Paper : Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (Thomas Müller, Alex Evans, Christoph Schied, Alexander Keller / SIGGRAPH 2022)
- Motivation : Multiresolution Hash Encoding이 궁금해서 공부
Short Summary
- NeRF에서 사용하는 positional encoding인 frequency encoding을 Multiresolution Hash Encoding으로 대체
- Rapid training / High quality / Simplicity의 측면에서 우세
Introduction

NeRF에서는 deep neural network가 low frequency function을 학습하도록 bias를 가지고 있기 때문에, 그대로 3d-coordinate를 network에 입력해주면 high frequency detail을 학습하기 어렵다고 지적했다.
이를 해결하기 위하여 입력 차원을 sinusoidal frequency function을 이용해 늘려주고 입력하는 frequency encoding을 사용하였다.
여기서 는 input point 좌표, 은 사용할 frequency band의 길이를 나타낸다.
이렇게 입력 feature를 늘린 후, MLP에 feeding하여 NeRF를 학습한다. 하지만 이렇게 늘어난 차원에 의해 MLP의 깊이 또한 깊어져야할 것이고, 학습 시간 및 계산량이 많다.
이를 해결하기 위해 이 논문에서는 multiresolution hash encoding을 제안하여 학습 속도 및 퀄리티를 높였다.
-
Parametric encoding
parametric encoding은 grid와 같은 보조적 data structure에 trainable parameter를 부여하여, 학습시키고, look-up table처럼 읽어서 input vector에 따라 parameter를 interpolate하는 방법이다.
이렇게 하면 학습 parameter가 훨씬 많아지는 대신에 computational cost를 많이 절약할 수 있고, 학습 시간을 단축시킬 수 있다고 한다.
이후에는 학습 parameter 수를 줄일 수 있는 coarse parametric encoding 등이 연구되었다.
Plenoxels: Radiance Fields without Neural Networks (Alex Yu, Sara Fridovich-Keil, Matthew Tancik, Qinhong Chen, Benjamin Recht, Angjoo Kanazawa / CVPR 2022)는 이러한 방법을 활용한 대표적인 연구로 Voxel grid를 먼저 구성하고, 각 voxel의 3차원 좌표에 density와 coefficient를 trainable parameter로 둬서 direct optimization을 진행한다. 실제로 ray는 정확히 voxel grid위의 voxel을 지나지는 않으므로, trilinear interpolation하여 값을 구해낸다.
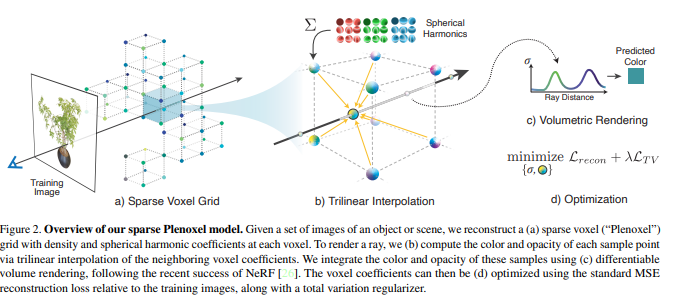
Multiresolution hash encoding 또한 parametric encoding 방식을 바탕으로 하고 있으며, 이를 개선하기 위해 multi resolution의 spatial hash table을 활용하였다.

위 그림을 보면 서로 다른 encoding과 parametric data structure 사이의 recon 성능을 비교해볼 수 있다. MLP의 weight와 encoding parameter수를 확연히 줄이면서, 시간 감축과 성능 향상을 함께 얻었다.
Method
NeRF를 위한 neural network 가 주어졌을 때, training time과 quality를 높일 수 있는 encoding 를 찾는 것이 주된 목표이다. 여기서 , 모두 학습된다.
Encoding parameter로는 개의 resolution마다 각각 차원을 갖는 개의 feature vector를 포함하는 어떤 feature table을 학습한다.
