SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
KeyPoints:
- Positional encodeing free hierarchically structured Transformer encoder
(resolution independent test/training performance, multiscale features)
- Simple structured MLP decoder
Backgrounds
- Former works are concentrated on encoders only (PVT, Swin Transformers, etc).
- Still requires high computation on decoders.
Overal Method
- Input image(H×W×3) is divided in to patches of size 4×4.
- By hierarchicl Transformer encoder, mulit-level features sized {1/4,1/8,1/16,1/32} of the original image, are obtained from the patches.
- Pass the features to ALL-MLP decoder and get resolution segmentation mask prediction. ( : num of categories)
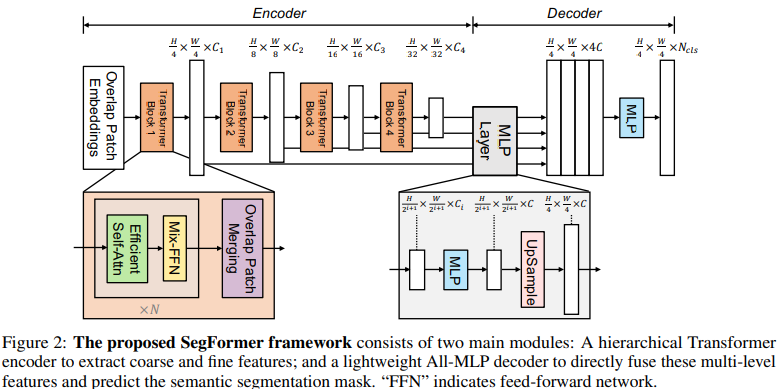
Overlapped patch merging.
- Like ViT unified N×N×3 patches to 1×1×C vectors, heirarchical features from are shrinked into . And method iterates for other heirarchy.
(Note. What ViT paper actually did was flattening patches into vectors.
Dividing H×W×3 images into N patches size and flatten those patches into .) - To preserve local continuity among the patches, K = 7, S = 4, P = 3 (and K = 3, S = 2, P = 1) is set, where K is the patch size, S is the stride, P is the padding size.
Efficient Self-Attention.
By reducing lenth of sequence (size NC) from N to with
= Reshape( , C · R)() [reshape NC to (C · R)]
= Linear(C · R , C)( ) [linear transpose (C · R) to C]
the self-attension mechanism complexity decreased from to
Mix-FFN.

HAPPY the cat