Paper : Attention Is All You Need (A Vaswani, N Shazeer, N Parmar, J Uszkoreit, L Jones, N. Gomez, L Kaiser, I Polosukhin / NIPS 2017)
- Motivation : 자연어 처리 인공지능이 매우 각광을 받고 있다. 특히 그 선두주자를 달리고 있는 Chat GPT는 Transformer architecture를 기반으로 하는 language generative model이다. Transformer 논문은 인용수가 무려 65,000회가 넘는 작품이다. 사실 자연어 처리는 그렇게 관심이 많지는 않지만 컴퓨터 비전 분야에서도 transformer architecture는 Imagenet SOTA만 봐도 그 대단함을 알 수 있다. 원래는 Vision Transformer부터 리뷰하려고 했는데, 어차피 똑같은 개념을 가져다가 쓴 것이라 생각해서 이 논문부터 정리하고 attention의 개념을 상기해보려 한다.
Short Summary
-
RNN이나 CNN 구조를 벗어나 오직 Attention Mechanism만을 사용하는 새로운 아키택처인 Transformer를 제안
-
Translation task에서 효율적인 학습을 할 수 있었고, SOTA를 달성
-
다른 modality로도 확장가능한 포괄적인 개념을 제시
Introduction
Language modeling이나 machine translation과 같은 transduction problem는 그동안 encoder, decoder를 포함하는 복잡한 recurrent나 convolutional neural network를 기초하고 있었다.
- Transductive Model
Transductive model은 우리가 보통 supervised learning으로 사용하는 inductive model과 상반된 추론 방법을 가진 모델을 의미한다. Inductive model에서는 training data를 이용해 일반적인 패턴을 학습해 predictive model을 만들고, 이를 한번도 보지 못한 test data에 적용하여 좋은 성능을 내기를 기대하는 반면, transductive model에서는 어떤 특정한 predictive model을 만들지 않고, training/test data를 한번에 모두 관찰하여 이미 있는 데이터 베이스를 이용하여 문제를 풀고자 한다. 이러한 특징 때문에 inductive model은 새로운 data point에 대해 그냥 inference만 하면 되지만, transductive model은 완전히 다시 학습을 진행해야 한다.
하지만 Recurrent Neural Network는 필연적으로 이전 결과를 입력으로 받는 순차적인 특징 때문에 병렬 처리가 불가능하다는 제약이 있었다. 이러한 경우 sequence length가 길어지면 메모리 문제 등이 발생할 수 있다.
해당 논문에서는 이러한 recurrent 모델의 제약 사항을 피하고 입력과 출력 사이의 global dependency를 잘 끌어낼 수 있도록 오직 attention mechanism에만 의존하는 새롭고 간단한 network인 Transformer를 제안한다.
Background
먼저 transformer 이전에 sequence transductive model에 주로 사용되던 recurrent model에 대해서 간단히 알아보자.
Sequence data (예를 들어 문장)는 단어 하나하나만 알고 있다고 이해할 수 있는 것이 아니고, 전체적인 맥락을 모두 이해하야 하므로, recurrent model은 sequence에 따라 데이터를 순차적으로 입력으로 넣어 이전 결과가 다음 결과에 영향을 미칠 수 있도록 설계되어 있다.
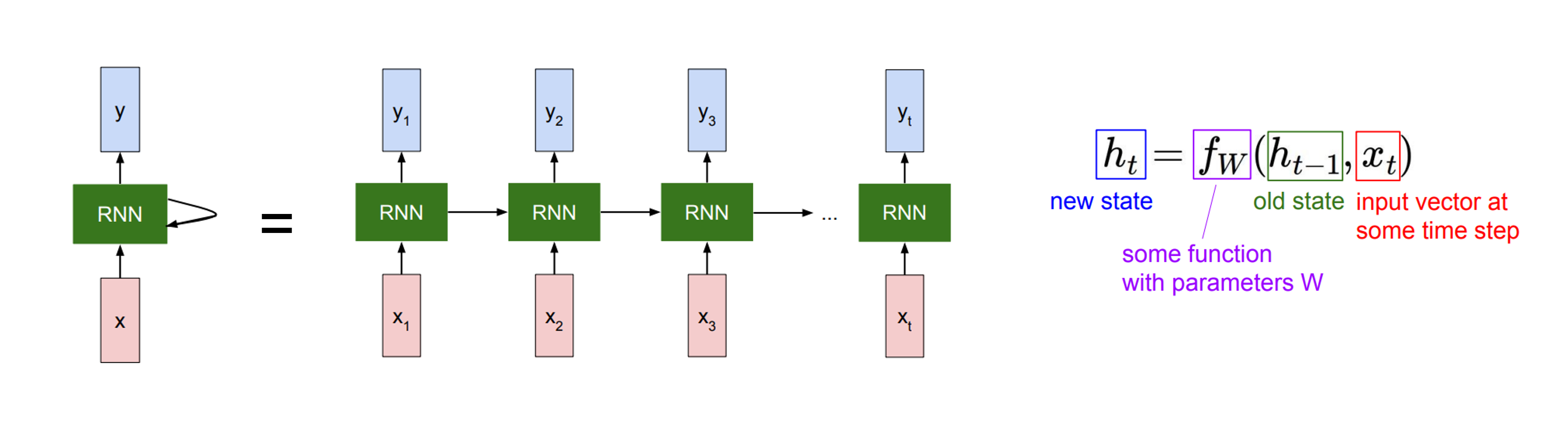
그림 출처 : http://cs231n.stanford.edu/
RNN은 어떤 sequence를 처리함에 따라 업데이트되는 어떤 internal hidden state를 갖고 있고, 특정 time의 데이터 x가 입력으로 들어갈 때는 이전의 hidden state를 입력으로 받게 된다.