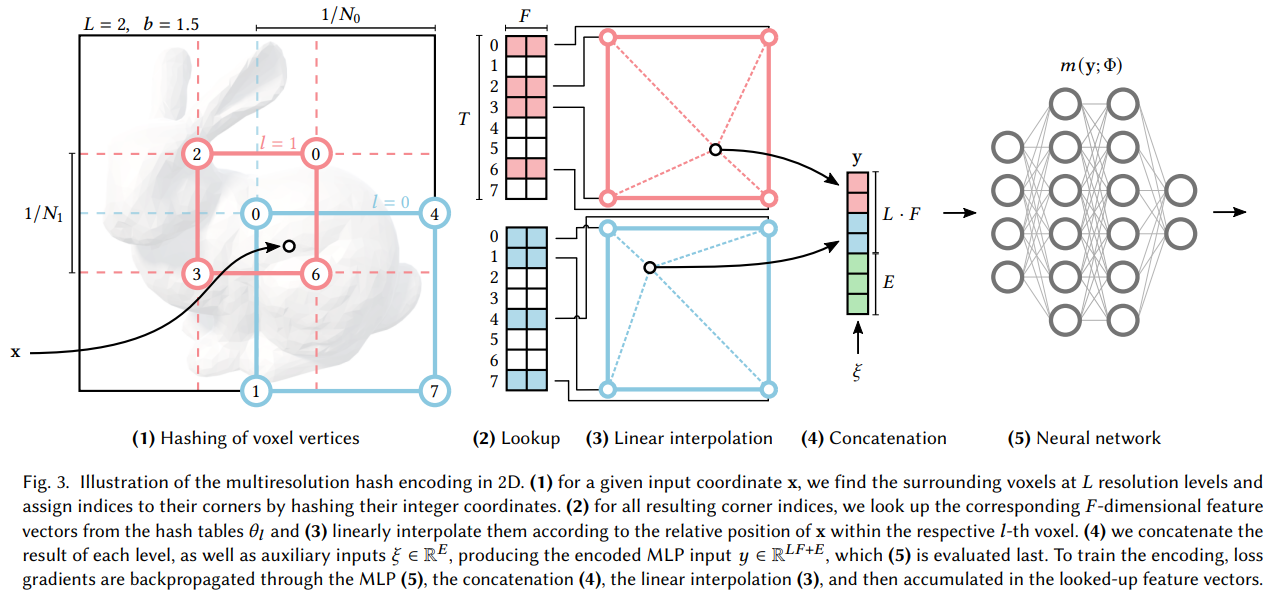
위 그림은 multi resolution hash encoding을 2D에서, 두 가지의 resolution에 대해 진행했을 때를 도식화한 것으로, 실제로는 3D에서 더 많은 resolution을 가지고한다.
예시 그림에서는 인 상황에서 max resolution이 3, min resolution이 2이다. 각 level의 resolution에 대한 계산은 아래와 같이 한다.
(1) Input 좌표 x에 대해 resolution level별로 해당 좌표를 포함하는 voxel을 찾아 주변 4개의 좌표를 찾는다.
각 resolution level 이 주어지면, input coordinate 는 각 level의 grid resolution으로 scaling해서 주변 corner vertices를 찾게 된다. 그 주변 vertices가 해당 resolution의 하나의 voxel을 span (2차원은 4개, 3차원은 8개)
(2) hash table로부터 주변 4개의 좌표의 차원의 feature vector를 look up
4개 좌표의 integer 좌표값을 hashing해서 feature table의 indices를 assign해준다.
Dense grid가 인 Coarse level에서는 hash feature table과 1대1 대응으로 뽑아내면 되고, 그렇지 않은 경우네는 spatial hash function을 이용하여 hash feature table로 mapping시킨다고 한다.
아래 그림처럼 예를 들어서 (T는 이미 정해져 있는 상태에서) resolution이 라고 하면 개의 grid point가 만들어질 텐데, low resolution에서는 그냥 각 grid point를 table의 각 feature와 mapping시키고, high resolution에서는 의 feature vector를 만들어내기가 부담스러우니까 hash function으로 mapping index를 결정해주겠다는 의미같다. (잘 이해했는지는 모르겠다.)
