[REVIEW] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
1. Introduction
Proposing general and model-agnostic meta-learning algorithm.
2. Model-Agnostic Meta-Learning(MAML)
2.1. Meta learning scenario
Meta-training part
- A task is drawn from task distribution .
- With , the model is trained with only samples and feedback from .
- Tested on new samples from , this test error is considered when imporving model f(generaly expressed as 'model f' since meta-learnable object is differ from algorithms to parameters) with respect to the parameters.(Thus this test error serves as training error.)
Meta-testing part
- New tasks are sampled from , and meta-performance is measured after learning from K samples.(Tasks used for meta-testing are out held out during meta-training)
2.2. A Model-Agnostic Meta-Learning Algorithm
Intuition
- Some representations are more transferable.
-> Let Neural networks learn features from such representations, thus broadly applicable to all tasks.
Problems
- Existence of such representations.(Personal question)
- How can we tell which one is the one.
Approach
- It is a relative matter. Not looking for an absolute transferable, but relatively more transferable representation.
- By finding the model that makes most rapid adjustment on new tasks from . Thus able to evoke a large improvement from a small change. More transferable.
Setup
- : distribution of tasks
- : batch of tasks,
- : single task,
Algorithm

Inner loop
- For all , sample K data points each and compute gradient descent.
- Get number of inner loop parameters
- Sample for meta update (outer loop)
- For each task , we have where
Outer loop
- For each tasks , compute
- Compute gradient descent with sum of all losses.
- Note that, since , is driven with 2nd order differentiation.
Concequently, the meta-object is as follows:
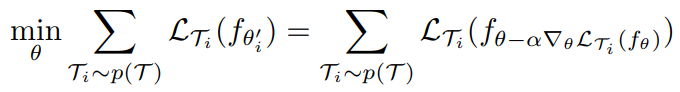
Meta test step (Meta performance test)
- Sample batch of task
- Test it on full algorithm
- Purpose of the model includes training.
3. Species of MAML
3-1. Supervised Regression and Classification
MSE for regression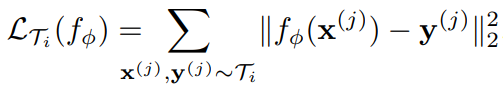
CE-loss for classification 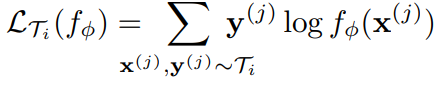
MAML for Few-Shot Supervised Learning
- Note that, K-shot classification tasks use K input/output pairs from each class, thus NK data points for N-way classification.
3.2.Reinforcement Learning
Definitions
- = { }
: Task (Each learning problems) - : Loss function with observation , output
- : A distribution of initial observations
- : A transition distribution
- : An episode length. A cycle length of generating an output of a query set. (Each time , model generates samples of length H by chooosing an output )
Algorithm

Terminology
- task : (Classification for example) Each work given specific classes to perform classification, where this specific classes may not include whole class range. Thus, there might be more than one tasks under one dataset.

HAPPY the cat