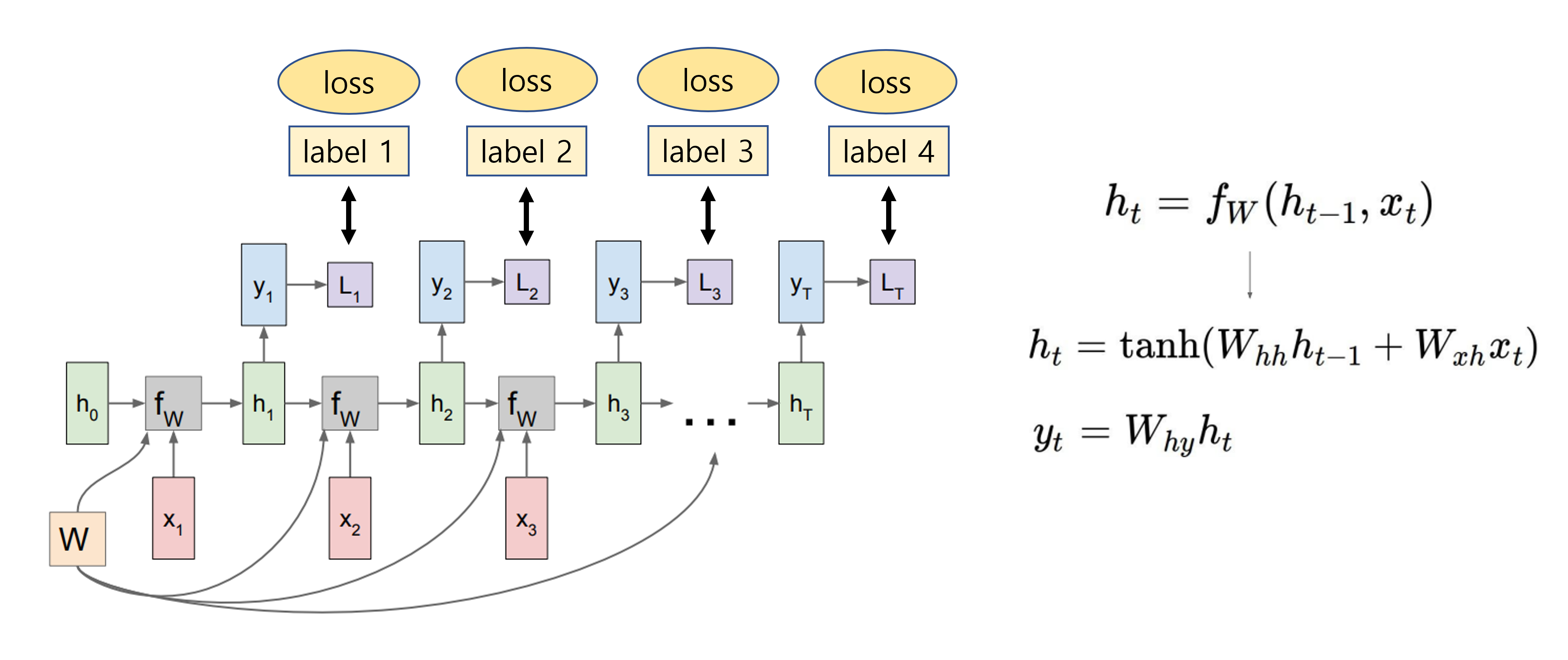
RNN에는 input x를 hidden state로 mapping하는 weight와 이전 hidden state를 받는 weight가 있어서 이를 이용해 현재 hidden state를 계산한다. 그리고 이 hidden state를 이용하여 output y를 얻을 수 있다.
여기서 RNN, 즉 는 하나의 고정된 함수이고, 모든 time step에 대해 똑같은 함수가 적용된다. 그리고 순차적으로 나와야하는 label에 대해 loss를 주어 학습할 수 있다.
Many-to-many, many-to-one, one-to-many 등 다양한 시나리오로 학습을 하는데, 나중에 궁금하면 더 자세히 공부하는 것으로 하자.
아무튼 이러한 구조는 한계가 있었고, transformer는 근본적인 문제를 해결하려 한다.
Attention mechanism은 사실 이전부터 sequence modeling이나 transductive model에 많이 사용되었다.
이는 sequence 내부 요소 사이의 거리와 상관없이 서로 간의 dependency를 모델링하는 방법으로, 특히 self-attention에서는 어떤 sequence의 representation을 계산하기 위해 single sequence 내부 서로 다른 position에 대해 (자기 자신의 위치도 포함한다.) 내적 등의 연산을 통해 상관관계를 구한다.
Transformer는 온전히 self-attention만을 사용하여 transductive model을 제안하였고, translation task에서 매우 좋은 성능을 보여주었다. 구조도 간단하다.
