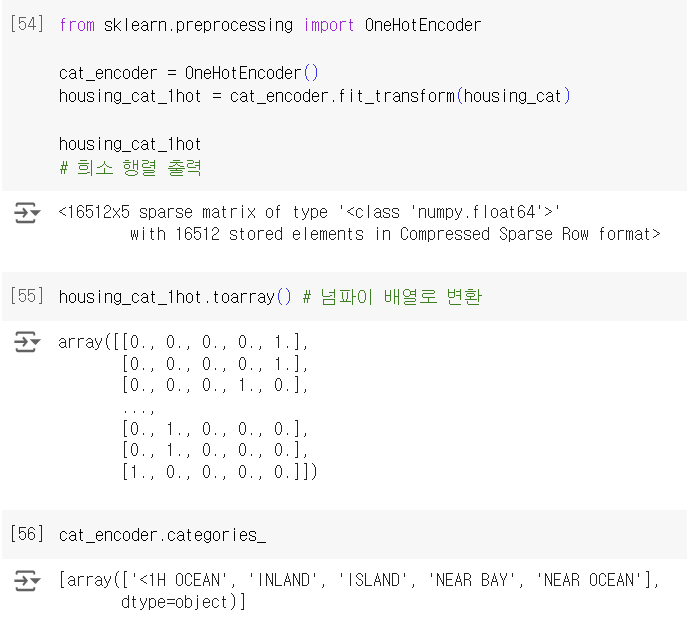
OneHotEncoding은 카테고리별 이진 특성을 만들어 이 문제를 해결한다. 예를 들어 카테고리가 1H OCEAN일 때 한 특성이 1이고 그 외의 특성은 0이고, 카테고리가 INLAND일 때 다른 한 특성이 1이고 그 외에는 0이 되는 식이다. 한 특성만 1(hot)이고 나머지는 0이므로 one-hot encoding이라고 한다.
출력 결과는 scipy의 희소 행렬로, 내부적으로 0이 아닌 값과 그 위치만 저장하기 때문에 0이 대부분인 행렬을 효율적으로 처리한다. 희소 행렬은 그대로 사용할 수도 있지만, toarray()나 OneHotEncoder의 매개변수 sparse=False(또는 sparse_output=False)로 설정, transform()으로 넘파이 배열로 만들어 반환할 수도 있다.
4-3) Feature Scaling
Standardization과 Min-Max Scaling 관련된 내용은 이 블로그에 ➡️Feature Scaling
(이 두 가지 방법 말고 다른 scaling 방법들이 있다는 건 처음 알았다..ㅎ)
power law distribution(멱법칙 분포)
: 한 수가 다른 수의 거듭제곱으로 표현되는 두 수의 함수적 관계. long tail의 형태를 가짐
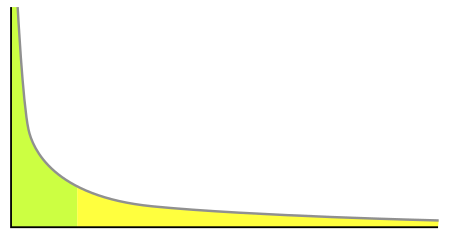
출처: https://ko.wikipedia.org/wiki/%EB%A9%B1%EB%B2%95%EC%B9%99
- 특성을 제곱근으로 바꾼다.
- 0~1 사이에서 특성을 제곱한다.
