Monocular Depth Estimation (MDE) 방법론들 중에서 가장 잘 활용되어 보이는 DepthAnything 세번째 버전
DepthAnything V3는V1,V2의 monocular input에서 나아가 any-view input을 받는 새로운 모델 시리즈라고 보면 될 듯.
✅ MDE task에서 더 나아가, single / multiple images로부터 depth를 기반으로 3D physical world를 이해하려는 3D foundation model을 만들려는 시도
[Depth Anything 3: Recovering the Visual Space from Any Views]([2511.10647] Depth Anything 3: Recovering the Visual Space from Any Views) (Haotong Lin, Sili Chen, Junhao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, Bingyi Kang / ICLR, 2026 (oral))
프로젝트 페이지 : Depth Anything 3: Recovering the Visual Space from Any Views
갤러리 : https://depth-anything-3.github.io/gallery.html
MDE,SfM,MVS,SLAM,NVS과 같은 3D vision task들은 사실상 거의 비슷한 컨셉을 공유하면서도 서로 꽤나 다른 방법으로 문제를 풀어왔음.
→ 사실 가장 큰 차이는 사용하는 input view의 수 밖에 없음
- 이 연구에서는 더 근본적인 해결책을 찾으려고 함.
→ 인간의 공간 지능과 비슷하게, 정말로 이미지를 통해 그 3D 구조를 이해하는 모델을 만들고자 함.
DepthAnything V3모델의 목표는 다음과 같음.
Recovery of consistent 3D geometry from diverse visual inputs—single image, multi-view collections, or videos—and optionally incorporate known camera poses when available.
→ 즉, 임의의 visual input으로 부터 일관적인 기하학적 구조를 예측하고자 하는 것이고, 이는 depth와 ray를 예측함으로써 가능함.
Depth Anything 3
Depth 정보를 3D geometry reconstruction과 어떤 식으로 연결짓는지만 이해하고 가려고 한다.
- 네트워크 아키텍처나 학습 방법, LOSS 구성 등은 생략.
Formulation
-
기본적인 Camera physics
-
한 이미지에서 픽셀 이 3D 공간으로 projection된 점 을 표현하면,
-
는 각 픽셀에서의 depth
-
위 식은 image coord → camera coord → world coord 순으로 back-projection 시켜주는 식이라고 보면 된다.
-
이 를 잘 구할 수 있으면 3D 공간을 잘 recover한 것으로 볼 수 있다.
Depth-ray representation
-
그런데 실제로 네트워크로 rotation matrix 를 예측하는 것은 매우 어려움.
-
그래서 저자들은 camera pose를 per-pixel ray map으로 implicit하게 표현했음.
→ 각 픽셀 마다, origin 과 direction 로 이루어진 를 정의
→ 는 를 카메라 frame으로 backprojection시키고 world frame으로 회전 ()시키면 구할 수 있음 :
→ 그리고 이 dense ray map 이 있어서 모든 픽셀에 대해 을 정의
- 이렇게 하면, world coord의 3D point를 아래와 같이 쉽게 구할 수 있음.
Deriving Camera Parameters from the Ray Map
- 먼저, 각 이미지마다 camera center 는 per-pixel ray origin vector를 평균한 값으로 사용
- 이제 rotation 과 intrinsic 를 estimate해야 하는데, 이 문제를
homography를 찾는 문제로 정의
-
일단 단순한 기준 카메라를 하나 만들어보자. 이 카메라는 아무런 왜곡이나 회전이 없어서 () 픽셀 좌표가 곧 그 방향으로 뻗어나가는 ray의 방향이 됨. (좌표계의 원점에 있고, 앞을 똑바로 바라보고 있는 카메라)
-
이제 실제 우리가 사진을 찍은 타겟 카메라를 생각하면, 이 카메라는 어딘가로 회전 되어있고, 렌즈의 특성 도 다름. 이 타겟 카메라의 ray direction 로 변환하는 식은 로 쓸 수 있는데, 이때 direct homography 로 두면, 픽셀 위치 에 라는 행렬을 곱하면 진짜 광선의 방향 이 나온다라는 공식을 만들어낼 수 있음.