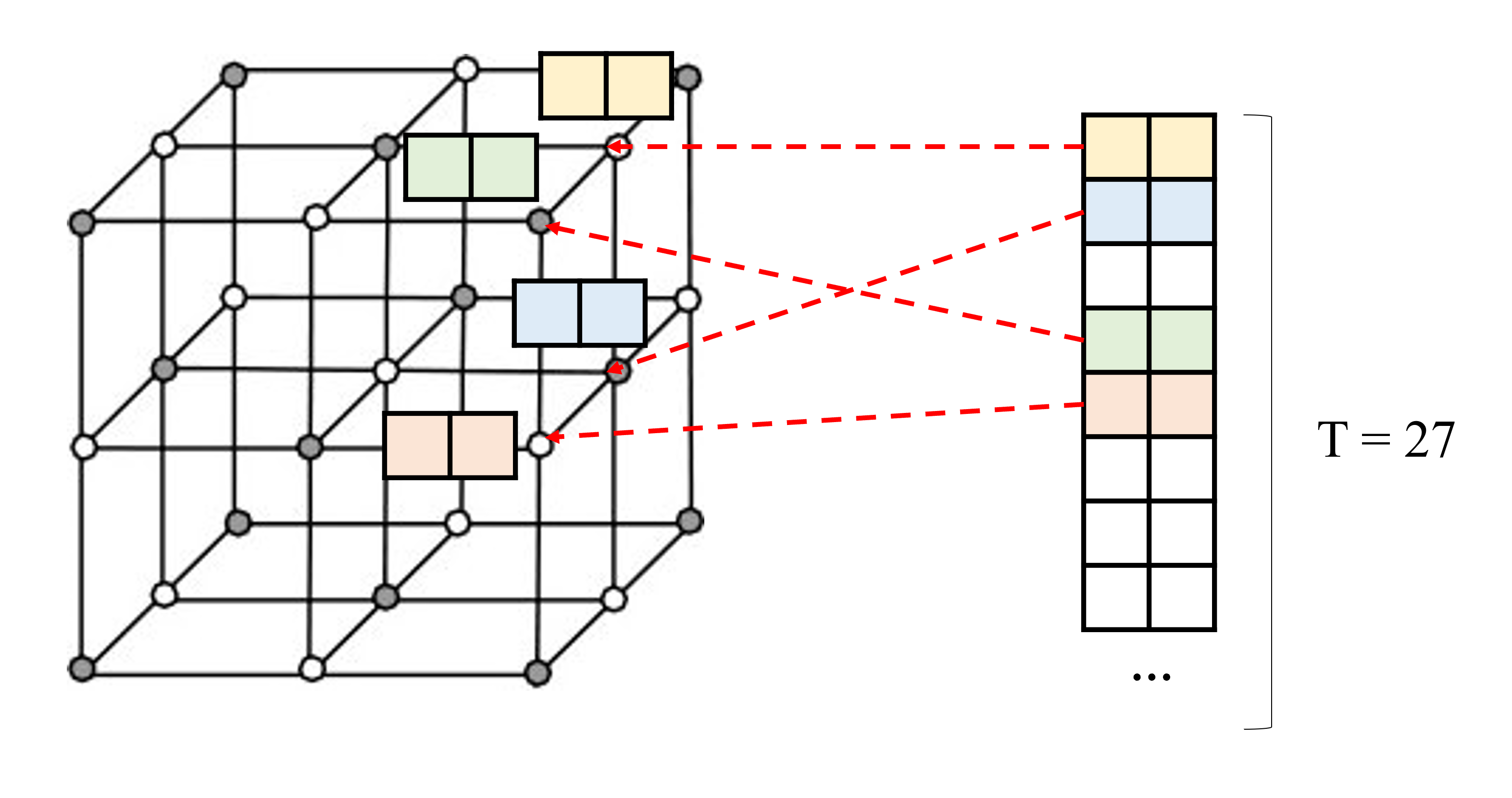
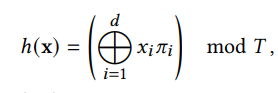
(3) Input 좌표 x의 relative position에 따라 interpolate하여 feature vector 생성
각 corner의 feature vector를 이용하여 거리 기반으로 weighted sum하여 interpolation
(4) 각 level에 대한 feature를 concat, 추가적인 정보 도 추가 가능
(3)의 process는 각 level에 대해 independent하게 적용되기 때문에 각 level에서 interpolate된 feature들을 concat하여 합쳐준다. 이때 NeRF의 view direction 등을 같이 넣어줄 수도 있다.
(5) MLP를 통과하여 output을 생성하고 backprop
여기서 update가 되는 것은 level당 한 개씩 정의된 hash table이다.
아래는 multiresolution hash encoding에 실제로 사용되는 hyperparameter이다.

