Paper : Digging Into Self-Supervised Monocular Depth Estimation (Clément Godard, Oisin Mac Aodha, Michael Firman, Gabriel Brostow / ICCV 2019)
Monodepth1를 발전시켜 나온 Monodepth2 논문으로, self-supervised 방식으로, 하나의 이미지를 통해 depth estimation을 수행하고, 아주 간단한 모델을 통해 매우 좋은 성능을 보인다.
Highlights
- Occlusion을 robust하게 다루기 위한 minimum reprojection loss
- Visual artifact를 줄이기 위한 full-resolution multi-scale sampling method
- Camera motion 가정을 해치는 training pixel을 무시하기 위한 auto-masking loss
Introduction & Background
Monocular depth estimation의 목표는 single color input image로 부터 dense depth image를 얻어내는 것이다.
하지만 supervised learning을 위한 정확한 depth map ground truth는 얻기가 어렵기 때문에, monocular depth estimation 모델들은 self-supervised 접근법에 대한 연구가 활발히 진행되었다.
Self-supervised 접근을 이용한 Depth estimation은 주로 image reconstruction을 supervisory signal로 사용하였는데, image set을 input으로 넣고, depth estimation 정보를 이용해 한 이미지를 통해 다른 이미지를 recon하게 만듦으로써 네트워크를 학습했다.
이런 방법론들은 사용 데이터에 따라 조금씩 다른데, 크게는 synchroized stereo pairs (Monodepth 1)나 monocular video를 사용하는 방법으로 나뉜다.
두 데이터 중에 stereo data를 이용한 학습은 left / right 이미지를 사용하는데, pair 사이의 pixel disparity를 estimation하도록 네트워크를 학습하고, test-time에는 하나의 이미지에 대한 depth를 estimate해야하므로 한쪽 이미지를 통해 다른쪽 이미지를 recon하는 방식을 사용한다.
반면에 monocular video를 이용한 학습은 학습 데이터를 구성하기 쉬운 반면 학습 시에 temporal image pair 사이의 camera의 ego-motion을 estimation하는 pose estimation network가 추가적으로 필요하다. 이 camera pose는 학습 시에만 사용되며 test-time에는 사용하지 않는다.
이렇게 두 방법은 조금씩 다르지만, 기본적으로 self-supervised 접근법들은 모두 appearance나 material properties에 대한 가정에 의존하므로, 이를 잘 설계해주는 것이 중요하다.
왜냐하면 input image set 사이에서 appearance나 material properties 정보를 잘 matching 시킬 수 있어야 image 사이의 disparity를 잘 구할 수 있고, 이를 통해서 depth를 잘 estimate할 수 있기 때문이다.
본 연구에서는 몇 가지 architectural/loss innovation을 통해 위의 두 접근법에 모두에 대한 성능을 크게 향상시켰다.
-
Monocular supervision을 사용할 때 발생하는 occluded pixel의 문제를 해결하기 위한 appearance matching loss
-
상대적인 camera motion이 없을 때, 이를 필터링하기 위한 auto-masking approach
-
Depth artifact를 줄이기 위한 multi-scale appearance matching loss
Method
Self-Supervised Training
Self-supervised depth estimation은 하나의 viewpoint의 이미지로부터 또다른 viewpoint의 이미지를 예측하는 일종의 novel view-synthesis 문제로 생각할 수 있다.
특히, network로 하여금 intermediary variable인 depth나 disparity를 사용하여 image synthesis를 수행하게 제한함으로써, 간접적으로 모델으로부터 depth 정보를 추출해낼 수 있게 되는 것이다.