Architecture & Training
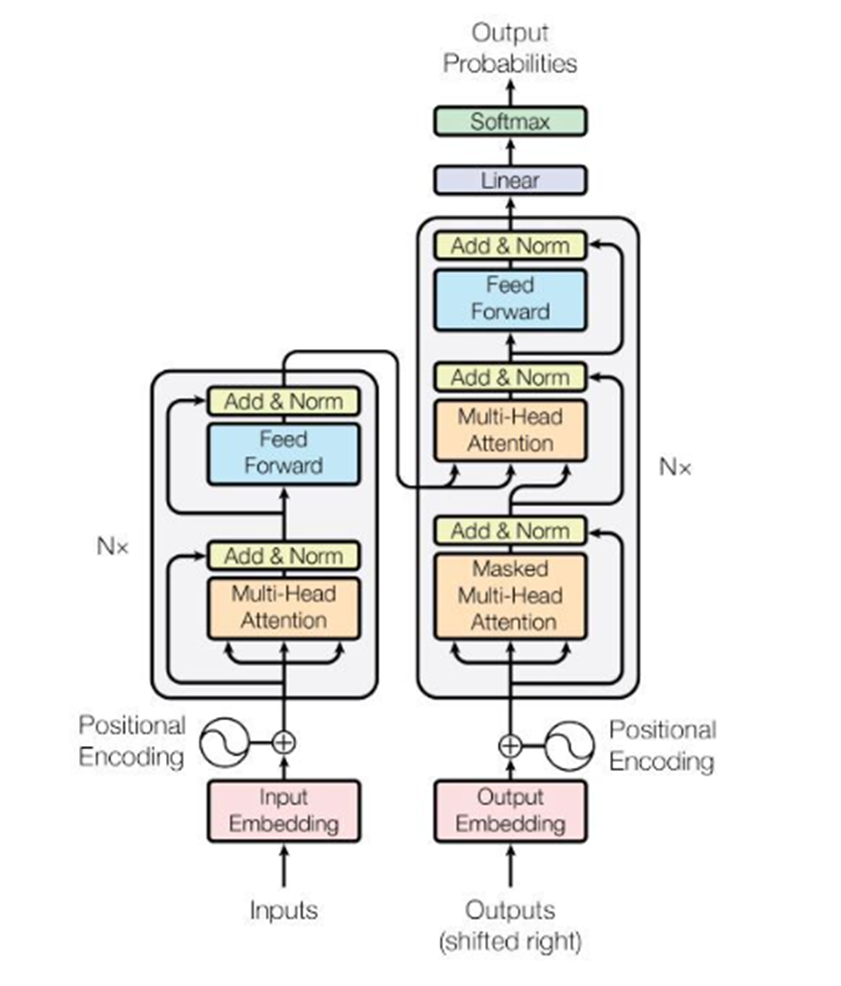
Transformer의 overall architecture는 아래의 그림과 같이 Encoder-Decoder structure로 이루어져있다. Encoder는 input sequence ()를 받아 연속적인 representation ()으로 mapping시킨다. 이후 decoder는 를 받아 output sequence ()을 출력한다. 이때, model은 output sequence를 순차적으로 만들어내서, 이전에 만들어낸 출력을 decoder의 추가적인 input으로 사용한다.
나는 처음에 이 그림만 보고 하나도 이해가 안갔는데,, 한국어를 영어로 번역한다고 해보자. 그냥 encoder의 input으로 "나는(=) 공부하는(=) 사람(=)"이 들어가면 encoder는 이 문장을 어찌저찌 이해해서 =(vector1(), vector2(), vector3())를 만들어 낸다. 그러면 decoder는 여러 step으로 나누어 output sequence를 만든다. 처음에는 start token이라는게 들어가서 이미 학습된 단어 database에서 encoding된 문장에 가장 어울리는 첫 단어를 만들어낸다 "I". 그럼 다음 step에서 decoder는 "I"와 를 가지고 다음 단어를 출력하고, 이를 계속 반복한다. "am" "studying" "person".
Architecture와 학습 방법, 구현 방법은 Vision Transformer에서 더 자세하게 알아보자...
Attention
가장 중요하고 핵심이 되는 연산인 attention에 대해서 알아보자. Attention 함수는 query와 key-value pair 집합을 어떤 output으로 mapping하는 것으로 생각할 수 있다. 이 output은 value vector의 weighted sum으로 계산되며, 이 weight는 query vector와 이에 상응하는 key vector와의 함수로 구한다.
Transformer에서 사용되는 attention은 Scaled Dot-Product Attention이고, 이를 multi-head로 나누어 계산한다. 각각 무엇인지 더 살펴보자.