Result
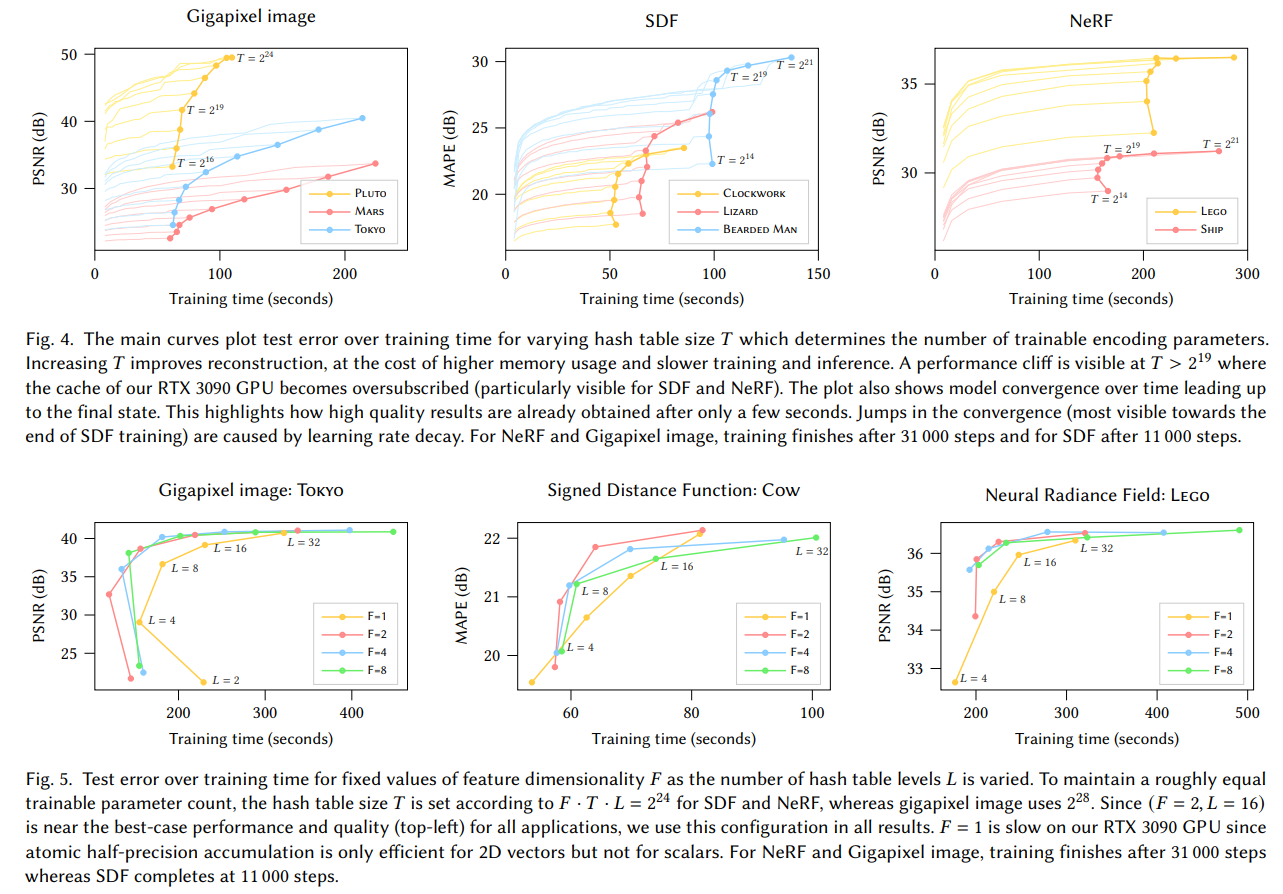
Hash table size(T)가 performance, memory와 quality에 미치는 영향이다. Hash table size가 클수록 quality가 좋아지고 training time은 늘어난다.
또한, number of level과 feature dimension도 성능에 영향을 준다.
Discussion
원래 이 논문은 NeRF만을 위해서 연구가 된 것이 아니고, Gigapixel image, Signed Distance Functions, Neural Radiance Caching 등의 다른 분야에 대해서도 적용하기 위해서 설계가 되었고, 좋은 성능을 보여주었다.
그래서 엄청 자세하게 다루거나 코드를 까보지는 않았다. 그리고 애초에 Nvidia에서 pytorch로 구현된 모듈을 공개해서 가져다가 쓰기만 하면 되는데, 대략적인 이해가 필요했다.
또한 최근에 CBCT reconstruction을 다루면서, positional encoding 방식이 상당히 중요하다는 것을 깨닫고 공부를 하려고 하고 있다.