Monodepth 2에서도 다른 view point로의 photometric reprojection error를 최소화하는 것을 목표로 네트워크를 학습한다.
즉, 각 source view image 를 target image 로 최대한 비슷하게 synthesize하도록 학습하는 것이다.
이때, 에 대한 의 상대적인 pose를 로 표현하면, 네트워크는 아래의 photometric reprojection error 를 최소화하는 dense depth map 를 예측한다.
** pose는 3D 공간 속에서 camera frame간의 rotation, translation을 나타내는 변환 행렬이라고 보면 된다.
여기서 는 pixel space의 L1 loss와 같은 photometric reconstruction error, 는 를 로 projection한 것의 2D coordinate이고, 는 sampling operator. 는 intrinsic parameter로, 미리 계산되어 고정된다고 가정한다.
Source image를 sampling하기 위해서는 미분 가능한 bilinear sampling을 사용하고, photometric error는 L1과 SSIM을 사용한다.
추가적으로, disparity discontinuity를 방지하기 위한 edge- aware smoothness loss도 사용한다.
여기서 로 mean-normalized inverse depth를 사용한다.
수식을 보면 disparity map의 변화량과 이미지 pixel값의 변화량을 이용하는데, 이미지의 pixel값의 변화량이 적은 곳에서 depth 변화가 적도록하고, 이미지의 pixel값이 급격하게 변하는 곳에서도 어느정도 smooth하게 depth가 변하도록 한다.
Stereo training에서는 source image 를 target 의 stereo pair로 사용하면 되고, monocular training에서는 의 인접한 두 frame ()를 source image로 사용하면 된다.
정리하자면, self-supervised depth estimation 방법은 위에서 설명한 photometric reprojection error와 edge aware smoothness loss를 통해 네트워크를 학습한다.
Monodepth2에서는 이를 조금 더 발전시켜서 성능을 향상시키려 한다.
Improved Self-Supervised Depth Estimation
추가적인 기법들을 사용하여 self-supervised method의 depth quality를 향상시키려 하였다.
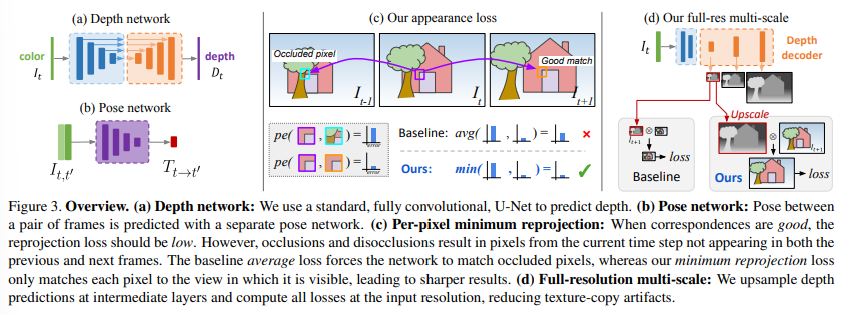
1) Per-Pixel Minimum Reprojection Loss
기존의 self-supervised depth estimation 방법들은 가능한 모든 source image로부터 reprojection error를 다 계산하여 average를 취하는 방식을 사용하였다.
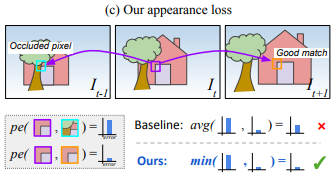
하지만 위의 그림처럼 target image ()에서는 보이는 pixel이 특정 source image ()에서는 보이지 않을 때 문제가 발생할 수 있다.
이러한 문제를 발생시키는 pixel을 주로 1) image boundary에서 카메라의 egomotion때문에 안보이는 pixel이거나, 2) 물체로 인해 가려진 pixel인데, 첫번째 경우는 적당한 masking으로 해결이 가능하지만 두번째 경우는 처리가 어렵다.
가령 network가 그 pixel의 depth를 정확하게 추정했을 때, source image에서 가려졌던 pixel 값이 target과 잘 매칭이 되지 않을 것이고, 결과적으로 photometric error penalty거 커지게 된다.
이러한 문제를 해결하기 위해서, 본 논문에서는 아주 간단한 방법을 제시했는데, 각 pixel에 대해 source image들 중에서 reprojection error가 작은 쪽만 반영하는 것이다.
실제로는 아래와 같은 example에서 도움이 되는데, 에서 빨간색 원 모양이 에서는 가려지므로, 해당 pixel에 대해서 과 사이에는 loss가 구해지지 않는다. 반면 에서는 해당 픽셀이 보이므로 loss를 구한다. 오른쪽 위 color map은 각 pixel에 대해 어떤 source image와 loss를 구하게 되는지를 나타낸다.