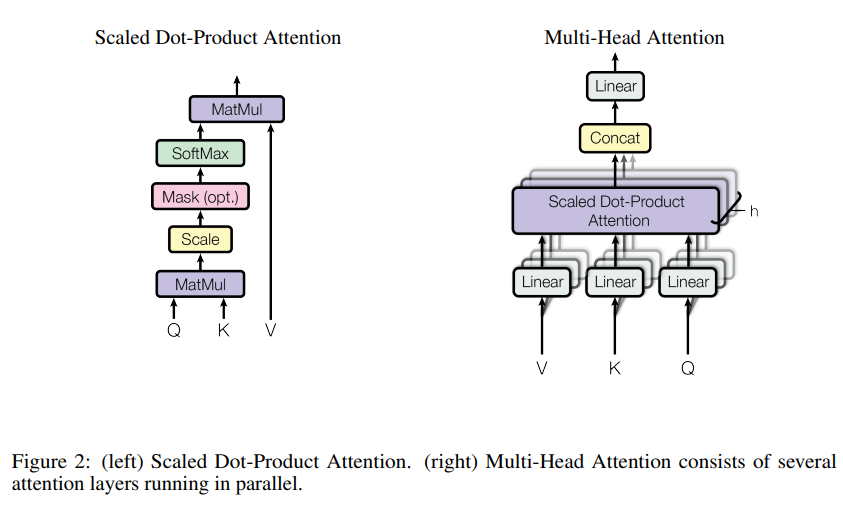
Scaled Dot-Product Attention
각 입력은 모두 각각의 query, key와 value를 가지고 있다. 하나의 query를 모든 나머지 key와 dot product한 후, query와 key의 dimension인 로 나눈 값에 softmax를 취해 해당 key의 value에 대한 weight를 얻는다.
이때 로 나누는 이유는 가 커짐에 따라 dot product magnitude가 커질 것이고, 그러면 softmax function이 매우 작은 gradient 값을 가지게 되어 학습이 잘 안되므로 scaling을 해주는 것이라고 한다.
말로는 잘 이해가 안되니까 그림으로 보자. 아래 그림은 encoder에서 입력의 흐름을 도식화한 것이다. 그리고 쉬운 이해를 위해 input은 word의 sequence인 sentence라고 하자. "I AM HEEJUN"
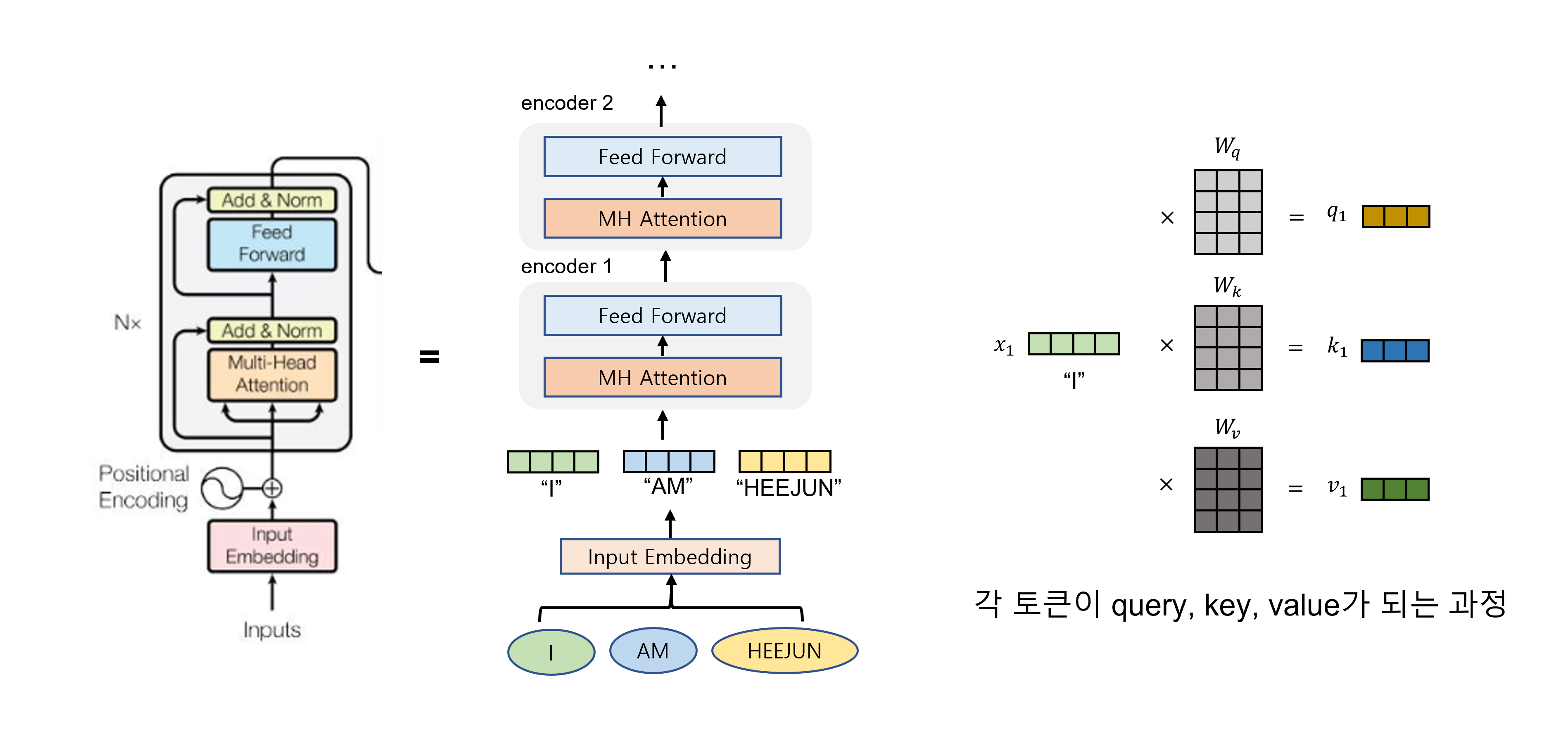
가장 먼저 각 단어들은 정해진 channel, hidden size를 가지는 벡터로 embedding된다 (그림에서 Input Embedding). Positional Embedding도 있기는 한데, 이거는 조금 있다가 다시 알아보자.