- 특성을 로그값으로 바꾼다. (가우스 분포에 가까운 형태를 가짐)
- bucketizing(구간화)
: 분포를 거의 동일한 크기의 bucket으로 자르고 특성값을 해당하는 bucket의 인덱스로 바꾸면 됨. 백분위수로 바꿀 수도 있음. 거의 동일한 크기의 bucket을 만든 경우 거의 균등 분포를 띄기 때문에 스케일링을 할 필요가 없음. bucket 수로 나누면 0~1 사이 범위로 만들 수도 있음
multimodal distribution
: 2개 이상의 최빈값(=mode, 정점)을 갖는 확률분포
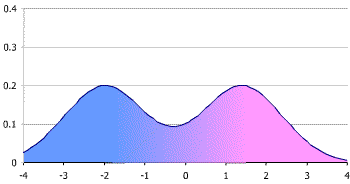
출처: https://ko.wikipedia.org/wiki/%EB%8B%A4%EB%B4%89%EB%B6%84%ED%8F%AC
- bucketizing에서 bucket의 인덱스를 수치가 아닌 카테고리로 다룸. bucket 인덱스를 인코딩 해야 한다는 의미. 회귀 모델이 특성값의 여러 범주에 대해 다양한 규칙을 학습할 수 있게 됨
- Radial Basis Function(RBF, 방사 기저 함수)
: real-valued function으로 input과 어떤 고정된 포인트 사이의 거리에 의존하는 값임. 고정된 포인트는 origin이나 center가 될 수 있음. 이런 조건을 만족하는 게 radial function이며 거리 측정에는 주로 Euclidean distance가 사용됨
출처: https://en.wikipedia.org/wiki/Radial_basis_function- Gaussian
- c: 고정된 포인트
- : x가 c에서 멀어짐에 따라 얼마나 빠르게 감소할지 결정
rbf_kernel()로 x와 c 사이의 유사도를 재는 새로운 Gaussian RBF 특성을 만들 수 있음from sklearn.metrics.pairwise import rbf_kernel age_simil_35 = rbf_kernel(housing[["housing_median_age"]], [[35]], gamma=0.1)
- Gaussian
역변환 수행
: 예를 들어, 타깃의 tail이 길고 두꺼워서 로그 변환을 했다면, 주택 가격의 로그 값을 예측하게 되므로 주택 가격을 얻기 위해서는 지수 함수를 적용해야 한다. 이걸 수동적으로 하는 게 아니라 함수로 처리할 수 있는 방법이 있음
-
inverse_transform()from sklearn.linear_model import LinearRegression target_scaler = StandardScaler() scaled_labels = target_scaler.fit_transform(housing_labels.to_frame()) # StandardScaler는 2D 입력을 기대하므로 레이블을 판다스 시리즈에서 데이터프레임으로 변환 model = LinearRegression() model.fit(housing[["median_income"]], scaled_labels) some_new_data = housing[["median_income"]].iloc[:5] scaled_predictions = model.predict(some_new_data) # 역변환 수행 predictions = target_scaler.inverse_transform(scaled_predictions) -
TransformedTargetRegressorfrom sklearn.compose import TransformedTargetRegressor model = TransformedTargetRegressor(LinearRegression(), transformer=StandardScaler()) model.fit(housing[["median_income"]], housing_labels) # 역변환 수행 -> transformer의 inverse_transform() 메서드를 이용하여 예측을 생성함 predictions = model.predict(some_new_data)
이미 있는 transformer 외에도 사용자가 직접 변환기를 작성하는 방법도 있다. ➡️"핸즈온 머신러닝 2.5.4 사용자 정의 변환기"
4-4) Transformation Pipelines
아.. 파이프라인 함수가 이렇게 사용되는 거였구나.. 매번 지피티가 파이프라인으로 변환기들 묶었을 때 그냥 커널에 각각 쓰지 뭘 또 이렇게 어렵게 묶어놔.. 라고 생각했는데.. 이때 어렵다고 느꼈던 이유는 단순히 익숙하지 않아서.. 속으로는 간단해보이기는 하네 라고 생각했지만.. 이제서야 그동안의 의문이 풀리는 개운한 기분..
