Monocular Depth Estimation (MDE) 방법론들 중에서 가장 잘 활용되어 보이는 DepthAnything 두번째 버전
[Depth Anything V2]([2406.09414] Depth Anything V2) (Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao / Neurips, 2024)
프로젝트 페이지 : Depth Anything V2
-
MDE는 discriminative model을 활용하는 방법(
DepthAnythingV1)과 generative model을 활용하는 방법 (Marigold) 을 중심으로 발전해왔다. -
각 방법은 서로 장단점이 분명함. (Marigold는 디테일을 더 잘 포착하고, Depth Anything은 더 robust함)

→ 위 두 방법론들의 장점을 모두 취할 수 있는 MDE foundation model을 만들고자 하는 연구
DepthAnythingV1와 같은 discriminative model을 활용하는 방법을 취하되, 이 방법이 갖는 약점을 보완하는 식으로 발전- 그리고 여전히 핵심은 데이터의 양과 질.
핵심 방법론
Revisiting the Labeled Data Design of Depth Anything V1
❓Midas나 Depth Anything V1 의 coarse한 depth 결과가 discriminative 모델 때문 ? → No.
- 사실은 모델 자체 때문이 아니라 labeled data가 문제

→ 학습하는 label data depth가 noisy하고, detail이 없음.
- 하지만 synthetic image data를 보면 fine detail까지도 depth label로 잘 표현이 되어있음.
-
hypersim과 같은 synthetic data**는 CG 엔진이나 시뮬레이터를 사용하여 생성한 이미지를 의미함
-
- 실제로 real label 이미지 대신에 synthetic image를 활용하여 학습한 네트워크는 디테일까지 잘 예측함.
Challenges in Using Synthetic Data
- Synthetic data의 활용도 근데 여전히 한계가 있음.
- 실제 이미지와 가상 이미지 사이의 distribution shift
- 가상 이미지의 restricted scene coverage
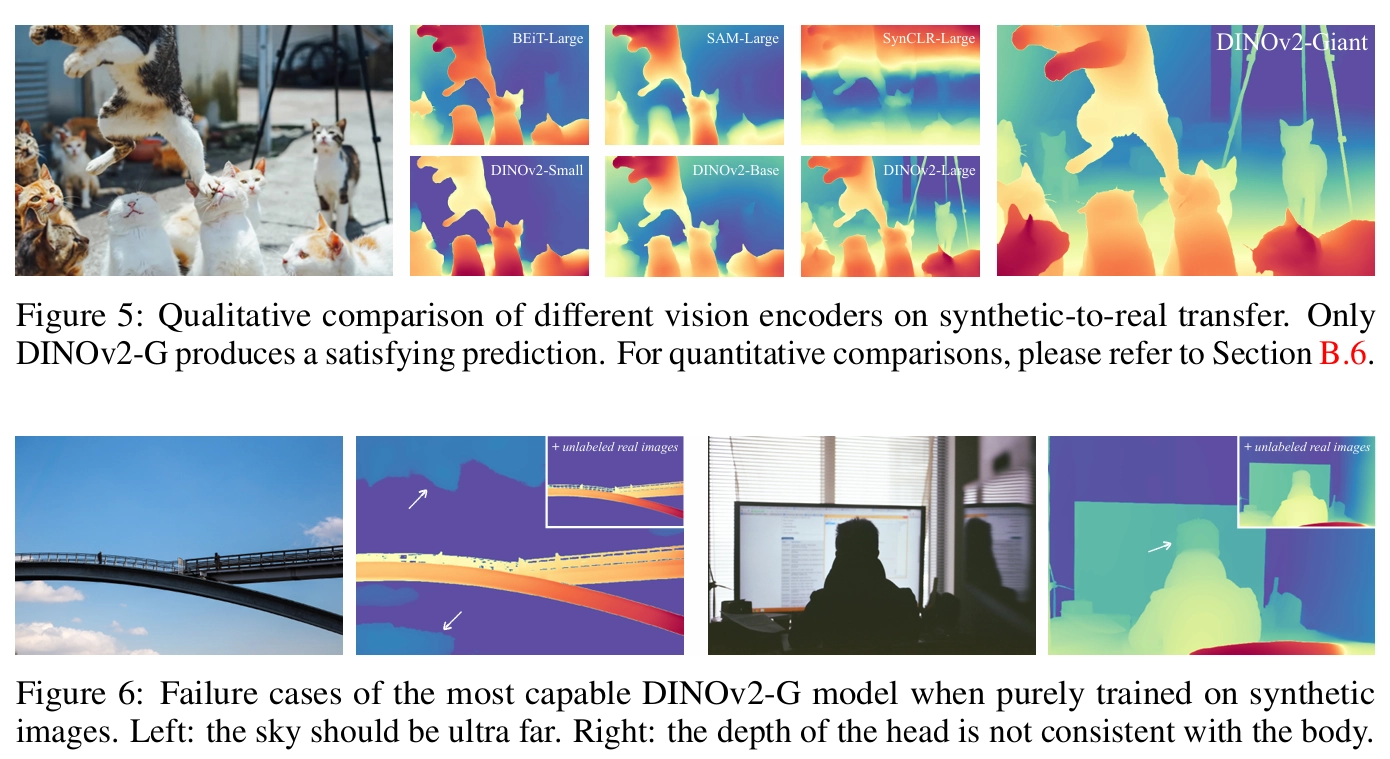
→ DINOv2-G 정도 되는 크기의 encoder의 generalibility에 의존하지 않고서는 가상 데이터로만 학습 시켰을 때, 실제 이미지에서는 잘 작동하지 않는 경우가 많음.