Embedding된 input sentence의 word vector ("I"), ("AM"), ("HEEJUN")은 attention layer에 들어가서 weight vector 를 만나 Query, Key, Value의 3가지 vector를 만든다. (위의 맨 오른쪽 그림) Query, Key, Value는 모든 입력 토큰이 각각 가지고 있는 어떤 hidden state의 토큰이다. 그냥 한 단어가 세 가지 이름표를 가지고 있다고 생각해도 무난할 거 같다.
Attention은 결국 서로 얼마나 영향을 주고 받는지를 구하는 것이라고 했었다. Query, Key, Value는 그 자체의 의미보다도 attention value를 구하는데 있어서 어떠한 역할을 하는지를 이해하는 것이 쉽다.
- Query는 영향을 받는 단어를 나타내는 변수
- Key는 영향을 주는 단어를 나타내는 변수
- Value는 그 영향에 대한 가중치가 곱해질 단어 자체를 나타내는 변수
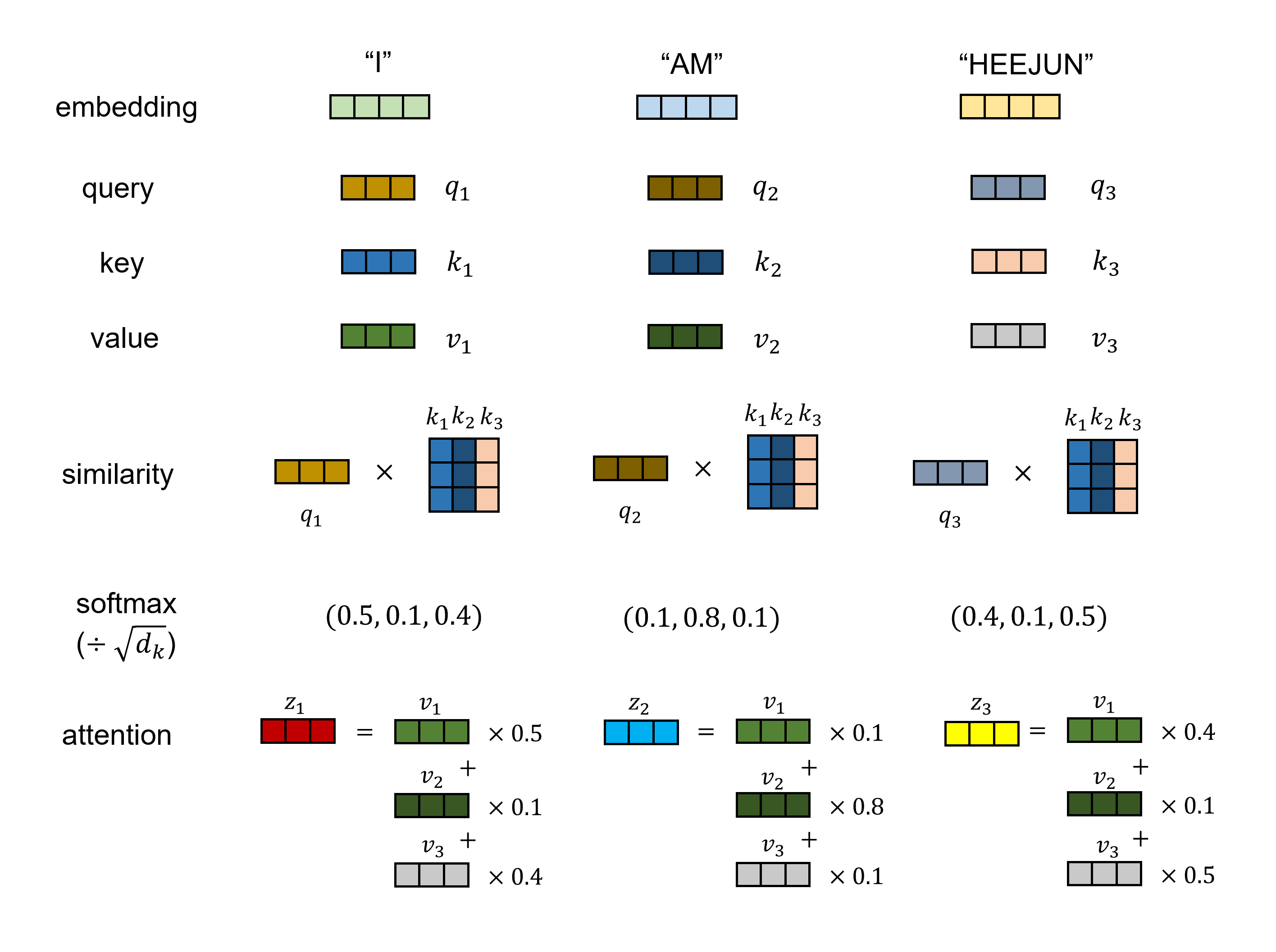
각 단어의 Query는 모든 단어의 Key에 대해 (자기 자신도 포함) dot product 연산을 통해 두 vector의 유사도를 측정하여 서로에게 얼마나 중요한지 (영향을 주는지) 파악한다. 이 유사도 값을 모든 단어에 대해 softmax 취하여 sum이 1이 되는 weight로 만들고 (를 전에 나누긴 한다), 각 단어의 value에 weighted sum하여 attention value를 구할 수 있다.