-
이때 우리 모델은 이미 각 픽셀이 world 공간에서 어떤 방향으로 뻗어나가는지 예측하기 때문에, 이 ray 행렬 과의 geometric error를 최소화하도록 최적화 해서 를 구할 수 있음.
☑️ 이게 transformation을 상상하면 헷갈리는데, 그냥 원점에서 앞을 바라보고 있는 기본 카메라를 기준으로 했을 때, 내 카메라의 위치가 어디 있고, 카메라 특성은 어떻게 다른가를 최적화해서 구한다고 생각하면 될 것 같음.
- 위 최적화는 Direct Linear Transform 알고리즘으로 풀고, 를 구하면 RQ decomposition으로 을 구할 수 있음.
Minimal prediction targets
-
위에서 살펴본 것 처럼 3D geometry를 복원할 때, depth와 ray map만 잘 예측해도 다른 3D 특성들을 잘 유도해낼 수 있음.
-
저자들은 이러한 depth-ray representation이 다른 representation에 비해서 3d scene structure와 camera motion을 포착하는데 더 유리하다고 한다.
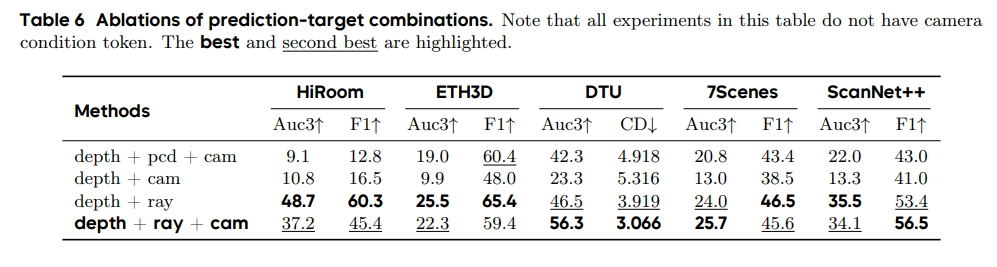
- pcd는 pointcloud, cam은 camera pose
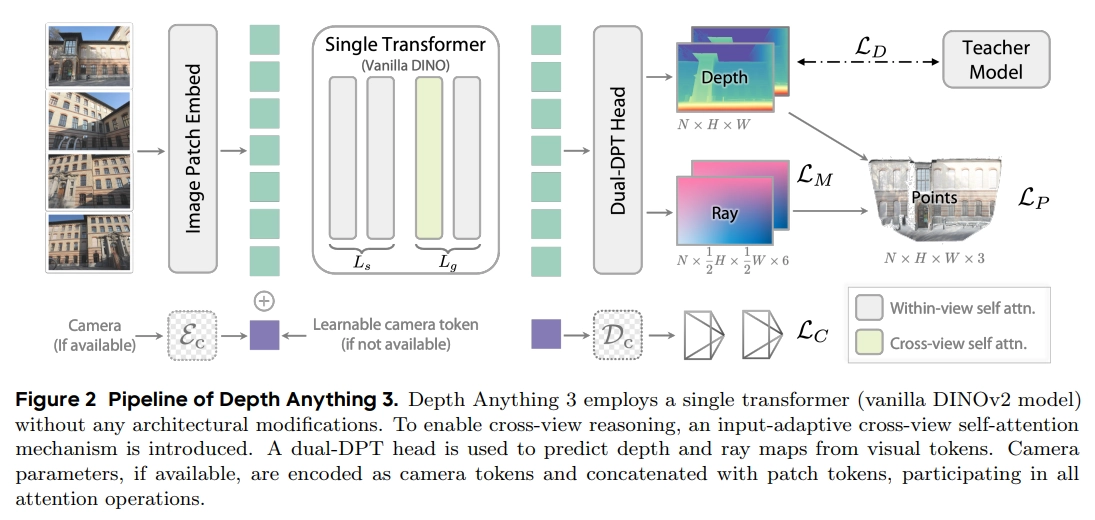
Architecture
-
전체 아키텍처는 위와 같음
Single vision transformer backbone: cross-view attention + single view attentionCamera condition injection: 가능하다면 넣어줌Dual-DPT head: depth 와 ray를 predict. 선택적으로 camera pose도 예측
-