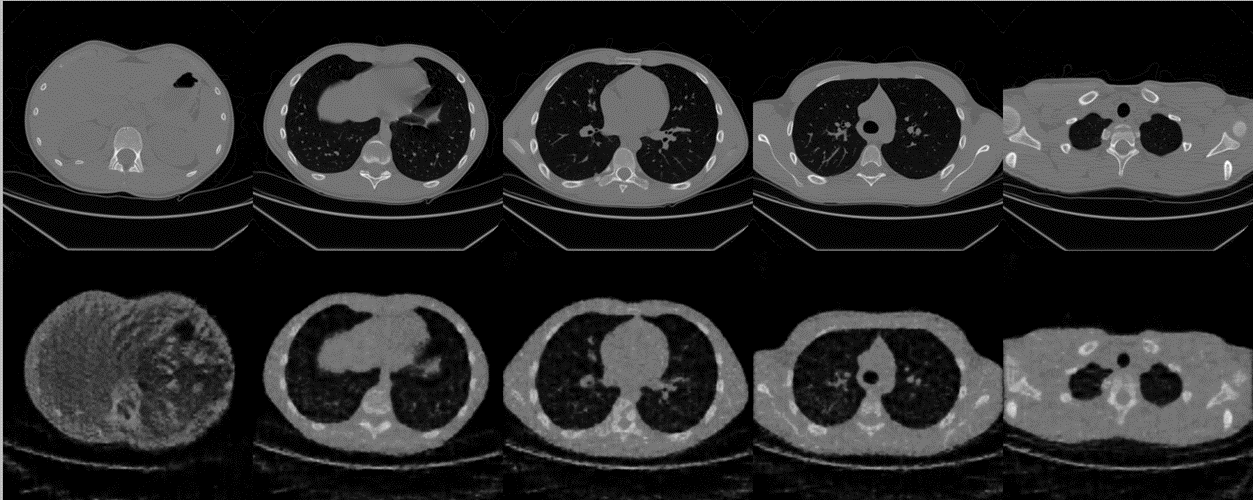
아래는 다음의 연구 방법을 이용한 CBCT Recon 결과이다.
NAF: Neural Attenuation Fields for Sparse-View CBCT Reconstruction (Ruyi Zha, Yanhao Zhang, Hongdong Li / MICCAI 2022)
Hash Encoding 방법 (num_level=16, level_dim=2, min_res=16, hash_size=19)
Frequency Encoding 방법 (L=12)
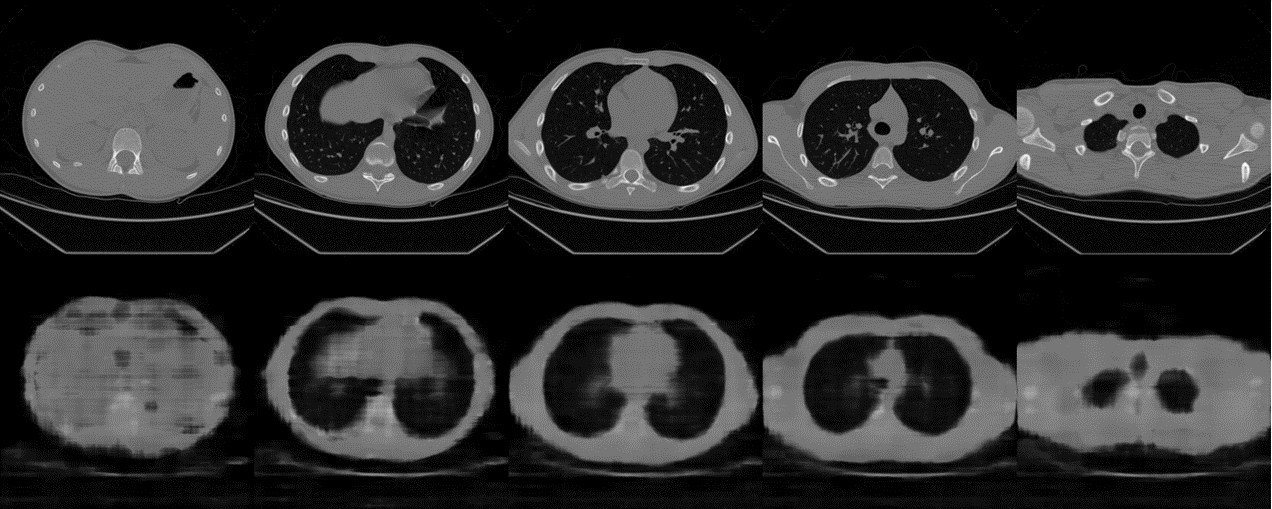
Detail을 출력해내는 성능에서 매우 차이가 난다. 물론 hyperparameter 영향도 있겠지만..
아마도 어떤 좌표를 encoding하는 관점에서 trainable한 encoder를 사용함으로써 더 중요한 detail에 집중할 수 있게 된 것이 아닌가 싶다. 예를 들어서 CT image의 경우 같은 물질은 같은 HU value를 갖기 때문에 표현해야하는 optimal한 frequency band가 존재할 수도 있는데, 이를 학습으로 배울 수도 있을 것 같다.