다시 설명하자면, 어떤 hidden state에서 각 token은 모두 Query, Key, Value를 가지고 있는데, 각 단어는 Query 이름표를 가지고 모든 단어의 Key 이름표와 비교해서 그 Key에 해당하는 Value를 다음 hidden state에 얼마나 받아올 것인지 정한다. 집중하고자 하는 관련이 있는 단어의 영향은 남기고 관련이 없는 단어의 영향은 지우는 작업이라고 이해할 수도 있겠다.
Self-attention layer에서 attention 연산이 이렇게 끝나면 feed-forward layer를 지나 그 다음 encoder의 self-attention layer로 들어간다.
정리하자면 Attention layer가 하는 일은 input sequence의 단어들이 서로 주고 받는 영향을 계산하고 이 정보를 vector 안으로 주입한다는 것이다. 즉 attention output은 입력 단어의 의미와 문장 내 다른 단어와의 관계에 대한 정보를 동시에 포함한다.
이게 어떤 효과를 가져오냐면 예를 들어 "The creator of Transformer is a really great person, and I have a lot of respect for him. It is designed very rationally and shows tremendous performance."라는 문장에서 "It"은 Transformer를 의미하는 것인데, 컴퓨터가 이러한 문맥을 파악하는 것은 정말 어렵다. 그런데 attention을 통해 단어 사이의 관계를 잘 계산한 Transformer는 이를 잘 해석할 수 있다.
Multi-Head Attention
Multi-Head Attention은 scaled dot product attention을 병렬 처리하기 위해 여러 개 사용한 것이다.
Query, Key, Value를 그대로 단일 attention function에 입력하는 것이 아니고, 각각 다르게 학습된 linear projection으로 project시켜 h번 병렬적으로 계산하였다. (예를 들어 512-dimension을 가지는 Query를 64-dimension으로 8번 따로 projection시키고 따로 scaled dot-product attention을 연산시킨 후 concatenate한다)
이러한 병렬 연산은 모델이 서로 다른 위치에서 여러 개의 representation subspace에 대한 정보를 함께 사용하는 것과 같은 효과를 낼 수 있다고 한다. 마치 CNN에서 필터를 더 많이 사용해서 정보를 추출하는 것과 비슷한 의미로, single-head일 때보다 문맥을 이용하기 쉽다고 한다.
Positional Encoding
Transformer는 recurrent나 convolution이 없기 때문에 sequence 순서에 대한 정보를 사용하려면 추가적으로 상대적인 위치나 절대적인 위치 정보를 주입해주어야 한다. 이를 위해 encoder나 decoder에서 input vector embedding 시에 positional encoding을 추가하여 위치정보를 주입한다.
Positional encoding을 통해 sequence 정보를 주입하고, sequence 자체를 한번에 attention으로 해석한다는 아이디어는 transformer에서 아주 중요하다고 생각한다.
Positional encoding은 원래 모델 input dimension과 같게 하여 그냥 더해주는 방식을 채택하였다. 특히 이 논문에서는 서로 다른 frequency의 cos, sin 함수를 input embedding에 더해주어 relative position 정보를 주입하려 하였다.
Vision Transformer에서는 learned parameter를 사용하여 positional embedding을 하였다. 성능에는 크게 차이가 없을 것 같다.
Why Self-Attention?
이 논문에서는 recurrent와 convolution layer에 비해서 self-attention layer가 갖는 장점을 아래와 같은 관점에서 설명한다.
- total computational complexity per layer.
각 layer에서 연산 복잡도가 더 작아 연산 속도가 빠르다. 보통 sequence length n에 비해서 vector dimension d가 훨씬 작은 경우가 많으므로, 아래의 표를 보면 recurrent와 convolution에 비해서 연산복잡도가 낮다는 것을 확인할 수 있다. 하지만 sequence가 매우 길어지는 input을 받을 때에는 이 이점이 사라질 수는 있다. 이를 위해 attention하는 neighborhood size를 정해주는 restricted self-attention의 개념도 있다.
- The amount of computation that can be parallelized
Recurrent network의 경우 n개의 sequence를 처리하기 위해 순차적으로 n번 데이터를 forward해야하지만 (time n의 input이 forward되고 나온 output과 time n+1의 input이 다시 forward되는 것을 n번 반복) Transformer는 모든 sequence position을 연결하여 한번에 처리할 수 있다.