하나의 Transformer model만 활용하여 간단하고 효율적인 아키텍처
-
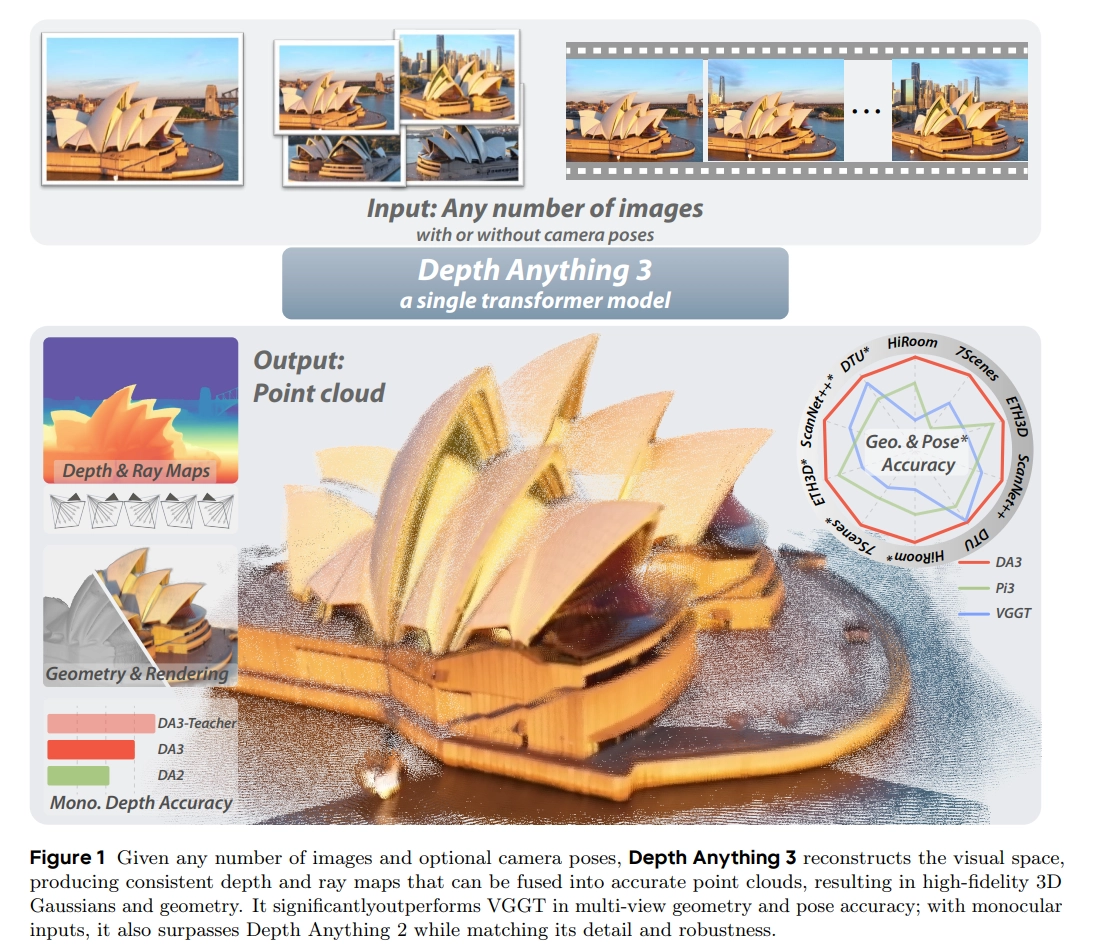
Depth & ray output을 통해서 3D point cloud reconstruction이 가능
Results
- 일관적인 Depth estimation이 실제로 downstream 3D vision task에 큰 도움을 줄 수 있고, 이를 검증하기 위해서 저자들은 여러 task에 대해 검증
Pose estimation
- 여러 이미지들이 feed-forward model에 들어가서 pose와 depth estimation을 출력
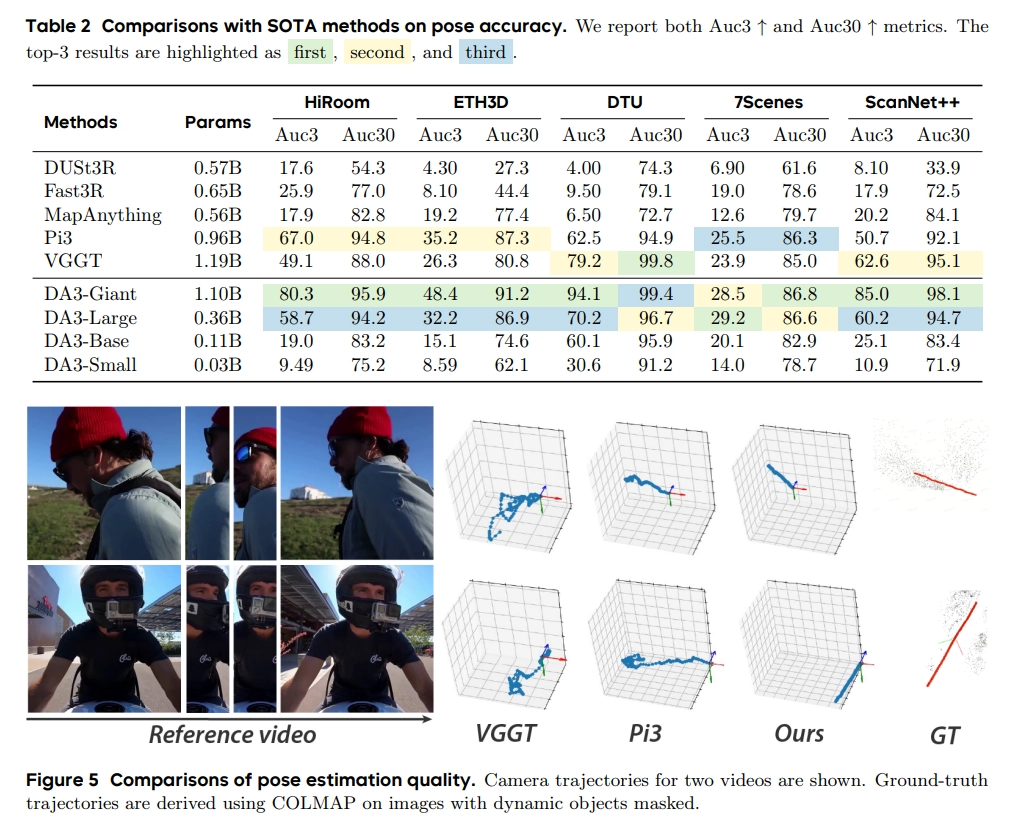
Geometry estimation
- 같은 이미지 셋에 대해서 predicted pose와 predicted depth로 point cloud를 계산.