- 근데 DINOv2-G같은 모델은 너무 resource-intensive.
Key Role of Large-Scale Unlabeled Real Images
-
핵심은 unlabeled real image를 활용하는 것.
-
핵심 방법론
- DINOv2-G 기반 MDE 모델을 high-quality synthetic image만을 활용하여 teacher model을 학습
- Large-scale unlabeled real image 대해 pseudo depth label을 생성
- 이 pseudo-labeled real image로 student model을 학습
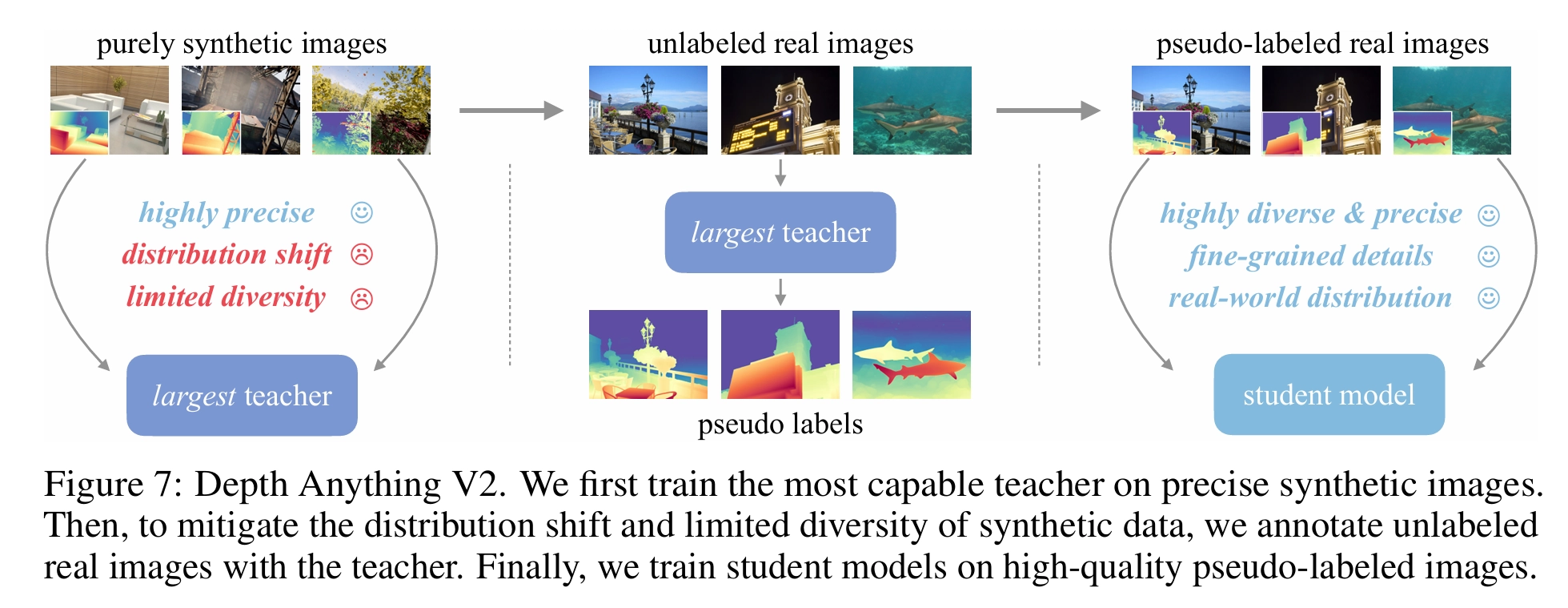
-
이렇게 하면 real world의 훨씬 더 넓은 distribution의 scene을 cover할 수 있을 뿐더러 synthetic data의 fine-detail label을 학습할 수 있음.