- path length between long-range dependencies in the network
Sequence 정보를 처리할 때, 서로 거리가 먼 element 사이의 dependency를 배우는 것은 매우 중요하다. 이러한 dependency를 학습하는데 가장 중요한 요인은 network를 지나는 forward signal과 backward signal 사이의 path length이다. 머릿속으로 loss가 구해지고 back prop이 되는 경로를 생각해보자. 이런 관점에서도 attention이 다른 layer에 비해서 강점이 있다고 한다.
- Interpretation
Self-attention은 sequence data 내부 요소들 사이의 상관 관계를 학습하므로, attention 자체를 visualize 하는 것만으로 어느 정도 모델의 결과를 해석할 수 있다는 장점이 있다. 이 장점은 사실 Vision Transformer에서도 빛나는데, classification token과 attention을 보면 어떤 image patch가 가장 영향을 많이 줬는지를 확인해볼 수도 있다.

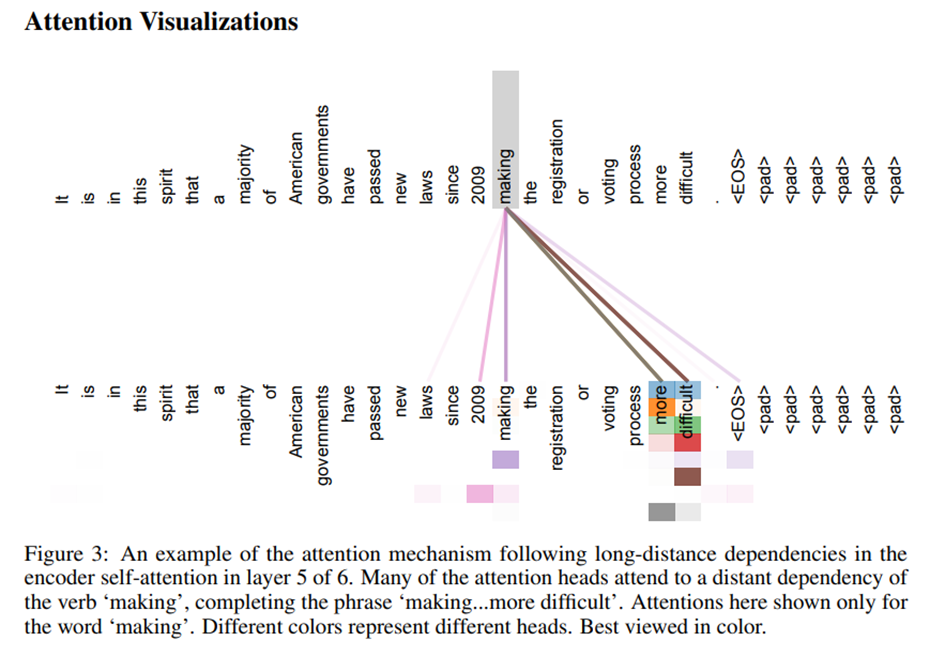
Overall Training
Attention을 이해했으니까, Transformer가 어떻게 작동하는지 한번 보자.
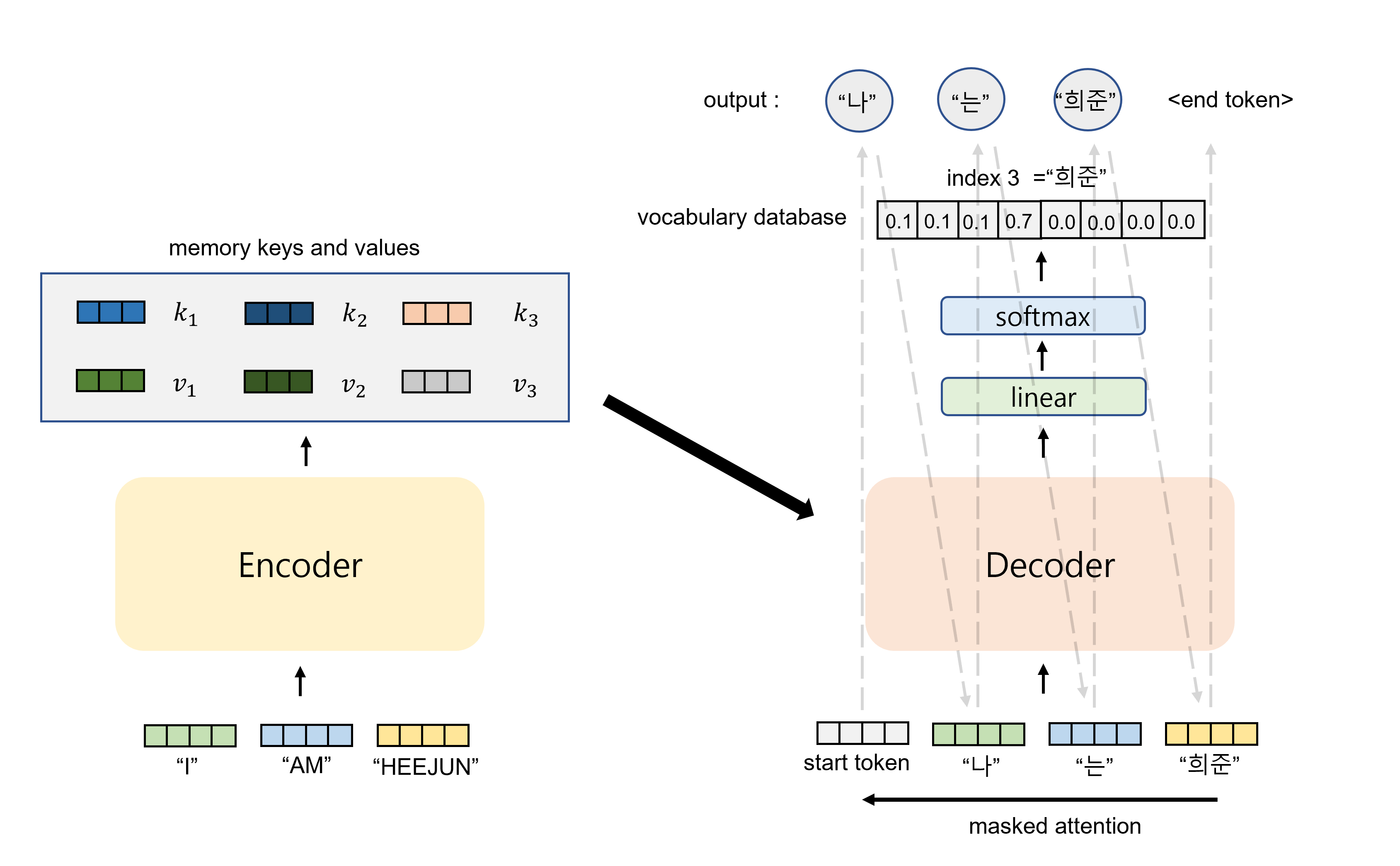
Encoder에서는 문장 내 단어와 문맥을 이해하고, Decoder에서는 순차적으로 번역된 문장을 내놓는다.
(1) Encoding
입력 문장이 들어가면 각 단어는 모두 벡터로 embedding되고 각 위치 정보도 positional embedding을 통해 들어간다.
Embedding된 word sequence는 곧바로 self-attention과 feed forward network을 포함하는 encoder block을 통해 encoding 된다.
Encoding된 vector는 각 단어에 대한 의미와 각 단어가 서로 다른 단어와 어떤 관계를 가지고 있는지에 대한 정보를 포함하고 있을 것이다.
(2) Decoding
Decoder는 번역된 결과를 내놓는 네트워크로, 순서대로 하나씩 output word를 출력으로 내놓는다.
이때 이전 sequence의 output은 다음 sequence의 입력으로 함께 사용한다. 예를 들어 맨 처음에는 start token이 들어가서 "나"라는 단어가 가장 높은 확률로 도출된다. "나"라는 단어는 다시 decoder의 입력으로 들어가서 "는"이라는 output이 나오고, "나"와 "는"은 다시 함께 decoder로 들어가 "희준"이 나오게 된다.