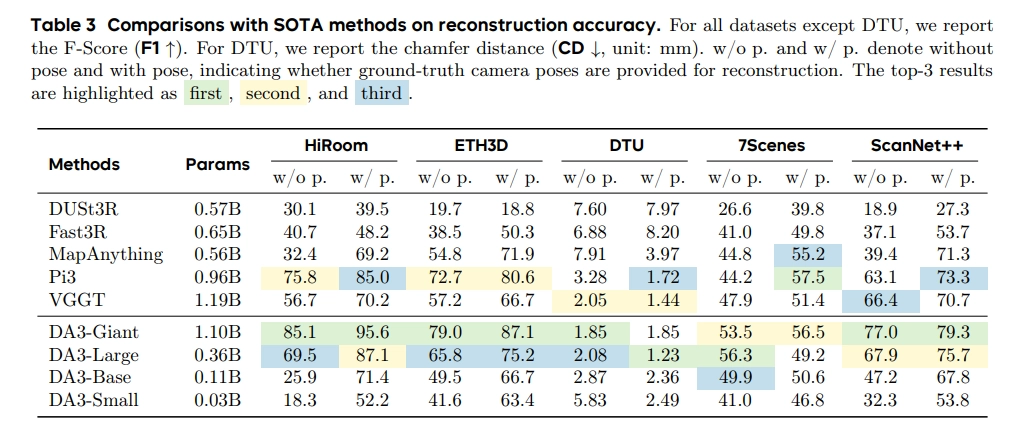
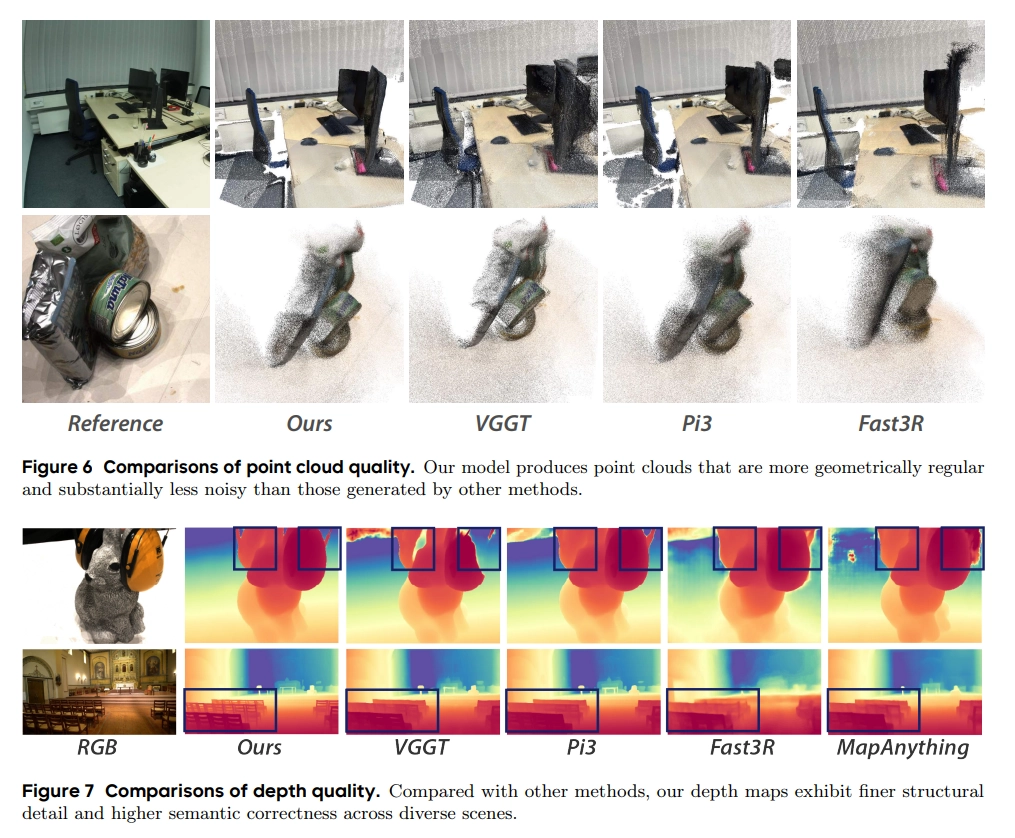
Visual Rendering
-
각 scene마다 랜덤하게 test view를 고르고 12개의 input view를 골라서 rendering
-
추가적인 DPT head를 fine-tuning하여 학습하였고, pixel-aligned 3D Gaussian 출력을 내도록 학습하였다.
- 각 픽셀마다 camera-space에서 3DG 파라미터를 예측하였다.
- 각각 opacity, rotation quaternion, scale, RGB color 의미
- Depth 예측 값은 이 3D Gaussian의 global 좌표를 계산하는데 활용되었고,
- 이 gaussian들은 camera pose가 주어졌을 때, rasterize되어서 새로운 이미지로 만들어짐.