Pipeline
- 연속적인 단계를 정의하는 이름과 추정기로 이루어진 튜플의 리스트를 받음
- 이름에는 이중 밑줄 문자(__) 포함X
- 추정기는 마지막을 제외하고는 모두 변환기여야 함 -> fit_transform() 메서드를 가져야 함
- 마지막 추정기는 변환기, 예측기 등 다양하게 ㄱㄴ
from sklearn.pipeline import Pipeline
num_pipeline = Pipeline([ # 수치형에 사용할 것
("impute", SimpleImputer(strategy="median")),
("standardize", StandardScaler()),
])make_pipeline()
- 위치 매개변수로 변환기를 받음
- 이름은 따로 쓰지 않아도 됨. 클래스 이름을 소문자로 바꿔서 알아서 이름 만듦. 동일한 변환기의 경우 숫자를 붙임
from sklearn.pipeline import make_pipeline
num_pipeline = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())"pipeline은 기본적으로 마지막 추정기와 동일한 메서드를 제공한다."
pipeline에 fit() 호출하기
- pipeline에 속한 모든 변환기의 fit_transform()을 순서대로 호출하며 한 단계의 출력을 다음 단계의 입력으로 넘김
- 마지막 변환기에서는 fit() 메서드만 호출
pipeline에 transform() 호출하기
- 데이터의 모든 변환을 순서대로 적용함
- 마지막 추정기가 변환기가 아니라 예측기라면 transform() 대신 predictor() 메서드를 수행
pipeline 추정기 접근하기
- 인덱싱 -> pipeline[1]은 pipeline의 두 번째 추정기 반환
- 슬라이싱 -> pipeline[:-1]은 마지막 추정기를 제외한 모든 추정기를 담은 pipeline 객체 반환
- 이름/추정기 쌍의 리스트인 steps 속성으로 참조
- 이름과 추정기를 매핑한 딕셔너리인 named_steps 속성으로 참조
아래 파트에서 또 아.. 싶었음.. 올해 LG Aimers 데이터에서 수치형이랑 범주형/텍스트형에 다른 변환기 적용하려고 했더니 지피티가 딱 이런 코드 알려줬음.. 근데 기억상으로는 수치형 컬럼은 따로 안 묶고 카테고리형만 묶어서 변수 만들었던 것 같기도..? 어쨌든 그런 코드를 쓰긴 했으나 결국 안 쓰긴 함^-^
ColumnTransformer
- 클래스 생성자는 세 개의 원소를 가진 튜플의 리스트를 받음
- 각 튜플은 이름(밑줄 문자X, 고유), 변환기, 변환기가 적용될 열 이름 리스트로 구성됨
remainder파라미터는 기본적으로 drop으로 설정되어 있기 때문에 컬럼명이 명시되어 있지 않으면 삭제됨. passthrough라고 지정을 하면 명시된 컬럼명을 제외한 컬럼의 경우는 아무런 변환 없이 pass through하게 됨
참고: https://scikit-learn.org/stable/modules/generated/sklearn.compose.ColumnTransformer.html
from sklearn.compose import ColumnTransformer
num_attribs = ["longitude", "latitude", "housing_median_age", "total_rooms", "total_bedrooms", "population", "households", "median_income"] # 수치형 특성
cat_attribs = ["ocean_proximity"] # 범주형 특성
cat_pipeline = make_pipeline( # 범주형에 사용할 것
SimpleImputer(strategy="most_frequent"),
OneHotEncoder(handle_unknown="ignore"))
preprocessing = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", cat_pipeline, cat_attribs),
])make_column_selector()
- 수치형이나 범주형처럼 주어진 타입의 모든 특성을 자동으로 선택해줌
make_column_transformer()
- ColumnTransformer + make_pipeline() 느낌. 이름 자동으로 지정
from sklearn.compose import make_column_selector, make_column_transformer
preprocessing = make_column_transformer(
(num_pipeline, make_column_selector(dtype_include=np.number)),
(cat_pipeline, make_column_selector(dtype_include=object)),
)주택 가격 데이터셋에 모든 작업을 수행하는 파이프라인을 만드는 코드는 책의 p.124를 참고하자
출처: 핸즈온 머신러닝 3판