-
나머지 학습 loss 설계 등은 V1과 동일한 듯.
-
추가적으로, top 10% loss를 학습 시 무시함으로써 혹시나 있을 noisy pseudo label을 걸러냄
결과
-
또 다른 contribution으로, 기존의 benchmark 데이터 셋이 noisy하다는 것과 다양성이 부족하다는 것, 그리고 해상도가 낮다는 것을 지적하면서 새로운 benchmark
DA-2K를 제안 -
일단 Zero-Shot Relative Depth Estimation task에서 기존의 Depth Anything V1 및 다른 모델들에 비해 좋은 성능 보여줌
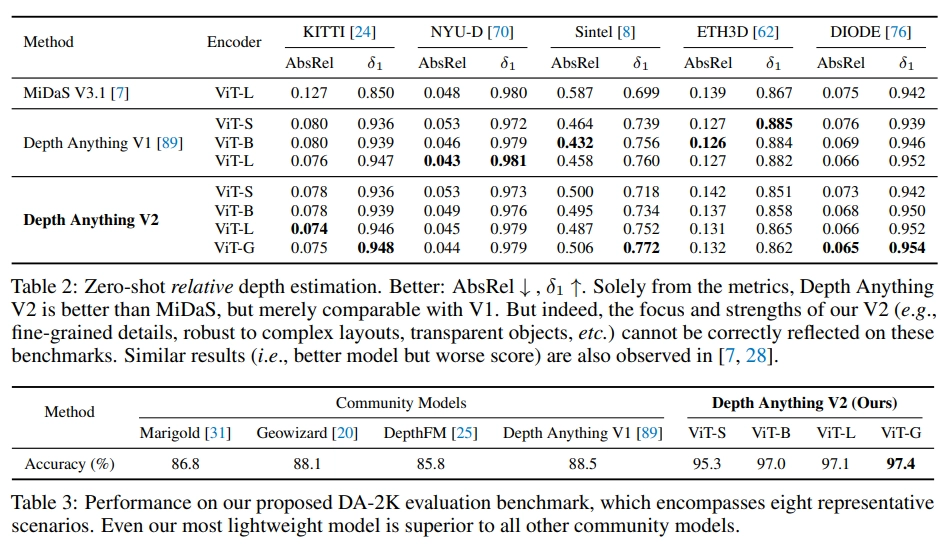
- Metric Depth Fine-tuning task에서도 다른 여러 모델들 보다 좋은 성능 보여줌
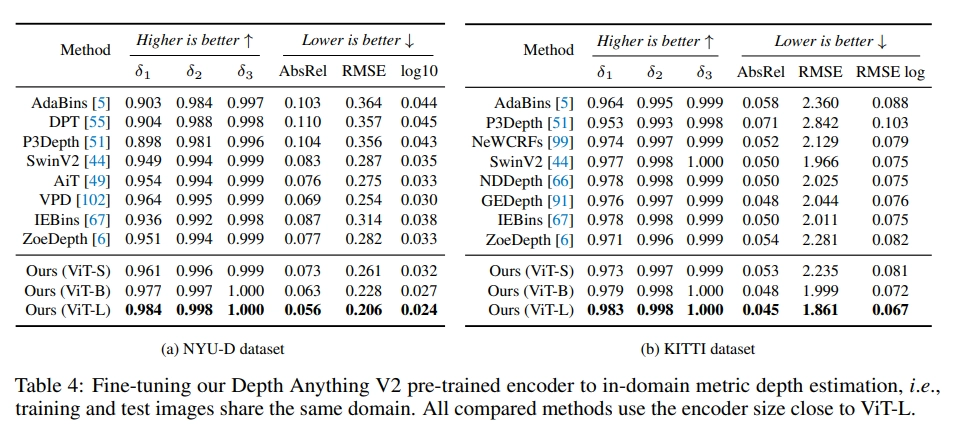
- Qualitative Results