2) Auto-Masking Stationary Pixels
Self-supervised monocular training에서는 주로 moving camera & static scene을 가정하는데, 만약 camera가 stationary하거나 object가 moving하는 상황에서는 성능이 매우 떨어지게 된다.

예를 들어 위와 같이 움직이는 자동차가 있을 때, 하나의 scene에 대한 disparity를 구할 수가 없기 때문에 infinite depth를 가지는 'hole'을 만들어내는 문제가 발생할 수 있다.
이를 해결하기 위해 본 논문에서는 연속된 frame에서 appearance change가 없는 pixel을 filter-out하는 auto-masking method를 사용한다.
이러한 방식을 사용하면, network는 카메라와 같은 속도로 움직이는 물체나, 카메라가 움직이지 않을때 monocular video의 모든 frame을 무시하게 된다.
저자들은 auto-masking을 위해 per-pixel mask 를 사용하였다.
이는 reprojection error가 warped image 보다 unwarped source image 에 대해서 더 작을 때를 masking하는 방식이다. 즉, frame간의 이미지 차이가 어느정도 있는 경우에만 학습을 진행하는 것이다.

위 그림에서 오른쪽 이미지의 검정색 pixel이 loss masking된 부분을 나타내는데, 위의 예제는 camera와 비슷한 속도로 움직이는 물체를 masking한 것이고, 아래 예제는 camera가 static한 경우에 모든 frame을 masking한 예제이다.
3) Multi-scale estimation
기존의 연구들은 대부분 multi-scale depth prediction을 수행하였고, 이를 통해 각 scale에서 각각 image reconstruction loss를 구해 학습하였다.
하지만 이렇게 학습할 경우 lower resolution depth map에서 low-texture region에 'hole'을 생성하거나 texture-copy artifact를 만드는 경우가 많았다. (왜냐하면 low resolution depth map에서는 변화량이 아주 적은 경우가 많기 때문에)
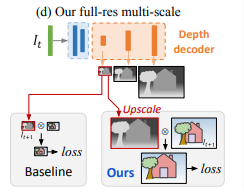
이러한 문제를 해결하기 위해 본 논문에서는 애매한 low-resolution image에서 photometric error를 계산하지 않고, lower resolution depth map (=모든 intermediate resolution)을 input image resolution으로 upsample하고, reproject한 뒤, resample하여 photometric error를 계산하였다.
Final Training Loss
최종 training loss는 위에서 설명한 per-pixel smoothness loss와 masked photometric loss를 합친 것으로, 각 pixel, scale, batch에 대해 평균내서 사용한다.
Additional Considerations
1) Depth network
Monodepth2의 depth estimation network는 U-Net을 사용하고, encoder로는 ResNet18과 같이 비교적 작은 네트워크를 사용하였다.
Depth estimation은 depth network의 sigmoid output 를 아래와 같이 변환하여 사용하였다. (와 는 depth 값은 0~100으로 제한하기 위함)
2) Pose network
Monodepth2의 pose network는 2개의 pair image channel 방향으로 concat하여 input으로 받고, 6-DoF relative pose를 output으로 출력한다.
특히, rotation은 axis-angle 표현법을 사용한다.
Results
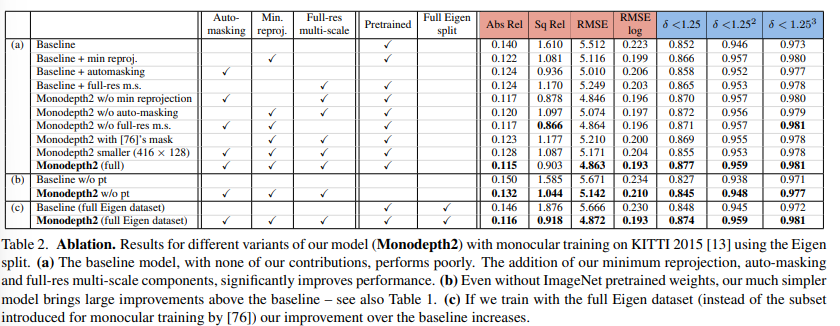
아래는 KITTI dataset에 대한 result로 다른 모델에 비해 좋은 성능을 보여주고 있다.
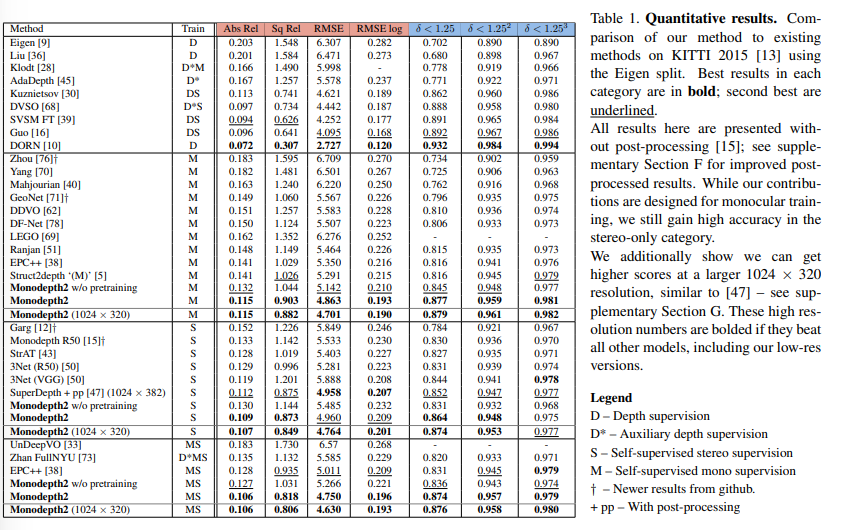

ablation도 잘 진행하였다.
Discussion
Monodepth2는 기존의 학습 framework를 바탕으로 간단한 loss design과 training scheme을 제안하여 self-supervised depth estimation 성능을 향상시킨 모델이다.
하지만 depth estimation network의 주요 목적 중 하나가 자율 주행 등에 사용되는 비싼 센서를 대체하는 용도인 것을 생각했을 때, 모델의 computational cost efficiency나 inference time efficiency 등에 대한 발전이나 분석 등이 함께 포함되었다면 더욱 좋았을 것 같다.

안녕하세요! 정리 잘 해주신 덕분에 공부 많이 됐습니다. 감사합니다.
잘 이해가 안가는 부분이 있어서 질문드리고자 합니다.
'Self-Supervised Training' 부분의 'photometric reprojection error'를 구하는 과정에서 t 프레임 시점 이미지를 Depth Network에 통과시킨 D_t와 pose T를 기반으로 reconstructed image를 생성하는 것은 이해했습니다.
그런데 그렇게 만들어진 이미지는 t 시점의 Depth map을 t'시점으로 옮겨와서 재구성한것이기때문에
t'시점 이미지를 재구성한것과 같지 않은가요? 'photometric reprojection error'를 구할 때 I_t'가 아닌 I_t와의 reconstructed error를 구하는 이유가 궁금합니다.