Decoder도 Encoder처럼 self-attention layer가 있어서 해당 position보다 이전의 모든 position의 출력을 참조하도록 한다. 이때, 위에서 설명한 것 처럼 이전의 단어들만을 참조할 수 있도록 현재 position 이후의 단어는 매우 작은 음수(-)로 masking 해서 softmax에서 영향을 주지 못하게 한다.
Decoder에는 masked self-attention 이후에 encoder의 출력으로 나온 key와 value를 사용하는 encoder-decoder attention layer가 있다. encoder-decoder attention layer에서 query는 decoder에서 이전 layer의 것을 사용하고, key, value는 encoder 출력을 사용하는데, decoder의 각 단어의 query를 이용해 input 단어들과 attention을 계산해서 decoder 내부 모든 postion이 input sequence의 모든 위치의 단어를 참조하도록 한다.
Loss 계산은 decoder의 softmax output이 그 위치에 와야하는 단어의 Database안에서 index와 같도록 학습이 된다고 생각하면 된다.
Opinion
이번 리뷰에서 Result는 건너 뛰는 것으로 한다. 사실 기계 번역 등을 잘 몰라서도 있는데, 그냥 잘한다. 매우 powerful하고 이미 많은 application이 생겨났다.
Text뿐만 아니라 image, audio와 video 등의 modality에서 적용된 연구가 많이 있고, 다양한 task에서 엄청난 성능을 보여주고 있다. 생각보다 많은 데이터가 sequence data이다. Vision Transformer에서 addressing하는 것처럼 이미지도 사실 16x16 words sequence로 생각할 수 있다.
Attention mechanism은 데이터의 맥락을 파악하는 능력이 훌륭한 것 같다. 연산 자체가 데이터를 해석하는데 있어서 필요한 정보와 필요하지 않은 정보를 걸러내는 역할을 수행하기 때문에 매우 합리적으로 보이기도 한다.
다만, Transformer에서 사용하는 attention이나 mlp는 모든 weight가 독립적이고 공유되지 않으므로 기존의 CNN보다 훨씬 더 많은 데이터를 필요로 한다. 즉, 어떤 문제를 잘 풀기 위한 사전의 가정 (Inductive Bias)를 최대한 배제하면서 general한 문제를 다 잘 풀 수 있도록 설계가 된 것이고, 그러기 위해서는 정말 정말 많은 데이터를 보고 배워야한다. 이것은 아주 중요한 문제이므로 나중에 더 자세히 논의를 해보도록 하자.

좋은 글 감사합니다.
신작이 없군요.. 기다리고 있습니다.